Структуры данных и эффективность алгоритмов. 4
 Скачать 2.32 Mb. Скачать 2.32 Mb.
|

ГрафыИзвестно несколько представлений графа G=(V, E). Один из них — матрица смежностей, т.е. матрица А размера ||V||x||V||, состоящая из 0 и 1, в которой Еще одно возможное представление графа — с помощью списков. Списком смежностей для узла v называется список всех узлов w, смежных с v. Граф можно представить с помощью 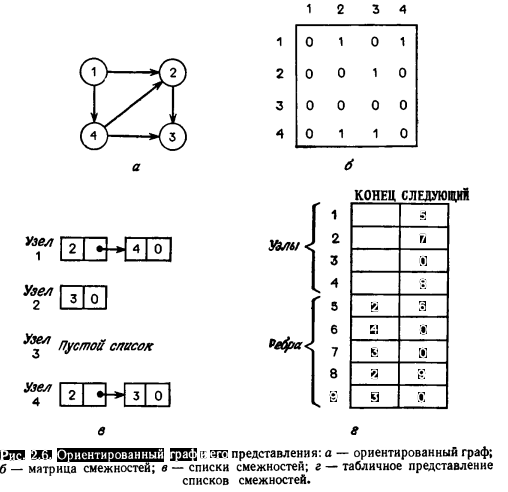
Также как и для последовательностей, доступ к компонентам (вершинам) дерева может быть определен как прямой или последовательный. Будем различать понятия: позиция вершины дерева - однозначно идентифицирующая вершину и её положение в дереве, и элемент – информация, ассоциированная с вершиной дерева (в частности, просто хранимая вместе с ней). Определение. Ориентированный граф без циклов называется ориентированным ациклическим графом. (Ориентированное) дерево (иногда его называют корневым деревом) — это ориентированный ациклический граф, удовлетворяющий следующим условиям: 1) имеется в точности один узел, называемый корнем, в который не входит ни одно ребро, 2) в каждый узел, кроме корня, входит ровно одно ребро, 3) из корня к каждому узлу идет путь (который, как легко показать, единствен). Ориентированный граф, состоящий из нескольких деревьев, называется лесом. Леса и деревья — столь часто встречающиеся частные случаи ориентированных ациклических графов, что для описания их свойств стоит ввести специальную терминологию. Определение. Пусть F=(V, E) — граф, являющийся лесом. Если Глубина узла v в дереве — это длина пути из корня в v. Высота узла v в дереве — это длина самого длинного пути из v в какой-нибудь лист. Высотой дерева называется высота его корня. Уровень узла v в дереве равен разности высоты дерева и глубины узла v. 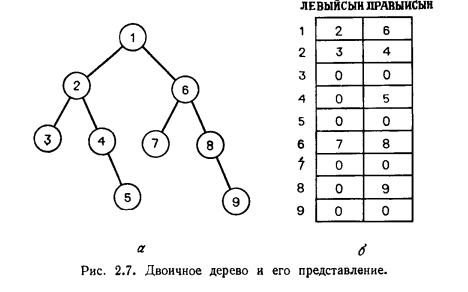 Например, на рис. 2.7,а узел 3 имеет глубину 2, высоту 0 и уровень 1. Упорядоченным деревом называется дерево, в котором множество сыновей каждого узла упорядочено. При изображении упорядоченного дерева мы будем считать, что множество сыновей каждого узла упорядочено слева направо. Двоичным (бинарным) деревом называется такое упорядоченное дерево, что 1) каждый сын произвольного узла идентифицируется либо как левый сын, либо как правый сын, 2) каждый узел имеет не более одного левого сына и не более одного правого сына. Поддерево Двоичное дерево обычно представляют в виде двух массивов ЛЕВЫЙСЫН и ПРАВЫЙСЫН. Пусть узлы двоичного дерева занумерованы целыми числами от 1 до Двоичное дерево называется полным, если для некоторого целого числа k каждый узел глубины меньшей k имеет как левого, так и правого сына и каждый узел глубины k является листом. Полное двоичное дерево высоты k имеет ровно Многие алгоритмы, использующие деревья, часто проходят дерево (посещают каждый его узел) в некотором порядке. Известно несколько систематических способов сделать это. Мы рассмотрим три широко распространенных способа: прохождение дерева в прямом порядке, обратном и внутреннем. Определение. Пусть Т — дерево о корнем Прохождение дерева Т в прямом порядке определяется следующей рекурсией: 1) посетить корень 2) посетить в прямом порядке поддеревья с корнями Прохождение дерева Т в обратном порядке определяется следующей рекурсией: 1) посетить в обратном порядке поддеревья с корнями 2) посетить корень Прохождение двоичного дерева во внутреннем порядке определяется следующей рекурсией: 1) посетить во внутреннем порядке левое поддерево корня (если оно существует), 2) посетить корень, 3) посетить во внутреннем порядке правое поддерево корня (если оно существует) 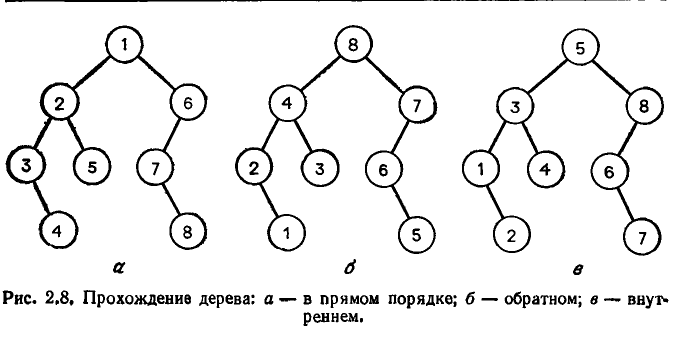 При нумерации в прямом порядке все узлы поддерева с корнем Список основных операций навигации по дереву (операций доступа к компонентам дерева) [7 п.3.2; 13 п.6.1.2]:
Для варианта с последовательным доступом к компонентам аргумент «позиция» (номер) становится не нужным, все операции привязаны к текущей позиции. Для представления деревьев используются и массивы, и (нелинейные) связные списковые структуры данных (с указателями) и смешанные способы представления. В частности, представление структуры дерева может быть отделено от хранилища информации, привязанной к вершинам (и ребрам) дерева.
• если v является корнем, то p(v) = 1; • если v - левый сын вершины u, то p(v) = 2*p(u); • если v - правый сын вершины u, то p(v) = 2*p(u)+ l. Эта нумерационная функция известна как уровневая нумерация (level numbering) вершин бинарного дерева, поскольку нумерует вершины (начиная с корня) на каждом уровне (сверху вниз) в возрастающем порядке слева направо, но пропускает номера отсутствующих вершин, соответствующего полного бинарного дерева. Бинарное дерево представляется вектором, в котором вершине v соответствует элемент с индексом p(v). Аналогичную нумерационную функцию и представление можно предложить и для деревьев с не более чем m сыновьями (у каждой вершины). Все вышеприведенные операции навигации реализуемы для такого представления с константным временем выполнения. Но по памяти такое представление неэкономично для существенно-неполных деревьев, оно потребует примерно 2k единиц памяти, где k – длина самой длинной ветви (даже если такая ветвь только одна, а все остальные существенно короче). Т.к. в таком векторе имеется позиция для каждой вершины полного дерева, а в нашем дереве большая часть вершин этого полного дерева может отсутствовать, то мы можем получить экспоненциальный перерасход памяти.
Реализация операций модификации структуры дерева (удаления и добавления вершин) существенно зависит от их специфики и условий применения и соответствующего этой специфике способа представления дерева. Отметим, что деревья общего вида (с переменным числом сыновей большим двух) можно представлять бинарными, подходящим способом различая в представляющем бинарном дереве ребра связи (исходного дерева) с родителем и ребра связи с братьями, как показано на рисунке (пунктиром соединены вершины представляющего дерева, ассоциируемые с вершинами-братьями исходного дерева): 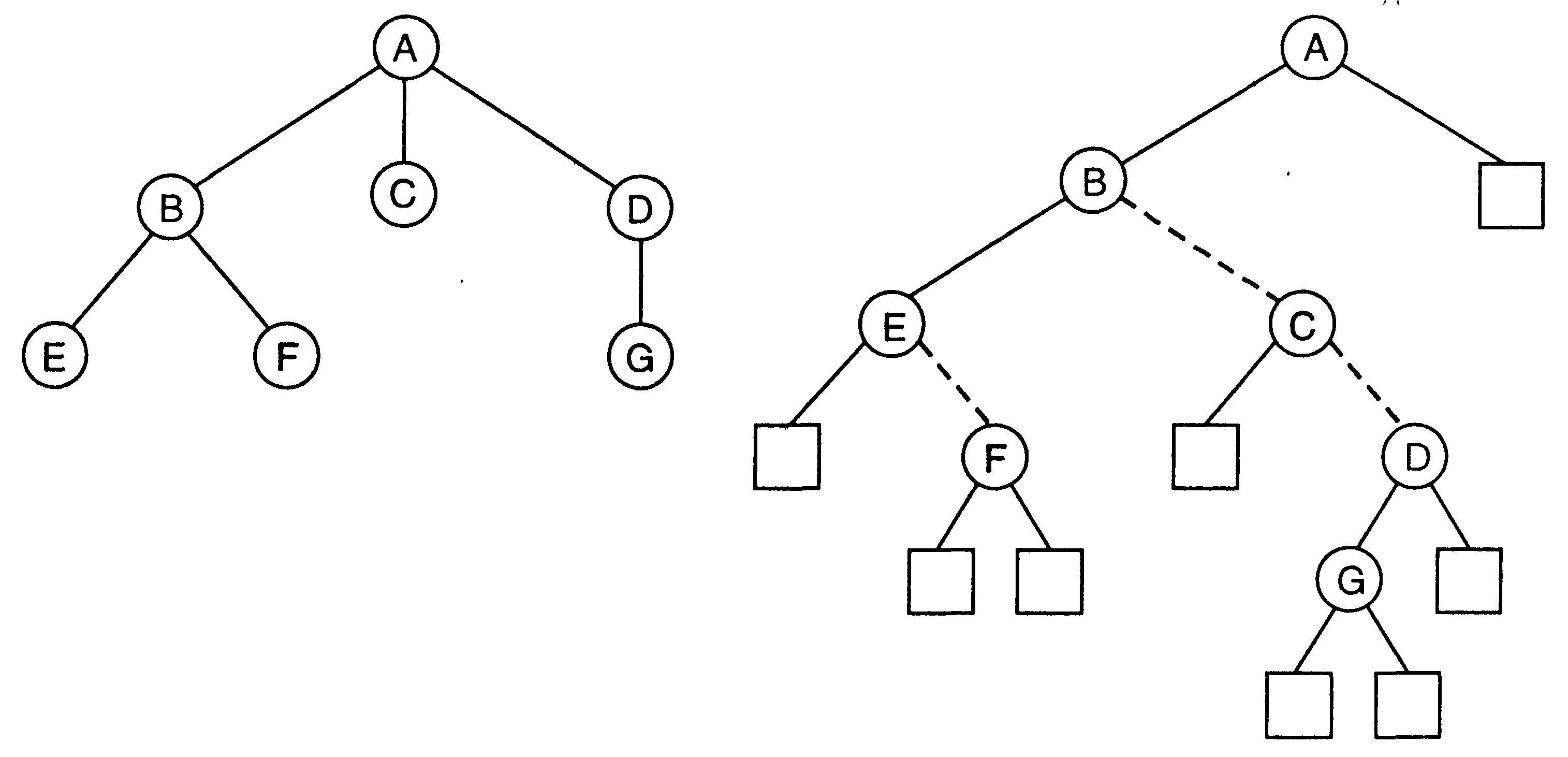 Дерево по определению обладает рекурсивной структурой. Это обстоятельство создает условия использования рекурсивных процедур. Процедуру, которая прямо или косвенно обращается к себе, называют рекурсивной. Применение рекурсии часто позволяет давать более прозрачные и сжатые описания алгоритмов, чем это было бы возможно без рекурсии. Рассмотрим определение прохождения двоичного дерева во внутреннем порядке. При создании алгоритма, который присваивает узлам номера в соответствии с внутренним порядком, хорошо было бы отразить в нем определение прохождения во внутреннем порядке. Один из таких алгоритмов приведен ниже. Заметим, что он рекурсивно обращается к себе для нумерации поддерева. Алгоритм 2.1. Нумерация узлов двоичного дерева в соответствии с внутренним порядком Вход. Двоичное дерево, представленное массивами ЛЕВЫЙСЫН и ПРАВЫЙСЫН. Выход. Массив, называемый НОМЕР, такой, что НОМЕР[i]— номер узла i во внутреннем порядке. Метод. Кроме массивов ЛЕВЫЙСЫН, ПРАВЫЙСЫН и НОМЕР, алгоритм использует глобальную переменную СЧЕТ, значение которой — номер очередного узла в соответствии с внутренним порядком. Начальным значением переменной СЧЕТ является 1. Параметр УЗЕЛ вначале равен корню. Cам алгоритм таков: begin СЧЕТ ВНУТПОРЯДОК(КОРЕНЬ) end ? Рекурсия дает несколько преимуществ и прежде всего простоту программ. Если бы приведенный выше алгоритм не был записан рекурсивно, надо было бы строить явный механизм для прохождения дерева. Двигаться вниз по дереву нетрудно, но чтобы обеспечить возможность вернуться к предку, надо запомнить всех предков в стеке, а операторы работы со стеком усложнили бы алгоритм. а операторы работы со стеком усложнили бы алгоритм. procedure ВНУТПОРЯДОК(УЗЕЛ): begin 1. if ЛЕВЫЙСЫН[УЗЕЛ] 2. НОМЕР[УЗЕЛ] 3. СЧЕТ 4. if ПРАВЫЙСЫН[УЗЕЛ] End Вариант алгоритма во внутреннем порядке без рекурсии Вход. Тот же, что у предыдущего алгоритма . Выход. Тот же, что у предыдущего алгоритма . Метод. При прохождении дерева в стеке запоминаются все узлы, которые еще не были занумерованы и которые лежат на пути из корня в узел, рассматриваемый в данный момент. При переходе из узла v к его левому сыну узел v запоминается в стеке. После нахождения левого поддерева для v узел v нумеруется и выталкивается из стека. Затем нумеруется правое поддерево для v. При переходе из и к его правому сыну узел v не помещается в стек, поскольку после нумерации правого поддерева мы не хотим возвращаться в у; более того, мы хотим вернуться к тому предку begin СЧЕТ УЗЕЛ СТЕК левый: while ЛЕВЫЙСЫН[УЗЕЛ] begin затолкнуть УЗЕЛ в СТЕК; УЗЕЛ end; центр: НОМЕР[УЗЕЛ1 СЧЕТ — СЧЕТ+1; if ПРАВЫЙСЫН[УЗЕЛ[ begin УЗЕЛ goto левый end; if СТЕК не пуст then begin УЗЕЛ вытолкнуть из СТЕКа; goto центр end end
Поисковое дерево – это упорядоченное дерево, имеющее следующие свойства:
Отметим особенность (геометрического характера) таких деревьев – у вершин такого бинарного дерева допускается наличие правого сына при отсутствии левого, т.е. фиксируется не просто порядок на множестве дочерних вершин, но и их позиция (даже если позиция левого свободна). Хотя, с другой стороны, эту ситуацию можно трактовать как наличие двух детей, из которых левый – «пустой» (фиктивный)20.  Для таких деревьев время поиска по ключу ≤ O(h), где h – высота дерева. Но при вставке новых вершин (с ключами) могут появляться длинные ветви, поэтому для времени поиска верхняя оценка в худшем O(n), где n – количество вершин в дереве. Статистический анализ показывает, что для бинарных поисковых деревьев с n вершинами оценка высоты в среднем O(log(n)) и она такая же для операций поиска, вставки, удаления и min с множествами мощности n. Поэтому бинарное дерево поиска хороший вариант для представления АТД «Множество», «Словарь»21 и «Очередь с приоритетом», но эффективна такая реализация только в среднем, т.е. только в среде, в которой случающиеся задержки выполнения операций некритичны, если общее время работы программы длительное и приемлемое для обрабатываемого объема входного потока.
На сегодняшний день разработано несколько методов перестройки деревьев поиска, которые позволяют поддерживать сбалансированную структуру дерева поиска с приемлемыми расходами по времени, так чтобы общее время в худшем для операций поиска, вставки, удаления и min (АТД «Множество», «Словарь» и «Очередь с приоритетом») сохранялось O(log(n)). Балансировку структуры дерева можно проводить и по высоте, и по объему (весу) поддеревьев [18 п.6.4]. Для бинарных деревьев известны методы балансировки – АВЛ-деревья [13 п.9.2], красно-черные деревья (RB-tree)и их вариации.
Красно-черное дерево - это двоичное дерево поиска, обладающее следующими свойствами(будем называть их RB свойствами):
 Количество черных узлов на ветви от корня до листа называется черной высотой дерева. Перечисленные свойства гарантируют, что самая длинная ветвь, ведущая от корня к листу, не более чем в два раза длиннее любой другой ветви от корня к листу. Чтобы понять, почему это так, рассмотрим дерево с черной высотой Количество черных узлов на ветви от корня до листа называется черной высотой дерева. Перечисленные свойства гарантируют, что самая длинная ветвь, ведущая от корня к листу, не более чем в два раза длиннее любой другой ветви от корня к листу. Чтобы понять, почему это так, рассмотрим дерево с черной высотой Лемма[Кормен]. Красно-черное дерево с Из вышесказанного следует, что время выполнения операций поиска, нахождение минимального или максимального элементов с использованием красно-черных деревьев составляет Восстановление этих свойств требует перекраски некоторых вершин, а также выполнения операций вращения 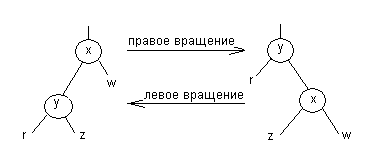 Операции левого и правого вращения являются обратными друг другу. При добавлении нового узла сначала ведется поиск места этого узла в дереве. Узел красится в красный цвет, его сыновья (NIL-узлы) окрашены в черные цвета. При вставке может быть нарушено RB-свойство 3, поскольку отец вставленной вершины также может быть окрашен в красный цвет. Если необходимо, мы перекрашиваем узел и производим поворот, чтобы сбалансировать дерево. Рассмотрим ситуацию, когда отец нового узла - красный: при этом будет нарушено свойство 3. Достаточно рассмотреть следующие два случая: Красный отец, красный "дядя": Ситуацию красный-красный иллюстрирует рис. У нового узла X отец А и "дядя" С оказались красными. Простое перекрашивание избавляет нас от красно-красного нарушения. После перекраски нужно проверить "дедушку" нового узла (узел B), поскольку он может оказаться красным. Необходимо обратить внимание на распространение влияния красного узла на верхние узлы дерева. В самом конце корень красится в черный цвет. Если он был красным, то при этом увеличивается черная высота дерева 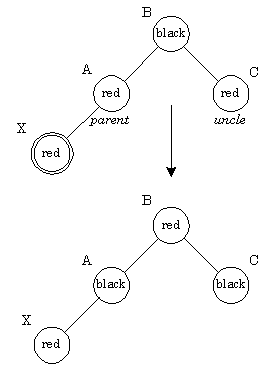 Красный отец, черный "дядя": На рис. представлен другой вариант красно-красного нарушения - "дядя" нового узла оказался черным. Здесь узлы может понадобиться вращать, чтобы скорректировать поддеревья. В этом месте алгоритм может остановиться из-за отсутствия красно-красных конфликтов и вершина дерева (узел A) окрашивается в черный цвет. Если узел X был в начале правым потомком, то первым применяется левое вращение, которое делает этот узел левым потомком. Каждая корректировка, производимая при вставке узла, заставляет нас подняться в дереве на один шаг. В этом случае до остановки алгоритма будет сделано 1 вращение (2, если узел был правым потомком). Метод удаления рассматривается аналогично. 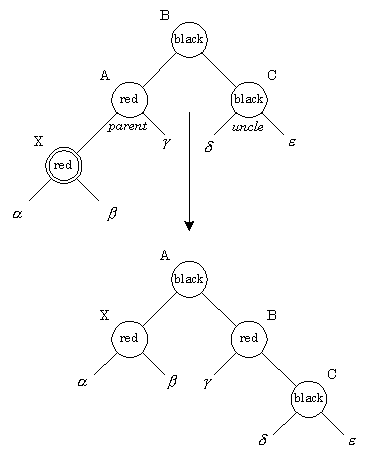
Специфическая структура данных – Splay-дерево. Это бинарное дерево поиска, но при этом не поддерживается явного баланса, оно может оказаться разбалансированным в определенном (традиционном) смысле. Вместо этого после выполнения каждой операции, типовой для бинарных поисковых деревьев, осуществляется перестройка (сохраняющая определяющие свойства поискового дерева) с целью «подтянуть» вершины текущего пути дерева поближе к корню, что ускоряет их нахождение в будущем. Для такого представления вышеупомянутые операции с множествами (и некоторый набор дополнительных операций) имеют время работы O(log(n)), но амортизированное. Перестройка проводится с помощь трех Splay-операций:


 Возможности организовать балансировку расширяются, если допускать изменение количества сыновей вершины в фиксированном диапазоне [k,m]. К таким методам балансировки относятся 2-3-деревья, В-деревья и их вариации. Сильно ветвящиеся В-деревья представляют особый интерес при работе с данными, хранящимися во внешней памяти. Баланс в АВЛ деревьях и красно-черных деревьях поддерживается за счет операций вращения. Из-за сложности операций балансировки считается, что сбалансированные деревья следует использовать лишь в том случае, когда поиск информации производится значительно чаще, чем включение. Можно предложить другую модель кодирования словаря, в которой все листья дерева расположены на одном и том-же уровне, а степень ветвления вершин может быть более двух. Баланс в таких деревьях поддерживается за счет изменений степеней вершин. Существует множество других операций над сбалансированными деревьями, которые поддерживают их сбалансированность. Сбалансированные деревья используются и для представления последовательностей таким образом, что можно будет быстро вставлять элементы в последовательность, преодолевая трудности, которые связаны с последовательным расположением элементов (в массиве), и обеспечивая при этом произвольный доступ к элементам последовательности, т. е. преодолевая сложности связанного размещения элементов. При этом такие представления позволяют эффективно реализовать операции сцепить (конкатенация) и расцепить для последовательностей. Исследуются и известны расширения выше отмеченных структур данных предназначенные для применения в различных предметных областях, естественно имеющих свою специфику интерпретации данных. Например, расширение красно-черных деревьев для работы с ключами вида интервал вещественных чисел [4 п.14.3], которое представляет прямой интерес в задачах вычислительной геометрии.
В задачах поиска зачастую ключ поиска представлен последовательностью в (достаточно ограниченном) конечном алфавите (цифр или букв). В частности, при желании любой ключ можно трактовать как двоичную (или 16-ю) последовательность. Такое позиционное представление ключа эффективно используется в алгоритмах позиционной сортировки (сегментная-поразрядная сортировка, bucket- radixsort). Если длина ключа и размер алфавита ограничены сверху константой, то можно отказаться от сравнения ключей (на меньше-больше), и упорядочивать множество с такими ключами за линейное время (с мультипликативной константой, зависящей от размера алфавита и длины ключа). См. [7 п.8.5; 4 гл.8; 3 гл.10.], а также Пример 2. Лексикографическая сортировка. В дереве цифрового поиска разветвления основаны не на полном сравнении ключей, а на значении очередной позиции ключа. Такие деревья широко используются в задачах обработки текстов, а точнее для хранения и поиска слов (и текстов) в поисковых словарях: 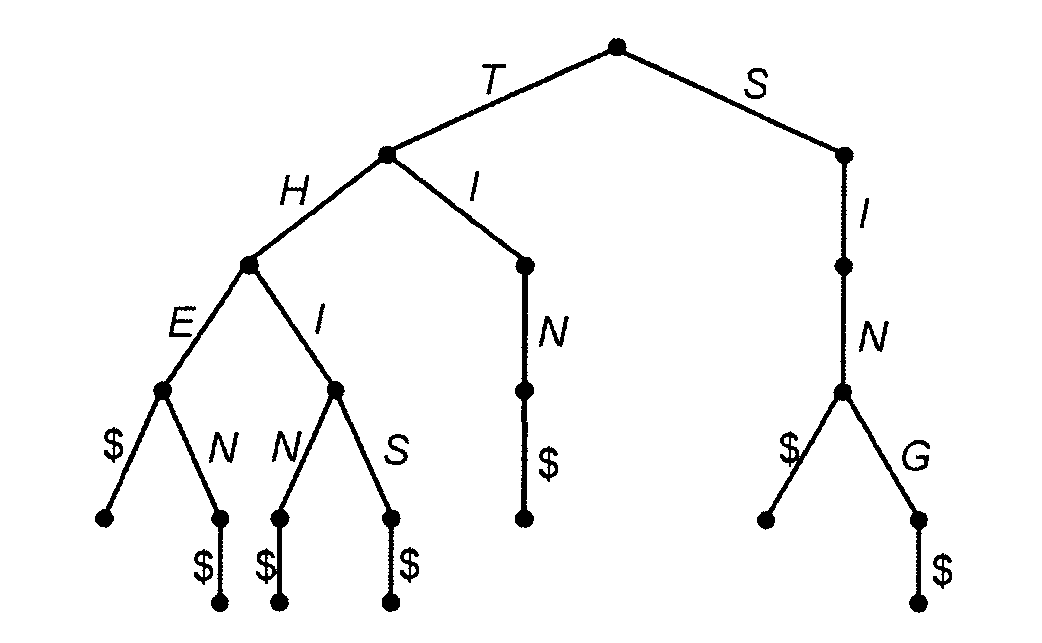 Это дерево хранит множество слов (ключей поиска) {THE, THEN, THIN, THIS, TIN, SIN, SING}. Корень соответствует пустой строке, а два его сына - префиксам Т и S. Самый левый лист представляет слово THE, следующий лист - слово THEN и т.д. Для деревьев цифрового поиска временные характеристики основных операций аналогичны таковым для бинарного поискового дерева, т.е. O(log(n)) в среднем, но в худшем случае не превышает количества позиций в искомом ключе. Для задач обработки текстов (в частности задачи поиска по ключевым словам с точным и неточным сопоставлением) на основе деревьев цифрового поиска разработаны более сложные структуры данных (например, суффиксные деревья), позволяющие эффективно решать эти задачи [2 п.9.5; 15; 16].
Неубывающая пирамида – это почти полное дерево (только уровень листьев может быть неполным), удовлетворяющее требованию – ключ каждой вершины не больше ключа родителя. Аналогично определяются невозрастающие пирамиды. 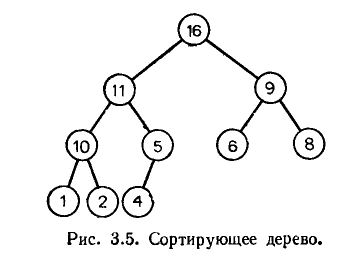 На рисунке приведен пример двоичной невозрастающей пирамиды. Несложно заметить, что ключи в каждой вершине не меньше максимального из ключей левого и правого поддеревьев. Дерево является сбалансированным, высота этого дерева равна Для пирамид представление с помощью массива, основанное на нумерации вершин (см. выше преамбулу п.3.2), эффективно и по памяти, и по времени в худшем, O(log(n)) – для операций АТД «Очередь с приоритетом» (с n элементами). Алгоритм (внутренней) пирамидальной сортировки можно описать как алгоритм, который сначала строит очередь с приоритетом для сортируемой последовательности, а потом выводит её в отсортированном виде, удаляя из очереди выводимый элемент. Он имеет наилучшие характеристики, по времени в худшем - O(nlog(n)), и при этом не требует дополнительной памя ти (как например алгоритм сортировки слиянием). Отметим, что на пирамидах не удается реализовать операторы общего вида Найти и Удалить (произвольно заданный) элемент с временем выполнения O(log(n)). Разработаны и исследованы расширения пирамидальных структур данных, которые используются в практике программирования в задачах, требующих большей функциональности, чем базовый АТД очередей с приоритетом. Один из видов таких расширений известен под названием сливаемые пирамиды (mergeable heaps) - биномиальные и фибоначчиевы пирамиды. Главное функциональное отличие этих структур данных – операция слияния двух пирамид, которая создает новую пирамиду (без сохранения исходных). Сливаемые пирамиды позволяют реализовать эту операцию за время (log(n)) в худшем случае или даже (1) в среднем (точнее, это амортизированное время). В то время как бинарная пирамида позволяет реализовать эту операцию только за время в худшем (n). Основные структурные отличия этих структур данных:
Но эта структура деревьев (с учетом леса) позволяет организовать приемлемую балансировку, в итоге она дает для операций базового АТД очередей с приоритетом такие же оценки по времени, как и классическая бинарная пирамида. Список основных операций для (неубывающих) сливаемых пирамид:
Кроме того, эти структуры данных поддерживают следующие две операции.
Время выполнения операций у разных реализаций сливаемых пирамид:
Все три указанных вида пирамид не могут обеспечить эффективную реализацию поиска элемента с заданным ключом (операции Найти и Принадлежать АТД «Множество» и «Словарь»), поэтому операции Decrease_Key и Delete в качестве параметра получают указатель на вершину, а не значение её ключа. Замечание. Но дополнительно используя подходящую структуру данных для работы со словарем вершин можно устранить это ограничение. Фибоначчиевы пирамиды особенно полезны в случае, когда количество операций Extract_Min и Delete относительно мало по сравнению с количеством других операций. Такая ситуация возникает во многих приложениях. Однако с практической точки зрения программная сложность реализации и высокие значения постоянных множителей в формулах времени работы существенно снижают эффективность применения фибоначчиевых пирамид, делая их для многих приложений менее привлекательными, чем обычные бинарные (или к-арные) пирамиды, если не нужна операция Union.
Основные принципы организации таких структур данных и методов работы с ними были проиллюстрированы во введении (Пример 3 Связность). Отметим, что представление таких семейств множеств лесом деревьев позволяет выполнять (в префиксном режиме) последовательность n операций «Объединить-Найти» за почти линейное время благодаря двум основополагающим методам (важным и в других приложениях, как методы для хороших алгоритмов):
|