Структуры данных и эффективность алгоритмов. 4
 Скачать 2.32 Mb. Скачать 2.32 Mb.
|

Рандомизированные структуры данных.Идея использовать в разработке алгоритмов статистические основания (соображения) удивительно плодотворно себя проявляет22. Рандомизированные структуры данных полностью ставят на удачу, но статистически хорошо обоснованную. Если для какой-то структуры данных оценка времени в среднем оказывается хорошей, то вместо ставки на случайность входной последовательности можно встроить случайность в алгоритм построения (и реорганизации) этой структуры данных. Особую привлекательность этот прием получает, если исходная структура данных проста и легко реализуема.
Хеш-таблица – это структура данных, предназначенная для хранения и поиска данных с ключом. Пусть на входе последовательность длины n обрабатываемых данных (с ключами). Пусть хеш-функция h(k) по значению ключа k дает целое в интервале [0..m), причем статистически равномерно отображает ключи элементов входной последовательности в этот интервал. Представим хеш-таблицу вектором H[0..m) с элементами типа обрабатываемых данных и будем хранить данное с ключом k в H[h(k)]. Это откроет нам возможность прямого доступа к данным по ключу. Тогда:
Для хеш-таблиц разработаны и исследуются разнообразные методы разрешения коллизий, в частности методы её регулярного пересоздания с увеличением размера. Отдельный теоретический вопрос – методы построения и выбора хеш-функций, а также исследования их свойств.
При вставке новой вершины в дерево, состоящее из n вершин, вероятность появления новой вершины в корне должна быть равна 1/(n+1), это следует из рассуждений обоснования оценки времени в среднем для операций с бинарным поисковым деревом. Поэтому вместо стандартной вставки мы просто принимаем рандомизованное решение с этой вероятностью, использовать вставку в корень. В случаях рандомизованных и стандартных бинарных поисковых деревьев усредненные затраты одинаковы (хотя для рандомизованных деревьев коэффициент пропорциональности несколько выше), однако для случая стандартных деревьев результат зависит от допущения о вставке в случайном (равновероятном) порядке их ключей. Это допущение не всегда справедливо в практических приложениях, а рандомизованный алгоритм примечателен тем, что позволяет избавиться от такого допущения и вместо этого исходить из законов распределения вероятностей в генераторе случайных чисел. При вставке элементов в порядке следования их ключей, в обратном порядке или любом другом порядке, поисковое дерево все равно будет рандомизованным.
Список пропусков - это многоуровневый связный список, в котором элементы одной последовательности связываются в односвязные списки на каждом уровне, но на i-м уровне связываются не все элементы, а с пропуском - только некоторые из связанных на предыдущем уровне. Образование нового уровня и пропуск элементов основаны на рандомизации. Пусть skip-список S для словаря D состоит из серии списков {S0, S1, S2, … Sh}. Каждый список Si хранит набор объектов словаря D по ключам в неубывающей последовательности (плюс объекты с двумя специальными ключами, записываемыми в виде «-» и «+», где «-» обозначает меньше, а «+» - больше любого возможного ключа, который может быть в D). Кроме того, списки в S отвечают следующим требованиям:
Образец такого skip-списка приведен ниже: 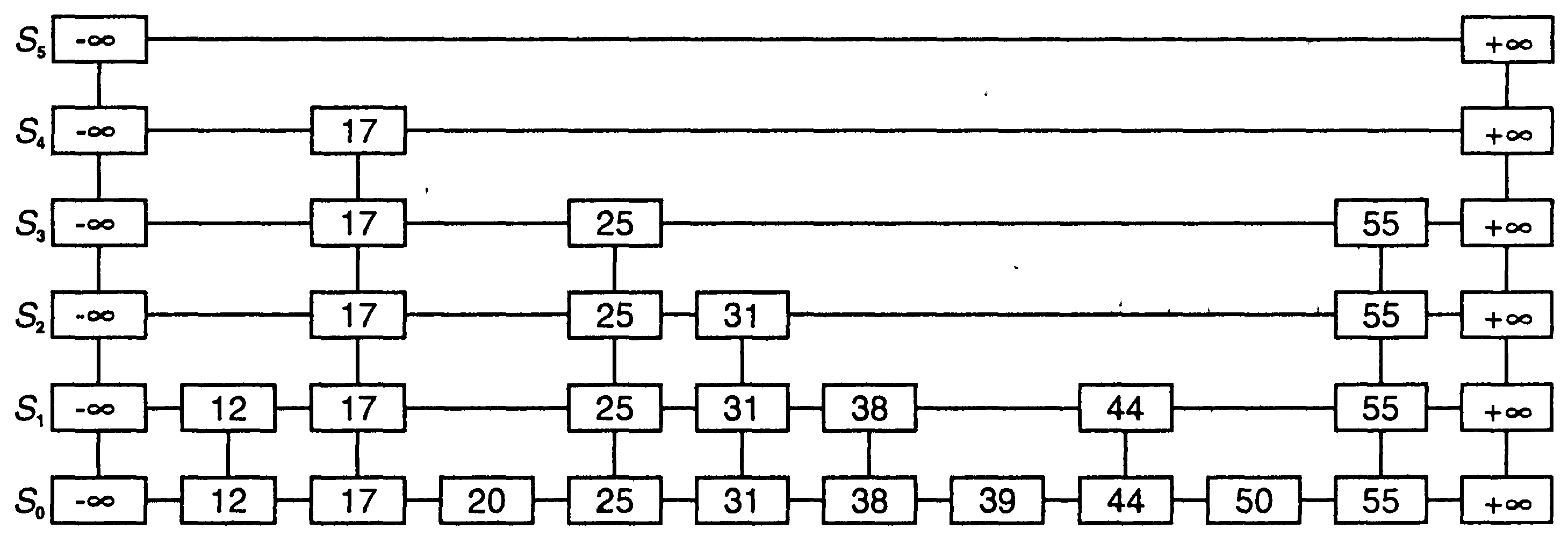 Фактически такой skip-список является аналогом упорядоченного дерева, в котором на каждом уровне примерно в два раза (в среднем) меньше вершин, чем на предыдущем. Каждой вершине p текущего уровня (с предшествующей вершиной p) в качестве сыновей соответствуют вершины предыдущего уровня с ключами в интервале от ключа вершины p (исключительно) до ключа вершины p. Позиции skip-списка можно проходить с помощью следующих операций:
Эти операции реализуемы с временем O(1) в среднем, а операции АТД «Словарь» (Вставить, Удалить, Найти элемент) реализуемы с временем O(log(n)) в среднем.
Декартово дерево – это бинарное дерево. Каждая вершина x такого дерева имеет два ключа key[x] и priority[x]. По ключу key[x] – это дерево является поисковым (т.е. ключ родителя меньше ключей всех потомков левого сына и больше всех потомков правого), а по ключу priority[x] – это дерево является бинарной пирамидой (т.е. ключ вершины меньше ключей всех её потомков). В таком дереве ключ key задается условиями задачи, а ключ priority – (динамически) формируется генератором случайных чисел. Помочь разобраться с таким деревом может следующая интерпретация. Предположим, что мы вставляем вершины x1, x2, … xn со связанными с ними ключами. Тогда получающееся в результате декартово дерево представляет собой дерево, которое получилось бы в результате стандартной вставки вершин в стандартное бинарное поисковое дерево по ключам key, но в порядке, определяемом (случайно выбранными) приоритетами, т.е. priority[xi] < priority [xj] означает, что вершина xi была вставлена раньше вершины xj. Для этой структуры данных доказано:
С таким же временем, O(log(n)) в среднем, реализуемы операции Вставить, Удалить, Найти min и ряд других операций. В заключение раздела о рандомизированных структурах данных приведем обещание, которое дал Кнут Д.Э. в последнем издании т3. книги «Искусство программирования» [14] - «В следующее издание книги планируется добавить раздел 6.2.5, посвященный рандомизированным структурам данных. В нем будут рассмотрены списки с пропусками, рандомизированные бинарные деревья поиска, а также упомянутые в этом разделе "дучи" (декартовы деревья)». 1 Это плата за возможность поддержки единовременно двух порядков. Платить приходится за все! Весь вопрос – сколько? 2 26 – число букв в используемом алфавите 3 Задача (и изложение вариантов её решения) заимствована из книги [3 гл.1.]. Даже с учетом высказывания автора «...вероятно, процесс был искусственно упрощен...» этот пример нам представляется уж очень хорошим, особенно и именно в этом месте. С одной стороны достаточно просто изложена и логика развития и способ достижения целей и его реализация, а с другой стороны методы, задействованные в этом примере, совсем не «штучки, придуманные на ходу», а результаты целого периода исследований в этой области... тщетны надежды придумать такие «штучки» на ходу... И это всё притом, что приложения этой задачи и этих методов настолько важны для практики (и интересны для теории), что структура данных «объединить-найти» до сих пор интенсивно исследуется, и многие вопросы остаются открытыми. 4 p-q симметричное: если р связано с q, то q связано с р. 5 p-q транзитивное: если р связано с q, a q связано с r, то р связано с r. 6 Постановка задачи в терминах теории графов. p,q – вершины неориентированного графа, p-q – его ребра. Сведения о ребре p-q надо игнорировать, если в текущем состоянии в графе уже есть путь, соединяющий вершины p и q. 7 Можно отметить аналогию с квадратом, у которого, как известно, среди всех прямоугольников - максимальная площадь при минимальном периметре. 8 Двойственность одна из фундаментальных связей между проблемами, которая в математике всегда фиксируется, изучается и используется... 9 Более того, это доказано для (такой же) инверсии функции Аккермана в качестве функции G(.), а функция Аккермана возрастает быстрее любой примитивно-рекурсивной функции. 10 А это напрямую связано с анализом алгоритма решения задачи 11 Такое предположение выглядит очень правдоподобно. Системы линейных уравнений этой задачи описывают реальные системы реальных объектов, причем обычно – это большие системы, созданные человеком. В такой системе скорее всего совсем не всякий объект связан напрямую со всяким, скорее всего система состоит из обозримого количества подсистем с обозримым количеством межкомпонентных связей, и далее то же самое можно сказать о каждой из её подсистем... Т.е. в реальных задачах структура этих систем линейных уравнений не так уж и хаотична... 12 Например, операцию соединения обычных строк (размера до 256) при желании еще можно трактовать как базовую операцию, но эту же операцию над длинными строками (неограниченного размера) относить к базовым видимо не разумно, ясно что такая операция скорее всего реализуется соответствующей циклической программой. 13 Данные типа указатель играют в процедурных языках программирования такую же роль, но это только с определенной точки зрения... Мы же будем придерживаться несколько иной точки зрения – массив (как структура данных) явно существует уже в конструкции ЭВМ (и соответствующей модели вычислителя) в виде адресуемой памяти, а указатели – это индексы этого массива памяти, абстракция адреса этой памяти с предопределенными операциями (в частности, с операцией new – выделить память для хранилища данных). 14 в смысле, множества равны, если у них одинаков состав элементов, независимо от того в каком порядке элементы перечислены. 15 Конечно, можно рассматривать аналогичный АТД, рассматривая «максимальный» взамен «минимального» и соответственно поправив определения нижеследующих операций. 16 Кстати, такое представление не препятствует эффективной реализации операций удаления и добавления (только) ребер. 17 В нижеследующем списке операций различаются понятия «номер» и «позиция» элемента в последовательности, об этом см. выше п.2.1 (о прямом доступе). 18 Фактически перейти от множества к множеству с ключами элементов – словарю. 19 Можно рассматривать и случай с неуникальными ключами, хотя в этом случае придется аккуратно решать некоторые технические проблемы. 20 Аналогичное уточнение следовало бы сделать и в вышеприведенном определении поисковых деревьев общего вида, но предполагается, что эта недоговоренность устраняется использованием фиктивных сыновей. 21 Естественно, использование поискового дерева для представления множеств предполагает задание какого-нибудь линейного порядка на этих множествах, а использование для словарей – возможность сравнивать значения ключей. 22 Некоторые случаи представляются удивительно странными, с одной стороны, и одновременно удивительно показательными. Например, известно что симлекс метод решения задачи линейного программирования имеет очень плохую оценку по времени в худшем, но статистика испытаний показывает его высокую эффективность по времени. Так называемая быстрая сортировка имеет оценку по времени O(n log(n)) только в среднем, а в худшем – банальную O(n2). Однако статистика испытаний показывает её заметно лучшие характеристики в сравнении с другими методами сортировки. Видимо это объясняется тем, что «плохие» для этих алгоритмов входные данные редко встречаются в практике их использования. |