10001_Контрл. Теории вероятностей. Далее рассматриваем основные вопросы построения вероятностных моделей в разнообразных случаях
 Скачать 185.55 Kb. Скачать 185.55 Kb.
|

Оглавление1. Современное представление о математической статистике 4 2. Примеры применения теории вероятностей и математической статистики 7 2.1. Задачи оценивания 10 2.2. Вероятностно-статистические методы и оптимизация 11 3. Построение полигона и гистрограммы 12 3.1. Полигон 12 3.2. Гистограмма 14 Заключение 17 Список литературы 18 Введение Теория вероятностей и математическая статистика суть основы вероятностно-статистических методов обработки данных. Данные мы обрабатываем и анализируем прежде всего для принятия решений. Чтобы воспользоваться современным математическим аппаратом, необходимо рассматриваемые задачи выразить в терминах вероятностно-статистических моделей. Применение конкретного вероятностно-статистического метода состоит из трёх этапов: Переход от экономической, управленческой, технологической реальности к абстрактной математико-статистической схеме, то есть построение вероятностной модели системы управления, технологического процесса, процедуры принятия решений, в частности по результатам статистического контроля, и тому подобного. Проведение расчётов и получение выводов чисто математическими средствами в рамках вероятностной модели. Толкование математико-статистических выводов применительно к реальной ситуации и принятие соответствующего решения (например, о соответствии или несоответствии качества продукции установленным требованиям, необходимости наладки технологического процесса), в частности, заключения (о доле дефектных единиц продукции в партии, о конкретном виде законов распределения контролируемых параметров технологического процесса и подобном). Математическая статистика применяет понятия, методы и результаты теории вероятностей. Далее рассматриваем основные вопросы построения вероятностных моделей в разнообразных случаях. 1. Современное представление о математической статистике Под математической статистикой понимают «раздел математики, посвящённый математическим методам сбора, систематизации, обработки и интерпретации статистических данных, а также использованию их для научных или практических выводов. Правила и процедуры математической статистики опираются на теорию вероятностей, позволяющую оценить точность и надёжность выводов, получаемых в каждой задаче на основании имеющегося статистического материала». При этом статистическими данными называются сведения о числе объектов в какой-либо более или менее обширной совокупности, обладающих теми или иными признаками. По типу решаемых задач математическая статистика обычно делится на три раздела: описание данных, оценка и проверка гипотез. По виду обрабатываемых статистических данных математическая статистика делится на четыре направления [2, c. 97]: Одномерная статистика (статистика случайных величин), в которой результат наблюдения описывается действительным числом. Многомерный статистический анализ, где результат наблюдения над объектом описывается несколькими числами (вектором). Статистика случайных процессов и временны́х рядов, где результат наблюдения — функция. Статистика объектов нечисловой природы, в которой результат наблюдения имеет нечисловую природу, например, является множеством (геометрической фигурой), упорядочением или получен в результате измерения по качественному признаку. Исторически первыми появились некоторые области статистики объектов нечисловой природы (в частности, задачи оценивания доли брака и проверки гипотез о ней) и одномерная статистика. Математический аппарат для них проще, поэтому на их примере обычно демонстрируют основные идеи математической статистики. Лишь те методы обработки данных, то есть математической статистики, являются доказательными, которые опираются на вероятностные модели соответствующих реальных явлений и процессов. Речь идёт о моделях поведения потребителей, возникновения рисков, функционирования технологического оборудования, получения результатов эксперимента, течения заболевания и тому подобного. Вероятностную модель реального явления следует считать построенной, если рассматриваемые величины и связи между ними выражены в терминах теории вероятностей. Соответствие вероятностной модели реальности, то есть её адекватность, обосновывают, в частности, с помощью статистических методов проверки гипотез. Невероятностные методы обработки данных являются поисковыми, их можно использовать лишь при предварительном анализе данных, так как они не дают возможности оценить точность и надёжность выводов, полученных на основании ограниченного статистического материала. Вероятностные и статистические методы применимы всюду, где удаётся построить и обосновать вероятностную модель явления или процесса. Их применение обязательно, когда сделанные на основе выборочных данных выводы переносятся на всю совокупность (например, с выборки на всю партию продукции). В конкретных областях применений используются как вероятностно-статистические методы широкого применения, так и специфические. Например, в разделе производственного менеджмента, посвящённого статистическим методам управления качеством продукции, используют прикладную математическую статистику (включая планирование экспериментов). С помощью её методов проводится статистический анализ точности и стабильности технологических процессов и статистическая оценка качества. К специфическим методам относятся методы статистического приёмочного контроля качества продукции, статистического регулирования технологических процессов, оценки и контроля надёжности и другие. Широко применяются такие прикладные вероятностно-статистические дисциплины, как теория надёжности и теория массового обслуживания. Содержание первой из них ясно из названия, вторая занимается изучением систем типа телефонной станции, на которую в случайные моменты времени поступают вызовы — требования абонентов, набирающих номера на своих телефонных аппаратах. Длительность обслуживания этих требований, то есть длительность разговоров, также моделируется случайными величинами. Большой вклад в развитие этих дисциплин внесли Александр Яковлевич Хинчин (1894—1959), Борис Владимирович Гнеденко (1912—1995) и другие отечественные учёные. [1, c. 63] 2. Примеры применения теории вероятностей и математической статистики Рассмотрим несколько примеров, когда вероятностно-статистические модели являются хорошим средством решения задач. В романе Алексея Николаевича Толстого «Хождение по мукам» (том 1) говорится: «мастерская даёт двадцать три процента брака, этой цифры вы и держи́тесь, — сказал Струков Ивану Ильичу». Как понимать эти слова в разговоре руководителей завода? Eдиница продукции не может быть дефектна на 23 %. Она может быть либо годной, либо дефектной. Наверноe, Струков мыслил, что в партии большого объёма содержится примерно 23 % дефектных единиц продукции. Тогда возникает вопрос: а что значит «примерно»? Пусть из 100 проверенных единиц продукции 30 окажутся дефектными, или из 1000 — 300, или из 100 000 — 30 000… Надо ли обвинять Струкова во лжи? [3, c. 94] Монетка, используемая как жребий, должна быть «симметричной»: в среднем в половине случаев подбрасывания должен выпадать орёл, а в половине случаев — решка. Но что означает «в среднем»? Если провести много серий по 10 бросаний в каждой серии, то часто будут встречаться серии, в которых монетка 4 раза выпадает орлом. Для симметричной монеты это будет происходить в 20,5 % серий. А если на 100 000 бросаний окажется 40 000 орлов, то можно ли считать монету симметричной? Процедура принятия решений строится на основе теории вероятностей и математической статистики. Пример может показаться несерьёзным. Это не так. Жеребьёвка широко используется при организации промышленных технико-экономических экспериментов. Например, при обработке результатов измерения показателя качества (момента трения)подшипников в зависимости от различных технологических факторов (влияния консервационной среды, методов подготовки подшипников перед измерением, влияния нагрузки подшипников в процессе измерения и тому подобных). Допустим, нужно сравнить качество подшипников в зависимости от результатов хранения их в разных консервационных маслах. При планировании такого эксперимента возникает вопрос, какие подшипники следует поместить в масло одного состава, а какие — в другое, но так, чтобы избежать субъективизма и обеспечить объективность принимаемого решения. Ответ может быть получен с помощью жребия. Аналогичный пример можно привести и с контролем качества любой продукции. Чтобы решить, соответствует или не соответствует контролируемая партия продукции установленным требованиям, из неё выбирается представительная часть: по этой выборке судят о всей партии. Поэтому желательно, чтобы каждая единица в контролируемой партии имела одинаковую вероятность быть выбранной. В производственных условиях выбор единиц продукции обычно делают не жребием, а по специальным таблицам случайных чисел или с помощью компьютерных датчиков случайных чисел. Похожие проблемы обеспечения объективности сравнения возникают при сопоставлении различных схем организации производства, оплаты труда, при проведении тендеров и конкурсов, подбора кандидатов на вакантные должности. Всюду нужна жеребьёвка или подобные ей меры. Пусть надо выявить наиболее сильную и вторую по силе команду при организации турнира по олимпийской системе (проигравший выбывает). Допустим, что более сильная команда всегда побеждает более слабую. Ясно, что самая сильная команда однозначно станет чемпионом. Вторая по силе команда выйдет в финал только когда до финала у неё не будет игр с будущим чемпионом. Если такая игра запланирована, то вторая по силе команда в финал не попадёт. Тот, кто планирует турнир, может либо досрочно «выбить» вторую по силе команду из турнира, сведя её в первой же встрече с лидером, либо обеспечить ей второе место, обеспечив встречи с более слабыми командами вплоть до финала. Чтобы избежать субъективизма, проводят жеребьёвку. Для турнира из 8 команд вероятность того, что в финале встретятся две самые сильные команды, равна 4 из 7. Соответственно с вероятностью 3 из 7 вторая по силе команда покинет турнир досрочно. При любом измерении единиц продукции (с помощью штангенциркуля, микрометра, амперметра…) имеются погрешности. Чтобы выяснить, есть ли систематические погрешности, необходимо многократно измерить единицы продукции, характеристики которой известны (например, стандартного образца). При этом следует помнить, что кроме систематической погрешности присутствует и случайная погрешность. Встаёт вопрос, как по измерениям выявить систематическую погрешность. Если отмечать только, является ли полученная при очередном измерении погрешность положительной или отрицательной, то эту задачу можно свести к уже́ рассмотренной. Действительно, сопоставим измерение с бросанием монеты: положительную погрешность — с выпадением орла, отрицательную — решки (нулевая погрешность при достаточном числе делений шкалы практически никогда не встречается). Тогда проверка отсутствия систематической погрешности эквивалентна проверке симметричности монеты. Итак, задача проверки на систематическую погрешность сведена к задаче проверки симметричности монеты. Проведённые рассуждения приводят к так называемому «критерию знаков» в математической статистике. При статистическом регулировании технологических процессов на основе методов математической статистики разрабатываются правила и планы статистического контроля процессов, направленные на своевременное обнаружение разладки технологических процессов и принятия мер к их наладке и предотвращению выпуска продукции, не соответствующей установленным требованиям. Эти меры нацелены на сокращение издержек производства и потерь от поставки некачественных единиц продукции. При статистическом приёмочном контроле на основе методов математической статистики разрабатываются планы контроля качества путем анализа выборок из партий продукции. Сложность заключается в том, чтобы уметь правильно строить вероятностно-статистические модели принятия решений. В математической статистике для этого разработаны вероятностные модели и методы проверки гипотез, в частности, гипотез о том, что доля дефектных единиц продукции равна определённому числу 2.1. Задачи оценивания В ряде ситуаций возникают задачи оценки характеристик и параметров распределений вероятностей. Рассмотрим пример. Пусть на контроль поступила партия из Предположим, что при испытании выборки дефектными оказались Или при статистическом анализе точности и стабильности технологических процессов надлежит оценить такие показатели качества, как среднее значение контролируемого параметра и степень его разброса в рассматриваемом процессе. Согласно теории вероятностей в качестве среднего значения случайной величины целесообразно использовать её математическое ожидание, а в качестве статистической характеристики разброса — дисперсию, среднеквадратичное отклонение иликоэффициент вариации. Возникают вопросы: как оценить эти статистические характеристики по выборочным данным и с какой точностью это удаcтся сделать? 2.2. Вероятностно-статистические методы и оптимизация Идея оптимизации пронизывает прикладную математическую статистику и иные статистические методы. А именно, методы планирования экспериментов, статистического приёмочного контроля, статистического регулирования технологических процессов и другие. С другой стороны, оптимизационные постановки в теории принятия решений, например, прикладная теория оптимизации качества продукции и требований стандартов, предусматривают широкое использование вероятностно-статистических методов, прежде всего прикладной математической статистики. В производственном управлении, в частности, при оптимизации качества продукции и требований стандартов особенно важно применять статистические методы на начальном этапе жизненного цикла продукции, этапе научно-исследовательской подготовки опытно-конструкторских разработок (разработка перспективных требований к продукции, аванпроекта, технического задания на опытно-конструкторскую разработку). Это объясняется ограниченностью информации, доступной на начальном этапе жизненного цикла продукции, и необходимостью прогнозирования технических возможностей и экономической ситуации на будущее. Статистические методы должны применяться на всех этапах решения задачи оптимизации: при шкалированиипеременных, разработке математических моделей функционирования изделий и систем, проведении технических и экономических экспериментов и тому подобном. В задачах оптимизации, в том числе оптимизации качества продукции и требований стандартов, используют все области статистики. А именно, статистику случайных величин, многомерный статистический анализ, статистику случайных процессов ивременны́х рядов, статистику объектов нечисловой природы. Разработаны рекомендации по выбору статистического метода для анализа конкретных данных [3]. 3. Построение полигона и гистрограммы 3.1. Полигон При построении полигона на горизонтальной оси (ось абсцисс) откладывают значения варьирующего признака, а на вертикальной оси (ось ординат) — частоты или частости. [5, c. 114] Полигон на рис. 1 построен по данным микропереписи населения России в 2014 г.
 Рис. 1. Распределение домохозяйств по размеру Условие: Приводятся данные о распределении 25 работников одного из предприятий по тарифным разрядам: 4; 2; 4; 6; 5; 6; 4; 1; 3; 1; 2; 5; 2; 6; 3; 1; 2; 3; 4; 5; 4; 6; 2; 3; 4 Задача: Построить дискретный вариационный ряд и изобразить его графически в виде полигона распределения. Решение: В данном примере вариантами является тарифный разряд работника. Для определения частот необходимо рассчитать число работников, имеющих соответствующий тарифный разряд.
Полигон используется для дискретных вариационных рядов. Для построения полигона распределения (рис 2) по оси абсцисс (X) откладываем количественные значения варьирующего признака — варианты, а по оси ординат — частоты или частости.  Рис. 2. Полигон распределения Если значения признака выражены в виде интервалов, то такой ряд называется интервальным. Интервальные ряды распределения изображают графически в виде гистограммы, кумуляты или огивы. Статистическая таблица Условие: Приведены данные о размерах вкладов 20 физических лиц в одном банке (тыс.руб) 60; 25; 12; 10; 68; 35; 2; 17; 51; 9; 3; 130; 24; 85; 100; 152; 6; 18; 7; 42. Задача: Построить интервальный вариационный ряд с равными интервалами. Решение: Исходная совокупность состоит из 20 единиц (N = 20). По формуле Стерджесса определим необходимое количество используемых групп: n=1+3,322*lg20=5 Вычислим величину равного интервала: i=(152 — 2) /5 = 30 тыс.руб Расчленим исходную совокупность на 5 групп с величиной интервала в 30 тыс.руб. Результаты группировки представим в таблице:
При такой записи непрерывного признака, когда одна и та же величина встречается дважды (как верхняя граница одного интервала и нижняя граница другого интервала), то эта величина относится к той группе, где эта величина выступает в роли верхней границы. 3.2. Гистограмма Для построения гистограммы по оси абсцисс указывают значения границ интервалов и на их основании строят прямоугольники, высота которых пропорциональна частотам (или частостям). [4, c. 28] На рис. 3. изображена гистограмма распределения населения России в 1997 г. по возрастным группам.
 Рис. 3. Распределение населения России по возрастным группам Условие: Приводится распределение 30 работников фирмы по размеру месячной заработной платы
Задача: Изобразить интервальный вариационный ряд графически в виде гистограммы и кумуляты. Решение: Неизвестная граница открытого (первого) интервала определяется по величине второго интервала: 7000 — 5000 = 2000 руб. С той же величиной находим нижнюю границу первого интервала: 5000 — 2000 = 3000 руб. Для построения гистограммы в прямоугольной системе координат по оси абсцисс откладываем отрезки, величины которых соответствуют интервалам варицонного ряда. Эти отрезки служат нижним основанием, а соответствующая частота (частость) — высотой образуемых прямоугольников. Построим гистограмму: 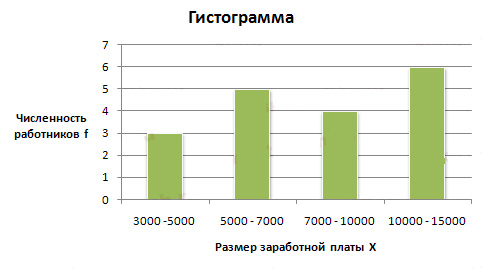 Рис. 4. Гистограмма Для построения кумуляты необходимо рассчитать накопленные частоты (частости). Они определяются путем последовательного суммирования частот (частостей) предшествующих интервалов и обозначаются S. Накопленные частоты показывают, сколько единиц совокупности имеют значение признака не больше, чем рассматриваемое. Заключение Математическая статистика как наука начинается с работ Карла Фридриха Гаусса, на основе теории вероятностей исследовавшего и обосновавшего метод наименьших квадратов, созданный им в 1795 году и применённый для обработки астрономических данных (с целью уточнения орбиты карликовой планеты Церера). Его именем часто называют одно из наиболее популярных распределений вероятностей — нормальное, а в теории случайных процессов основной объект изучения —гауссовские процессы. В 30-е годы ХХ века поляк Ежи Нейман (1894—1977) и англичанин Эгон Пирсон развили общую теорию проверки статистических гипотез, а советские математики Андрей Николаевич Колмогоров (1903—1987) и Николай Васильевич Смирнов (1900—1966) заложили основы непараметрической статистики. В 40-е годы ХХ века румын Авраам Вальд (1902—1950) построил теорию последовательного статистического анализа. Математическая статистика бурно развивается и ныне. За последние 40 лет можно выделить четыре принципиально новых направления исследований: Разработка и внедрение математических методов планирования экспериментов; Развитие статистики объектов нечисловой природы как самостоятельного направления в прикладной математической статистике; Развитие статистических методов, устойчивых по отношению к малым отклонениям от используемой вероятностной модели; Широкое развёртывание работ по созданию компьютерных пакетов программ, предназначенных для проведения статистического анализа данных. Список литературы Горлач, Б.А. Теория вероятностей и математическая статистика: Учебное пособие / Б.А. Горлач. - СПб.: Лань, 2013. - 320 c. Калинина, В.Н. Теория вероятностей и математическая статистика: Учебник для бакалавров / В.Н. Калинина. - М.: Юрайт, 2013. - 472 c. Лебедев, А.В. Теория вероятностей и математическая статистика: Учебное пособие / Л.Н. Фадеева, А.В. Лебедев; Под ред. проф. Л.Н. Фадеева. - М.: Рид Групп, 2011. - 496 c. Павлов, С.В. Теория вероятностей и математическая статистика: Учебное пособие / С.В. Павлов. - М.: ИЦ РИОР, ИНФРА-М, 2010. - 186 c. Семенов, В.А. Теория вероятностей и математическая статистика: Учебное пособие / В.А. Семенов. - СПб.: Питер, 2013. - 192 c. Чашкин, Ю.Р. Математическая статистика. Анализ и обработка данных: Учебное пособие / Ю.Р. Чашкин; Под ред. С.Н. Смоленский. - Рн/Д: Феникс, 2010. - 236 c. |