вопросы по курсу. Вопросы по курсу Защита информации
 Скачать 1.23 Mb. Скачать 1.23 Mb.
|

|
Статическая биометрия Статические методы идентификации основаны на анализе неизменных физиологических характеристик человека. В число этих характеристик входят: отпечатки пальцев (на использовании этих идентификаторов строится самая распространенная, удобная и эффективная биометрическая технология); форма и геометрия лица (с этими идентификаторами работают технологии распознавания двумерных изображений лиц, черпаемых из фотографий и видеоряда); форма и строение черепа (для большей благозвучности компании, действующие в данной сфере, предпочитают говорить о технологиях распознавания человека по трехмерной модели лица); сетчатка глаза (практически не используется в качестве идентификатора); радужная оболочка глаза (распространение технологии, в которой применяется данный идентификатор, сдерживается патентными ограничениями); геометрия ладони, кисти руки или пальца (используется в нескольких узких сегментах рынка); термография лица, термография руки (основанные на использовании этих идентификаторов технологии не получили распространения); рисунок вен на ладони или пальце руки (соответствующая технология становится популярной, но ввиду дороговизны сканеров пока не используется широко); ДНК (в основном в сфере специализированных экспертиз); запах тела (автоматических систем распознавания человека, использующих данный идентификатор, еще не создано); форма уха (автоматических систем распознавания человека, использующих данный идентификатор, еще не создано). Динамическая биометрия Динамические методы идентификации основываются на анализе поведенческих характеристик личности — особенностей, присущих каждому человеку в процессе воспроизведения какого-либо действия. Динамические методы существенно уступают статическим в точности и эффективности и, как правило, используются в качестве вспомогательных. Применяемые идентификаторы: динамика подписи; динамика клавиатурного набора; голос; движение губ; походка; особенности начертания рукописного текста. Биометрические системы защиты информации Биометрические системы защиты информации - системы контроля доступа, основанные на идентификации и аутентификации человека по биологическим признакам, таким как структура ДНК, рисунок радужной оболочки глаза, сетчатка глаза, геометрия и температурная карта лица, отпечаток пальца, геометрия ладони. Также эти методы аутентификации человека называют статистическими методами, так как основаны на физиологических характеристиках человека, присутствующих от рождения и до смерти, находящиеся при нем в течение всей его жизни, и которые не могут быть потеряны или украдены. Часто используются еще и уникальные динамические методы биометрической аутентификации - подпись, клавиатурный почерк, голос и походка, которые основаны на поведенческих характеристиках людей. Суть биометрических систем сводится к использованию компьютерных систем распознавания личности по уникальному генетическому коду человека. Биометрические системы безопасности позволяют автоматически распознавать человека по его физиологическим или поведенческим характеристикам. Описание работы биометрических систем: Все биометрические системы работают по одинаковой схеме. Вначале, происходит процесс записи, в результате которого система запоминает образец биометрической характеристики. Некоторые биометрические системы делают несколько образцов для более подробного запечатления биометрической характеристики. Полученная информация обрабатывается и преобразуется в математический код. Биометрические системы информационной безопасности используют биометрические методы идентификации и аутентификации пользователей. Идентификация по биометрической системы проходит в четыре стадии: Регистрация идентификатора - сведение о физиологической или поведенческой характеристике преобразуется в форму, доступную компьютерным технологиям, и вносятся в память биометрической системы; Выделение - из вновь предъявленного идентификатора выделяются уникальные признаки, анализируемые системой; Сравнение - сопоставляются сведения о вновь предъявленном и ранее зарегистрированном идентификаторе; Решение - выносится заключение о том, совпадают или не совпадают вновь предъявленный идентификатор. Заключение о совпадении/несовпадении идентификаторов может затем транслироваться другим системам (контроля доступа, защиты информации и т. д), которые далее действуют на основе полученной информации. Способы обеспечения надежности биометрических систем Одна из самых важных характеристик систем защиты информации, основанных на биометрических технологиях, является высокая надежность, то есть способность системы достоверно различать биометрические характеристики, принадлежащие разным людям, и надежно находить совпадения. В биометрии эти параметры называются ошибкой первого рода (False Reject Rate, FRR) и ошибкой второго рода (False Accept Rate, FAR). Первое число характеризует вероятность отказа доступа человеку, имеющему доступ, второе - вероятность ложного совпадения биометрических характеристик двух людей. Подделать папиллярный узор пальца человека или радужную оболочку глаза очень сложно. Так что возникновение "ошибок второго рода" (то есть предоставление доступа человеку, не имеющему на это право) практически исключено. Однако, под воздействием некоторых факторов биологические особенности, по которым производится идентификация личности, могут изменяться. Например, человек может простудиться, в результате чего его голос поменяется до неузнаваемости. Поэтому частота появлений "ошибок первого рода" (отказ в доступе человеку, имеющему на это право) в биометрических системах достаточно велика. Система тем лучше, чем меньше значение FRR при одинаковых значениях FAR. Иногда используется и сравнительная характеристика EER (Equal Error Rate), определяющая точку, в которой графики FRR и FAR пересекаются. Но она далеко не всегда репрезентативна. При использовании биометрических систем, особенно системы распознавания по лицу, даже при введении корректных биометрических характеристик не всегда решение об аутентификации верно. Это связано с рядом особенностей и, в первую очередь, с тем, что многие биометрические характеристики могут изменяться. Существует определенная степень вероятности ошибки системы. Причем при использовании различных технологий ошибка может существенно различаться. Для систем контроля доступа при использовании биометрических технологий необходимо определить, что важнее не пропустить "чужого" или пропустить всех "своих". 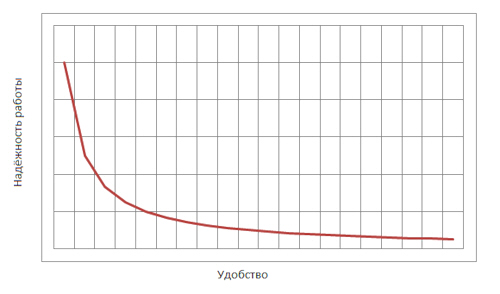 Рис. 2. График зависимости надежности системы от удобства использования Не только FAR и FRR определяют качество биометрической системы. Если бы это было только так, то лидирующей технологией было бы распознавание людей по ДНК, для которой FAR и FRR стремятся к нулю. Но ведь очевидно, что эта технология не применима на сегодняшнем этапе развития человечества. Поэтому важной характеристикой является устойчивость к муляжу, скорость работы и стоимость системы. Не стоит забывать и то, что биометрическая характеристика человека может изменяться со временем, так что если она неустойчива - это существенный минус. Также важным фактором для пользователей биометрических технологий в системах безопасности является простота использования. Человек, характеристики которого сканируются, не должен при этом испытывать никаких неудобств. В этом плане наиболее интересным методом является, безусловно, технология распознавания по лицу. Правда, в этом случае возникают иные проблемы, связанные в первую очередь, с точностью работы системы. Алгоритм распознавания голоса Метод идентификации диктора на основе вычисления акустических параметров речи с помощью метода Мел-кепстральных коэффициентов (MFCC - Mel-frequency cepstrum coefficients) является наиболее популярным способом, так как MFCC можно применять на зашумленных/телефонных записях, а также, потому что MFCC вектора не подтверждены влиянию эмоционального состояния диктора. Основной идеей метода MFCC является максимальное приближение информации, поступающей на вход системы, к информации, поступающей на слуховой анализатор мозга человека. Вначале происходит предварительная обработка звука: нормализация входного набора данных - амплитуд сигнала. Нормализация необходима для приведения частотных характеристик в более общий вид, так как внешние шумы и разная громкость сигнала могут приводить к большим изменениям в амплитуде сигнала. Один из возможных методов нормализации является деление значений амплитуд на максимальное (в рамках данного сигнала) значение. После обработки данных происходит деление звукового сигнала на кадры - отрезки некоторой длины (увеличение длины кадра повышает точность работы алгоритма, понижение длины кадра повышает скорость работы алгоритма). Для каждого кадра применяется дискретное преобразование Фурье, чтобы получить кратковременную спектрограмму кадра: 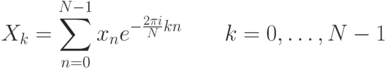 Затем полученные в результате дискретного преобразования Фурье коэффициенты умножаются на амплитудно-частотные характеристики треугольных фильтров, центральные частоты которых равномерно распределённые по мел-шкале. 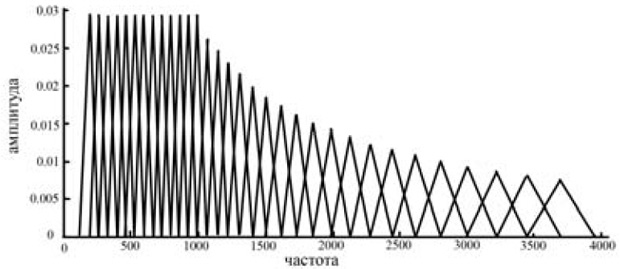 Рис. 9. Блок фильтров одинаковой площади, распределенных по мел-шкале На рисунке показаны первые 32 фильтра, которые покрывают диапазон частот 133-3954 Гц. Частотные центры первых тринадцати из них распределены по линейному закону в диапазоне 200-1000 Гц, а следующие 19 распределены логарифмически. Это связано с особенностями восприятия человеческого уха. Мел-шкала была получена в результате экспериментов, таким образом, чтобы наиболее точно моделировать чувствительность человеческого уха. Вычисление мел-значений можно приблизительно представить следующей формулой:  Каждый из фильтров определяется по формуле: 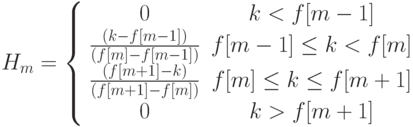 Для которой частоты 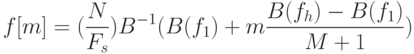 Где После этого можно вычислить энергию для каждого кадра: 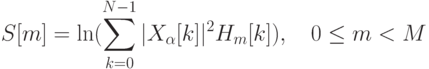 Применяя дискретное косинусное преобразование, получаем финальный вектор признаков (они же мел-кепстральные коэффициенты) для кадра, 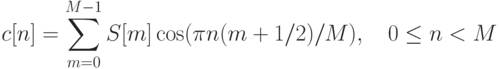 Последней стадией является классификация диктора. Классификация производится вычислением меры схожести пробных данных и уже известных. Мера схожести выражается расстоянием от вектора признаков пробного сигнала до вектора признаков уже классифицированного. Например, можно использовать следующую метрику: 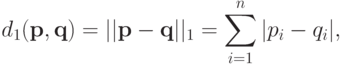 Если минимальное расстояние меньше некоторого порога, то считается, что диктор распознан. Алгоритм распознавания по лицу Для решения задачи распознавания объектов (в данном контексте под объектом понимается лицо человека) построено множество методов, которые сильно отличаются друг от друга по требованиям к настройке метода на базу объектов, входным данным, скорости работы и др. При этом сущность процесса распознавания в различных методах остается одной и той же. Соотнесение распознаваемого объекта с базой объектов, которые необходимо идентифицировать, проходит в три этапа: выделение того или иного признака объекта; объединение признаков в комплексы или классы; выбор предполагаемого значения из ряда альтернатив. Существует целый ряд методов идентификации лиц таких, как метод главных компонент, линейный дискриминантный анализ, сравнение эластичных графов, анализ антропометрических характеристик, неокогнитрон, скрытые Марковские модели. Проведем сопоставление перечисленных методов с процессом визуального распознавания. В методе главных компонентов признаками объекта являются главные компоненты, т. е. линейные коэффициенты, вычисленные на основе собственных векторов лицеподобной формы. Первые n главных компонентов формируют представление в собственном пространстве, соответствующее отдельному объекту. Для сравнения набора компонентов, которые относятся к наблюдаемому объекту, с хранящимися в памяти наборами главных компонентов для других объектов используются методы сравнения такие, как метрики различного вида, нейронные сети (радиально-базисные, карты Конохена) и т.д. Конкретизация метода сравнения зависит от требуемой скорости вычислений, необходимого качества распознавания изображений лиц и поддерживаемых мощностей оборудования. Использование собственных векторов в методе главных компонентов отражает такую особенность человеческого распознавания, как фиксация на градациях изображения, при этом сами по себе вектора являются неким подобием гештальтов. Данный подход требует жестко фиксированных условий для изображений объекта, так как иначе будет невозможно сопоставить ему построенные по базе объектов собственные вектора. В методе линейного дискриминантного анализа объект представляется как проекция на пространство признаков, в котором базисные дискриминантные вектора близки по виду собственным в методе главных компонентов. При этом проекция выбирается для каждого объекта таким образом, чтобы обособить его от остальных объектов. Проецирование распознаваемого объекта, находящегося в пространстве изображений, на пространство признаков осуществляется с помощью линейного дискриминанта. Основное требование метода - возможность линейно разделить проекции, однако в общем случае данное условие может не выполняться, и метод станет выдавать ошибку. Линейный дискриминантный анализ так же как и метод главных компонентов, учитывает градации изображения лица, в связи с этим для обеспечения работы метода при изменяющихся условиях освещения необходимо использовать предобработку изображения, приводящую его к заданным стандартным условиям. Эластичные графы используются в методе распознавания лиц, где признаками идентифицируемого объекта являются вершины графа, расположенные на контурах головы, губ, глаз и др. В каждой вершине вычисляется джет, т.е. набор определенных заранее коэффициентов Габоровых функций, и конкретному лицу соответствует отдельная совокупность джетов для различных областей на лице. Тогда, если необходимо провести сравнение лиц, достаточно сопоставить джеты с использованием функции подобия для сравнения графов. Идея, лежащая в основе метода эластичных графов, напоминает такую особенность визуального распознавания, как движение глаза от одной точки объекта к другой, при этом в рассматриваемом методе не учитываются возможные градации изображения. Даже при использовании коэффициентов важности для джетов эластичные графы будут сравнивать лица лишь с помощью вычисления взвешенных геометрических искажений объекта, а большой объем информации, содержащейся в изменении оттенков цвета на коже лица, остается без внимания. Следует особо отметить такой метод идентификации, как анализ антропометрических характеристик, в котором в качестве признаков используются расстояния между уголками глаз, губ, центрами глаз или их отношения, сходные с вершинами графа в эластичных графах. В дальнейшем они группируются как известный набор ключевых точек или областей лицах, причем наиболее информативные признаки и их весовые коэффициенты выбираются экспериментально с привлечением различных математических методов. Сформированный для распознаваемого лица набор признаков сравнивается с базой, содержащей наборы для других лиц, с помощью методов сравнения количественных характеристик таких, как метод k ближайших соседей или многослойный персептрон. При сопоставлении метода на основе антропометрических характеристик с визуальным распознаванием можно заметить, что подобно сравнению эластичных графов, этот метод переносит в автоматическую идентификацию объектов последовательный обход "псевдоглазом" ключевых точек объекта. При этом необходимо иметь в виду, что для корректного анализа антропометрических характеристик предварительно устраняются те элементы на лице, которые вносят неточности при идентификации объекта. В неокогнитроне признаками объекта являются простые образы (линии и образованные ими углы), формирующие совокупность узлов неокогнитрона для каждого объекта из подготовленной базы объектов при различных уровнях абстракции данных в процессе обучения нейронной сети. В результате неокогнитрон, настроенный на конкретную базу объектов, последовательно сравнивает группу признаков для распознаваемого объекта с заложенными при обучении совокупностями признаков для объектов из базы. Все особенности визуального распознавания в том или ином виде отражаются в неокогнитроне, и его можно назвать наиболее эффективным для распознавания методом, если бы не большие вычислительные затраты для обеспечения достаточной скорости распознавания, требующие применение нейрокомпьютеров. Из-за этого на современном уровне развития вычислительной техники широкое использование неокогнитрона затруднительно. Для метода "скрытые Марковские модели" признаками идентифицируемого объекта являются последовательности наблюдений объекта. Каждому объекту соответствует своя Марковская модель - набор состояний системы. При распознавании объекта проверяются сгенерированные для заданной базы объектов Марковские модели и ищется максимальная из наблюдаемых вероятность того, что последовательность наблюдений для данного объекта сгенерирована соответствующей моделью. Скрытые Марковские модели вобрали в себя все вышеперечисленные особенности человеческого восприятия и распознавания. При этом они не требуют больших вычислительных мощностей и позволяют менять состав сформированной базы без изменения всей совокупности настроенных Марковских моделей, хотя размер базы объектов, для которых обеспечивается корректное распознавание этим методом, ограничен. Анализ рассмотренных методов показывает, что они сформированы аналогично процессу визуального восприятия. При этом ни один из этих методов не достигает точности распознавания человеком, хотя и приближается к ней. Алгоритм распознавания радужки глаза человека Данный метод в качестве идентификатора использует уникальный рисунок кровеносных сосудов глазного дна. Сканирование происходит с помощью инфракрасного излучения низкой интенсивности, которое направляется через зрачок к задней стенке глаза. Система контроля доступа на основе сканирования сетчатки глаза отличается высокой надежностью, используется на особо охраняемых объектах, в силу того, что биометрические СКУД по сетчатке глаза имеют самый низкий коэффициент FRR и практически не бывает ошибочного отказа в доступе (FAR). Алгоритм распознавания по отпечаткам пальцев. |