доклад мультимедийные системы. дамов. Введение 1 Некоторые Важные Определения 1 Типы носителей и мультимедиа 2 Базы данных и субд
 Скачать 349.27 Kb. Скачать 349.27 Kb.
|

|
Глава 1 Введение 1.1 Некоторые Важные Определения 1.1.1 Типы носителей и мультимедиа 1.1.2 Базы данных и СУБД 1.1.3 Поиск информации в Текстовом Документе 1.1.4 Мультимедийное индексирование и поиск 1.1.5 Извлечение объектов, представление контента и индексация 1.2 Потребность в MIRS 1.2.1 Распространение мультимедийных данных и их характеристики 1.2.2 СУБД и их роль в обработке мультимедийных данных 1.2.3 ИК-системы и их роль в поиске мультимедиа 1.2.4 Комплексный подход к индексации мультимедийной информации и Поиск 1.3 Обзор мультимедийной системы индексации и поиска 1.4 Ожидаемые возможности и общие области применения MIRS 1.5 Организация последующих глав Проблемы Рекомендации ВВЕДЕНИЕ Несколько лет назад основное внимание в исследованиях и разработках мультимедиа уделялось мультимедийным коммуникациям, а также созданию и презентации мультимедиа. Поскольку захватывается все больше и больше цифровых мультимедийных данных в виде изображений, видео и аудио и сохраненный, в последние несколько лет акцент сместился на эффективное хранение и извлечение мультимедийной информации. Аналогичная ситуация произошла около тридцати лет назад, когда все больше и больше буквенно-цифровых данных хранилось в машиночитаемой форме, это привело к развитию систем управления базами данных (СУБД), которые сейчас являются одним из самых популярных компьютерных приложений и используются практически в каждой организации. Из-за различий между характеристиками и требованиями к буквенно-цифровым данным и мультимедийные данные, традиционная СУБД не способна эффективно обрабатывать мультимедийные данные. Таким образом, требуются новые мультимедийные методы индексации и поиска. Эта книга содержит всестороннее освещение проблем и современных технологий в области управления мультимедийными базами данных. Она начинается с обсуждения основных характеристик и требований к мультимедийным данным. Затем в нем описываются общие вопросы проектирования систем управления базами данных multime-dia для удовлетворения этих характеристик и требований. Мы обсуждаем методы индексации и извлечения текстовых документов, аудио, изображений и видео. Общим для этих методов является то, что все они пытаются извлечь основные характеристики из необработанных медиаданных, а затем попытаться извлечь элементы, относящиеся к запросу пользователя , на основе сходства или расстояния между извлеченными векторами признаков сохраненных элементов и запроса, поскольку несколько типов носителей обычно отображаются вместе в мультимедийных объектах или документах, где различные методы фиксируют различные их функции или содержимое, мы обсуждаем, как интегрировать различные методы индексации и поиска для эффективного извлечение мультимедийных документов, поскольку объекты, извлеченные из необработанных мультимедийных данных , обычно представлены многомерными векторами, было бы очень трудоемко вычислять сходство между вектором признаков запроса и вектором признаков каждого из сохраненных элементов. Мы обсуждаем различные методы и структуры данных, чтобы поиск и извлечение могли осуществляться эффективно. Доступ к мультимедийным базам данных обычно осуществляется удаленно по сети. Мультимедийные объекты, идентифицированные как относящиеся к запросу, должны быть извлечены с сервера и переданыted клиенту для презентации. Для обеспечения бесперебойной и своевременной мультимедийной презентации необходимо выполнить ряд требований, связанных с такими факторами, как задержка и дрожание задержки, называемое качеством обслуживания . Мы описываем компьютерную архитектуру, мультимедийное хранилище, операционную систему и сетевую поддержку, чтобы соответствовать этим требованиям. В традиционных СУБД основной проблемой производительности является эффективность (сколько времени требуется для ответа на запрос). В системах управления мультимедийными базами данных (MMDBMSs) эффективность также важна. Кроме того, эффективность поиска (способность извлекать соответствующие-нужные элементы и способность отклонять нерелевантные элементы) становится важным. Это потому что MMDBMSs извлекают элементы на основе сходства, измеренного с использованием показателя сходства, а не точного соответствия, поскольку трудно извлечь все характеристики мультимедийных элементов и дизайна метрика сходства, которая точно соответствует человеческому суждению, вполне вероятно, что некоторые элементы, определенные системой как релевантные, на самом деле считаются пользователем нерелевантными, а некоторые релевантные элементы не извлекаются. Таким образом, мы также обсуждаем вопросы измерения производительности в MMDBMSs. Наконец, мы кратко опишем текущие продукты, разработку приложений и другие вопросы, такие как безопасность и стандартизация. Эта книга предназначена для следующих групп читателей: • Студенты старших курсов университетов и аспиранты, многие университеты по всему миру начали или начнут предлагать предметы, связанные с мультимедийными технологиями и MMDBMS. Эта книга служит учебным пособием по таким предметам. • Системные дизайнеры и разработчики, которые хотят изучить различные вопросы и методы разработки мультимедийных систем управления базами данных. • Исследователи, которые хотят ознакомиться с текущими разработками и новыми направлениями исследований в MMDBMSs. • Другие специалисты, которые хотят знать технические проблемы и текущее состояние MMDBMSs. Я хотел бы поблагодарить адъюнкт-профессора Боба Бигналла за его постоянную поддержку-наставления и поддержку, а также за вычитку всех глав для меня. Я благодарю Темплара Хэнкинсона за подготовку трех графиков в главе 5, а также Деншэн Чжана и Ши Вэй Тенга за исправление некоторых ошибок в оригинальной рукописи. Я также хотел бы поблагодарить своих коллег и друзей из Гиппслендской школы вычислительной техники и информационных технологий Университета Монаш за их поддержку в течение последних трех лет. Доктор Илиас Петруниас из UMIST в Мачестере, Великобритания, рецензировал книгу и предоставил много полезных комментариев и предложений, за которые я очень благодарен. Я посвящаю эту книгу моей жене Фэнся, сыновьям Джеймсу и Колину, без чьей поддержки и понимания написание этой книги было бы невозможно. Глава 1 Вступление Первоначальное внимание в исследованиях и разработках мультимедиа было сосредоточено на мультимедийных коммуникациях, а также на создании и презентации мультимедиа [1-4]. За последние несколько лет все больше и было захвачено и сохранено больше цифровых мультимедийных данных в виде изображений, видео и аудио . В настоящее время существует большой исследовательский интерес к эффективному хранению и извлечению мультимедийной информации. Аналогичная ситуация произошла около тридцати лет назад , когда все больше и больше буквенно-цифровых данных хранилось в машиночитаемой форме. Это привело к разработке систем управления базами данных (СУБД), которые в настоящее время являются одним из самых популярных компьютерных приложений и используются практически в каждой организации. Однако СУБД не могут эффективно обрабатывать мультимедийные данные из-за различий между характеристиками буквенно-цифровых данных и мультимедийных данных. Поэтому требуются новые мультимедийные методы индексации и поиска. 20 Основная цель этой книги - описать проблемы и современные технологии в области индексации и поиска мультимедиа. Область мультимедийного индексирования и поиска все еще находится на ранней стадии развития. Но ожидается, что мультимедийные системы управления базами данных (MMDBMSs) в ближайшем будущем будут столь же популярны, как и современные СУБД [5-7]. В этой главе сначала определяются некоторые важные термины и концепции, используемые во всем книга и объясняет, почему традиционные СУБД не могут обрабатывать мультимедийную информацию и почему требуются новые технологии для поддержки эффективного поиска мультимедийной информации. Затем в нем дается обзор мультимедийных систем индексации и поиска (МИРСс). Представлены некоторые ожидаемые возможности и общие области применения MIRSs. Глава завершается кратким описанием организации следующих глав. 1.1 НЕКОТОРЫЕ ВАЖНЫЕ ОПРЕДЕЛЕНИЯ Чтобы избежать путаницы или недопонимания, в этом разделе приведены определения некоторых важных терминов и концепций, используемых в этой книге. 1.1.1 Типы носителей и мультимедиа Средства массовой информации относятся к типам информации или типам представления информации, таким как буквенно-цифровые данные, изображения, аудио и видео. Существует много способов классификации медиа. Общепринятые классификации основаны на физических форматах и взаимосвязи носителей со временем. В этой книге мы классифицируем медиа в зависимости от того, существуют ли у них временные измерения . Это соглашение приводит к двум классам сред: статическим и динамическим (или непрерывным во времени ). Статичные медиа не имеют временного измерения, а их содержание и значения не зависит от времени презентации. Статические носители включают буквенно-цифровые данные, графику и неподвижные изображения. 20 Динамические медиа имеют временные измерения, и их значение и корректность зависят от скорости, с которой они представлены. Динамические носители включают анимацию, аудио и видео. Эти носители имеют свои собственные единичные интервалы или скорости. Например, чтобы передать плавное движение, видео должно воспроизводиться со скоростью 25 кадров в секунду (или 30 кадров, в зависимости от используемой видеосистемы). Аналогично, когда мы воспроизводим записанное голосовое сообщение или музыка, только одна скорость воспроизведения является естественной или разумной. Воспроизведение в более медленном или быстром темпе искажает смысл или качество звука. Поскольку эти носители должны воспроизводиться непрерывно с фиксированной скоростью, их часто называют непрерывными носителями. Их также называют изохронными носителями из-за фиксированной взаимосвязи между каждой единицей носителя и временем. Мультимедиа относится к набору типов носителей, используемых вместе. Подразумевается, что по крайней мере один тип носителя не является буквенно-цифровыми данными (т.Е. По крайней мере одним типом носителя является изображение, аудио или видео). В этой книге "мультимедиа" используется как прилагательное, поэтому мы будем конкретно говорить "мультимедийная информация", "мультимедийные данные", "мультимедийная система", "мультимедийные коммуникации", "мультимедийные приложения" и так далее. Мультимедийные данные относятся к машиночитаемое представление нескольких типов носителей. Мультимедийная информация относится к информации, передаваемой несколькими типами носителей. Иногда мультимедийная информация и мультимедийные данные используются взаимозаменяемо. Иногда мы используем мультимедиа или медиа-элемент и объект для обозначения любого автономного объекта в MIRS, который может быть запрошен, извлечен и представлен. Термин "объект" может быть неправильно определен в техническом объектно-ориентированном (OO) смысле. Контекст должен прояснять, используется ли он в общем смысле или относится к правильно определенному объекту в подходе OO. 1.1.2 Базы данных и СУБД В литературе базы данных и СУБД иногда используются взаимозаменяемо, в этой книге база данных относится к коллекции или хранилищу данных или элементов мультимедиа. Мы используем СУБД для обозначения всей системы, которая управляет базой данных. 1.1.3 Поиск информации в Текстовом Документе Автоматизированные системы поиска информации (ИК) были разработаны для того, чтобы помочь управлять огромным объемом научной литературы, которая была создана с 1940-х годов [8, 9). Основная функция ИК-системы заключается в хранении большого количества текстовых документов и управлении ими в способ, позволяющий быстро извлекать документы, относящиеся к запросам пользователей. Обратите внимание, что аббревиатура IR конкретно относится к извлечению текстовых документов, хотя полный термин "извлечение информации" может относиться к извлечению любого типа информации. Мы обсудим ИК-технологии в главе 4. 1.1.4 Мультимедийное индексирование и поиск СУБД извлекают элементы на основе структурированных данных, используя точное сопоставление. IR также называется поиском на основе текста. Поиск на основе контента относится к поиску, основанному на фактических характеристиках носителя , таких как цвет и форма, вместо текстовой аннотации элемента носителя. Поиск на основе содержимого обычно основан на сходстве, а не на точном совпадении между запросом и набором элементов базы данных. MIRS относится к базовой системе, обеспечивающей поиск мультимедийной информации с использованием комбинации СУБД, ИК и методов поиска на основе контента. В MIRS некоторые проблемы, такие как управление версиями и контроль безопасности, могут быть реализованы не полностью, полноценная MIRS называется мультимедийной СУБД (MMDBMS). 1.1.5 Извлечение объектов, представление контента и индексация 20 В MIRSs одним из наиболее важных вопросов является извлечение функций или представление контента (каковы основные функции или содержимое в мультимедийном элементе). Извлечение признаков может быть автоматический или полуавтоматический процесс. В некоторой поисковой литературе, основанной на содержании. извлечение объектов также называется индексацией. В этой книге мы следуем этому соглашению. Когда термин "индекс" используется как существительное, он относится к структуре данных или к организации извлеченных объектов для эффективного поиска. 1.2 ПОТРЕБНОСТЬ В MIRS 22 Необходимость в MIRS может быть объяснена следующими тремя фактами. Во-первых, захватывается и хранится все больше и больше мультимедийных данных. Для того, чтобы использовать информацию, содержащуюся в этих данных требуется эффективная и действенная система индексации и поиска. Во-вторых, мультимедийные данные обладают особыми характеристиками и требованиями, которые существенно отличаются от буквенно-цифровых данных. Таким образом, традиционная СУБД не подходит для обработки мультимедийных данных, в-третьих, хотя ИК-технологии могут помочь в поиске мультимедиа, сами по себе они недостаточны для эффективной обработки мультимедийных данных. 1.2.1 Распространение мультимедийных данных и их характеристики В настоящее время мы сталкиваемся со взрывом мультимедийной информации. Например, a большое количество изображений и видео создается и хранится в Интернете, Многие картины и рисунки в печатной форме преобразуются в цифровую форму для быстрой обработки, распространения и сохранения, Изображения из телевизионных новостей и газет также преобразуются в цифровую форму для удобства обслуживания и сохранения. Большой каждый день снимается большое количество медицинских изображений, и спутники делают еще больше. Эта тенденция сохранится с развитием систем хранения данных и цифровых технологий. Однако создание простого хранилища для этого постоянно растущего объема мультимедийной информации имеет мало смысла. Будет невозможно в полной мере использовать это мультимедиа информация, если она не организована для быстрого поиска по запросу. Не только увеличивается объем хранимых данных, но и типы данных и их характеристики отличаются от буквенно-цифровых данных. Мы обсудим различные типы носителей и их характеристики в главе 2. Ниже мы перечислим основные характеристики мультимедийных данных : Мультимедийные данные, особенно аудио и видео, требуют большого объема данных. Например. для 10-минутного видеоряда приемлемого качества требуется около 1,5 ГБ памяти без сжатия. • Аудио и видео имеют временное измерение, и они должны воспроизводиться с фиксированной скоростью для достижения желаемого эффекта. Цифровые аудио, изображения и видео представлены в виде отдельных выборочных значений и не имеют очевидной семантической структуры, позволяющей компьютерам автоматически распознавать содержимое. Многие мультимедийные приложения требуют одновременного представления нескольких типов мультимедиа скоординированным в пространстве и времени способом. • Значение мультимедийных данных иногда бывает нечетким и субъективным, например, разные люди могут интерпретировать одну и ту же картинку совершенно по-разному. Мультимедийные данные богаты информацией. Для адекватного представления его содержания требуется множество параметров . 1.2.2 СУБД и их роль в обработке мультимедийных данных СУБД в настоящее время хорошо развиты и широко используются для структурированных данных. Доминирующий СУБД - это системы управления реляционными базами данных (RDBMSs). В СУБД информация организована в виде таблиц или связей. Строки таблицы соответствуют информационному элементу или записям, в то время как столбцы соответствуют атрибутам. Язык структурированных запросов (SQL) используется для создания таких таблиц, а также для вставки и извлечения информации из них. Мы используем простой пример, чтобы показать, как использовать SQL для создания таблицы, вставки и извлечения из нее информации. Предположим, мы хотим создать таблицу, содержащую записи о студентах , состоящие из номера студента, имени и адреса. Используется следующее утверждение: создать таблицу STUDENT ( stu# integer, имя char(20), адрес char(100) ): Приведенная выше инструкция создает пустую таблицу, как показано в таблице 1.1. Когда мы хотим вставить записи учащихся в таблицу, мы используем команду SQL insert следующим образом: вставить в значения УЧАЩИХСЯ (10, "Лью, Том", "2 Main St., Черчилль, Австралия"); Приведенная выше инструкция вставит строку в таблицу STUDENT, как показано в таблице 1.2. Другие записи учащихся могут быть вставлены в таблицу с использованием аналогичных инструкций. 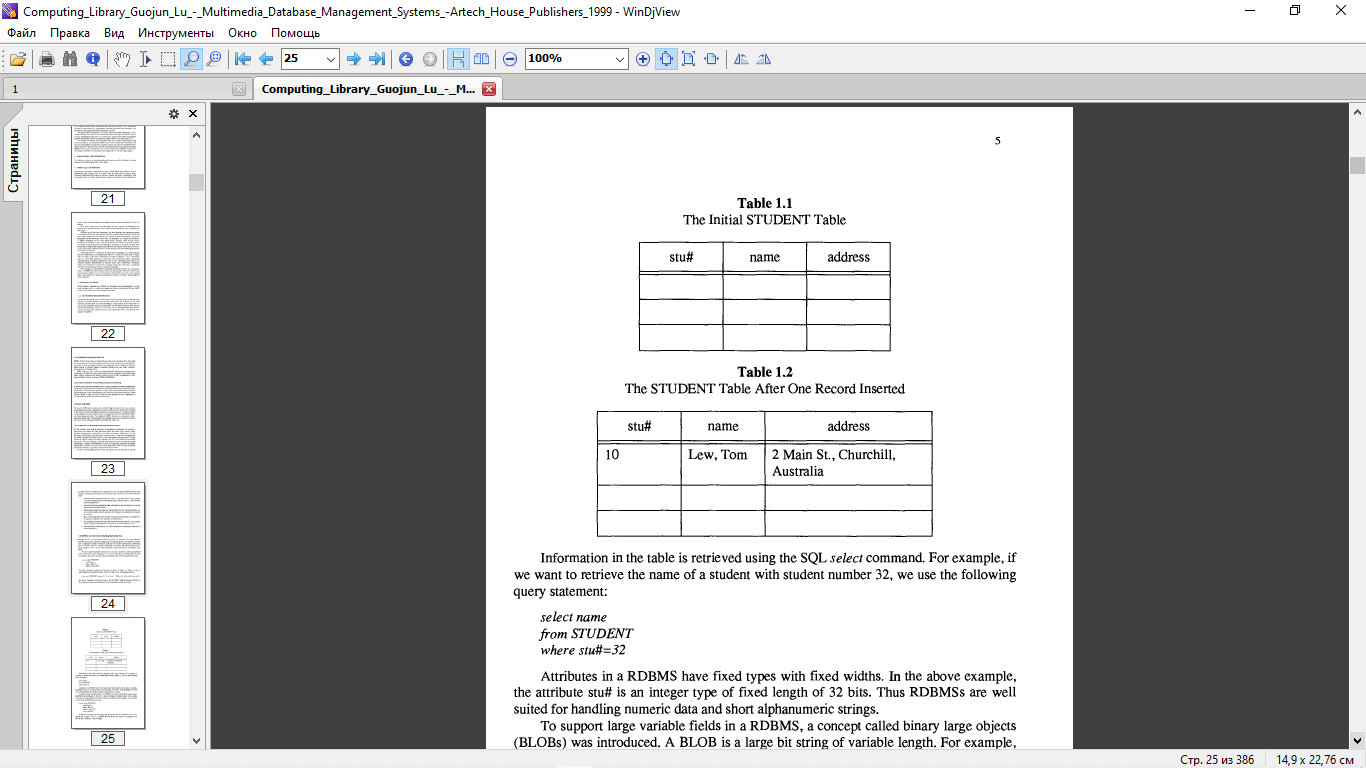 Информация в таблице извлекается с помощью команды SQL select, например, если мы хотим получить имя студента с номером студента 32, мы используем следующее оператор запроса: выберите имя у СТУДЕНТА , где stu#=32 Атрибуты в СУБД имеют фиксированные типы с фиксированной шириной. В приведенном выше примере атрибут stu# представляет собой целочисленный тип фиксированной длины в 32 бита. Таким образом, СУБД хорошо подходит для обработки числовых данных и коротких буквенно-цифровых строк. Для поддержки больших полей переменных в СУБД используется концепция, называемая двоичными большими объектами (BLOBs) был введен. Большой двоичный объект - это большая битовая строка переменной длины. Например, если мы хотим сохранить фотографии учащихся в приведенном выше примере записи учащихся, мы можем создать таблицу, используя следующую инструкцию: создайте таблицу STUDENT ( stu# integer, имя char(20), адрес char(100) , большой двоичный объект); Большие двоичные объекты обычно представляют собой просто битовые строки, и такие операции, как сравнение, не могут быть проводимый на них. То есть СУБД не знает содержимого или семантики большого двоичного объекта. Все, что он знает, - это блок данных. 24 Другим типом СУБД являются объектно-ориентированные системы управления базами данных (ООД- BMSs). Обратите внимание, что подробное описание объектно-ориентированных методов выходит за рамки этой книги. Читатель может обратиться к [10, 12, 13] для полного охвата, OODBMSs сочетают в себе возможности базы данных (такие как хранение и поиск) и объектно-ориентированные функции (инкапсуляция, наследование и идентификация объекта). Один из распространенных подходов заключается в объединении объектно-ориентированные функции с реляционной базой данных. Объединенная система называется объектно-реляционной системой баз данных. В такой системе объекты должным образом определены в объектно-ориентированном смысле. То есть каждый объект содержит свойства или атрибуты, а также методы или функции, используемые для управления свойствами. Например, мы можем определить класс типа с именем IMAGE следующим образом: создать ИЗОБРАЖЕНИЕ типа ( частное целое число размера , целое число разрешения, содержимое floai[], общедоступное ); Затем мы объявляем picture как тип ИЗОБРАЖЕНИЯ, которое может быть использовано в таблице следующим образом: таблица creale STUDENT ( stu# целое число, символ имени(20), символ адреса(100) изображение картинки); Основное различие между большим двоичным объектом и объектом заключается в том, что объект определен правильно, включая его свойства и разрешенные операции со свойствами, в то время как большой двоичный объект - нет. Концепции больших двоичных объектов и объектов - это шаг к обработке мультимедийных данных [5, 10-12]. Но большие двоичные объекты используются только для хранения больших данных. В то время как объекты содержат некоторые простые атрибуты, необходимо разработать гораздо больше возможностей для обработки мультимедийного поиска на основе контента . Некоторые из необходимых возможностей заключаются в следующем: •Инструменты для автоматического или полуавтоматического извлечения содержимого и функций , содержащихся в мультимедийных данных; Многомерные структуры индексации для обработки векторов мультимедийных объектов; Показатели сходства для мультимедийного поиска вместо точного соответствия; • Подсистемы хранения, переработанные таким образом, чтобы соответствовать требованиям большого размера и высокой пропускной способности, а также требованиям реального времени; • Пользовательский интерфейс, разработанный для обеспечения гибких запросов в различных типах носителей и предоставления мультимедийных презентаций. Вышеупомянутые возможности и связанные с ними вопросы находятся в центре внимания этой книги. 1.2.3 ИК-системы и их роль в поиске мультимедиа В дополнение к СУБД существует еще один тип системы управления информацией, которая ориентирована на поиск текстовых документов. Этот тип системы называется системой поиска информации (ИК) система [8, 9]. ИК-технологии играют важную роль в управлении мультимедийной информацией системы по двум основным причинам. Во-первых, во многих организациях, таких как библиотеки, существует большое количество текстовых документов, текст является очень важным источником информации организации. Для использования информации, хранящейся в этих документах, необходима эффективная и действенная ИК -система. Во-вторых, текст можно использовать для аннотирования других носителей, таких как аудио, изображения и видео. Обычные ИК-методы могут быть использованы для поиска мультимедийной информации. Однако использование ИК для обработки мультимедийных данных имеет следующие ограничения : • Аннотирование обычно выполняется вручную и отнимает много времени: Текстовая аннотация является неполной и субъективной; *Методы IR не могут обрабатывать запросы в формах, отличных от текстовых (таких как аудио и изображения)•; • Некоторые мультимедийные функции, такие как текстура изображения и формы объектов, трудно, если не невозможно, описать с помощью текста. 1.2.4 Комплексный подход к индексации и поиску мультимедийной информации Из приведенного выше обсуждения мы видим, что СУБД и IR не могут полностью удовлетворить требованиям мультимедийного индексирования и поиска, поэтому требуются новые методы для обработки особых характеристик мультимедийных данных. Тем не менее, мы признаем, что СУБД и ИК может играть важную роль в MMDBMSs. Части мультимедийных данных, такие как дата создания и автор мультимедийного документа, структурированы. Эти структурированные данные могут быть обработаны с помощью методов СУБД. Текстовые аннотации по-прежнему являются мощным методом захвата содержание мультимедийных данных, поэтому ИК-технологии играют важную роль. Подводя итог, можно сказать, что для разработки эффективной MIRS необходим комплексный подход, сочетающий СУБД, IR и специальные технологии для обработки мультимедийных данных . 1.3 ОБЗОР MIRS На рисунке 1.1 представлен обзор работы MIRS. Информационные элементы в базе данных предварительно обрабатываются для извлечения функций и семантического содержимого и индексируются на основе этих функций и семантики. Во время поиска информации обрабатывается запрос пользователя и извлекаются его основные характеристики. Затем эти функции сравниваются с функциями или индексом каждого информационного элемента в базе данных. Информационные элементы, характеристики которых наиболее схожи с характеристиками запроса, извлекаются и представляются пользователю. 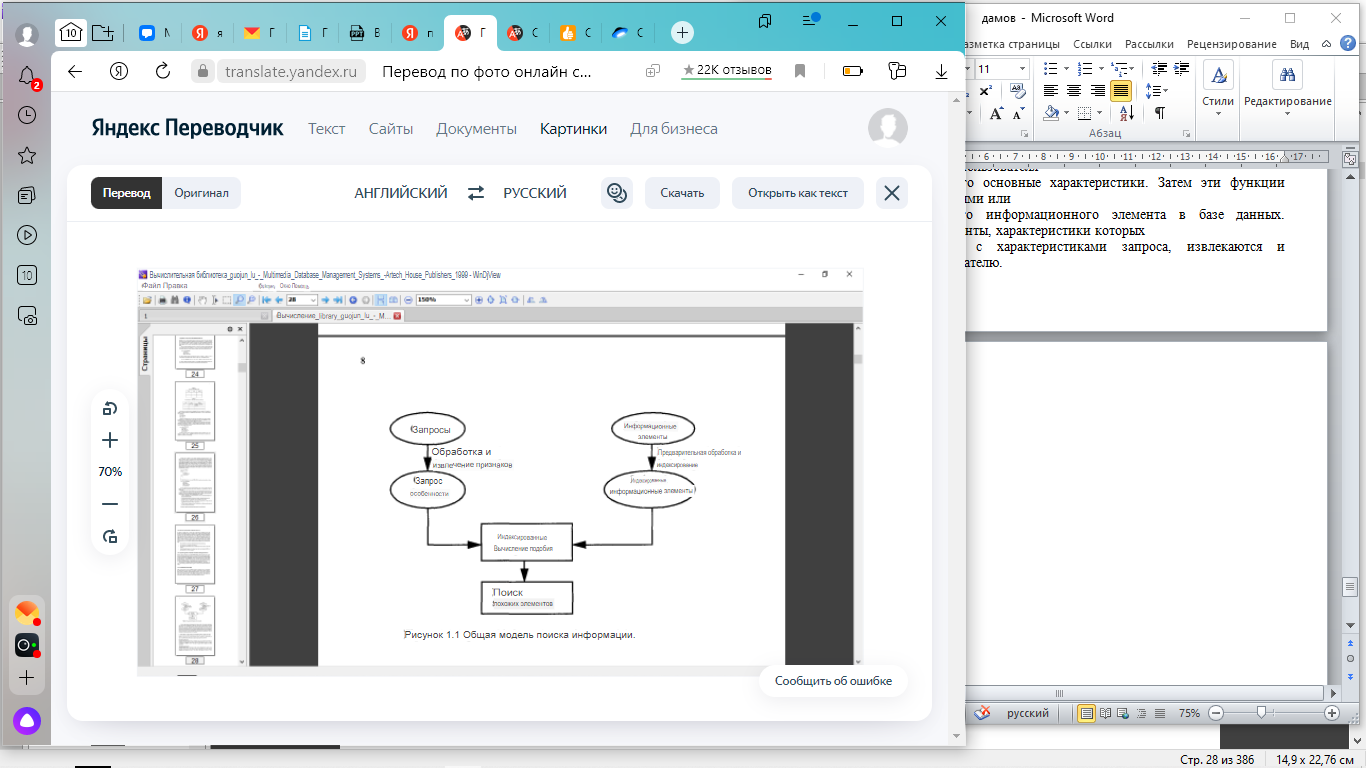 Есть много вопросов, которые необходимо решить в приведенной выше модели. Например, информационные элементы могут быть в любой комбинации типов носителей. Как мы можем извлечь функции из этих мультимедийных элементов? Как эти функции могут быть сохранены и структурированы для эффективного поиска? Как мы измеряем "сходство" между двумя медиа-элементами? Что нам нужно сделать чтобы пользовательский интерфейс мог принимать сложные, нечеткие и гибкие запросы? Как мы сравниваем производительность поиска различных MIRSS? Как мы можем удовлетворить временные требования при передаче и презентации мультимедийных данных? Мы обсудим эти и другие вопросы в остальной части книги. 1.4 ОЖИДАЕМЫЕ ВОЗМОЖНОСТИ И ОБЩИЕ ОБЛАСТИ ПРИМЕНЕНИЯ MIRS Ожидается, что MIRSS будут мощными и гибкими. Их возможности иллюстрируются типами запросов, которые они могут поддерживать. Ожидаемые типы запросов следующие. Запросы на основе метаданных Метаданные относятся к формальным атрибутам элементов базы данных, таким как имена авторов и дата создания. Примером запроса в приложении "Видео по запросу" (VOD) может быть "Список фильмов , снятых по НАЗВАНИЮ в 1997 году". Этот тип запроса может быть обработан СУБД возможности. Запросы на основе аннотаций Аннотация относится к текстовому описанию содержимого элементов базы данных. Запросы выполняются в виде ключевых слов или произвольного текста, а поиск осуществляется на основе сходства между запросом и аннотацией. Примером запроса может быть "Покажите мне сегмент видео, в котором АКТЕР катаюсь на велосипеде." Этот тип запроса предполагает, что элементы должным образом аннотированы и могут быть обработаны методами IR. Запросы, основанные на шаблонах данных или функциях Шаблоны данных относятся к статистической информации о мультимедийных данных, такой как громкость, распределение цветов и описание текстуры. Примером запроса может быть "Покажите мне видео рамка с таким распределением цветов." Чтобы ответить на запрос такого типа, статистическая информация об элементах базы данных должна быть предварительно собрана и сохранена. Запрос на примере Запросы относятся к мультимедийным объектам, таким как изображения, эскизы и звуковые фрагменты. Примером запроса может быть "Покажите мне фильм, в котором есть похожие сцены, подобные ЭТОЙ ИЗОБРАЖЕНИЕ." Этот тип запроса может быть усложнен включением пространственных и временных связей между объектами. Запросы, относящиеся к конкретному приложению Существует много типов запросов, специфичных для конкретного приложения. Например, запросы могут быть основаны на очень конкретной и подробной информации, такой как размер объекта и процесс старения человека. Мы видим, что ожидается, что MIRSS будут поддерживать различные типы запросов и, следовательно, будут иметь широкое применение, включая: • Медицина. Врач делает новое ультразвуковое изображение и хочет извлечь изображения с сопоставимой степенью гипертрофии левого желудочка из базы ультразвуковых изображений. • Безопасность, полицейский представляет системе изображение человеческого лица и хочет извлечь все другие изображения и связанные с ними записи о лицах, похожих на это изображение , из информационной базы безопасности. • Образование, учащийся сканирует изображение животного и хочет получить все факты (включая звук, изображения и текстовое описание) об этом типе животных из образовательной базы данных. Альтернативно, студент имитирует звук животного и хочет получить изображения и описательную информацию об этом типе животных. • Пресса. Репортер, пишущий статью о человеке, хочет получить фотографии этого человека и связанную с ними информацию, появившуюся в газетах и на телевидении за последние 20 лет. • Развлечения. Зритель хочет получить видеоклипы, похожие на то, кем он или она является просмотр из большой базы данных видео. • Регистрация товарного знака. Сотрудник, обрабатывающий заявку на товарный знак, хочет определить, был ли ранее зарегистрирован аналогичный товарный знак. Чтобы сделать это, ему или ей нужна база данных по товарным знакам, с помощью которой можно сравнить наиболее похожие существующие товарные знаки с новым товарным знаком. В конечном счете MIRSs сосредоточится на самой информации, а не на типах носителей, и представление информации может быть сопоставлено или переведено с одного типа носителей на другой. Это означает, например, что видеоматериал может быть запрошен с использованием видео, текста, музыки, речи, и тому подобное. Поисковая система должна сопоставить данные запроса с элементами базы данных. 1.5 ОРГАНИЗАЦИЯ ПОСЛЕДУЮЩИХ ГЛАВ Эта книга состоит из 13 глав, включая эту. В этом разделе излагаются последующие 12 глав. MIRS требуется для обработки данных в виде текста, графики, изображений, аудио и видео. Поэтому важно понимать эти типы носителей и их основные характеристики, которые описаны в главе 2. Мультимедийные данные обычно хранятся в сжатом виде, поэтому общие методы сжатия мультимедиа и стандарты также включены в главу. В главе 3 представлены требования MIRS и проблемы проектирования. Обсуждается общая архитектура, извлечение характеристик, моделирование данных, структура индексации, пользовательский интерфейс, архитектура хранилища, измерение производительности, а также поддержка операционной системы и сети. Эти вопросы и связанные с ними методы подробно обсуждаются в главах с 4 по 12. Главы 4-7 посвящены тексту, аудио, изображению и видео соответственно, для каждого из этих типов носителей мы обсуждаем, как извлекать функции или как представлять их содержимое. Затем элементы мультимедиа представляются в наборе извлеченных объектов, называемых feature векторы. Мы описываем, как измерить сходство между векторами признаков для извлечения. Для разных типов носителей требуются разные методы индексации и поиска. Для одного типа носителя могут быть использованы различные методы. Пользователи могут быть заинтересованы в релевантной информации, независимо от типов носителей, проблема заключается в том, как интегрировать различные методы для получения релевантной информации в ответ на запрос пользователя. Для решения этой проблемы необходимо решить множество вопросов, таких как спецификация и обработка запросов, сходство взвешивание и представление составных объектов В главе 8 обсуждаются эти проблемы и описывается комплексный подход к индексации и поиску мультимедиа. Для эффективного поиска необходимы соответствующие структуры индексации. Поскольку векторы признаков многомерны, а MIRSs извлекает элементы на основе сходства, а не точного соответствия, структуры индексации, используемые в СУБД, не подходят для MIRSs. В главе 9 описывается ряд структур индексации, предложенных для MIRSs. Набор требований, включающий факторы, включающие задержку и дрожание задержки, называемый qual- качество обслуживания, должно быть соблюдено для передачи и представления мультимедийных данных. В главе 10 описывается операционная система и сетевая поддержка, отвечающие этим требованиям. Серверы хранения также обсуждаются в этой главе. В СУБД основным показателем производительности является эффективность (сколько времени требуется для ответа на запрос). В MIRSs эффективность еще более важна из-за большого размера мультимедийных данных. Кроме того, эффективность поиска (способность извлекать релевантные элементы и способность отклонять нерелевантные элементы) становится важной. Это связано с тем, что MIRSs извлекает элементы на основе по сходству, измеренному с использованием метода подобия вместо точного соответствия. Поскольку сложно разработать метрику сходства, которая точно соответствует человеческому суждению, вполне вероятно, что некоторые элементы, определенные системой как релевантные, на самом деле считаются пользователем нерелевантными, а некоторые релевантные элементы не извлекаются. В главе 11 обсуждаются вопросы измерения производительности в MIRSs. В главе 12 кратко описываются текущие продукты, разработка приложений и другие вопросы, такие как безопасность и стандартизация. Это дает нам представление о том, чего ожидать в будущем. проблемы Проблема 1.1 Опишите типы носителей, обрабатываемых MIRSs. Проблема 1.2 Каковы основные характеристики мультимедийных данных и приложений? Проблема 1.3 Почему СУБД не могут эффективно обрабатывать мультимедийные данные? Проблема 1.4 Что такое ИК-системы? Подходят ли они для обработки мультимедийных данных? Почему? Проблема 1.5 Опишите основную работу MIRS. Проблема 1.6 Опишите типы запросов, которые, как ожидается, будут поддерживаться MIRSs. |