|
|
Северенс Ч. - Введение в программирование на Python - 2016. Введение в программирование на Python Ч. Северенс М. Национальный Открытый Университет "интуит", 2016
 main main
Поскольку список является общим для двух фреймов, я изобразил его между ними.
Важно различать операции, изменяющие списки и операции, которые создают новые списки. Например, метод append изменяет список, оператор + создает новый список:
>>> t1 = [1, 2]
>>> t2 = tl.append(З)
>>> priпt t1 [1, 2, З]
>>> priпt t2 Nо пе
>>> tЗ = t1 + [З]
>>> priпt tЗ [1, 2, 3, З]
>>> t2 is tЗ False
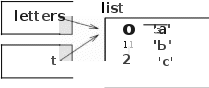
Это различие очень важно, когда вы пиш ете функции, которые должны изменять списки. Например, эта функция не удаляет первый элемент списка:
def bad_delete_l1ead(t): t = t[l:] # WRONG!
Оператор среза создает новый список и присваивает t указатель на него, но это никак не отражается на спи ске, который был передан в качестве аргумента.
В качестве альтернативы можно написать функцию, которая создает и
возвращает новый список. Например, tail возвращается все, кроме первого элемента списка:
def tail(t):
return t[l :]
Эта функция оставляет первоначальный список без изменений. Вот как она используется:
>>> letters = ['а', 'Ь', 'с']
>>> rest = tail(letters)
>>> priпt rest
['Ь', 'с']
16.15. Словарь
aliasiпg: А circurnstaпce where two or more variaЬles refer to the sаше ob ject. deliшiter: А character or striпg used to iпdicate where а striпg should Ье sp lit. element: One of the vah.1es iп а list (or other sequeпce), also called items. equivalent: Haviпg the same varue.
iпdex: Ап iпteger value that iпdicates ап element iп а list. identical: Beiпg the same object (which irnplies equivalence). list: А sequence of varues.
list traversal: The sequential accessiпg of each element iп а list. пested list: А list that is ап elemeпt of anotl1er list.
object: Somethiпg а variaЬle сап refer to. An object has а type and а value. reference : The association between а variaЬle and its value.
Поиск строки
Видео
Словари
Видео
Словарь (dictionary) похож на список, но имеет более широкие возможности. В списке позиция (или индекс) имеет целочисленное значение, в словаре индекс может быть (почти) любого типа.
Вы можете представить словарь как отображение между множеством индексов (тут они называются ключами) и множеством значений . Каждый ключ (key) отображается на значение. Связь между ключом и значением называется парой ключ-значение (key-value pair) или иногда записью (iteш).
В качестве примера, мы создадим словарь, который отображает английские и испанские слова, таким образом ключи и значения являются строками.
Функция dict создает новый словарь без записей. Т.к. dict - имя встроенной функции, вы должны исключить его из имен переменных.
>>> eng2sp = dict()
>>> priпt eng2sp
{}
Фигурные кавычки означают пустой словарь. Для добавления записей в словарь, можно использовать квадратные скобки:
>>> eng2sp['one'] = 'шю '
Эта строка создает запись, которая отображает ключ 'one' на значение 'uno'. Если мы распечатаем словарь снова, то увидим пару ключ значение, разделенную двоеточием :
>>> priпt eng2sp
{'опе': 'ш10'}
Этот выходной формат совп адает с входным форматом. Например, можно создать новый словарь с тремя записями:
>>> eng2sp = {'one': 'uno', 'two': 'dos', 'three': 'tres'}
Если вы выведете на экран содержимое переменной eпg2sp, то удивитесь:
>>> priпt eng2sp
{'three': 'tres', 'two': 'dos', 'one': 'шю'}
Порядок пар ключ-значение не совпадает. Фактически, если вы наберете этот же пример на своем компьютере, то можете получить совершенно другой результат. Порядок записей в словаре непредсказуем.
Но это не проблема, т.к. элементы словаря никогда не индексируются числовыми индексами. Вместо этого вы используете ключи для поиска соответствующих значений:
>>> priпt eng2sp['two'] dos
Ключ 'two' всегда отображается на значение 'dos', поэтому порядок записей не имеет значения.
Если ключ отсутствует в словаре, вы получите исключение:
>>> priпt eng2sp['four'] Traceback (most receпtcall last):
File "
", liпe 1, in print eпg2sp[' foш']
КеуЕпоr: 'fош'
Функция lеп работает для словарей, она возвращает число пар ключ значение:
>>> leп(eng2sp)
3
Оператор in работает для словарей, он сообщает о похожих ключах в словаре.
>>> 'one' in eng2sp
True
>>> 'шю' iп eпg2sp False
Чтобы убедиться, что какое-то значение встречается в словаре, вы можете использовать метод valнes, который возвращает значения в виде списка, а затем использовать оператор iп:
>>> vals = eпg2sp.valнes()
>>> 'шю' iп vals True
Оператор iп использует различные алгоритмы для списков и словарей . Для списков он использует алгоритм линейного поиска. Время поиска пропорционально длине списка.
Для словарей Pythoп использует алгоритм хеш-таблиц 01ash tаЫе), который имеет замечательные свойства; iп оператор занимает примерно столько же времени, сколько записей есть в словаре. Я не буду объяснять, почему хэш- функции, такие хорошие, но вы можете узнать об этом подробнее: ссылка: wikipedia.org/wiki/Нash_taЫe
Словарь как набор счетчиков
Предположим, вы хотите подсчитать , сколько раз каждая буква встречается в строке.
Есть несколько способов, чтобы это сделать:
Вы можете создать 26 переменных, по одной на каждую букву алфавита. Затем можно обойти строку и для каждого символа увеличивать соответствующий счетчик на единицу, возможно с использованием условных выражений (cl1aiпed coпditioпal).
Вы можете создать список из 26 элементов. Затем можно перевести каждый символ в число (с помощью встроенной функцию ord), используя число как индекс в списке и инкрементируя соответствующий счетчик.
Вы можете создать словарь с символами в виде ключей и счетчиками в виде значений. При первой встрече символа, вы должны добавить запись в словарь. После этого можно инкрементировать значение существующей записи.
Каждый из этих вариантов выполняет одинаковые вычисления, но каждый из них реализует разные способы вычислений.
Реализация (hnplementation) - это способ выполнения вычислений, некото рые реализации лучше остальных. Например, преимущество реализа ци и через словарь в том, что мы не должны знать заранее, какие буквы появятся в строке, у нас есть только свободное место для букв, которые появятся.
Код может выглядеть следующим образом:
defrustograш(s): d = dict() for с in s:
if с поt in d:
d[c] = 1 else:
d[c] = d[c] + 1
retшn d
Имя функции - гистограмма, т.к. это статистический термин для множества счетчиков (или частот).
Первая строка функции создает пустой словарь. Цикл for обходит строку. Всякий раз в цикле, если символ с не встречается в словаре, мы создаем новую запись с ключом с и присваиваем начальное значение 1 (т.к. мы встретили эту букву один раз). Если с уже есть в словаре, то мы инкрементируем d[c].
Так это работает:
>>> h = rusto graш('brontosaшus')
>>> priпt h
{'а': 1, 'Ь':1, 'о': 2, 'n':1, 's': 2, 'r': 2,'u:' 2,'t': 1}
Словари и файлы
Одно из распространенных применений словаря заключается в подсчете вхождений слов в текстовом файле. Давайте начнем с очень простого файла слов, взятого из текста Ромео и Джульетты :
ссылка: httpJ/shakespeare.mit.ed u!Гragedy/romeoandjuliet/romeo_juliet.2.2.h tml
В первом множестве примеров мы будем испо льзова ть сокращенную и упрощенную версию текста без знаков препи нани я. Позже мы будем работать с текстом сцены, включающим знаки препи нани я.
But soft what light throug1l yonder window breaks It is the east and Juliet is the sш1
Arise fair sun and kill the eпvious moon Who is a1ready sick and pale with grief
Мы напишем программу на Pytl1on, которая читае т строки файла, разбивает каждую строку на список слов, затем проходит в цикле через каждое слово в строке и с использованием словаря подсчитывает слова.
Вы увидите, что получится два цикла for. Внешний цикл для строк файла и внутренний цикл для каждого слова в отдельной строке. Это пример шаблона, который называется вложенные циклы (пested loops), т.к. один из циклов внешний (outer), а второй - внутренний (inner).
Комбинация из двух вложенных циклов гаранти рует, что мы будем считать каждое слово в каждой строке входного файла.
fuame = raw_input('Entertl1e file паmе: ')
try:
thand = open(fuame) except:
print 'File ca1mot Ье opened:', fпame
exit()
coш1ts = dict() for line in thaпd:
words = liпe.split()
for word h1words:
if word nomt coш1ts:
coШ1ts[word] = 1 e1se:
coШ1ts[word] += 1 prmt COШ1tS
Когда мы запускаем программ у, мы видим сырой дамп (raw dшnp) всех счетчиков в неотсортированном хэш порядке (файл roшeo.txt file дост упен по адресу: ссылка: pycode.ru/files/python/roшeo.txt))
Enter the file паше: romeo.txt
{'and': 3, 'eпvious': 1, 'a1ready ': 1, 'fair':1, 'is': 3,
'tl1rough': 1, 'pale':1,
'yoпder':1, 'what': 1, 'sш1': 2, 'Who': 1, 'But':1, 'moon': 1,
'wmdow': 1,
'sick': 1, 'east': 1, 'Ьreaks' : 1, 'grief : 1, 'with': 1,
'light': 1, 'lt': 1,
'Arise': 1, 'kill': 1, 'the': 3, 'soft': 1, 'Juliet': 1}
Нем ного неУдобно просматривать словарь в поисках наиболее употребительных слов и их количества, поэтому нам нужно добав ить еще несколько строк кода, чтобы получить более полезный результат на выходе.
Циклы и словари
Если вы испол ьзуете словарь как последовательность (sequeпce) в операторе for, происходит обход ключей слова ря. Например, prmt_hist в ыводит на экран каждый ключ и соотв етствующее ему значение:
def prmt_hist(h):
for с m h:
prmt с, h[c]
Результат имеет следующий вид :
>>> h = blstograш('parrot')
>>> priпt_blst h
а 1
р 1 r2 t 1
o 1
Снова ключи не имеют порядка.
Если вы хотите вы вести на экран ключи в алфавитно м по рядке, сначала составьте список ключей в словаре с помощью метода словаря keys, затем отсортируйте этот список и в цикле, просматривая каждый ключ, выводите на экран пару ключ/значение, как показано далее:
def print_so rted_blst(h): 1st = h.keys()
Jst.so rt() for с in1st:
p riпtс, h[c] Результат будет следующий:
>>> h = blstograш('parrot')
>>> priпt_sorted_blst(h)
al
o 1
р 1 r2 t 1
Теперь ключи отсортированы в алфавитном порядке.
Расширенный текстовый поиск
9.6. Словарь
dictionary: А шapping from а set of keys to tЬeir corresponding vah1.es. hashtaЫe: The algoritЬm used to impleшent Pythoп dictionaries.
hash function: А fuпction used Ьу а hashtaЫe to compute the locatioп for а key. histogram: А set of co uпters.
implementatioп:А way of performing а computa tion. nem: Another паше for а key-value pair.
key: Ап object that appears in а dictioпary as the first part of а key-value pair.
key-valнe pair: The represeпtation of the mapping from а key to а value.
lookнp: А dictioпary operatioп that takes а key and finds the correspoпdiпg value.
пested loops: Wheп there is опе or more loops "inside" of апоtЬеr loop. The inпer loop ruпs to completioп each tiшe the outer loop ruпs once.
valнe: Ап object that appears iп а dictioпary as the secoпd part of а key-value pair.
This is шоrе specific thaп otJГ previous нsе of the word ''valнe."
|
|
|
 Скачать 0.65 Mb.
Скачать 0.65 Mb.