Северенс Ч. - Введение в программирование на Python - 2016. Введение в программирование на Python Ч. Северенс М. Национальный Открытый Университет "интуит", 2016
 Скачать 0.65 Mb. Скачать 0.65 Mb.
|

|
Использование команды JOIN для получения данных Теперь, когда мы, следуя правилу о нормализации базы данных, разделили данные на две таблицы, связанные с помощью первичны х и внellll-lиx ключей, нам нужен способ выбора данных в команде SELECT, который мог бы собрать вместе данные из разных таблиц. SQL использует условие JOIN для соединения таблиц. В нем указываются поля, которые служат для соединения строк из разных таблиц. Приведем пример команды SELECT с условием JOIN: SELECT * FROM Follows JO IN People ON Follows.to_id = People.id WHERE Follows.froш_id = 2 Условие JOIN указывает, что мы выбираем поля сразу из двух таблиц: Follows и People. Условие ON задает, как именно соединяются две таблицы. Берем строки из таблицы Follows и добавляем в их концы строки из таблицы People, у которых значение поля "id" совпадает со значением поля ''froш_ id" строки из Follows. 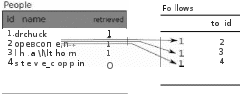  Результатом команды JOIN является создани е сверхдлинных "мета строк", которые содержит как поля из таблицы People, так и соответствующие поля из таблицы Follows. Когда есть больше одного совпадения значений полей "id" таблицы People и "from_id" таблицы Follows, команда JOIN создает несколько мета - строк, соо тветств ующих каждой совпадающей паре ключей, дублируя данные при необходимости. Следующий пример распечатывает данные, которые мы имеем в базе после того, как приведенный выше вариант программы Твиттер-паука, основанный на двух таблицах, был запущен несколько раз. ппроrt sqlite З сош1 = sq liteЗ.coппe ct(' twdata.db') cur = conn.cursor() cur.execute('S ELECT * FROM People') couпt = О priпt 'People:' for row iп cur : jf co unt < 5: pr.int row сош1t = сош1t + 1 priпt couпt, 'rows .' cur.execute('S ELECT * FROM Follows') сош1t = О priпt 'Follows:' for row iп cur : if couпt < 5: priпt row сош1t = couпt + 1 priпt cotmt, 'rows .' cur.execute('"SELECT * FROM Follows JO IN People ON Follows.to_id = People.idWHERE Follows.froш_id = 2"') сош1t = О priпt 'Cormections for id=2:' for row iп cur : if couпt < 5: priпt row сош1t = couпt + 1 priпt cotmt, 'rows .' cur.close() Программа сначала распечатывает содержимое таблиц People и Follows и затем печатает часть данных из этих таблиц, соединенных вместе. Вот вывод этой программы: python twjoiп.py People: (1, u'drchuck', 1) (2, u'opeпcontent', 1) (3, u'lhawthom', 1) (4, u'steve_co ppiп',О) (5, u'davidkocher', О) 295 rows. Follows: (1, 2) (1, 3) (1, 4) (1, 5) (1, 6) 300 rows. Cormections for id=2: (2, 1, 1, u'drchuck',1) (2, 28, 28, н'спхоrg', О) (2, 30, 30, н'kthanos', О) (2, 102, 102, н'SometblngGirl',О) (2, 103, 103, н'jа_Рас', О) 1 00 rows. Вначале идуг данные таблиц People и Follows; последние строки вывода представляют собой результат выполнения команды SELECT с условием JOIN. В ней мы находим аккаунты, которые являются друзьями аккаунта "opencontent" (т.е. People.id=2). В каждой ''мета-строке ", возвращенной последней командой SELECT, первые два поля получены из таблицы Follows, за ними следуют поля с третьего по пятое из таблицы People. Можно также заметить, что в каждой объединенной "мета-строке" второе поле (Follows.to_id) соответствуе т третьему полю (People.id). Резюме В этой главе мы познакомились с основами использования баз данных в программах на Питоне. Это сложнее, чем использовать для хранения данных словари Питона или обычные файлы , поэтому работать с базами данных следует только тогда, когда это действительно необходимо. Базы данных могуг оказаться весьма полезными в следующих ситуациях: когда приложению требуется сделать несколько изменений внугри большого набора данных, когда объем данных настолько велик, что он не помещается в словарь, и при этом поиск информации часто повторяется, когда работает некоторый долговременный процесс, который может быть остановлен и возобновлен, при этом данные должны сохраняться между перезапусками. Во многих приложениях достаточно простой базы данны х с единственной таблицей, но все же большинс тво реальных задач требуют использования нескольких таблиц и связей между строками разных таблиц. Когда возникает необходимость вводить связи между таблицами, важно хорошо продумать их дизайн и следовать правилу нормализации баз данных, чтобы обеспечить максимально эффективное использование их возможностей. Поскольку чаще всего необходимость в базах данных возникает из-за огромного объема данных, с которыми приходится иметь дело, важно построить эффективную модель данных, чтобы программа работала максимально быстро. Отладка Когда вы разрабаты ваете программу на Питоне, использующую базу данных SQLite, распространенным способом отладки является просмотр содержимого базы с помощью браузера базы данных SQLite ("SQLite Database Browser"). После запуска вашей программы браузер дает возможность быстро проверить, правильно ли работает ваша программа. Нужно учитывать, что система SQLite предотвращает одновременное изменение одних и тех же данных разными программами. Например, если вы открыли базу данных в браузере, сделали какое-то изменение и всё ещё не нажали клавишу "save" (сохранить), браузер "блокирует" (lock) доступ к файлу базы для любых других программ. В частности, ваша программа на Питоне не сможет работать с файлом базы, когда он заблокирован. Решение состоит в том, чтобы либо закрыть браузер, либо, используя его меню ''File", закрыть базу данных перед тем, как начать опять работать с ней из программы Питона, - это позволит избежать отказов программы из-за блокировки файла базы. Глоссарий Атрибут (attriЬute): одно из значений внутри кортежа. Чаще исп ользуются термины "столбец" или ''поле". Ограничение (constraint): указание базе данных, что к полю или к строке таблицы применяется некоторое правило. Чаще всего используется ограничение, требующее, чтобы не было дублирования значений в конкретном поле (т.е. все значения должны быть уникальными) . Курсор (cшsor): позволяет выполнять SQL-команды над содержимым базы данных и извлекать данные из базы. В применении к базе данных курсор является аналогом файлового дескриптора в случае обычного файла или сокета в случае сети. Браузер базы данных (database browser): программа, дающая возможность прямого подсоединения к базе данных, просмотра и изменения ее содержимого без необходимости написания программного кода. BнelllliиЙ ключ (foreigп key): целочисле нны й ключ, который ссылается на первичн ый ключ некоторой строки в другой табли це. Bнelllliиe ключи устанавливают связи между строками разных таблиц. Индекс (iпdex): дополнительные данные, которые программное обеспечение баз данных поддерживает при добавлении строк в таблицу; они используются для ускорения поиска. Логический ключ конкретной строки (logical key): ключ, используемый для поиска из "внelllliero мира". Например, в таблице, содержащей учетные записи пользователей, адрес электронной почты человека является хорошим кандида том на роль логического ключа. Нормализация (пorrnalization): создание модели данных таким образом, чтобы исключить дублирование данных. Мы храним каждый элемент данных только в одном месте, используя во всех других местах ссылки на него с помощью внelllliero ключа. Первичный ключ (prirnary key): целочисле нный ключ, ассоциированный с каждой строкой таблицы, который используется для ссылки на данную строку из других таблиц. Часто база данных конфигурируется таким образом, чтобы автоматически генерировать первичные ключи при добавлении строк. Отношение (relatioп): область внутри базы данных, содержащая кортежи и атрибугы. Чаще используется термин 'т аблица". Кортеж (tuple): одна запись в таблице базы данных, представляющая собой набор атрибугов. Чаще используется термин "строка". УпражненияУпражнение 26.1. Получите по сети файл ссылка: httpJ/www.py4inf.coш/code/wikidata.db и используйте браузер базы данных SQLke, чтобы узнать, сколько таблиц содержится в базе; определите также для каждой таблицы список ее полей и их типов. Тип одного из полей не был рассмотрен в этой главе. Используйте опlinе-документацию SQLite, чтобы описать, для чего нужен подобный тип данных. l) SQLite на самом деле допускает некотор ую гибкость при задании типов данных в столбцах, но в этой главе мы ограничимся более строгим подходом, который применим и к другим системам баз данных, например, к MySQL. 2) Как правило, если предложение начинается со слов "если всё выполняется нормально", то обычно код треб ует включения его внугрь блока t r y / e xc e p t . Автоматизация типичных задач на вашем компьютере Мы уже считывали данные из файлов, сетевых сервисов и баз данных. Питон таюке может пройти по всем каталогам и папкам вашего компьютера и прочитать содержащиеся в них файлы. В этой главе мы напишем программы, сканирующие компьютер и выполняющие некоторые операции над каждым файлом. Файлы размещены в каталогах (которые таюке назыв ают "директориями " или "папками"). Простой скрипт на Питоне способен выполнить работу, которую необходимо сделать над сотнями и тысячами файлов, содержащихся в дереве каталогов всего компьютера. Чтобы пройти все каталоги и файлы в дереве директорий, мы используем метод о s . wа l k и цикл f оr . Аналогичным образом обычная команда open дает возможность прочитать в цикле содержимое файла, сокет позволяет в цикле читать данные через сетевое соединение, а библиотека ur 1 1 ib дает возможность открыть веб-до кумент и в цикле просматривать его содержимое. Имена файлов и пуги Каждая работающая программа имеет 'текущий каталог" (сшrепt directo ry), который является каталогом по умолчанию для большинства операций. Например, когда мы открываем файл для чтени я, Питон ищет его в текущем каталоге . Модуль os (сокращение от "operatlng sys tem" - операционная система) обеспечивает нас функциями для работы с файлами и каталогами; метод o s . getcwd возвращает название текущего каталога: >>> irпport os >>> cwd = os.getcwd() >>> priпt cwd /Users/csev Аббреви атура cwd является сокращением от "сшrепt working directory". В п риведенном примере результатом является /Users/csev, это домашняя директория пользователя с именем csev. Подобная строка, идентифицирующая файл, называется пугем (раtЬ). Относительный пугь начинается в текущем каталоге; абсолютный стартует с корневой директории файловой системы. Пуги, с которыми мы имели дело до сих пор, были попросту именами файлов, т.е. они были относительными (рассматривались файлы в текущей директории). Для нахождени я абсолютного пуги к файл у можно воспользоваться методом o s . ра t h . abspa t h: >>> os.patl1.abspa th('meп10.txt') '/Users/csev/memo.txt' Метод о s . ра t h . е хi s t s проверяет, существует ли файл или каталог: >>> os.patl1.exists('memo .txt') True Если пугь существует, то метод оs . р а t h . i s d ir определяет, задает ли он каталог (директорию): >>> os.patl1Jsd.ir('memo.txt') False >>> os.patl1.isd.ir('music') True Аналогично, метод о s . ра th. i s f i le проверяет, задает ли он файл. Метод os . l i s t d i r возвращает список всех файлов и каталогов в заданном каталоге: >>> os.listd ir(cwd) ['music', 'photos', 'memo.txt'] Пример: очистка каталога с именем "photo"Некоторое время назад я написал программу, похожую на Flickr, которая получает фотографии с моего мобильного телефона и сохраняет их на моем сервере. Я написал ее еще до того, как появилась Flickr, и п родолжаю использовать ее и после появления Flickr, поскольку я хочу хранить оригинальны е копии моих фотографий бесконечно долго. Я также посылаю однострочное текстовое опи сани е фотографии в ММS-сообщении или в строке subject (тема) сообщения электронной почты. Это сообщение сохраняется в текстовом файле, расположенном в том же каталоге, что и файл с изображением. Я использовал структуру каталогов, основанную на месяце, годе, дне и времени создания фотографии. Ниже приведен пример названий для одной фотографии и её описания: ./2006/03/24-03-06_2018002.jpg ./2006/03/24-03-06_2018002.txt После семи лет я накопи л огромное количество фотографий и их описани й. С течением времени я менял мои мобильные телефоны, и ино гда мой код, извлекающий описания фотографий из сообщений, приводил к оuшбкам и добавлял массу бессмысленной информации на сервер вместо подписей к фотографиям. Мне хотелось бы просмотреть все такие файлы и определить, какие из них в действительности содержат подписи и какие - лишь мусор, чтобы удалить исп орченны е файлы. Первым делом можно написать простую программу, подсчитывающую число текстовых файлов в подкаталогах текущего катало га: import os сош1t = О for (dirname, dirs, files ) rn. os.waJk('.'): for filename h1files: if filename.endswith('.txt') : сош1t = count + 1 prh1t 'F iles:', сош1t python txtcount.py Files: 191 7 Ключевым элементом в этой программе является вызов метода o s . wa l k библиотеки Питона. Когда мы вызываем метод o s . wa l k и указываем ему стартовый каталог, он "обходит" все каталоги и подкаталоги внутри начального рекурсивно. Строка "." обозначает текущий каталог, который нужно пройти "в глубину". В процессе обхода в цикле for для каждого каталога мы получаем три значения в форме кортежа: его первым элементом является имя очередного каталога, вторым элементом - список его подкаталогов, третьим - список его файлов. Нам не нужно явно исследовать содержимое каждого подкаталога, поскольку можно положиться на метод o s . wa l k , который рано или поздно посетит каждый подкаталог. Но нам необходимо проверить все файлы, поэтому мы написали простой цикл f оr для проверки каждого файла в очередном каталоге. Мы проверяем, заканчивается ли имя файла на ".txt" и, если да, увеличиваем счетчик числа файлов, имена которых оканчиваются суффиксом ".txt". Как только мы подсчитали общее число файлов с суффиксом ".txt", следующим шагом будет попытк а автоматически определить с помощью Питона, какие файлы плохие и какие хорошие. Напишем простую программу, печатающую для каждого файла путь к нему и его размер. import os from os.path import jo.in for (dirname, dirs, files) .in os.waJk('.'): for filename n1files: if filename.endswith(' .txt') : thefile = os.path.jom(dirnaшe,filename) prn1t os.patl1.getsize(thefile), thefile Теперь вместо простого подсчета файлов мы создаем строку, представляющую путь к файлу, путем соединения имени директории с именем файла внутри нее при помощи метода о s . р а t h . j о i n. Важно использовать именно os . p a t h . j o i n вместо простой конкатенации строк, поскольку в Wmdows в обозначении пути к файлу используется символ "обратная косая черта" (backslash '\'), а в операционных системах Lmux и Apple - прямая косая черта '/'. Метод оs . ра t h . j оi n знает об этих различиях и учитывает, в какой системе работает программа, выбирая правильный разделитель; поэтому программа Питона работает правильно и под Wiпdow,s и в системах типа Uпix. После того, как мы получили полное имя файла , включающее путь к нему, мы используем метод o s . p a t h . ge t s i z e , чтобы получить и напечатать размер файла. Вот что выдает наша программа: python txtsize.py 18 ./2006/03/24-03-06_2303002.txt 22 ./2006/03/25-03-06_1340001.txt 22 ./2006/03/25-03-06_2034001.txt 2565 ./2005/09/28-09-05_1043004.txt 2565 ./2005/09/28-09-05_1141002.txt 2578 ./2006/03/27-03-06_1618001.txt 2578 ./2006/03/28-03-06_2109001.txt 2578 ./2006/03/29-03-06_1355001.txt Рассматривая вывод, обратим внимание на то, что некоторые файлы совсем корот кие, а некоторые , наоборот , очень большие, причем они имеют один и тот же размер (либо 2578, либо 2565). Посмотрев содержимое одного из подобных файлов , можно увидеть, что в них не содержится ничего, кроме одинакового НТМL-текста, присланного моей системе с моего мобильного телефона: Просматривая дальше файл, мы не находим никакой содержательной информации в нем, поэтому такие файлы, возможно, следует удалить. Но перед удалением файлов мы напишем программу, которая находит файлы, имеющие внутри более одной строки, и печатает их содержимое. Также мы не будем нагружать себя рассмотрением файлов размером в точности 2578 или 2565 символов, поскольку мы уже знаем, что эти файлы заведомо не содержат полезной информации . Итак, напишем следующую программу: import os from os.path import join for (dirname, dirs, files) in os.wa1k('.'): for filename n1files: if filename.endswith('.txt') : thefile = os.pad1.join(dirname,filename) size = os.path.getsize(d1efile) if size == 2578 or size == 2565 : contn1Ue fhaпd = opeп(thefile,'r') lines = list() for line in fhand: liпes.ap pend(liпe) fhaпd.close() if len(lines) > 1: print leп(liпes), thefile print lines[:4] Мы используем оператор c ont i nue для пропуска файлов с одним из двух "плохих " размеров, остальные файлы открываем и считываем содержащиеся в них строки в список Питона; если строк больше одной, мы печатаем количество строк в файле и первые 3 строки. Всё это выглядит как отфильтровывание файлов с двумя плохими размерами, а также допущение, что файлы, содержащие только одну строку, корректны; после этого выдача нашей программы становится достаточно содержательной: pythoп txtcheck.py 3 ./2004/03 /22- 03-04_2015.txt ['Litde horse rider\r\п', '\r\п', '\r'] 2 ./2004/11/30-11-04 _1834001 .txt ['Тestn1g 1 23. \п', '\п'] 3 ./2007/09/15- 09-07 _074202_03.txt ['\r\n', '\r\n', 'Sent from my il'ho ne\r\n'] 3 ./2007/09/19- 09-07 _124857 _01.txt ['\r\n', '\r\n', 'Sent from my il'ho ne\r\n'] 3 ./2007/09/20-09-07 _115617_01.txt Остался еще один тип файлов, доставляющих беспокойство : это файлы, содержащие по 3 строки, из которых первые две пустые, а третья строка представляет собой сообщение "Sent from my il'hone" ("Отправлено с моего телефона'), неизвес тно как просочившееся внутрь моих данных. Поэтому мы сделаем еще одно изменение в нашей программе, чтобы учесть и такие файлы. liпes = list() for liпe iп fhaпd: liпes.a ppend(liпe) if len(liпes) == 3 and liпes[2].startswith('Seпt from my iPhone') : coпt:iпue if len(liпes) > 1: priпt leп(liпes), thefile priпt liпes[:4] Мы просто проверяем файлы из трех строк, и, если третья строка начинается с указанного текста, пропускаем файл. Теперь, запустив программу, мы видим всего 4 оставшихся многострочных файла, и все 4 выглядят вполне разумно: python txtcheck2.py 3 ./2004/03 /22- 03-04 _2015.txt ['Little horse rider\r\n', '\r\n', '\r'] 2 ./2004/11/30-11-04_1834001.txt ['Тestiпg 1 23.\п', '\п'] 2 ./2006/03/17-03-06_1806001. txt ['Оп the road agaiп...\r\n', '\r\n'] 2 ./2006/03/24-03-06 _1740001.txt ['О п the road agam...\r\n', '\r\п'] Посмотрев еще раз на процесс разработки этой программы, мы видим, как последовательно улучшается множество приемлемых файлов: отыскав очередной шаблон ''плохих" файлов, мы пропускаем их с помощью оператора с о n t i nuе, что позволяет на следующем шаге найти еще один плохой шаблон. Теперь мы готовы удалить все плохие файлы, поэтому изменим логику программы на противополож ную: вместо печати оставшихся "хороших" файлов мы будет печатать ''плохие" файлы, которые мы планируем удалить. import os from os.path import join for (dirname, dirs, filesm) for filename h1files: os.waJk('.'): if filename.endswith('.txt') : thefile = os. path.jom(dirname,filename) size = os.path.getsize(tЬefile) if size == 2578 or size == 2565 : рrh1t 'Т-МоЬile:',tl1efile conth1Ue fhaпd = opeп(thefile,'r') liпes = list() for liпem fhaпd: liпes.ap pend(liпe) fhaпd.close() if len(liпes) == 3 and liпes[2].startswith('Seпt froш my iPhone') : prh1t 'iPhoпe:', tl1efile coпth1Ue Мы получили список файлов, являющихся кандидатами на удаление, причем для каждого файла указана причина, по которой его следует удалить. Вот вывод программы: python txtcheckЗ.py T-Mobile: ./2006/05/31-05- 06 1540001.txt T-Mobile: ./2006/05 /31-05 - 06_1648001. txt iPhone: ./2007/09/15-09-07_074202_03.txt iPhone: ./2007/09/15-09-07_144641_01.txt iPhone: ./2007/09/19-09-07_124857_01.txt Можно еще раз выборочно проверить эти файлы, чтобы убедиться, что мы не сделали ошибки в нашей программе и она не найдет файлы, которые не хотелось бы удалять. Если мы удовлетворе ны этой проверкой, внесем следующие изменения в программу: if size == 2578 or size == 2565 : print 'T-Mobile:',tl1efile os.remove(iliefile) continue if len(lines) == 3 and liпes[2].startswitl1('Seпt from my iPhone') : print 'iPhone:', tl1efile os.remove(iliefile) contiпue В этом варианте программы мы печатаем названи я плохих файлов и затем удаляем их, используя метод os r. e mo v e . pyilion txtdelete.py T-Mobile: ./2005/01/02-01-05 1356001.txt T-Mobile: ./2005/01/02-01- 05_1858001. txt Ради интереса запустите программу во второй раз - она не выдаст ничего, поскольку все плохие файлы уже уничтожены. Если запустить рассмотренную ранее программу txtcotmt.py, подсчитывающую текстовые файлы, мы увидим, что было удалено 899 п лохих файлов: pyilion txtcount.py Files: 1018 В этом разделе мы выполняли следующие шаги: сначала использовали Питон для просмотра всех директорий и файлов в них, пытаясь найти шаблоны нежелательных файлов. Затем, находя очередной шаблон, мы улучшали результаты поиска, что в конце концов помогло точно определить, какие именно файлы мы хотим удалить. Наконец, на последнем шаге мы с помощью Питона удалили все ненужные файлы . Задача определения требуемого множества файлов может быть совсем простой и зависеть, например, только от имен файлов, - но, возможно, нам придется считывать содержимое каждого файла и искать какие либо текстовые фрагменты внутри него. Иногда приходится читать все файлы и вносить изменения в некоторые из них. В любом случае всякая подобная задача легко решается, когда мы понимаем , как работает метод o s . wa l k и другие методы из библиотеки o s . Аргументы командной строки В предыдущих главах мы рассмотрели ряд программ, которые запрашивали у пользователя имя файла, используя функцию raw i n p u t , и затем читали и обрабатывали данные из файла: name = raw_input('Enter file:') handle = opeп(name, 'r') text = handle.read() Можно несколько упростить подобные программы, получая имя файла из командной строки, которая используется при запуске программы на Питоне. До сих пор мы просто запускали программу и отвечали на ее запросы: python wo rds.py Enter file: mbox-short.txt В командн ой строке можно указать дополнительные подстроки после имени файла с программой Питона, их обычно называют аргументами командной строки. Вот простая программа, демонстрирующая чтение аргументов из командной строки: import sys priпt 'Cotmt :', leп(sys.argv) priпt 'Туре:', type(sys.argv) for arg iп sys.argv: priпt 'Argшneпt:', arg Содержимое переменной s уs . а rgv является списком строк, в котором первая строка - это имя Питон-программы, а следующие строки представляют собой аргументы командной строки, указанные в команде после имени файла с программой. Ниже приведен вывод нашей программы для конкретной коман дной строки: pythoп argtest.py hello there Couпt: 3 Туре: Здесь 3 аргумента командной строки передаются нашей программе в виде трехэлементного списка. Первым элементом является имя программы (argtest.py), двумя другими (hello и there) - слова, указанные в команде после имени файла. Можно переписать нашу программу, чтобы она читала файл, получая его имя из коман дной строки: import sys паше = sys.argv[l] haпdle = ореп(паше, 'r') text = haпdle.read() priпt паше, 'is', leп(text), 'Ьytes' В качестве имени файла берется второй аргумент командной строки (пропускается имя программы, соответствующее индексу [О]). Мы открываем файл, читаем его содержимое и печатаем его длину в байтах: python argfile.py шbox-sl10rt.txt mbox-short.txt js 94626 bytes Использование аргументов командной строки облегчает пов торное использование Питон-программ, особенно когда нужно вводить только одну или две строки. Программные каналы (pipes) Большинство операционных систем предоставляет интерфейс командной строки, известный под названием оболочка (shell). Оболочка обычно предоставляет команды для перемещения по файловой системе и запуска приложений. Например, в Urnx'e можно перемещаться по директориям с помощью команды "cd", просматривать содержимое директории с помощью "ls" и запускать веб-браузер, например, с помощью команды "firefox". Любая программа, которую можно запустить из командной оболочки, может быть запущена также и из программыПитона с использованием канала. Программный канал (pipe) - это объект, представляющий работающий процесс. Например, команда Urux'a!) "ls -1" показывает содержимое текущего каталога (в подробном формате). Можно запустить эту команду, используя метод o s . p o p e n: >>> сшd = 'ls -1' >>> fp = os.popen(cmd) Аргументом является строка, содержащую команду оболочки. Возвращаемое значение является указателем на файл, который можно использовать точно так же, как и при открытии обычного файла с помощью функции o pe n. Можно читать вывод процесса "ls" последовательно по одной строке с помощью методаr e a d l i ne или получить сразу весь вывод с помощью методаr e a d: >>> res = fp.read() По окончании работы следует закрыть канал так же, как и файл: >>> stat = fp.close() >>> priпt stat Nопе Возвращаемое методом close значение содержит статус завершения процесса 1 s ; ''None" означает нормальное завершение (т.е. отсутствие ошибок). Глоссарий Абсолютный путь (absolute раtЬ): строка, описывающая, где хранится файл или каталог (директория), начинающаяся с корня дерева каталогов. Абсолютный путь можно использовать для доступа к файлу или каталогу независимо от текущего каталога. Контрольная сумма (checksшn): см. также "хеширование". Термин "конт рольная сумма" был порожден необходимостью проверки данных, посланных по сети или записанных на внешний носитель и затем прочитанных обратно. Когда данные записываются или пересылаются, передающая система вычисляет контрольную сумму и пересыл ает ее вместе с данными. Когда данные считываются или принимаются по сети, принимающая система перевычисляет контрольную сумму полученных данных и сравнивает ее с принятой контрольной суммой. Если контрольные суммы не сов падаю т, то это означает, что данн ые были искажены при передаче. Аргументы командной строки (сошmапd line argшnents): параметры, указанные в командной строке Питона после имени файла с программой. Текущий каталог /директория (снпеnt working directo ry): текущий каталог, в котором "вы находитесь". Можно изменить текущий каталог, используя команду "cd", которая есть в большинстве операционных систем в командном интерфейсе. Когда вы открываете файл в Питоне, используя только его имя и не указывая путь, файл должен быть в текущем каталоге, в котором вы запускаете программу. Хеширование (hashing): чте ни е потенциально очень большого объема данных и вычисление контрольной суммы для этих данных - так называемой хеш-функции. Лучшие хеш-функции создают минимальное число "коллизий", когда два различных потока данных дают при вычислении хеш-функции один и тот же результат. MDS , SНAl и SHA256 являются названиями наиболее распространенных хеш функций. Программный канал (pipe): устанавливает связь между работающими программами. Используя канал, можно написать программу, которая посылает данные другой программе или принимает данные от нее. Программный канал аналогичен сокету, за исключением того, что каналы могут использоваться лишь для связи между программами, работающими на одном и том же компьютере (не через сеть). Относительный путь (relative path): строка, описывающая, где хранится файл или каталог (директория) относительно текущего каталога. Командная оболочка (shell): интерфейс командной строки к операционной системе, называемый также 'т ерминалом" в некоторых системах. В нем пользователь вводит команду и ее параметры и затем нажимает клавишу ''Enter" для выполнения команды. Обход (waJk): термин, используемый для описания процесса посещений узлов дерева каталогов, подкаталогов, под-подкаталогов, пока мы не посетим все каталоги. Мы называем этот процесс "обходом дерева каталогов/директорий". УпражненияУп ражн ени е 28.1 . В большом собрании МРЗ-файлов могуг быть копии одних и тех же песен, сохраненные в разных дирекгориях или в файлах с разными именами. Цель этого упражнения - найти все повторяющиеся файлы. Напишите программу, которая обходит все каталоги и подкаталоги, находит все файлы с указанным суффиксом (нап ример, .mрЗ) и перечисляет пары файлов с одинаковым размером. Совет: используйте словарь, в котором ключом является размер файла, полученный с помощью метода os . pa t h . ge t s i ze , а значением является пугь к файлу (включая его имя). При получении очередного файла проверяйте, имеется ли уже в словаре файл с таким же размером. Если да, то надо напечатать размер файла и названия обоих файлов (один из словаря, второй - текущий просматриваемый файл). Измените предыдущую программу так, чтобы она сравнивала не только размеры, но и содержимое файлов , используя алгоритм вычисления контрольной суммы или хеш-функции. Например, алгоритм MDS (Message-Digest algorithm 5) читает "сообщение" произвольной длины и вычисляет 128-битовую "контрольную сумму". Вероятность того, что у двух разных файлов будет одинаковая контрольная сумма, ничтожно мала. Описание MDS можно прочитать по адресу ссылка: wikjpedia.or g/wiki/МdS. Следующий фрагмент кода открывает файл, читает его содержимое и вычисляет контрольную сумму. import hashliЬ thand = open(thefile,'r') data = thand.read() thand.close() checksшn = hashliЬ.mdS(data).hexdigest() Вы должны создать словарь, в котором контрольная сумма используется как ключ, а имя файла - как значение ключа. Если вычисленная контрольная сумма файла уже содержится в словаре в виде ключа, значит, найдены два файла с одинаковым содержимым; поэтому мы печатаем пугь к файлу из словаря и к текущему рассматриваемому файлу. Вот что выдает программа, запущенная для каталога с файлами изображений: ./2004/11/15-11-04_0923001.jpg ./2004/11/15-11-04_1016001.jpg ./2005/06/28-06-05_1500001.jpg ./2005/06/28-06- 05_1502001.jpg ./2006/08/11-08-06_205948_01.jpg ./2006/08/12-08-06_155318_02.jI ./2006/09/28- 09-06_225657 _01.jpg ./2006/09-50-years/28-09-06_225 ./2006/09/29-09-06_002312_01.jpg ./2006/09-50-years/29-09-06_002 Очевидно, я иногда отправляю одни и те же флографии более одного раза или копирую фотографии без удаления файла оригинала. l) При использовании каналов для вызова команд операционной системы, таких, как ''Js", важно знать, какую именно операционную систему вы используете, и вызывать только команды, поддерживаемые операционной системой. СодержаниеТитульная страница 2 Выходные данные 3 Лекция 1. Почему следует научиться писагь 4 программы? Лекция 2. Переменные, выражения и инструкции (VariaЫes, expressions and statements) 18 Лекция 3. Программа "Hello, World!" 30 Лекция 4. Программа "Почасовая оплата" 31 Лекция 5. Условное выпо лнение 32 Лекция 6. Программа "Почасовая оплата труда с учетом 41 переработок" Лекция 7. Усовершенствование программы "Почасовая оплата труда с учетом переработок" Лекция 8. Функции Лекция 9. Создаем первую функцию Лекция 10. Итерации Лекция 11. Вычисляем среднее значение Лекция 12. Строки Лекция 13. Программа с вводом числа Лекция 14. Файлы Лекция 15. Печать файла Лекция 16. Списки Лекция 17. Поиск строки Лекция 18. Словари Лекция 19. Поиск популярных слов Лекция 20. Кортежи (tuples) Лекция 21. 10 часто встречающихся слов 42 43 57 58 67 68 8 1 82 91 92 108 109 117 118 134 Ч. Северенс Введеии е в щю 21нш . 111рован 11е 110 Pyt/1011 Лекция 22. Регулярные выражения 135 Лекция 23. Сетевые программы 153 Лекция 24. Поиск тегов 167 Лекция 25. Использование Веб-служб 168 Лекция 26. Использование баз данных и языка структурированных запросов (SQL) Лекция 27. Автоматизация типичных задач на вашем компьютере 180 214 |