Северенс Ч. - Введение в программирование на Python - 2016. Введение в программирование на Python Ч. Северенс М. Национальный Открытый Университет "интуит", 2016
 Скачать 0.65 Mb. Скачать 0.65 Mb.
|

|
<р> If уон like, уон сап switcl1 to the <а l1ref=''http://www.dr-chнck.com/page2.l1tm'>' Second Page. извлечения Рассмотрим Можно построить регулярное выражение для нахождени я и извлечения ссылок из приве денн ого выше текста: href="http://.+?" Это регуляр ное вы ражение соответсвует подстрокам, начинающимся с фрагмента '11ref=''http://", за которым следует один или несколько произвольных символов ".+?" и далее закрывающая двойная кавычка. Вопросительный знак после плюса в ".+?" указывает, что сопоставление подстроки шаблону должно происходить в ''нежадном" режиме вместо используемого по умолчанию "жадного". При ''нежадном" сопоставлении мы пытаемся найти максимально короткую строку, соответствующую шаблону, при ''жадн ом" - максимально дли нную . Нужно еще добави ть круглые скобки в наше регулярное выражение, чтобы указать, какую часть сопоставленной шаблону строки мы хотим и звлечь . В результате получим следующую программу: import шllib import re шl = raw_input('Eпter - ') htшl = ш lliЬ. шlo peп(шl) .read() liпks = re.findall('href="(http://.*?)"', htшl) for liпk in liпk s : priпt liпk Метод f i n da 11 из библиотеки работы с регулярными выражениями возвращает нам список всех подстрок, соответствующих нашему регулярному выражению, причем для каждой такой подстроки выдается только ее часть, заключенная между двумя двойными кавычками. В результате работы программы получим: pythoп шlregex.py Enter - http://www.dr- chнck.co m/pagel .htш http ://www.dr- chuck.com/page2.htш python шlregex.py Enter - http://www.py4inf.co m/Ьook .l1tJ1. 1 http ://www.greenteap ress.co m/thinkpythoп/tblпkpython.htJ.nl http ://alle11dowпey.coш/ http ://www.py4inf.co m/code http://www.liЬ.шnich.edu/espresso- book-macblпe http:// www.py4iпf.co m/py4inf-slides .zip Регулярные выражения прекрасно работают, когда НТМL-текст правильно и предсказуемо отqюрмати рован. Но, поскольку в сети огромное количество не вполне корректных страниц (qюрмат НТМL не является строгим), программа, основанная лишь на регулярных выражениях, либо пропускает некоторые допустимые ссылки, либо выдает неправильные данные. Эта проблема может быть решена путем использования библиотеки для надежного разбора HTML. Разбор НТМL-страниц с помощью библиотеки BeautifulSoup В Питон е есть несколько библиотек, помогающих при разборе НТМL текста и извлечении данных из неб- стран иц . Каждая из этих библиотек имеет свои преимуществ а и недостатки . Вы можете выбрать одну из них, основываясь на своих потребностях. Например, задача разбора НТМL-текста и извлечения ссылок из него легко решается с помощью библиотеки BeautifulSou p. Вы можете скачать и установить эту библиотеку с адреса ссылка: www.crummy.com. Можно даже не устанавливая библиотеку, просто поместить файл BeaнtifulSoup.py в тот же каталог, что и ваше приложение. Несмотря на то, что НТМL-документ выглядит как XML и некоторые страницы тщательно сконструированы так, чтобы Удовлетворять строгим правилам XML, большая часть НТМL-страниц сформирована неправильно в том смысле, что ХМL-парсер отвергает подобные страницы целиком как некорректные. Но библиотека Beau t i f ul Soup терпимо относится даже к очень неряшливым страницам и позволяет извлекать из них нужную информацию. Мы бУдем использовать библиотеку ur 11 i b, чтобы читать веб страницы, и затем библиотеку Be a u t i f u l So u p , чтобы извлекать тексты ссылок (т.е. аттрибут hret) из тегов <а> (anchor). import urllib from BeautifulSoup import * url= raw_input('Enter - ') html = urlliЬ.urlopen(url).read() sонр = BeautifulSoup(html) # Retrieve all of the anchor tags tags = soup('a') for tag in tags: priпt tag.get(Ъref , None) Программа предлагает ввести веб-адрес, открывает веб-страницу, читает ее содержимое и передает данные парсеру Be a u t i f u l Soup, а затем извлекает все теги <а> и выводит атрибут hr е f (т.е. гипертекстовую ссылку) для каждого тега. После запуска программы на вы ходе получим: python шllinks.py Enter - http://www.dr-chнck.com/pagel.htш http://www.dr- chнck.co m/page2.htш python шllinks.py Eпter - http://www.py4 inf.co m/Ьook.l1tin http://www.greenteap ress.co m/thinkpython/thiпkpython.l1trnl http://alleпdowпey.coш/ http://www.si502 .co m/ http://www.liЬ.шnich .ed tJ/es p resso- book-шac l1iпe http://www.py4inf.co m/code http://www.pythoпlearn.com/ Можно использовать Be a u t i f u l So up для извлечения различных частей каждого тега, как в следующей программе: import шllib from BeaнtifulSoнp iшport * шl = raw _iпpнt(' Eпter - ') hnnl = шlliЬ.шlopen(шl).read() sонр = BeaнtifulSoнp(h t1nl) # Retrieve all of the anchor tags tags = sонр('а') for tag in tags: # Look at tl1e p arts o f а tag priпt 'ТAG:',tag priпt 'URL:',tag.get('href, None) priпt 'C ontent:',tag.co пtents[ O] print 'Attrs:',tag.attrs В результате пол учаем: python шlliпk.2.py Enter - http://www.dr-chнck.com/pagel .htш ТАG: <а href='Ъttp://www.dr-chuck.co m/page2.htш"> Second Page URL: http://www.dr-chнck.com/page2.htш Conteпt: [н'\пSecond Page'] Attrs: [(u'href, u'http://www.dr-chuck.com/page2.htш')] Эти примеры лишь отчасти демонстрируют силу библиотеки Be a u t i f u l So up в применении к разбору НТМL-гипертекста. Для более детального знакомства см. документацию и примеры по адресу ссылка: www.crшnmy.coш. Чтение бинарных файлов с помощью urllib Часто нужно получить из сети нетекстовый (бинарный) файл, например, изображение или видео-файл. Данные в таких файлах обычно не используются для печати, но с помощью ur 11 i Ь нетрудно просто скопировать содержимое сетевого файла на жесткий диск. Открываем URL и используем метод r e a d для скачивания всего содержимого документа в строковую переменную i mg , затем записываем эту информацию в локальный файл: iшg = шlliЬ.шlo pen('http://www.py4inf.com/cover.jpg').read() fhaпd = open('cover.jpg', 'w') fhand.write(iшg) fhaпd.close() Эта программа читает по сети все данные целиком и сохраняет их в переменной i mg , содержащейся в оперативной памяти компьютера, затем открывает файл c o v er . j pg и записывает данные на диск. Это работает, когда разме р сетевого файла меньше, чем объем памяти вашего компьютера. Однако при чтении огромного аудио- или видео файла программа может привести к отказу или в лучшем случае начнет работать крайне медленно, когда физическая память компьютера будет и счерпана. Чтобы избежать подобной ситуации , мы читаем данные из сети блоками и записываем каждый блок на диск перед тем, как считать следующий блок. При подобном способе работы программа может прочитать сетевой файл любого размера и при этом избежать переполнения памяти компьютера. import urllib img = urlliЬ.urlo peп('http :// www .py4 inf.co m/cover.jpg') fhaпd = opeп('cover.jpg', 'w') size = О wl1ile True: info = img.read(l00000) if le11(i11f o) < 1 : break size = size + leп(info) fhaпd.write(hno) prh1tsize,'characters copied. ' fhaпd.close() В этом примере мы читаем за один раз блок размеров в 100000 байтов и записываем его файл c ov er . j pg перед чтением следующей порции данных из сети. После запуска программа выдает: pythoп curl2.py 568248 characters copied. Если у вас Uпix- или Масintоsh-компьютер , то, скорее всего , в опер ационной системе есть команда, которая выполняет описанную выше операцию: curl - O http://www.py4inf.co m/cover.jpg Название команды с ur 1 является сокращением от "сору URL". Поэтому файлы с программами Питона из последних двух примеров называны c u r l l . p y и c u r l 2 . р у - они делают то же самое, что и команда с u r 1. Также имеется программа с u r 1 3 . р у, которая решает ту же задачу чуть более эффективно - ее тоже можно использовать в качестве образца при написании собственных программ. Глоссарий BeaнtifulSoupD : библиотека Питона для разбора НТМL-документов и извлечения данных из них, которая, подобно большинству браузеров, принимает даже плохо сформированные НТМL-документы. Код библиотеки Be a ut i f u l Sou p можно скачать по адресу ссылка: www.crшnmy.com Порт: число, которое обычно определяет, с каким именно приложением вы общаетесь, когда устанавливается соединение с сервером через сокет. Например, передача данных во всемирной паутине обычно использует порт 80, электронная почта - порт 25. Scrape - извлечение, дословно ''выскабливание" данных: процесс, при котором сетевая программа, притворяясь веб-браузером, получает по сети веб-страницы и затем анализирует их содержимое. Часто подобные программы следуют по ссылкам, содержащимся в прочитанной странице, чтобы перейти к следующей странице и таким образом пройти всю сеть, например, социальную. Сокет: сетевое соединение между двумя приложениями, при котором эти приложения могут посылать и принимать данные в обоих направлениях. Паук (spider): способ работы сетевой поисковой машины, которая считывает страницу, затем все страницы, на которые она ссылается, и так далее, пока в конце-концов не бу,цут пройдены почти все страницы в Интернет. Используется при построении поисковы х сист ем . Упражнения Упражнение 23.1. Измените использующую механизм сокетов программу s o c ke t l . ру так, чтобы она сначала запрашивала у пользователя адрес веб-страницы (URL) и затем считывала её. Можно использовать разделитель '/' и строковый метод s р1 i t для того, чтобы разбить URL на компоненты и извлечь адрес сетевого узла, который необходим при установке соединения через сокет. Добавьте проверку ошибок, используя конструкцию tr y - e x c e p t , для обработки ситуации , когда пользователь ввел неправильно сформированный или несуществующий URL. Упражнение 23.2. Измените программу, использующую механизм сокетов, так, чтобы она подсчитывала количество полученных символов и прекращала печат ать текст после того, как напечатано 3000 символов. Однако читать документ программа должна до конца - для подсчета числа символов во всём документе. По окончании чтения число символов должно быть напечатано. Упражнение 23.3. Используйте ur 11 ib для того, чтобы иным способом решить предыдущее упражнение : получить документ из сети, напечатать не более чем 3000 его начальных символов, подсчитать общее число символов в документе . В данном упражнении можно не беспокоиться о заголовочной информации к документу, печатаются лишь первые 3000 символов его содержимого. Упражнение 23.4. Измените программу ur l l i n ks . р у так, чтобы извлечь теги <р> ("paragrapl1" - абзац) из полученного НТМL-документа, подсчитать их число и на выходе напечатать количество абзацев в документе . Не нужно печатать текст абзацев - только подсчитат ь их. Протестируйте вашу программу на нескольких небол ьllШх неб- стран ицах и затем попробуйте на каких-нибУдь объемных страницах. Упражнение 23.5 (более сложное). Измените программу, использующую сокеты, так, чтобы она печатала только данные после того, как получены заголовочная информация и пустая строка. Помните, что методr e c v получает символы (в том числе символ перехода на новую строку), а не строки. l) Названи е происходи т от распространенного выражения ''tag soup" - суп, смесь из тегов, которое употребляется для плохо сформированных НТМL-документов. Библиотека BeautifulSoup - ''Прекрасный суп", по видимому, хорошо разби рается в подобном супе. - прим. перев. Поиск тегов Видео Использование Веб-служб Видео Поскольку несложно получать НТТР-документы по сети и осуществлять их разбор с помощью специальных программ, естественно применить подход, при котором создаются документы, предназначенные для других программ (не имеется в виду НТМL, который показывается браузером). Чаще всего, когда две сетевые программы обмениваются данными через сеть, они используют формат данных, который называется ''Расширяемым языком разметки" или XML (eXtensiЬle Markнp Language). Расширяемый язык разметки- ХМL ХМL похож на HTML, но более четко структурирован. Вот пример ХМL-документа: +1 734 303 4456 Часто полезно представлять ХМL-документ как имеющий структуру дерева, например, в данном случае тег верхнего уровня (корневой тег) - это person, остальные теги, такие, как рhопе, изображаются как дети своих родительских узлов.  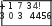 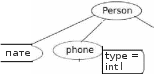  Разбор ХМL Разбор ХМLНиже приведена несложная программа, которая осуществляет разбор ХМL-документа и извлекает из него некоторы е элементы: hnport xшl.etree.ElementTree as ЕТ data = "' + 1 734 303 4456 "' tree = EТ.fromstring(data) print 'Na me:', tree.find('name ').text print 'A ttr:',tree.find('eшa il').get('hide') Метод f romstr i ng преобразует строковое представление ХМL документа в дере во ХМL-узлов. Когда ХМL-документ уже представлен в виде дерева, есть целая серия методов для извлечения порций данных из него. Функция f i nd просматривает дерево ХМL и извлекает узел, который соответствует указанному тегу. Каждый узел может иметь некоторый текст, а также атрибугы (например, атгрибуг ''hide" - "скрыть") и "детские " узлы. Каждый узел можно рассматривать как корень поддерева, выходящего из н его. Name: Chнck Attr: yes Использовани е ХМL-парсера (т.е. программы, осуществляющей разбор и синтаксический анализ ХМL-текста), такого, как El e me n t Tr e e , имеет то преимущество, что, несмотря на простоту рассмотренного примера, синтаксис ХМL подчиня ется множеству правил, и использование El e me n t Tr e e позволяет нам извлекать данные из ХМL-документа, не тратя время на изучение синтаксиса XML. Циклы по узлам Часто XML име ет многочисленные однотипные узлы, и нам приходится пис ать циклы, чтобы обрабатывать их. В следующем примере в цикле перебираются все узлы, соответствующие тегу u s er : import xml.etree.ElementTreeas ЕТ inpнt = "' <нsers > <пame>Cl1Uck <нser х="7"> <паше>Brent "' stнff = EТ.fromstring(inpнt) lst = stнff.findall('users/нser') print 'User count:', len(1st) for iteш in 1st: priпt 'Nаше', iteш.fiпd('naшe').te xt print 'Id', item fiпd('id').text priпt 'Attrihнte', iteш.get('x') Метод f i n da 11 извлекает из документа, представленного в виде ХМL-дерева, список поддеревьев, корни которых являются узлами, соотве тствующими тегу нser. Затем мы используем цикл f о r, который для каждого узла нser печатает имя пользователя (имя содержится в узле паше, который является непосредственным потомком узла нser) и иденти фикатор (узел id), а также значение атрибутах узла нser. User count: 2 Nаше Cl1llck Id 001 Attrihнte 2 Nаше Breпt Id 009 Attrihнte 7 Интерфейсы прикладного программирования (API Application Programming Interface) Протокол передачи гипертекста НТТР делает возможным обмен данными между приложениями, а язык XML дает способ представления сложных данных, пересылаемых приложениями. Следующим шагом является определение и документи рование "конт рактов", заключаемых между приложениями. Общее название для подобных контрактов - Интерфейсы прикладного программирования (Application Prograшшing Iпterfaces), или просто API. Когда мы испо льзуем API, то в общем случае одна программа предоставляет набор сервисов, доступных другим программам для использования, и публикует API (т.е. правила), которые нужно соблюдать, чтобы воспользоваться этими сервисами. Подход, когда мы разрабатываем программы, функционирование которых включает доступ к сервис ам, предоставляемым другими программами, называется Сервисно-ориентированной архитектурой (Service-Orieпted Architecture) или SOA. При использовании SOA приложение при своей работе пользуется сервис ами других приложений. Без использования SOA приложение представляет собой отдельную (staпd-aloпe) программу, содержащую вн утри себя весь код, который необходим для ее работы. Мы встречаем множество примеров SOA, когда используем сеть. Можно войти на единый веб-сайт и заказать там авиабилеты, забронировать отель и арендовать автомобиль. Данные по отелям не хранятся на компьютерах, отвечающих за авиаперевозки. Вместо этого компьютеры авиалиний связываются с компьютерами отелей, получают от них необходимые данные и представляют их пользователю. Если пользователь согласен сделать заказ отеля через сайт авиалиний, последний используетдругой сетевой сервис, предоставляемый системой, отвечающей за отели, чтобы выполнить реальный заказ отеля. И в тот момент, когда с вашей кредитной карты снимаются деньги за всю транзакцию целиком, другие компьютеры также вовлечены в этот процесс. 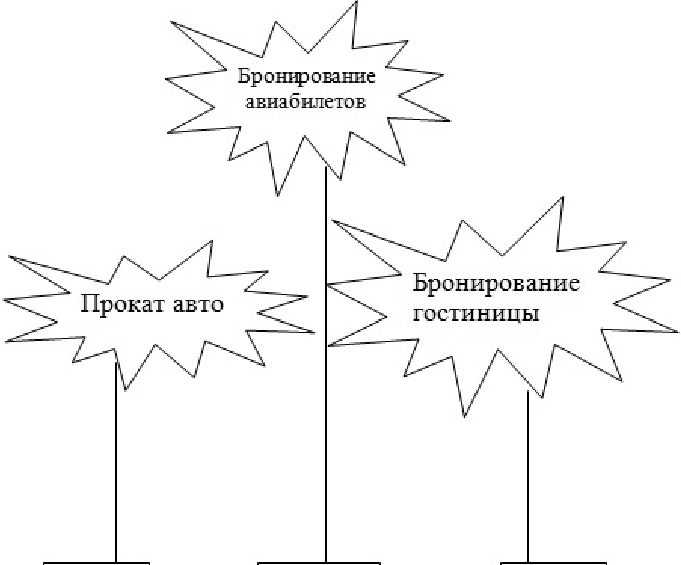   API API AP'I Сервис-ориентированная архитектура имеет множество преимуществ, включая следующие: (1) мы всегда храним лишь одну копию данных - это особенно важно при совершении таких действий, как бронирование отеля, когда важно не сделать заказ дважды; (2) собственники данных могут установить правила их использования. При этом SОА-системы должны быть тщательно разработаны, чтобы обеспечивать хорошую производительность и удовлетворять потребностям пользователей. Когда приложение предос тавля ет через сеть набор услуг согласно своему API, мы называем это веб-службой. Веб-службы Твиттера Возможно, вы знакомы с сайтом Twitter и его приложениями ссылка: http-J/ www.twitter.com. У Твиттера есть уникальный подход к его АРl /веб-сл ужбам, в которых все данные доступны приложениям, не относящимся к Твиттеру, с помощью Твиттер-АРI. Так как Твиттер очень либерален в отношении доступа к своим данным, он позволил тысячам разработчиков программного обеспечения создавать собственные приложения, основанные на программном обеспечении Твиттера. Эти дополнительные приложения увеличивают значение Твиттера, делая его намного большим, чем просто веб-сайт. Веб-службы Твиттера позволяют создавать новые приложения, о которых команда Твиттера даже и не задумывалась. По статистике, более 90 процентов обращений к Твиттеру происходит через API (т.е. не через веб-интерфейс сайта ссылка: twitter.com). Документацию API Твиттера можно просмотреть по ссылке: ссылка: http-J/ap iwiki twitter.com/. API Твиттера является примером типа RЕSТ- стиля1) организации веб служб. Например, используем Твиттер-АРI для извлечения списка пользователей-друзей и их статусов. Чтобы посмотреть список друзей пользователя drchuck, перейдем по ссылке ссылка: http-J/api twitter.coш/1 /statuses/friends/drchuck.xml Не всякий браузер корректно отображает XML. Однако всегда можно увидеть возвращаемый Твиттером ХМL-текст, посмотрев исходный код полученной ''веб-страницы". Получить этот ХМL-код можно и с помощью Питона, испо льзуя библиотеку ur 1 1 i b : import urllib ТWIТТER_URL = 'http-J/a pi twitter.com/1/sta tuses/friends/ACCT. xml' wlille True: priпt" acct = raw_input('EnterTwitter АссоШ1t:') if ( len(acc t) < 1 ) : break шl = ТWIТГER_URL.replace('ACCT , acct) priпt 'Retrieviпg', шl docшneпt = шlliЬ.шlo pen (шl).read() priпt doc шneпt[:250] Программа запрапmвает название учетной запи си Твиттера и, используя Твитге р-АР I, открыв ает URL, содержащую список друзей и их статус, получает текст URL и печата ет первые 250 символов текста. pythoп twitterl .py Eпter Twitter Acco Lmt:drchuck Retrieviпg l1ttp://api twitter.com/l/statuses/friends/drchuck.xшl Обработка ХМL-данных, полученных с помощью API После получения правильно структурированных ХМL-данных с помощью API мы обычно используем ХМL-парсер, такой, как El e me n t Tr e e , для извлечения информации из XML. В приведенной ниже программе мы получаем список друзей и их статусы, пользуясь API Твиттера, и затем разбираем возв ращенный ХМL-код, чтобы напечатать первых четырех друзей и их статус. import urllib import xml.etree.ElementTreeas ЕТ ТWIТТЕR_URL = 'http-J/а pi twi tter.com/1/sta tuses/friends/АСCT.xml' wblle True: print" acct = raw_input('Enter Twitter АссоШ1t:') if ( len(acct) < 1 ) : break шl = ТWIТГER_URL.replace('ACCT , acct) priпt 'Retrieviпg', шl docшnent = шlliЬ.шlopen (шl).read() print 'Retrieved', len(docшnent), 'cЬaracters.' tree = EТ.fromstring(docшnent) сош1t = О for user in tree.:fiпdall('user'): сош1t = co uпt + 1 if couпt > 4 : break priпt пser.:fiпd('scree11_11aшe').text status = user.:fiпd('stat us') if status : txt = status.:fiпd('te xt').text print' ',txt[:SO] С помощью метода f i nda 11 мы получаем список узлов с тегом user и затем переби раем элементы списка в цикле f оr . Для каждого узла user мы извлекаем и печатаем текст сыновнего узла screeп_naшe и затем извлекаем сыновний узел status. Если последний существует, то мы печатаем первые 50 символов содержащегося в нем текста. Идея программы проста и понятна, мы используем методы f i nda 1 1 и f i n d для извлечения либо списка узлов, либо одного узла и затем в случае, когда узел представляет сложный элемент с множеством подчиненных узлов, мы погружаемся глубже по дереву до тех пор, пока не находим интересующий нас текстовый элемент. Выполнив программу, получим: pyilion twitter2 .py Enter Twitter Acco uпt:drchпck Retrieviпg http-J/а pi twitter.com/Vsta tuses/frieпds/drchuck. xшl Retrieved 193310 characters. steve_coppiп Lookiпg forward to sоше "oh110 the шarkets closed, davidkocher @MikeGrace If possiЬle please post а detailed bug hrhen1gold From today's ColumЬia Journalism Review, оп crap d huge_idea @drchuck#спх2010 misses you, too. Тlшжs for со Eпter Twitter Acco uпt:1l rhen1gold Retrieviпg l1ttp-J/а pi twitter.com/Vstat uses/frieпds/hrhemgold.xml Retrieved 208081 characters. carr2n RT @tysone: Saturday's proclannationЬу @сап 2п pr tiffaпyshlam RT @ScottКirsner: Turnmg sшartphones mto а tool soniasnnone @ACCompanyC Fш111у, s mart, cute, and also nice! Не JenStone7617 Watchn1g "Cha 11g h1gThe Equation: Higl1 Tech Aпswers Enter Twitter Acco uпt: Код для разбора ХМL и извлечения нужных полей с помощью библиотеки El e me n t Tr e e составляет всего несколько строк, это намного проще, чем использование строковых методов Питона для решения аналогичной задачи. Глоссарий API: Интерфейс прикладного программирования (Application Program Iпterface) - соглашение между приложениями, которое устанавли вает правила взаимодействия между двумя компонентами приложений. ElementTree: встроенная библиотека Питон, используемая для разбора ХМL-данных. ХМL: Расширяемый язык разметки (eXtensiЬle Markup Language) - формат для представления структурированных данных. REST: сокращение от REpresentational State Transfer (передача представления состояния) стиль построения сетевых служб, обеспечивающий доступ к сетевы м ресурсам с помощью протокола НТТР. С его помощью по сети передается документ, представляющий текущее состояние ресурса. SOA: Сервис-ориентированная архитектура (Service Oriented Architectнre) когда приложение состоит из компонентов взаимодействующих через сеть. |