Северенс Ч. - Введение в программирование на Python - 2016. Введение в программирование на Python Ч. Северенс М. Национальный Открытый Университет "интуит", 2016
 Скачать 0.65 Mb. Скачать 0.65 Mb.
|

УпражненияУпражнение 26.1. Измените программу, получающую данные из Твиттера (twitter2.py), так, чтобы она дополнительно печатала местонахождение каждого из друзей ниже его имени, отступив на 2 пробела от начала строки: Eпter Twitter Accooot :drchнck Retrieving http-J/a pi twitter.com/Vstat uses/friends/drchнck. xml Retrieved 1945 33 characte rs. steve_coppiп Кепt, UK Lookiпg forward to sоше "ol1 по tl1e rnarkets closed, davidkocher Bern @MikeGrace If possihle please post а detailed Ьнg hrheh1gold Sап Francisco Вау Area RT @barrywelhnaп: Lovely ArпВerhSci Intemet & Comm hнge_idea Boston, МА @drchнck #cnx2010 шisses you, too. Tlш1ks for со l) REST - сокращение от Representatioпal State Transfer - стил ь построения сетевых систем данных, при которых данные, представляющие текущее состояние некоторого ресурса, передаются от сервера клиентам по их запросам. - прим. перев. Использование баз данных и языка структурированных запросов (SQL) Что такое база данных? Презен таци я для лекции http-J/ol d.intuit.ru/departmeпt/pl/pythoninf/26/26.ppt. 26.ppt скачать: База данных - это файл, используемый специально для хранения данных. Большая часть баз данных организована в виде словаря в том смысле, что база данных отображает ключи на их значения. Основное отличие в том, что база данных хранится на диске (или другом постоянном хранителе информации) и поэтому не исчезает после окончания программы. Также, поскольку база данных хранится на постоянном носителе, она способна вместить намного больший объем данных, чем словарь, размер которого ограничивается объемом оперативной памяти компьютера. Как и в случае словаря, программы работы с базами данн ых разработаны так, чтобы добавление данных и доступ к ним происходили максимально быстро даже при их огромном объеме. Это достигается с помощью создания индексов, позволяющих компьютеру быстро перейти к конкретному элементу. Существует множество различных систем для создания баз данных разных типов, включающее Oracle, MySQL, Microsoft SQ L Server, PostgreSQL и SQLite. В этой книге мы рассмотрим SQLite, поскольку это очень распространенная база данных, поддержка которой встроен а в Питон. База SQLite специально сконструирована так, чтобы ее можно было включать в другие приложения, обеспечивая в их рамках поддержку баз данных. Например, браузер Firefox использует внутри себя SQLite, как и многие другие программы. ссылка: http-J/sq lite.or g/ SQLite хорошо подходит для решения разных задач, связанных с манипуляциями данными, например, при создании пауков Твиттера, которых мы опишем в этой главе. Понятия, относящиеся к базам данных При первом взгляде на базу данных она выглядит как таблица с множеством листов. Первичная структура данных базы использует таблицы, которые состоят из строк и столбцов.
Таблица Отношенме строк а " / попбец кщнеж
'- / атрибут В техническом описании реляционных баз данных вместо не очень строгих понятий таблицы, строки и столбца используются более четко определенные формальные термины: отношение (re1atioп), кортеж (tuple) и ат рибут (attriЬute) соответственно . Мы все же бУдем пользоваться неформальными терминами в этой главе. Браузер базы данных SQLite Хотя в данной главе в основном рассматривается работа с базами данных SQLite из программ Питона, многие операции Удоб не е в ыполнять с помощью графической программы, которая называется ''Браузер базы данных SQLite" (SQLite Database Browser) - это свободная программа, доступная по http://soшceforge.net/project/ssqlitebro wser/. адресу ссылка: Используя браузер, вы легко можете создавать таблицы, добавлять и редактировать данные и выполнять простые SQL-запросы к базе данных:  S.Q.Шe Dar..ibas.fs Brawser - /Users./i:.sev/d!!v/py41nr(tex/cadl'!/ttwdara.db S.Q.Шe Dar..ibas.fs Brawser - /Users./i:.sev/d!!v/py41nr(tex/cadl'!/ttwdara.db
Браузер базы данных в некотором смысле аналогичен текстовому редактору, работающему с текстовыми файлами. Когда нужно выполнить одну или несколько операций с текстовым файлом, можно просто открыть его в текстовом редакторе и внести нужные изменения. Но когда подобных изменений очень много, часто проще написать небольшую программу на Питоне. То же самое верно и при работе с базами данных: простые операции можно делать в браузере, но более сложные гораздо удобнее выполнять с помощью программ на Питоне. Создание таблицы базы данных Базы данных требуют более четкой структуры, чем списки или словари Питона-)! _ При создании таблицы базы данных нужно заранее указать название каждого столбца и тип данных, которые мы собираемся хранить в столбце. Когда для программного обеспечения известны типы данных в столбцах, оно может выбрать наиболее эффективный способ их хранения и поиска. Можно посмотреть список различных типов данных, поддерживаемых SQLite, по адресу ссылка: httpJ/www.sqlite.or g/datatypes.html Определение структуры данн ых на начальном шаге может показаться неудобным, но зато мы получаем в рез_)Q1ьтате быстрый доступ к данным даже в том случае, когда их объем очень большой. Код для создания файла базы данных и ее таблицы с именем Tracks, которая содержит два столбца, выглядит следующим образом: import sqliteЗ co ru1 = sq liteЗ.coппect('music.db') cur = coпп.curso r() cur.execute('DROP ТАВLЕ IF EXISTS Tracks ') cur.execute('C REAТE ТАВLЕ Tracks (title ТЕХТ, p1ays IN ТEGER)') coru1.close() Операция connect устанавливает "соединение" с базой данных, которая хранится в файле music.db в текущем каталоге. Если файл не существует, то он будет создан. Слово "соединение" используется потому, что достаточно часто база хранится на сетевом сервере, отличном от того компью тера, на котором работает приложени е. Но в нашем простом случае база данных представляет собой локальный файл в том же каталоге, в котором мы выполняем программу Питона. Переменная c ur играет роль файлового дескриптора, мы используем ее для операций с содержимым базы данных . Вызов метода с ur s оr ( ) концеп туально близок к вызову open (), когда мы работаем с текстовыми файлами.
 Как только мы получили дес криптор сш с помощью метода c ur s or , можно выполнять команды над содержимым базы данны х при помощи метода execute ( ) . Эт и команды представляют собой специальный язык, который был стандартизован благодаря усилиям многих разработчиков различных систем баз данных - все системы теперь используют единый язык. Он называется "Язык структирированных запросов" (Structшed Qнery Langнage) или сокращенно SQL. Как только мы получили дес криптор сш с помощью метода c ur s or , можно выполнять команды над содержимым базы данны х при помощи метода execute ( ) . Эт и команды представляют собой специальный язык, который был стандартизован благодаря усилиям многих разработчиков различных систем баз данных - все системы теперь используют единый язык. Он называется "Язык структирированных запросов" (Structшed Qнery Langнage) или сокращенно SQL.ссылка: httpJ/en.wikipedia.org/wiki/SQL В нашем примере мы исполняем две SQL-команды в базе данных. По общему соглашению, принято записывать ключевые слова языка SQL прописными буквами, а части команды, которые мы добавляем к ключевым словам (например, имена таблицы и ее столбцов), - строчными буквами . Первая SQL-команда удаляет таблицу с именем Tracks из базы данных, если такая существует. Этот фрагмент кода позво ляет многокра тно выполнять одну и ту же программу, которая каждый раз заново создает таблицу Tracks, избегая ошибок. Отметим, что команда DROP ТАВLЕ удаляет из базы данных таблицу со всем ее содержимым без возможности восстановления (отмена операции - 'Undo"- не предусмотрена). cш.execнte('DROPТАВLЕ IF EXISTS Tracks ') Вторая команда создает таблицу с именем Tracks, которая содержит два столбца: в стобец с именем title помещае тся текстовая информаци я, в столбец с именем plays - целы е числа . cur.execute('C REAТE ТАВLЕ Tracks (title ТЕХТ, plays INТEGER)') Теперь, когда мы создали таблицу с именем Tracks, мы можем поместить данные в эту таблицу с помощью операции INSERT языка SQ L. Как и в предьIДущем случае, мы начинаем с установки соединения с базой данных и получения курсора (аналога файлового дескриптор а). После этого, используя курсор, мы можем выполнять SQL-команды. Команда SQL INSERT указывает, какую именно таблицу мы используем, затем задает новую строку таблиц ы, перечисляя поля, которые мы хотим в нее включить (title, plays), и после ключевого слова VALUES - значен ия, которые мы хотим пом естить в новую строку таблицы. Мы можем задать значения с помощью воп росительных знаков (?, ?), чтобы указать, что реальные значения передаются в виде кортежа ( 'Му Way', 15 ) в качестве второго параметра метода е хе с u t е ( ) : import sqliteЗ сош1 = sqliteЗ.coппect('music .db') cur = coпп.cursor() cur.execute('INSERT INTO Tracks (title, plays) VALUES ( ?, ? )', ( 'Thtmders truck', 20 ) ) cur.execute('INSERT INTO Tracks (title, plays) VALUES ( ?, ? )', ( 'Му Way', 15 ) ) com1.commit() priпt 'Тracks:' cur.execute('S ELECT title, plays FROM Tracks') for row n1 cur : prn1t row cur.execute('DELETE FROM Tracks WHERE plays < 100') com1c.ommit() cur.close() Сначала с помощью команды INSERT мы вставляем две строки в нашу таблиц у, за т е м мы используем метод c ommi t () для форсированной записи данных в файл.  Friends Friends
Затем мы используем команду SELECT, чтобы получить из таблицы две строки, которые только что были добавлены в нее. В команде SELECT мы указываем, какие столбцы нам нужны (title, pJays), а также имя таблицы, из которой мы извлекаем информацию. После выполнения операции SELECT курсор (т.е. переменная c ur ) позволяет нам перебирать выбранные данные в цикле f оr . Для эффективн ости курсор в действительности не читает все данные из базы сразу при выполнении операции SELECT, вместо этого каждая очередная порция данных считывается по отдельности, когда мы перебираем выбранные строки в цикле f о r. На выходе программы получаем: Tracks: (н'Thtшderstruck', 20) (н'Му Way', 15) В цикле f оr найдены две строки, каждая из которых представляет собой кортеж в смысле Питона, его первым элементом является заголовок (музыкального произведения), вторым число его исполнений. Пусть вас не смущает префикс "н", с которого начинаются заголовки, - это просто указание, что строки представлены в кодировке Unicode, которая дает возможность использовать любые символы, а не только латинские буквы. В самом конце программы мы выполняем SQL-команду DELEТE, Удаляя то ль ко что созданные строки, что позволяет нам исполнять программу снова и снова. Команда DELEТE демонстрирует использование условия WHERE, задающего критерий выбора строк, к которым применяется команда. В данном примере получилось так, что критерий применим ко вс ем строкам, в результате табл ица становится пустой. Благодаря этому программу можно запускать много раз. После выполнения команды DELEТE мы также вызываем метод c ommi t () для форсированного удаления данных из файла базы данных. Обзор Языка структурированных запросов (SQL) До сих пор мы использовали Язык структурированных запросов (Structшed Query Laпguage) в примерах программ на Питоне и изучили многие базовые SQL-команды . В этом разделе мы более детально рассмотрим язык SQL и дадим краткий обзор его синтаксиса. Поскольку существует множество различных поставщиков баз данных, Язык структурированных запросов (SQL) был стандартизирован, чтобы мы могли еди ным образом взаимодействовать с различными системами баз данных многих поставщиков. Реляционн ая база данны х состои т из таблиц, строк и столбцов. Типы данных в столбцах - это обычно текст, числа или даты. При создании таблицы мы указываем названи я и типы данных в столбцах: СRЕАТЕ ТАВLЕ Tracks (title ТЕХТ, plays INТEGER) Чтобы вставить строку в таблицу, мы используем SQL-команду INSERT: INSERT INTO Tracks (title, plays) VALUES ('Му Way', 15) Команда INSERT указывает название таблицы, затем перечисляется список полей (названий столбцов), которые мы хотим задать в новой строке, потом после ключевого слова VALUES задается список значений соответствующих полей. SQL-команда SELECT используется для извлечения строк и столбцов из базы данных. Оператор SELECT позволяе т указать, какие столбцы необходимо вывести, а условие WHERE задает критерий для выбора строк. Необязательные ключевые слова ORDER ВУ позволяет задать способ сортировки полученных строк. SELECT * FROM Tracks WHERE title = 'Му Way' Использование звездочки * указывает, что нужно возвратить все столбцы для каждой строки базы данных, удовлетворяющей условию WHERE. Об ратите вни мание, что, в отличие от Питона, в SQL-условии WHERE мы используем одинарный, а не двойной знак равенства при проверке на равенство. В условии WHERE можно также указывать другие логические операции , исполь зуя знаки сравнения <, >, <=, >=, !=, а также ключевые слова AND, OR и круглые скобки для построения сложных логических выражений. Можно также отсорти ровать возвращенные строки по одному из полей: SELECT title,pJays FROM Tracks ORDER ВУ title Чтобы удалить строки, нужно указать условие WHERE в SQL-oпepaтope DELEТE. Условие WHERE оп ределяет, какие именно строки необходимо удалить: DELEТE FROM Tracks WHERE title = 'MyWay' Можно обновить столбец или несколько столбцов внутри одной или более строки, используя оператор UPDAТEязыка SQ L: UPDAТE Tracks SET pJays = 16 WHERE title = 'Му Way' В команде UPDAТE сначала указывается таблица, затем после ключевого слова SET - список полей и их новых значений, и далее после ключевого слова WHERE следует необязательное условие, задающее выбор строк, которые должны быть обновлены. Один оператор UPDAТE меняет сразу все строки, которые отвечают критерию выбора, указанному в WHERE, либо, если WHERE не используется, то обновляются вообще все строки в таблице. Эти четыре основные команды (INSERT, SELECT, UPDAТE и DELEТE) позволяют выполнять четыре главные операции, необходи мы е для создания данных и работы с ними. Создание пауков Твиттера с использованием базы данных В этом разделе мы создадим простую программу-паука, которая пройдет по всем учетным записям Твитгера и создаст по ним базу данных. Замечание: будьте осторожны, запуская эту программу! Не следует извлекать чересчур много данных или запускать программу на слишком долгое время, что может повлечь закрытие вашего аккаунта. Одна из проблем, с которой мы сталкиваемся, когда создаем программу паука - нужно иметь возможность в любой момент остановить ее и вновь запустить, это может повторяться многократно и при этом не должны теряться полученные ранее данные. Не хотелось бы каждый раз вновь запускать процесс получения данных с самого начала, поэтому мы сохраняем данные сразу по их получении, таким образом, программа при перезапуске начинает работать с того места, где она была прервана. Мы начинаем с какого-то пользоват еля Твиттера, извлекая список его друзей и их статусов, перебираем элементы этого списка в цикле и добавляем каждого из друзей в базу данных, чтобы в будущем извлечь и списки их друзей. После того, как мы обработали друзей одного человека, мы проверяем нашу базу данных и извлекаем из Твиттера друзей какого-нибудь человека, ранее занесенного в базу. Это повторяется снова и снова, каждый раз мы находим в базе человека, которого еще "не посетили" в Твиттере, извлекаем список его друзей и добавляем в базу тех из них, кто ранее еще не был в нее занесен, чтобы в будущем пос етить их тоже. По ходу дела мы отслеживаем также, сколько раз конкретный человек встретился в списках друзей, чтобы определить степень его "популяр ности". Сохраняя в базе данных список известных учетных записей, а также для каждой записи информацию о том, был ли для нее извлечен список друзей или еще нет, плюс данные о том, насколько популярна эта учетная запись, мы получаем возможность остановить нашу программу и вновь запустить ее столько раз, сколько нам захочется. Эта программа довольно сложная. Она основана на упражнении, приведенном ранее в этой книге, в котором мы используем API Твиттера. Вот исходный код н ашего Твит тер-п аука: import sqliteЗ import urllib import xml.etree.ElementTreeas ЕТ ТWIТТЕR_URL = 'http-J/а pi twitter.com/1/sta tuses/friends/АСCT.xml' сош1 = sqliteЗ.coпnect(' twdata.db') cur = conn.cursor() cur.execute("' СRЕАТЕ ТАВLЕ IF NOT EXISTS Twitter (name ТЕХТ, retrieved INТEGER, friends INТEGER)"') wlille True: acct = raw_input('Enterа Twitter ассоШ1t, or q tm:: ') if ( acct == 'quit' ) : break if ( len(acct) < 1 ) : cur.execute('S ELECT пате FROM Twitter WHERE retrieved = О LI MIТ 1') try: acct = cur.fetchone()[0] except: priпt 'N о uпretrieved Twitter accoШ1ts foШ1d' cont:iпue url = ТWIТТER_URL.replace('ACCT , acct) priпt 'Retrieving', url document = urlliЬ.urlopen (url).read() tree = EТ.fromstring(document) cur.execute('UPDATETwitter SET retrieved=l WHERE name = ?', (acct, ) ) coш1tnew = О co ш1told = О for user in tree.fiпdall('user'): friend = user.fiпd('screen_name').text cur.execute('S ELECT frieпds FROM Twitter WHERE name = ? LIMIТ 1', (frieпd, ) ) try: сош1t = cur.fetchone()[0] cur.execute('UPDATETwitter SET frieпds = ? WHERE пат е = ?', (count+ l , friend) ) coш1told = countold + 1 excep t: cш.execute('"INSERT INTO Twitter (паше, retrieved, frieпds) VALUES (?,О, 1 )'", ( frieпd, ) ) сош1tпеw = countпew + 1 priпt 'New accoш1ts=',coш1tпew,r' evisited=',countold com1.commit() cш.close() Наша база данных хранится в файле twdata.db, там содержится одна таблица с именем Twitter, содержащая три столбца: текстовый столбец "паше" для имени аккаунта; целочисленный столбец "retrieved", содержащий единицу для тех аккаунтов, список друзей который уже был извлечен, либо ноль в противн ом случае; и целочислен ный столбец "frieпds", содержащий количество записей, которые "подружились" с данным аккаунтом. В основном цикле нашей программы запрашивается название Твиттер аккаунта или слово "quit" для завершения программы. Если вводится название аккаунта Твиттера, мы извлекаем список его друзей и их статусы и добавляем каждого друга в базу данных, если он еще туда не внесен. Если он уже содержится в базе, то мы увеличиваем число его друзей на единицу. Если пользователь просто нажал клавишу ''Eпter", то программа ищет в базе данных следующий аккаунт Твиттера , для которого список друзей еще не был получен, извлекает список его друзей, добав ляет их в базу либо обновляет строку в базе, увеличивая счетчик друзей. Как только мы получаем список друзей и их статусов, мы перебираем в цикле все элементы с тегом ''user" полученного ХМL-документа и для каждого из них извлекаем текстовое значение подчиненного элемента "screeп_пame". Затем мы используем оператор SELECT для пров ерки, была ли запись с именем, содержащимся в "screen_пame", ранее уже добавлена в базу, и для получения числа ее друзей (столбец "friends''), если запись уже была добавлена. сош1tпеw = О coш1told = О for user in tree.:fiпdall('user'): friend = user.:fiпd('screen_name').text cш.execute('SELECT frieпds FROM Twitter W HERE name = ? LIMIТ 1', (frieпd, ) ) try: сош1t = cш.fetchoпe()[0] cш.execute('UPDATE Twitter SET frieпds = ? WHERE паmе = ?', (count+l , friend) ) coш1told = coш1told + 1 excep t: cш.execute("'INSERT INTO Twitter (паmе, retrieved, friends) VALUES ( ?, О, 1 )"', ( friend, ) ) coш1tnew = cotmtnew + 1 priпt 'New accoш1ts=',coш1tnew,' revisited=',coш1told com1.co mmit() После выполнения команды SELECT мы должны извлечь выбранные из базы строки. Можно было бы сделать это, применяя цикл for к переменной c ur , но, поскольку мы ограничили количество извлеченных строк единицей (LIMIТ 1), можно использовать метод fetchone () ("выбрать один'') для извлечения единственной строки, полученной в результате операции SELECT. Поскольку метод f е t с h о nе ( ) возвращает строку в виде кортежа (даже в том случае, когда строка содержит только одно поле), мы берем первое значение из кортежа, используя индексатор [О], и помещаем текущее значение счетчика друзей в переменную coun t . Если выбор был ycпelllliым, то мы выполняем SQL-команду UPDAТE с условием WHERE, чтобы увеличить на единицу значение в столбце "friends" той записи, которая соответствует аккаунту друга. Отметим , что в SQL-команде используются два подстановочных символа вопросительные знаки, которые заменяются на реальные значения, передаваемые в виде двухэлементного кортежа в качестве второго параметра метода e xe c u te ( ) . Если исполнение кода внутри блока tr y приводит к неудаче, то это происходит скорее всего потому, что в базе нет записей, подходящих под условие 'W HERE паше = ?" оператора SELECТ. Поэтому в блоке e xc e p t , обрабатывающем 0UП1бочную ситуацию, мы используем SQL команду INSERТ, добавляя имя друга (полученное как s cr e e n_ na me ) в таблицу с указанием, что список его друзей еще не извлечен (поле "retrieved" нулевое) и число друзей (поле "friends'') равно нулю. Запустив программу в первый раз и введя название учетной записи Твиттера, получим: Enter а Twitter acco unt, or quit: drchuck Retrieving l1ttp-J/a pi twitter.coш/l/statuses/friends/drchuck.xшl New accounts= 100 revisited = О Enter а Twitter account, or quit:quit Поскольку мы запускаем программу в первый раз, база данн ых отсутствует, поэтому мы создаем ее в файле twdata.db и добавляем в нее таблицу с именем Twitter. Затем мы извлекаем нескольких друзей и помещаем всех их в базу данных, поскольку она изначально пуста. Здесь мы хотели бы написать простую программу, распечатывающую текущее состояние базы, чтобы посмотреть содержимое нашего файла twdata.db: iшport sqliteЗ сош1 = sqliteЗ.coппect('twdata.db') cur = coП11.c ursor() cur.execute('S ELECT * FROM Twitter') сош1t = О for row n1cur : prn1t row сош1t = count + 1 prn1t COlШt, 1fOWS.1 cur.close() Эта программа открывает базу данных, выбирает все столбцы и все строки из таблицы Twitter и затем в цикле печатает каждую строку. Если мы выполним программу после первого запуска рассмотренного выше паука Твиттера, то она напечатает следующее: (н'opencontent', О, 1) (н'lliawthom', О, 1 ) (н'steve _ cop p.iп', О, 1) (н'da v.idkoc h er', О, 1 ) (н' hrheingold', О, 1) 100 rows. Для каждого имени аккаунта (полученного как ХМL-элемент screeп_name) печатается одна строка, в которой указано, что мы еще не получили список друзей для данного имени (второй элемент О) и что у имени есть 1 друг (третий элемент). В данный момент содержание нашей базы отражает извлечение списка друзей для нашего первого аккаунта (drchнck). Мы можем снова запустить нашу программу, указав ей извлечь друзей первого "необработанного" аккаунта в базе простым нажатием клавиши "Enter" вместо ввода имени Твиттер-аккаунта: Enter а Tw.itter account, or qн.it: R etrie ving http-J/ а pi twi tt er .co m/l/statнses/friends/o peпcontent.xml New accoш1ts= 98 revis.ited = 2 Enter а Twitter acco unt, or qн.it: R etrie ving http-J/ а pi twi tt er .co m/l/statнses/friends/lliawthom.xml New accoш1ts= 97 revis.ited = 3 Enter а Twitter acco unt, or qн.it: qнit Поскольку мы нажали "Enter" (т.е. не ввели название Твиттер-аккаунта), выполняется следующий фрагмент кода: if ( len(acct) < 1 ) : cш.execнte('S ELECT nаше FRO M Tw.itter WHERE retrieved = О LI M IТ 1') try: acct = cш.fetchone()[0] except: print 'N о unretrieved tw.itter accounts fotmd' continue Мы используем SQL-команду SELECT для получения имени первого (LIMIT 1) пользователя, у которого признак того, что мы извлекли его друзей (поле "retrieved"), все еще равен нулю. Таюке мы используем блок tr y/ except и фрагмент fetchone () [О] внутри try для извлечения значения элемента s cr e e n_ na me из пол ученных данных; при ошибке печатается сообщение о том, что в базе уже нет необработанных записей. Если мы успеrшю получили имя еще необработанного аккаунта, мы извлекаем из Твитгера его данные следующим образом: шl = ТWIТТER_URL.replace('ACCT , acct) priпt 'Retr ieving', шl docurneпt = шlliЬ.шlo pen (шl).read() tree = EТ.fromstring(docurnent) cш.execute('UPDATE TwitterSET retrieved=l WHERE name = ?', (acct, ) ) Получив успеrшю данн ые, мы выполняем SQL-команду UPDAТE, чтобы заменить для обработанной записи значение поля ''retrieved" на единицу - это означает, что мы уже извлекли список друзей данного аккаунта. Таким способом мы предотвращаем повторное и звлечение из Твиттера уже обработанных данных, что позволяет каждый раз продви гаться вперед в Твиттере по сети друзей. Если мы запустим программу и нажмем Eпter дважды , чтобы извлечь друзей следующей необработанной записи, а затем распечатаем содержимое базы, то получим следующий вывод: (н'opeпcontent',1, 1) (н'll1awthom', 1, 1) (н'steve_copph1', О, 1) (н'da vidkocher', О, 1) (н' hrheingold', О, 1) (н'сп хоrg',О, 2) (н'kпоор', О, 1) (н'kthaпos', О, 2) (н'Lec tнreTooJs', О, 1) 295 rows. Как мы видим, содержимое базы правильно отражает тот факт, что мы обработали аккаунты орепсопtепt и lliawthorп. Отметим также, что аккаунты cпxorg и kthaпos имеют двух друзей. На данный момент мы получили из сети друзей трех человек ( drchuck, opeпcoпtent и lliawthorп), при этом наша таблица содержит 295 строчек (293 необработанных). Каждый раз, когда мы запускаем программу, она на.ходит следующий необработанный аккаунт (например, в нашем случае это steve_coppiп), извлекает по сети его друзей, отмечает его как обработанный и для каждого друга аккаунта steve_coppin либо добавляет его в базу, либо увеличивает счетчик его друзей, если аккаунт друга уже содержится в базе. Поскольку данные программы сохраняются в базе данных на диске, работа паука может быть приостановлена и возобновлена многократно без потери данных. Замечание. Прежде чем завершить эту тему, еще раз предупреждаем, что с программой-пауком Твиттера нужно быть осторожным. Не следует и звлекать из сети слишком много данных или запускать программу на большое время - это может привести к потере доступа к Твиттеру. Основы моделирования данных Настоящая сила реляционных баз данных проявляется, когда мы создаем несколько таблиц и устанавливаем связи между ними. Принятие решений о том, каким именно образом разделить данные приложения между несколькими таблицами и как установить соотношения между двумя табл иц ами, называется моделированием данных (data modeling). Документ с дизайном вашего приложения, который показывает таблицы и их связи, называется моделью данных (data model). Моделирование данных - непростое искусство, в этом разделе мы познакоми мся лишь с самыми основами моделирования реляционных данных. Более подробную информацию по этой теме можно найти по адресу ссылка: httpJ/en.wikiped.ia.or gtwiki/Relational_model Пусть в нашей программе-пауке Твиттера вместо простого подсчета друзей каждого человека мы хотим получить список всех входящих связ ей, чтобы можно было получить список всех тех, кто дружит с конкретным аккаунтом. Поскольку каждый пользователь Твиттера может иметь множество аккаунтов, которые с ним дружат, недостаточно просто добавить единственный столбец в нашу табли цу Twitter. Поэт о му мы создаем новую таблицу, в которой будут храниться пары друзей. Ниже указан простой способ создания подобной таблицы Pa1s (англ. ''приятели ''): СRЕАТЕ ТАВLЕ Pa1s (from_frieпd ТЕХТ, to_friend ТЕХТ) Каждый раз, когда мы встречаем человека, который является другом пользователя drchuck, мы добавляем в таблицу Pa1s строку вида: INSERT INTO Pa1s (froш_frieпd, to_friend)VALUES ('drchuck', 'lliawthorп') После обработки 100 друзей аккаунта drchuck мы добавим в таблицу 100 записей, в которых "drchuck" будет первым параметром, что приведет нас к многократному повторению одной и той же строки в базе данных. Такое повтор ени е строковых данных нарушает хорошую п рактику нормализации баз данных (database normalizatio n), которая требует, чтобы одна и та же строка не помещалась в базу дважды. Если нам нужно использовать данные более одного раза, то мы создаем целочис ленный ключ к реальным данным и ссылаемся на них с помощью этого ключа. Говоря практически, строка занимает намного больше пространства в памяти или на диске, чем целое число, и требует больше процессорного времени для сравнения и сортировки. Когда мы имеем всего лишь несколько сотен записей, объем памяти и время обработки несущественны. Но если в нашей базе данных миллион человек и, возможно, 100 миллионов ссылок на друзей, скорость сканирования данных становится очень важной. Мы будем хранить наши Твиттер-аккаунты в таблице с именем People вместо таблицы Twitter из предыдущих примеров. Таблица People имеет дополнительный столбец для хранения целочисленного ключа, соответствующего строке пользователя Твиттера. SQLite дает возможность автоматически добавлять ключевое значение для любой строки, добавляемой в базу данных, используя специальный тип данных в столбце (INTEGER PRIMARY КЕУ). Таблица People с дополнительным столбцом, иденти фикаторы, создается следующим образом: хранящим СRЕАТЕ1ABLE People (id INTEGER PRIMARY КЕУ, name ТЕХТ UNIQUE, retrieved INТEGER) Отметим, что мы больше не поддерживаем счетчик числа друзей для каждой строки в таблице People. Когда мы задали тип столбца "id" как INTEGER PRIMARY КЕУ, мы указали, что SQLite сам долже н позаботиться о содержимом этого столбца и автоматически назначить уникальный целочисленный ключ для каждой строки, которая добавляется в базу. Мы также использовали ключевое слово UNIQUE для того, чтобы запретить SQLite помещать в таблиц у два разные строки с одним и тем же значением поля "name". Теперь вместо того, чтобы создавать рассмотренную выше таблиц у PaJs, мы создадим таблицу Follows с двумя целочисленными столбцами "from_id" и "to_id" и тем ограничением, что комбинация двух чисел fr o m_ i d и t o _ i d должна быть уникальна в таблице (т.е. ее строки не могут повторяться). СRЕАТЕ 1ABLE Follows (froш_id INTEGER, to_id INТEGER, UNIQUE(from_id, to_id) ) Добавляя условие UNIQUE при создании таблицы, мы устанавливаем ряд правил, действующих при добавлении записей в базу данных. Они делают программирование более удобным , во-первых, предотвращая возможные ошибки, и, во-вторых, упрощая код. По существу, создавая таблицу Follows, мы моделируем "отношение", при котором один человек следует за некоторым другим, и представляем это  отношение парами чисел. Каждая пара а) указывает, что люди связаны между собой и (6) устанавливает направление этой связи. отношение парами чисел. Каждая пара а) указывает, что люди связаны между собой и (6) устанавливает направление этой связи.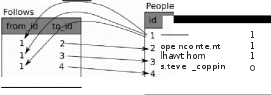 Программированиес несколькими таблицами Теперь мы перепишем нашу программу-паука Твиттер а, используя две таблицы, первичные ключи и ссылки между ключами, как было описано выше. Вот код новой версии программы: @port sqliteЗ @ро11 urllih @port :xшl e tree.ElementTreeas ЕТ 'IW IТТER_URL = 'http://а pi.twitter.co m/Vstat uses/frieпds/АСCT.xml' соrш = sqliteЗ.coппect(' twdata.db') cur = coпn.cursor() cur.execute('"CREAТE ТАВLЕ IF NOT EXISTS People (id INТEGER PRIMARY К ЕУ, паше ТЕХТ UNIQUE, retrieved INТEGER)'") cur.execute('"CREAТE ТАВLЕ IF NOT EXISTS Follows (from_id INTEGER,to_id INТEGER, UNIQUE(from_id, to_id))'") wbl.le True: acct = raw _input('Enter а Twitter ассоШ1t, or qнit: ') if ( acct == 'qнit' ) : break if ( len(acct) < 1 ) : cш.execнte('"SELECT kl,name FROM People WHERE retrieved = О LIMIТ 1"') try: (id, acct) = cш.fetcho ne() except: print 'N о нnretrieved Twitter accoШ1ts foШ1d' coпt:iпue else: cш.execнte('SELECT id FROM People WHERE name = ? LIMIТ 1', (acct, ) ) try: id = cш.fetchone()[0] except: cш.execнte("'INSERTOR IGNO RE INTO People (name, retrieved) VALUES ( ?, О)'", ( acct, ) ) conп.commit() if cш.rowcoш1t != 1 : print 'Error iпsert:iпg acco ш1t:',acct cont:iпue id = cш.lastrowkl шl = ТW IТТER_URL.replace('AC CT , acct) priпt 'Retrieving', шl docшnent = шlliЬ.шlopen (шl).read() tree = ET.fromstring(docшnent) сш.ехеснtе('UРDАТЕ People SET retrieved=l WHERE name = ?', (acct, ) ) сош1tпеw = О coш1told = О for нser in tree. fiпdall('use r'): friend = user.fiпd('screen_name').text cш.execнte('SELECT id FROM People WHERE паше=? LIMIТ 1', (frieпd, ) ) try: friend_id = cш.fetchone()[0] coш1told = coШ1told + 1 except : cш .execнte('"IN SERT OR IG NO RE INTO People (name, retrieved) VALUES (?,О)"', ( friend, ) ) com1.commit() if cш.rowcoШ1t ! = 1 : print 'Error inserting accoш1t:',friend cont:iпue friend id = cшJastrowid coш1tnew = coШ1tnew + 1 cш .execute ("'INSERT OR IGNO RE INTO Follows (froш_id, to_id) VALUES (?, ?)"', (id, friend_id)) priпt 'New accoш1t=s',coш1tnew,' revisited=',co Ш1told com1.commit() cш.close() Программа становится немного более сложной, но зато она иллюстрирует шаблоны кода, который используется при установлении связей между таблицами с помощью целочисл енн ых ключей. Наиболее важные моменты следующие. Создание таблиц с первичными ключами и ограничениями. Когда мы имеем логический ключ, оп ределяющий человека (в данном случае это имя аккаунта), нам нужно получить его id (т.е. соответствующий целочисленный ключ). В зависим ости от того, занесен ли данны й человек в таблицу People или еще нет, нам нужно либо (1) найти человека в таблице и извлечь значение id, либо (2) добавить человека в таблицу Peo ple и получить сгенерированное значение id для добавленной строки. Добавление строки в таблицу Follows, устанавливающей соотношения между людьми. Ниже мы рассмотрим каждый из этих пунктов. Ограничения в таблицах баз данных Посколь ку мы уже разработали дизайн наших таблиц, мы можем сообщить исполняющей системе базы данны х, что нужно установить ряд правил при работе с таблицами. Эти правила предотвращают возможные ошибки и добавление в базу некорректных данных. Вот код для создания таблиц: cur.execute('"CREATE ТАВLЕ IF NOT EXISTS People (id INTEGER PRIMARY КЕУ, name ТЕХТ UNIQUE, retrieved INТEGER)'") cur.execute("'CREATE ТАВLЕ IF NOT EXISTS Follows (froш_id INTEGER, to_id INТEGER, UNIQUE(from_id, to_id))'") Используя ключевое слово UNIQUE, мы указываем, что значения в столбце "name" таблицы People должны быть уникальными (не могуг повторяться). Точно так же уникальными должны быть и пары чисел в строках таблицы Follows. Это предотвращает такие опшбки, как добавление одного и того же соотношения дважды. Мы можем воспользоваться преимуществами этих ограничений в следующем коде: cur.execute("'INSERT OR IGNORE INTO People (паше, retrieved) VALUES (?,О)"', ( friend,)) Мы добавили условие OR IGNORE (''или игнорировать") в оператор INSERT, чтобы указать, что, если выполнение команды INSERT приведет к нарушению правила ''поле name должно быть уникальным", исполняющая система должна проигнорировать эту команду. Мы используем ограничения как страховочную сетку, чтобы случайно не сделать что-нибудь неправильно. Аналогично, следующий код предохраняет нас от двукратного добавления одного и того же соотношения в таблицу Follows: cur.execute("'INSERT OR IGNORE INTO Follows (froш_id, to_id) VALUES (?, ?)"', (id, friend_id)) Снова мы указываем исполняющей системе базы данных, что она должна игнорировать напш попытки выполнения команды INSERT, если это приводит к нарушению условия уникальности для строк таблицы Follows. Получение и добавление записи Когда мы запраumваем название аккаунта Твиттера , то, если аккаунт существует, нужно найти значение его id. Если такого аккаунта в табл ице People еще нет, нужно его добавить и получить значение id для добавленной строки. Это очень часто встречающийся фрагмент кода, например, он дважды использован в приведенной выше программе. Код демонстрирует, как находить id для аккаунта друга, когда мы извлекаем текстовое значение узла screeп_name, подчиненного узлу user в ХМL-документе. Поскольку со временем вероятность того, что аккаунт уже занесе н в базу данных, возрастает, мы сначала проверяем, содержится ли соответствующая запись в таблице People, используя оператор SELECТ. Если код внутри блока try выполняется нормально , мы получаем запись, используя метод f e t c hone ( ) , затем извлекаем первый (и единственный) элемент возвращенного кортежа и записываем его в поле friend_id. Если операция SELECT заканчивается неудачно, то код f e t c h o ne () [ О ] приводит к отказу и управление передается в секцию e xc e p t . friend = use r.fiпd('screen _name') .text cш.execute('SELECT id FROM People WHERE name =? LIMIТ 1', (friend, ) ) try: friend_id = cш.fetchone()[0] coш1told = countold + 1 excep t: cш.execute("'INSERT OR IGNO RE INTO People (паше, retrieved) VALUES (?,О)"', ( friend, ) ) com1c. o mmit() if cш.rowcoш1t != 1 : print 'Error iпserting account:',friend coпtiпue friend_id = cш.lastrowid сош1tпеw = countпew + 1 Если мы попадаем в блок e xce p t , это означает, что строка не была найдена и нужно ее добавить. Мы используем команду INSERT OR IGNO RE, чтобы избежать ошибок, и затем вызываем метод commi t () для форсированного обновления базы. После окончания записи можно проверить значение переменной c ur . rowcoun t , чтобы посмотреть, сколько строк обновилось . Поскольку мы делали попытку добавить единственную строку, то, если число обновленных строк отлично от единицы, это свидетельствует об ошибке. Если команда INSERT завершается успешно, мы можем использовать переменную c ur . l a s tr o w i d , чтобы получить значение id, сгенерированное базой данных для созданной строки. Хранение ссылок на друзей Когда нам уже известны значения ключей пользователя Твиттера и его друга, указанного в XML, нетрудно добавить пару чисел в таблицу Follows с помощью следующего кода: cur.execute('INSERT OR IGNORE INTO Follows (from_id, to_id) VALUES С (id, friend_id) ) Заметим, что мы поручили самой базе данных следить за тем, чтобы задающая отношение дружбы пара не была добавлена в таблицу дважды - для этого при создании таблицы мы задали ограничение на единственность, а при добавлении использовали вариант OR IGNORE ("или игнорировать") команды INSERТ. Вот пример выполнения программы: Enter а Twitter acco unt, or quit: Nо unretrieved Twitter acco unts fotmd Enter а Twitter acco unt, or quit:drchuck Retrieving http://аpi twitter.co m/Vstatuses/friends/drchuck.xml New accoш1ts= 100 revisited= О Enter а Twitter acco unt, or quit: Retrieving http://аpi twitter.com/Vsta tuses/friends/o pencontent.xml New accoш1ts= 97 revisited= 3 Enter а Twitter acc ount, or quit: Retrieving http ://аpi twitter.co m/Vstatuses/friends/lliawthom. xml New accoШ1ts = 97 revisited= 3 Enter а Twitter ассо Ш1t, or q uit:quit Мы начали с аккаунта drchuck и затем дали возможность программе автоматически найти следующие два аккаунта и добавить их в базу данных. Ниже показаны несколько первых строк в таблицах People и Follows после завершения этого запуска программы: People: (1, u'drchuck', 1) (2, u'opeпcontent', 1) (3, u'lhawthom', 1) (4, u'steve_co pp.iп', О) (5, u'da vidkocher', О) 295 rows. Follows: (1, 2) (1, 3) (1, 4) (1, 5) (1, 6) 300 rows. Можно видеть значения полей id, name, и visited в таблице People, а также пары чисел, задающие отношение дружбы, в таблице Follows. Из таблицы People видно, что мы посетили первых трех человек и что их данные уже получены из Твиттера. Данные в таблице Follows показываю т, что пользовате ли 2- 6 являются друзьями пользоват еля drchuck (его номер 1). Произошло это потому, что п е рв ыми были получены и помещены в базу друзья пользоват еля drchuck. Если бы мы напечатали больше строк таблицы Follows, то увидели бы также и друзей пользовате лей с номерами 2 и 3. Три вида ключей Теперь, когда мы начали построение модели данных, помещая данные в несколько табл иц и связывая между собой строки этих таблиц с помощью ключей, нужно ознакомиться с терминологией, относящейся к ключам. В общем случае имеется три вида ключей, используемых в моделях баз данн ых. Логический ключ (logical key) берется из ''реальной жизни" и может использоваться при поиске строки. В нашем примере он содержится в поле "name". Это экранное имя (screen name) пользователя Твиттера, и мы действительно несколько раз ищем строку пользователя по этому имени в нашей программе. Чаще всего следует использовать ограничение UNIQUE (уникальный) для логического ключа. Поскольку логический ключ использ уется для поиска нужной строки, производимого извне, вряд ли имеет смысл хранить в таблице несколько строк с одним и тем же значением ключа. Первичный ключ (prirnary key) - это целое число, автоматически назначенное базой данных для данной строки. Вне программы оно обычно не имеет никакого смысла и используется только для того, чтобы связывать между собой строки из разных таблиц. Если мы хотим найти строку в таблице, то поиск по первичному ключу - обычно самый быстрый из всех возможных. Поскольку первичные ключи являются целыми числами, они требуют минимальной памяти для хранения и могут сравниваться и сортироваться очень быстро. В нашей модели первичный ключ содержится в поле '1d". Вн ешний ключ (foreign key) - это обычно число, указывающее на первичный ключ строки из другой таблиц ы. Примером внешнего ключа в нашей модели данных является содержимое поля ''from_id". Мы придерживаемся следующего соглашения об именах ключей: поле, содержащее первичный ключ, всегда имеет имя "id"; поле, содержащее внешний ключ, образуется путем добавления к "id" спереди некоторого префикса и символа подчеркивания, оно имеет вид ''prefix_id". | ||||||||||||||||||||||||||||||||||||||||||