РГР. Анализ музыки Spotify
 Скачать 0.85 Mb. Скачать 0.85 Mb.
|

|
Анализ музыки Spotify Этот блокнот выполняет базовый анализ метаданных песен, взятых из Spotify. Данные содержат числовые метрики, генерируемые Spotify, которые измеряют танцевальность, настроение, живость и т. д. песни. Данные также содержат название песни и ее исполнителя. Сначала мы импортируем все необходимые модули и создаем таблицу для анализа.   Для начала мы создадим диаграмму рассеяния на основе значений валентности и танцевальности песен. Кроме того, мы также воспользуемся линейной регрессией, чтобы найти их корреляцию.  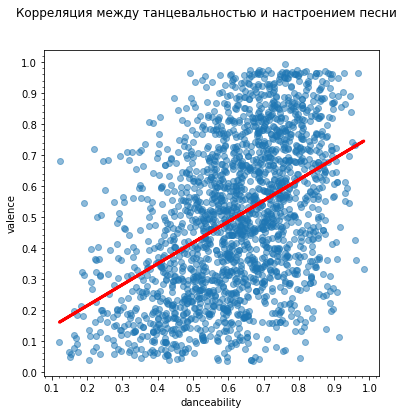 Теперь создадим несколько гистограмм. График слева иллюстрирует распределение песен по их энергетическим уровням, а график справа - это "тепловая карта" (гистограмма в двух измерениях), которая иллюстрирует количество песен, найденных при всех значениях валентности и танцевальности. 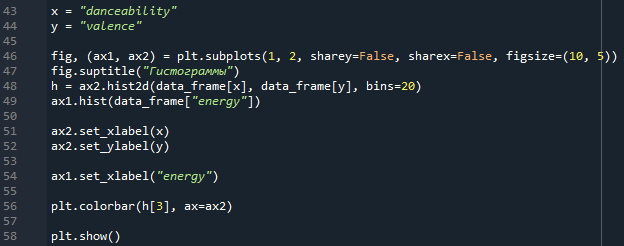  Здесь начинается самое интересное. Далее мы составляем список "избранных" признаков и с помощью анализа главных компонент сокращаем размерность этого списка до 3, создавая матрицу, пригодную для построения следующего трехмерного графика. Чем меньше расстояние между двумя песнями, тем больше сходства в их чертах. - Plotly — бесплатная библиотека, которую вы можете использовать в коммерческих целях - Plotly работает offline - Plotly позволяет строить интерактивные визуализации Т.е. с помощью Plotly можно как изучать какие-то данные «на лету» (не перестраивая график в matplotlib, изменяя масштаб, включая/выключая какие-то данные), так и построить полноценный интерактивный отчёт (дашборд). Для начала необходимо установить библиотеку, т.к. она не входит ни в стандартный пакет, ни в Anaconda. Для этого рекомендуется использовать pip: pip install plotly Перед началом работы необходимо импортировать модуль.  Если мы хотим построить график в автономном режиме и сохранить график как file.hmtl нужно добавить строчку: py.iplot(fig, filename="file.html") Так в папке с нашим Питон файлом сохранится и html файл, который можно открыть в браузере. 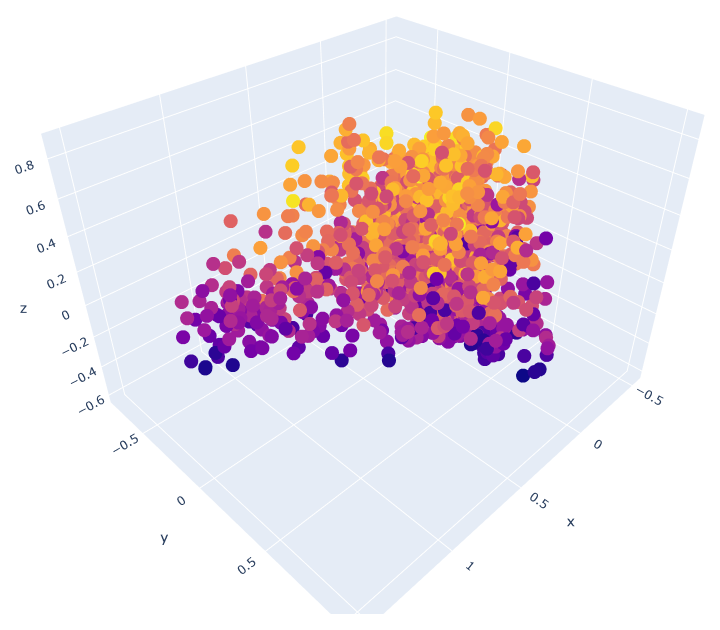 В другой попытке мы используем меньший "избранный" список и PCA для создания двумерного графика. Этот конкретный график был выбран из-за его кажущегося точного наименования осей. Метод главных компонент (англ. Principal Components Analysis, PCA) — один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации. Изобретен К. Пирсоном (англ. Karl Pearson) в 1901 г. Применяется во многих областях, таких как распознавание образов, компьютерное зрение, сжатие данных и т.п. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных или к сингулярному разложению матрицы данных. Иногда метод главных компонент называют преобразованием Карунена-Лоэва (англ. Karhunen-Loeve) или преобразованием Хотеллинга (англ. Hotelling transform).  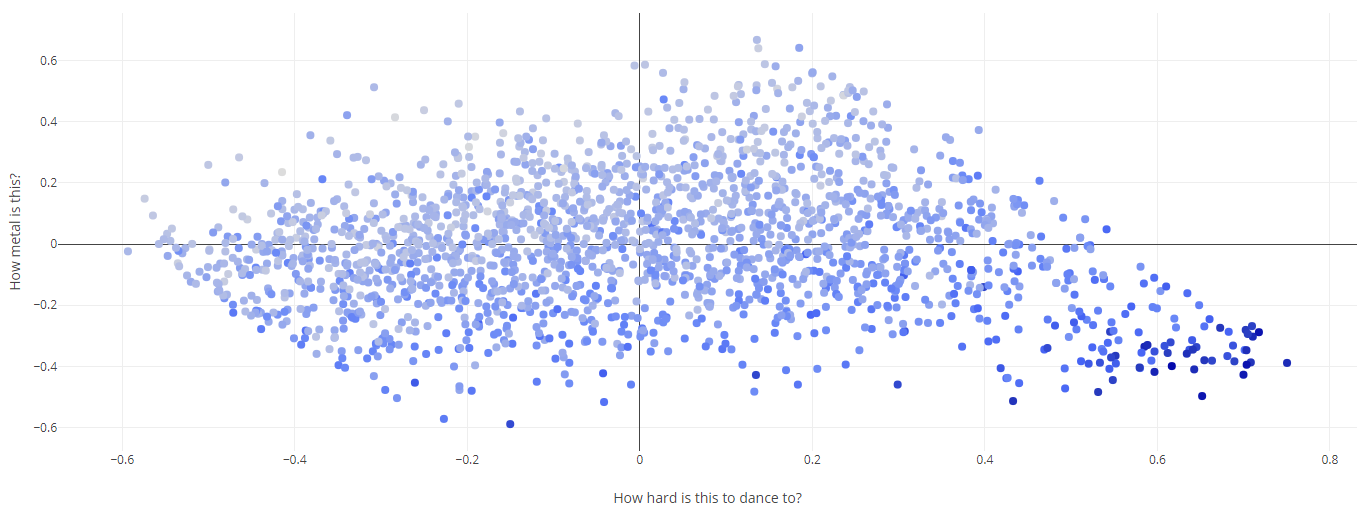 В последнюю очередь мы генерируем аналогичный граф, используя t-SNE и еще один "выбранный" список. Алгоритм t-SNE, который также относят к методам множественного обучения признаков, был опубликован в 2008 году (ссылка 1 в конце статьи) голландским исследователем Лоуренсом ван дер Маатеном (сейчас работает в Facebook AI Research) и чародеем нейронных сетей Джеффри Хинтоном. Классический SNE был предложен Хинтоном и Ровейсом в 2002 (ссылка 2). В статье 2008 года описывается несколько «трюков», которые позволили упростить процесс поиска глобальных минимумов, и повысить качество визуализации. Одним из них стала замена нормального распределения на распределение Стьюдента для данных низкой размерности. Кроме того, была сделана удачная реализация алгоритма (в статье есть ссылка на MatLab), которая потом портировалась в другие популярные среды.  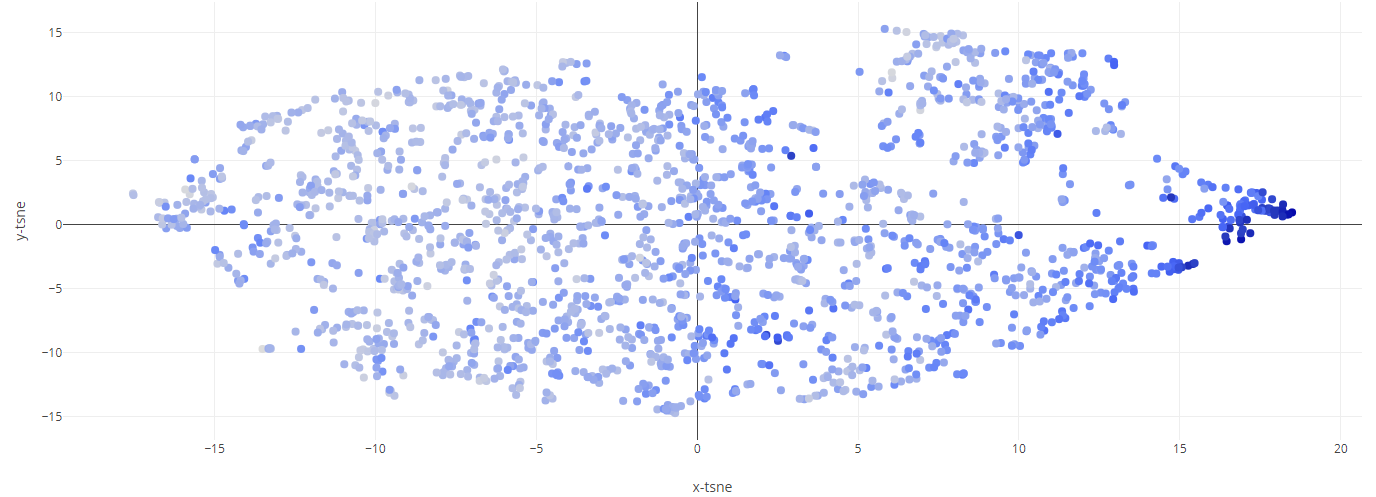 |