парсер. Автор Казьмина Анастасия, 4 курс. Баяндин Николай Иванович. Образовательное учреждение
 Скачать 5.47 Mb. Скачать 5.47 Mb.
|

|
Технологии анализа данных (Text Mining, Data Mining) Автор: Казьмина Анастасия, 4 курс. Руководитель: Баяндин Николай Иванович. Образовательное учреждение: Федеральное государственное бюджетное учреждение высшего профессионального образования "Московский государственный университет экономики, статистики и информатики (МЭСИ)", г. Москва Кто владеет информацией - тот владеет миром. В наше время трудно переоценить значение аналитики и мониторинга социальных медиа. Для быстрого и успешного развития бизнеса и эффективного продвижения в интернет, эти этапы просто необходимы. На сегодняшний день, всё большую популярность приобретают задачи, связанные с получением и накоплением новых знаний путём анализа ранее полученной информации. Возникла необходимость в создании больших хранилищ данных и систем поддержки принятия решений. Рассмотрим подробнее технологию анализа данных.  Наиболее перспективные направления анализа данных: анализ текстовой информации интеллектуальный анализ данных 1. Анализ текстовой информации Text MiningАнализ структурированной информации, хранящейся в базах данных, требует предварительной обработки: проектирования БД, ввод информации по определенным правилам, размещение ее в специальных структурах (например, реляционных таблицах) и т.п. Текстовые документы практически невозможно преобразовать в табличное представление без потери семантики текста и отношений между сущностями. По этой причине такие документы хранятся в БД без преобразований, как текстовые поля (BLOB-поля). В это же время в тексте скрыто огромное количество информации, но ее неструктурированность не позволяет использовать алгоритмы Data Mining. Решением этой проблемы занимаются методы анализа неструктурированного текста (Text Mining). Определение Text Mining: Обнаружение знаний в тексте - это нетривиальный процесс обнаружения действительно новых, потенциально полезных и понятных шаблонов в неструктурированных текстовых данных. "Неструктурированные текстовые данные" - набор документов, представляющих собой логически объединенный текст без каких-либо ограничений на его структуру (web-страницы, электронная почта, нормативные документы). Процесс анализа текстовых документов можно представить как последовательность нескольких шагов: 1. Поиск информации. В первую очередь необходимо понять, какие документы нужно подвергнуть анализу плюс обеспечить доступ. Пользователи могут определить набор анализируемых документов самостоятельно - вручную. 2. Предварительная обработка документов. Выполняются необходимые преобразования с документами для представления их в нужном виде. Удаление лишних слов и придание тексту более строгой формы. 3. Извлечение информации. Выделение ключевых понятий для анализа. 4. Применение методов Text Mining. Извлекаются шаблоны и отношения, имеющиеся в текстах. 5. Интерпретация результатов. Представлении результатов на естественном языке, или в их визуализации в графическом виде. Предварительная обработка документаПриемы удаления неинформативных слов и повышения строгости текстов: Удаление стоп-слов. Стоп-словами называются слова, которые являются вспомогательными и несут мало информации о содержании документа. Стэмминг - морфологический поиск. Он заключается в преобразовании каждого слова к его нормальной форме. Л-граммы это альтернатива морфологическому разбору и удалению стоп-слов. Позволяют сделать текст более строгим, не решают проблему уменьшения количества неинформативных слов; Приведение регистра. Этот прием заключается в преобразовании всех символов к верхнему или нижнему регистру. Наиболее эффективно совместное применение всех методов. 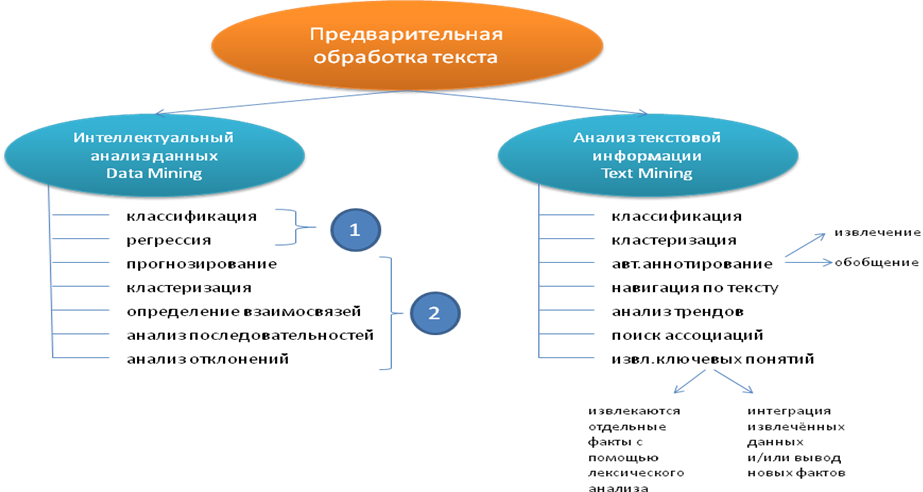 Задачи Text MiningКлассификация (classification) - определение для каждого документа одной или нескольких заранее заданных категорий, к которым этот документ относится, автоматическое выявление групп семантически похожих документов среди заданного фиксированного множества Автоматическое аннотирование (summarization) сокращение текста и сохранение его смысла. Результат включает в себя наиболее значимые предложения в тексте. Извлечения ключевых понятий (feature extraction) - идентификация фактов и отношений в тексте (имена существительные и нарицательные: имена и фамилии людей, названия организаций и др.). Навигация по тексту (text-base navigation) перемещение по документам по определённым темам и терминам. Это выполняется за счет идентификации ключевых понятий и некоторых отношений между ними. Анализ трендов позволяет идентифицировать тренды в наборах документов на какой-то период времени. Поиск ассоциаций. В заданном наборе документов идентифицируются ассоциативные отношения между ключевыми понятиями. Существует достаточно большое количество разновидностей перечисленных задач, а также методов их решения. Это еще раз подтверждает значимость анализа текстов. Примеры средства анализа текстовой информации: Средства Oracle - Oracle Text2. Средства от IBM - Intelligent Miner for Text1 Средства SAS Institute - Text Miner Интеллектуальный анализ данных Data MiningИнтеллектуальный анализа данных (англ. Data mining, другие варианты перевода - "добыча данных", "раскопка данных") - обнаружение неявных закономерностей в наборах данных. Интеллектуальный анализ данных может проводиться с помощью программных продуктов следующих классов: специализированных "коробочных" программных продуктов для интеллектуального анализа; математических пакетов; электронных таблиц (и различного рода надстроек над ними); средств интегрированных в системы управления базами данных (СУБД); других программных продуктов. Задачи интеллектуального анализа данных: Задача классификации определение категории и класса каждому объекту. Задача регрессии - поиск шаблонов для определения числового значения. Задача прогнозирования новых значений на основании имеющихся значений числовой последовательности. Учитываются тренды. анализ text data mining Задача кластеризации - деление множества объектов на группы (кластеры) с похожими параметрами. При этом, в отличие от классификации, число кластеров и их характеристики могут быть заранее неизвестны и определяться в ходе построения кластеров исходя из степени близости объединяемых объектов по совокупности параметров. Задача определения взаимосвязей - определение часто встречающихся наборов объектов среди множества подобных наборов. Анализ последовательностей - обнаружение закономерностей в последовательностях событий. Анализ отклонений - поиск событий, отличающихся от нормы. По способу решения задачи интеллектуального анализа можно разделить на два класса: обучение с учителем (от англ. supervisedlearning) и обучение без учителя (от англ. unsupervisedlearning). В первом случае требуется обучающий набор данных, на котором создается и обучается модель интеллектуального анализа данных. Готовая модель тестируется и впоследствии используется для предсказания значений в новых наборах данных. Во втором случае целью является выявление закономерностей имеющихся в существующем наборе данных. ВыводИнтеллектуальный анализ данных является одним из наиболее актуальных и востребованных направлений прикладной математики. Современные процессы бизнеса и производства порождают огромные массивы данных, и людям становится все труднее интерпретировать и реагировать на большое количество данных, которые динамически изменяются во времени выполнения. Нужно извлекать максимум полезных знаний из многомерных, разнородных, неполных, неточных, противоречивых, косвенных данных. А главное, сделать это эффективно, если объем данных измеряется гигабайтами или даже терабайтами. Важно предохранить людей от информационной перегрузки, преобразовать оперативные данные в полезную информацию так, чтобы нужные действия могли быть приняты в нужное время. Список используемой литературы и интернет - ресурсовЛ.М. Ермакова Методы классификации текстов и определения качества контента. Вестник пермского университета 2011. УДК 004.912 А.А. Барсегян, М.С. Куприянов, В.В. Степаненко, И.И. Холод: Технологии анализа данных. Data Mining, Visual Mining, Text Mining, OLAP: БХВ-Петербург, 2007 http://megaputer.ru/data_mining. http://www.compress.ru/ http://www.iteam.ru/ http://www.piter.com/ |