Билеты на экзамен по информатике (ХТФ, ПНИПУ). инфа билеты. 1. Определение информатики как науки. Данный термин получил распространение в 80х г г. Хх века. Производное от латинских inform информация
 Скачать 1.51 Mb. Скачать 1.51 Mb.
|

|
19. Этапы подготовки и решения задач на компьютере. Компьютер предназначен для решения разнообразных задач, поэтому можно выделить в процессе подготовки и решения задач этапы 1. Постановка задачи — формулируется цель решения задачи, подробно описывается ее содержание; проводится анализ условий, при которых решается поставленная задача, выявляется область определения входных параметров задачи. 2. Формальное построение модели задачи — предполагает построение модели с характеристиками, адекватными оригиналу; анализируется характер и сущность величин, используемых в задаче. 3. Построение математической модели задачи — характеризуется математической формализацией задачи, при которой существующие взаимосвязи между величинами выражаются с помощью математических соотношений. Как правило, математическая модель строится с определенной точностью, допущениями и ограничениями. 4. Выбор и обоснование метода решения — позволяет свести решение задачи к конкретному набору машинных команд. При обосновании метода решения рассматриваются вопросы влияния различных факторов и условий на конечный результат, в том числе на точность вычислений, время решения задачи на компьютере, требуемый объем памяти и др. 5. Построение алгоритма по выбранному методу решения. Процесс разбивается на отдельные относительно самостоятельные блоки с определенной последовательностью их выполнения. 6. Составление программы – алгоритм решения переводится на конкретный язык программирования. 7. Отладка программы – процесс устранения синтаксических и логических ошибок в программе. В процессе трансляции программы с помощью синтаксического и семантического контроля выявляются недопустимые конструкции и символы (или сочетания символов) для данного языка программирования. Компьютер выдает сообщение об ошибках в форме, соответствующей этому языку. Затем проверяется логика работы программы в процессе ее выполнения с конкретными исходными данными 8. Решение задачи на компьютере и анализ результатов. Первоначально выполняется многократное решение задачи на компьютере для различных наборов исходных данных, а полученные результаты анализируются. 20. Алгоритмизация и программирование. Синтаксис и семантика. Алгоритм – это формальное описание способа решения задачи путем разбиения её на конечную по времени последовательность действий (элементарных операций). Простые (базовые) типы данных. Переменные и константы. Реальные данные, с которыми работает программа, – это числа, строки и логические величины (аналоги 1 и 0, «да» и «нет», «истина» и «ложь»). Эти типы данных называются базовыми. Каждая единица информации хранится в ячейках памяти компьютера, имеющих свои адреса (путь). Чтобы не следить за тем, по какому адресу будут записаны данные, в языках программирования введено понятие переменной, позволяющие отвлечься от конкретных адресов и обращаться к содержимому памяти с помощью идентификатора или имени. Имя будет указывать на значение, о реальном адресе и способе хранения которого можно забыть. Переменная- именованный объект, который может изменять свое название Кроме имени и значения, переменная обычно имеет тип, определяющий, какая информация хранится в данной переменной, способ ее хранения и адрес остаются скрытыми. Тип переменной задает-использование способа записи инф в ячейке памяти, необходимый V памяти для хранения. Переменные могут существовать на всем протяжении работы программы – тогда они называются статистическими, а могут создаваться и уничтожаться на разных этапах её функционирования – такие переменные называются динамическими. Все остальные данные в программе, значения которых не меняются на протяжении её работы, называются константами, которые тоже имеют свой тип Синтаксис и семантика. Языки программирования – это формальные языки, имеющие алфавит, словарный запас, свои грамматику и синтаксис, а также семантику. Алфавит-разрешенный к исполнению набор символов, с помощью которых могут быть обозначены слова и величины данного языка. Синтаксис-система правил, определяющая допустимые конструкции языков программирования из букв алфавита позволяющая, формировать проверку текстовых программ, выделив мн-во синтаксически правильных программ; разбить эти программы на составляющие конструкции и в конце концов на лексемы. Семантика-система правил, однозначного толкования каждой языковой конструкции, позволяющих производить процесс обработки данных. Взаимодействие семантических и синтаксических правил определяет основные понятия языка, такие как операторы, идентификаторы, константы и т.д В отличие от естественного языка, языки программирования имеют запас слов и строгие правила их нахождения по написанию. Языки программирования, ориентированные на команды процессора и учитывающие его особенности, называют языками низкого уровня. «Низкий уровень» не означает неразвитый, имеется в виду, что операторы этого языка близки к машинному коду и ориентированы на конкретные команды процессора. Языком самого низкого уровня является ассемблер. Программа, написанная на нем, представляет последовательность команд машинных кодов, но записанных с помощью символьных мнемоник. Языки программирования, имитирующие естественные, обладающие укрупненными командами, ориентированные «на человека», называют языками высокого уровня. Разрабатывать программы на языках высокого уровня с помощью понятных и мощных команд значительно проще, число ошибок, допускаемых в процессе программирования, намного меньше. В настоящее время существует несколько сотен таких языков, например C++, C#, Delphi, Fortran, Java, Лисп, Паскаль 21. Интерпретация и компиляция программ. Трансляция программы — преобразование программы, представленной на одном из языков программирования, в программу на другом языке и, в определённом смысле, равносильную первой. При трансляции выполняется перевод программы, понятной человеку, на язык, понятный компьютеру. Выполняется специальными программными средствами (транслятором). Существует 2 основных вида трансляции: · Компиляция – метод выполнения программ, при котором инструкция программы выполняется лишь тогда, когда собран перевод всего текста программы Компилятор полностью обрабатывает весь текст программы или исходный код. Компиляторы выполняют поиск синтаксических ошибок, выполняют сематический анализ и только затем, если текст полностью соответствует правилам языка, автоматически переводит его на машинный язык или объектный код. Сгенерированный объектный код обрабатывается специальной программой –редактором связей, который производит связывание объектного и машинного кодов. Текст преобразуется в готовый к исполнению файл, который может быть сохранен либо в памяти комп, либо на внешнем носителе. Исх код-трансляция-объектный код-редактор связей-загрузочный модуль Недостатки компилятора: -трудоемкость трансляции языка программирования, ориентированного на обработку данных сложных конструкций. · Интерпретация – метод выполнения программ, при котором инструкции программы, переводятся и сразу же выполняются С помощью языков программирования создается текст программы, описание разработки алгоритмов, чтобы программа была выполнена надо либо весь ее текст перевести в машинный код (компилятор)и затем передать на исполнение процессору, либо выполнить команды языка, переводя на машинный язык и использовать каждую программу поочередно (интерпретатор) Интерпретаторы функционируют след образом: берется очередной оператор из текста программы, анализируется его структура, затем сразу же производится использование. После успешного выполнения текущей команды переходит к анализу и использованию след команды. Если один и тот же оператор в программе выполняется несколько раз. Интерпретатор всякий раз воспринимает его как будто впервые. Интерпретатор более надежный чем компилятор. В реальных системах программирования смешаны технологии компиляции и интерпретации. В процессе отладки программу можно выполнять по шагам (трассировать), а результирующий код не обязательно будет машинным, он может быть, например, аппаратно-независимым промежуточным кодом абстрактного процессора, который в дальнейшем будет транслироваться в различных компьютерных архитектурах с помощью интерпретаторов или компиляторов в соответствующий машинный код. Процесс создания программ-включения -создание исходного кода на языке программирования -этап трансляции, необходим для создания объектного кода программ -построение загрузочного модуля с помощью редактора связей Все эти действия требуют специальных программных средств. 24. Основные понятия реляционных бд: поля и записи, свойства полей, типы данных, системы управления бд. Модели данных.Ядром любой базы данных является модель представления данных. Наиболее распространенной и универсальной моделью данных является реляционная модель данных, которая ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица должна обладать следующими свойствами: - один элемент таблицы – один элемент данных; - все столбцы таблицы содержат однородные по типу данные; - каждый столбец имеет уникальное имя; - число столбцов задается при создании таблицы; - порядок записей отношений может быть произвольным; - записи не должны повторяться; - количество записей отношений не ограничено. В реляционной таблице каждый столбец есть домен, а совокупность элементов каждой строки – кортеж (или запись). Строка заголовков называется схемой отношения. В отношении каждый конкретный экземпляр сущности представляется строкой, которая также называется кортежем (или записью). Св-ва полей: Имя поля – определяет, как следует обращаться к данным этого поля при автоматических операциях с базой •Тип поля – определяет тип данных, которые могут содержаться в данном поле. • Размер поля – определяет предельную длину (в символах) данных, которые могут размещаться в данном поле. •Формат поля – определяет способ форматирования данных в ячейках, принадлежащих полю. •Маска ввода – определяет форму, в которой вводятся данные в поле (средство автоматизации ввода данных). •Подпись – определяет заголовок столбца таблицы для данного поля •Значение по умолчанию – то значение, которое вводится в ячейки поля автоматически (средство автоматизации ввода данных). •Условие на значение – ограничение, используемое для проверки правильности ввода данных (средство автоматизации ввода, которое используется, как правило, для данных, имеющих числовой тип, денежный тип или тип даты). •Сообщение об ошибке – текстовое сообщение, которое выдается автоматически при попытке ввода в поле ошибочных данных •Обязательное поле – свойство, определяющее обязательность заполнения данного поля при наполнении базы; •Пустые строки – свойство, разрешающее ввод пустых строковых данных Рассмотрим пример реляционной таблицы: 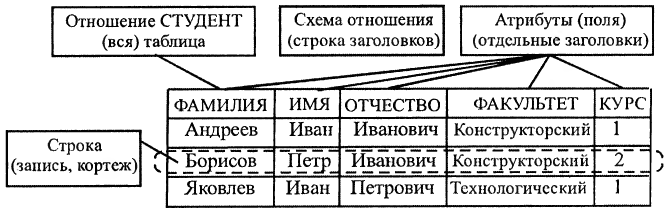 Первичным ключом отношения называется поле или группа полей, однозначно определяющие запись. На примере таблицы первичным ключом может быть поле «ФАМИЛИЯ», если во всем списке нет однофамильцев – это будет простой ключ. Если есть однофамильцы, то совокупность полей – «ФАМИЛИЯ, ИМЯ, ОЧЕСТВО» – создадут составной первичный ключ. На практике обычно в качестве ключевого выбирают поле, в котором совпадения заведомо исключены. Первичный ключ должен обладать следующими свойствами: - уникальность – в таблице может быть назначен только один первичный ключ, у составного ключа поля могут повторяться, но не все одновременно; - неизбыточность – не должно быть полей, которые, будучи удаленными из первичного ключа, не нарушает его уникальность; - в состав первичного ключа не должны входить поля типа, комментарий, графический и так далее. Типы данных Информационные системы работают со следующими основными типами данных. Текстовые данные. Значение каждого текстового (символьного) данного представлено совокупностью произвольных алфавитно-цифровых символов, длина которой чаще всего не превышает 255 (например, 5, 10, 140). Текстовыми данными представляют в ИС фамилии и должности людей, названия фирм, продуктов, приборов и т.д. Числовые данные. Данные этого типа обычно используются для представления атрибутов, со значениями которых нужно проводить арифметические операции (весов, цен, коэффициентов и т.п.). Данные типа даты и (или) времени. Данные типа даты задаются в каком-то известном машине формате, например, ДД.ММ.ГГ (день, месяц, год). Однако использование в ИС особого типа для даты имеет следующие преимущества. Во-первых, система получает возможность вести жесткий контроль. Во-вторых, появляется возможность автоматизированного представления формата даты в зависимости от традиций той или иной страны В-третьих, при программировании значительно упрощается арифметические операции с датами Логические (булевые) данные. Данное этого типа может принимать только одно из двух взаимоисключающих значений – True или False (условно: 1 или 0). Фактически это переключатель, значение которого можно интерпретировать как «Да» и «Нет» или как «Истина» и «Ложь». Логический тип удобно использовать для тех атрибутов, которые могут принимать одно из двух взаимоисключающих значений. Совокупность программ, реализующих в базе данных функции информационных систем в удобной для пользователя форме, называется системой управления базой данных (СУБД). Основные действия, которые пользователь может выполнять с помощью СУБД: создание структуры БД; заполнение БД информацией; изменение (редактирование) структуры и содержания БД; поиск информации в БД; сортировка данных 23.Базы данных (бд). Назначение бд. Проектирование и обработка бд. В истории развития вычислительной техники наблюдалось два основных направления ее применения. 1. выполнение больших численных расчетов, которые трудно или просто невозможно произвести вручную. Развитие этой области способствовало ускорению развития методов математического моделирования, численных методов, языков программирования высокого уровня Для задач данного типа характерны большие объемы вычислительной работы при относительно небольших потребностях в памяти. 2. связано с использованием СВТ для создания, хранения и обработки больших массивов данных. Задачи данного типа требуют больших объемов внешней памяти при относительно небольших расчетах. Одна из причин возникновения - отсутствие возможности хранения больших объемов данных у 1 направления. Данные задачи решают информационные системы (ИС) Информационная система представляет собой аппаратно-программный комплекс, обеспечивающий выполнение следующих функций: - ввод данных об объектах некоторой предметной области; - надежное хранение и защита данных во внешней памяти вычислительной системы; - дополнение, удаление, изменение данных; - сортировка, выборка данных по запросам пользователей; - выполнение специфических для данной предметной области преобразований информации; - предоставление пользователям удобного интерфейса; - обобщение данных и составление отчетов. Объем данных в информационных системах может исчисляться миллиардами байт. Отсюда возникает необходимость в устройствах, способных хранить большие объемы данных во внешней памяти. Число пользователей данных систем может достигать десятков тысяч, что создает немало проблем в реализации эффективных алгоритмов функционирования ИС. Для успешного решения данных задач необходимо чтобы данные в системе были структурированы. При структурировании данных первоначально из всего многообразия данных выбираются только некоторые, другими словами создается информационная модель объекта. Затем данные упорядочиваются по порядку следования, по применяемым типам или форматам данных, после чего уже обрабатываются компьютером. Совокупность взаимосвязанных данных называется структурой данных. Совокупность структурированных данных, относящихся к одной предметной области, называется базой данных (БД). Совокупность программ, реализующих в базе данных функции информационных систем в удобной для пользователя форме, называется системой управления базой данных (СУБД). Программы, производящие специфическую обработку данных в базе данных, составляют пакет прикладных программ (ППП). Информационные системы – это организационное объединение аппаратного обеспечения (АО), одной или нескольких баз данных (БД), системы управления базами данных (СУБД) и пакетов прикладных программ (ППП). Классификация БД По технологии обработки данных базы данных подразделяются на централизованные и распределенные. Централизованная база данных хранится целиком в памяти одной вычислительной системы. Если система входит в состав сети, то возможен доступ к этой базе данных других систем. Распределенная база данных состоит из нескольких, возможно пересекающихся или дублирующих друг друга баз данных, хранимых в памяти разных вычислительных систем, объединенных в сеть. По способу доступа к данным, базы данных подразделяются на локальный и удаленный (сетевой) доступ. Локальный доступ предполагает, что система управления базой данных обрабатывает базу данных, которая хранится на том же компьютере. Удаленный доступ – это обращение к базе данных, которая хранится на одном из компьютеров, входящих в компьютерную сеть. Удаленный доступ может быть выполнен по принципу файл-сервер или клиент-сервер. Архитектура файл-сервер предполагает выделение одного из компьютеров сети (сервер) для хранения централизованной БД. Все остальные компьютеры сети (клиенты) они могут использовать информацию, копировать ее в свою память, образуют обработку. Недостаток-снижение производительности за счет увелич нагрузки на канал сети. Архитектура клиент-сервер: сервер еще дополнительно производит обработку клиентских запросов, клиент получает обрабатываемые данные. Увелич быстродействие к серверу может обращаться любое число клиентов. Проектирование баз данных. Создание любой БД начинается с проектирования, которое включает след. Этапы 1.исследование предметной области, 2. анализ данных, сущности или атрибутов 3. определение отношений м/у сущностями первичных вторичных ключей в процессе проектирования определяется структура реляц таблиц БД: составом столбцов, типом данных, размерами столбцов , ключами таблиц Сущность-это любой конкретный или абстрактный объект, в рассмотренной предметной области, это базовые типы инф, которая хранится в БД.( студенты, клиенты, подразделения) Понятие тип сущности относится к набору однородной личности предметов или событий, выступающих как целое Экземпляр сущности относится к конкретной личности в наборе (Типом сущности может быть студент, а экземпляром – Петров, Сидоров) Атрибут-св-во сущности в предметной области. Его наименование должно быть уникальным для конкретного типа сущности ( для сущности студент могут быть использованы следующие атрибуты: фамилия, имя, отчество, дата и место рождения, паспортные данные и т.д.). Связь – взаимосвязь между сущностями в предметной области. Связи представляют собой соединения между частями БД(в реляционной БД – это соединение между записями таблиц). Сущности – это данные, которые классифицируются по типу, а связи показывают, как эти типы данных соотносятся один с другим. 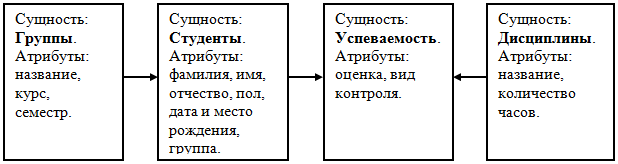 Из анализа данных предметной области следует, что каждой сущности необходимо назначить простейшую двумерную таблицу (отношения). Далее необходимо установить логические связи между таблицами. Между таблицами Студенты и Успеваемость необходимо установить такую связь, чтобы каждой записи из таблицы Студенты соответствовало несколько записей в таблице Успеваемость, т.е. один – ко – многим, так как у каждого студента может быть несколько оценок. Логическая связь между сущностями Группы – Студенты определена как один – ко – многим исходя из того, что в группе имеется много студентов, а каждый студент входит в состав одной группе. Логическая связь между сущностями Дисциплины – Успеваемость определена как один – ко – многим, потому что по каждой дисциплине может быть поставлено несколько оценок различным студентам. |