Модуль 3. 1. Память эвм, ее характеристики. Структура памяти. Постоянные запоминающие устройства (программируемые маской, перепрограммируемые eprom, eeprom). Оперативные запоминающие устройства статического и динамического типов. Стек. Виртуальная память
 Скачать 2.32 Mb. Скачать 2.32 Mb.
|

Часть команд работает в режиме чтение, модификация, запись. При обращении к порту эти команды активизируют сигнал чтения защелки, т.е. считывают содержимое триггеров, а не состояние внешних выводов. К таким командам относятся:
При обращении к внешней памяти содержимое фиксаторов защелок порта Р2 не меняется, а в защелке порта Р0 записываются 1. Для того чтобы порт работал на ввод данных в фиксаторы-защелки нужно записывать единицы, в противном случае возможно искажение считывания данных. Каждая линия порта может работать на ввод или вывод данных независимо от других. Порт Р0 не имеет внутренних подтягивающих транзисторов, поэтому при его использовании в качестве выходного порта общего назначения необходимо подключить внешние подтягивающие резисторы (5 – 10 кОм). Если Р0 используется только для обращения к памяти, то эти резисторы не нужны. После сброса микроконтроллера во все фиксаторы-защелки портов записаны единицы, т.е. они готовы к вводу данных. Структура прерываний МК-51 Система прерываний позволяет автоматически реагировать на внешние и внутренние события. В МК-51 существует 6 таких событий, т.е. 6 источников прерываний: 1, 2) внешние прерывания по входам /INT0, /INT1 3, 4) прерывания от таймера счетчика Т/С0 и Т/С1 5) окончание передачи данных последовательным портом 6) окончание приема данных последовательным портом Существует 5 векторов и 6 источников: Первые четыре источника имеют свои уникальные вектора, а 5й и 6й имеют один общий вектор. Под вектором прерываний понимается адрес, по которому содержится первая команда процедуры обработки прерывания. В счетчик команд в случае прерывания загружается адрес вектора прерывания. Адреса векторов аппаратно заданы. Управление системой прерываний осуществляется с помощью двух регистров:  Регистр разрешения прерывания IE (InteractEnable) Регистр разрешения прерывания IE (InteractEnable)EX0, EX1 – биты разрешения внешних прерываний по входам /INT0 и /INT1 ЕТ0, ЕТ1 – биты разрешения прерывания от 0го Т/С и 1го Т/С ES – бит разрешения прерывания от последовательного порта EA – бит общего разрешения прерываний если EA = 0, то все прерывания запрещены/ Регистр приоритетов прерываний IP  Существует два уровня приоритетов. 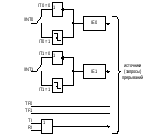 Прерывание имеет высокий приоритет, если соответствующий бит регистра IP равен 1, иначе прерывание имеет низкий приоритет. Прерывание имеет высокий приоритет, если соответствующий бит регистра IP равен 1, иначе прерывание имеет низкий приоритет.Процедура обработки прерываний с низким приоритетом может быть прервана процедурой обработки прерывания с высоким приоритетом. Процедура обработки прерывания не может быть прервана обработкой процедуры с равным приоритетом. Запрос внешнего прерывания может быть вызван нулевым уровнем сигнала на внешнем входе, либо спадом сигнала. При поступлении запроса от /INT0 устанавливается флаг запроса прерывания IE0. По входу /INT1 – IE1. Эти прерывания могут быть вызваны программно установкой флага запроса IE0 или IE1. В случае если прерывания произошло по спаду соответствующий флаг запроса сбрасывается аппаратно при вызове процедуры обработки. При прерывании по уровню флаг запроса будет сброшен только при восстановлении 1 на внешнем входе. Запрос на прерывание от Т/С формируется установкой флага переполнения. TF0 соответствует T/C0. TF1 соответствует Т/С1. Сбрасываются эти флаги аппаратно при вызове процедуры обработки прерывания. (Флаги IE0, IE1, TF0, TF1 могут устанавливаться и сбрасываться как программно, так и аппаратно) Флаг TI устанавливается по окончании передачи данных последовательным портом, флаг RI по окончании приема. Флаги вызывают одну и туже процедуру обработки прерываний, следовательно они аппаратно не сбрасываются и должны быть сброшены программно в процедуре обработки. Флаги запросов прерываний устанавливаются вне зависимости от того разрешено данное прерывание или нет. Внутри одного уровня приоритета существует подуровень, определяемый порядком опроса источников. Если одновременно произошло несколько запросов одного уровня, то в начале будет вызвана процедура обработки источника опрашиваемого первым. Последовательность опроса: IE0 TF0 IE1 опрос приоритет TF1 RI + TI Вызов процедуры обработки разрешенного прерывания может быть временно заблокирован в случае:
После окончания выполнения этих команд будет выполнена еще хотя бы одна команда. Часто встречается понятие вектора сброса, под ним понимается адрес, загружаемый в счетчик команд после сброса процессора (как правило это 0). Режимы работ последовательного интерфейса МК-51. Предназначены для организации ввода/вывода данных в последовательном коде и системы прерывания. Состав блока:
Регистр SCON: SM0, SM1 – определяет один из четырех возможных режимов работы последовательного порта SM2 – бит разрешения многопроцессорной работы Бит управления режимом UART. Устанавливается программно для запрета приема сообщения, в котором девятый бит имеет значение 0 REN – бит разрешения приема данных TB8, RB8 – в режимах 2 и 3 9й передаваемый и 9й принимаемый биты данных TI, RI – флаг переполнения по окончании передачи/приема Буфер передатчика предназначен для приема с внутренней шины МК информации в параллельном коде и ее выдаче в последовательном с помощью сдвигового регистра через вывод TxD. Буфер приемника предназначен для приема данных в последовательном коде со входа RxD, хранения и выдачи в параллельном коде на внутреннюю шину. Наличие буферного регистра приемника позволяет совмещать операцию чтения ранее принятого байта с приемом очередного байта. Прием и передача данных начинается с младшего бита, передача данных инициируется командой записи в регистр SBUF. Прием и передача могут осуществляться параллельно. Очередной байт будет приниматься даже если полученные перед этим данные не были считаны из буфера приемника. По окончании приема старый байт будет потерян. Режимы работы: 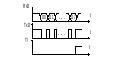 Режим 0: В этом режиме последовательный порт работает как 8ми разрядный сдвиговый регистр. Данные передаются и принимаются через RxD, через TxD передаются синхроимпульсы. Скорость передачи/приема одна и та же (не меняется). Режим 0: В этом режиме последовательный порт работает как 8ми разрядный сдвиговый регистр. Данные передаются и принимаются через RxD, через TxD передаются синхроимпульсы. Скорость передачи/приема одна и та же (не меняется).fT/R = fBQ / 12 (бод) – частота следования машинных циклов (fBQ – частота кварцевого резонатора). Временные диаграммы: Передача данных: TxD принимает синхроимпульсы. Когда данные не передаются RxD = TxD = 1. Синхронизация осуществляется по спаду сигнала. 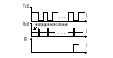 По умолчанию RxD и TxD принимают единичное состояние, передача данных через RxD стробируется спадом сигнала на выходе TxD. RxD и TxD работают на выдачу информации. По умолчанию RxD и TxD принимают единичное состояние, передача данных через RxD стробируется спадом сигнала на выходе TxD. RxD и TxD работают на выдачу информации.Прием данных: В режиме приема данных TxD и RxD работают на ввод, т.е. один принимает синхроимпульсы, другой данные. По окончании приема данных устанавливается флаг RI. В этом режиме прием выполняется при: RI = 0; REN = 1 – бит разрешения приема. Этот режим является синхронным, остальные являются асинхронными. Режим1: В этом режиме последовательный порт работает как 8ми разрядный универсальный асинхронный приемо-передатчик (УАПП или UART). (СОМ порты у персональных ЭВМ работают в этом режиме) 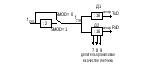 Через RxD принимаются, а через TxD передаются 10ти разрядные посылки, включающие нулевой старт-бит, 8 бит данных и единичный стоп-бит. Через RxD принимаются, а через TxD передаются 10ти разрядные посылки, включающие нулевой старт-бит, 8 бит данных и единичный стоп-бит.При приеме стоп-бит заносится в разряд RB8 регистра SCON. Скорость обмена задается частотой переполнения T/C1 – fOV1. На скорость передачи данных также влияет состояние бита SMOD регистра PCON. fT/R = fOV1 / (16*2SMOD) 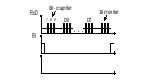 В режиме можно изменять скорость и частоту переполнения Т/С. Скорость приема/передачи — величина переменная и зад таймером. В режиме можно изменять скорость и частоту переполнения Т/С. Скорость приема/передачи — величина переменная и зад таймером.Формирование сигналов синхронизации передачи и управления: Временные диаграммы: Передача данных: 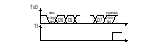 Прием данных начинается при обнаружении спада сигнала на входе RxD, для этого RxD опрашивается аппаратно с частотой fT/R. Если обнаружен спад сигнала, то происходит сброс счетчика-делителя на 16 в цепи сигнала синхронизации RxD (Д2). В моменты когда содержимое Д2 равно 7, 8 или 9 производится считывание состояния RxD, результат выбирается по мажоритарному принципу. Считанные 8 бит данных и стоп-бит из сдвигового регистра записываются в буфер приемника SBUF и бит RB8 соответственно. Загрузка SBUF, загрузка RB8 и установка RI происходит только в случае если к моменту последнего опроса выполнялось следующее: RI = 0 и SM = 0 или RI = 0 и стоп-бит = 1. Если хотя бы одно из этих условий не выполняется, то принятые данные теряются, а флаг RI не устанавливается. Режим 2 и 3: В этих режимах приемо-передатчик работает как 9ти разрядный УАПП. В режиме 2 скорость обмена постоянна, в режиме 3 может меняется задается таймером. Здесь посылка состоит из 11 бит, из них один нулевой старт-бит и единичный стоп-бит. Значение 9го бита данных берется из разряда TB8 регистра SCON. Принятый 9й бит записывается в RB8. В режиме 2 скорость обмена данными: fT/R = fBQ / 64 * 2SMOD fBQ – частота тактового генератора В режиме 3: fT/R = fOV1 / (32*2SMOD) fOV1 – частота переполнения 1го таймера-счетчика По приему и передачи режимы 2 и 3 аналогичны первому. 2й и 3й режимы отличаются между собой только скоростью обмена. Передача данных происходит аналогично 1му режиму, при приеме данных запись в SBUF, RB8 и установка флага RI производится при условии, что к моменту последнего опроса RI = 0 и SM = 0, либо RI = 0 и D8 = 0 (9й бит данных). Обязательное условие: принятый стоп-бит равен 1. Для использования Т/С1 в качестве задатчика скорости обмена необходимо запретить прерывания от Т/С1; установить Т/С1 в режим 0, 1 или 2; запустить Т/С1 на счет. SM2 - бит разрешения многопроцессорной работы. Режим 2 и 3 могут быть использованы для организации многопроцессорной системы, если SM2 = 1, то флаг RI будет устанавливаться только в том случае, когда принятый 9й бит = 1.  Регистр PCON: Регистр PCON:Микросхемы изготовлены по n-МОП технологии, имеют только один разряд SMOD, остальные не используются. SMOD - бит удвоения скорости передачи GF0, GF1 - флаги общего назначения PD - Power Down - бит включения режима микропотребления IDL - Idle - бит включения режима "холостого хода" PD. При переходе в этот режим отключаются все узлы микро ЭВМ, в том числе задающий генератор, сохраняется содержимое ОЗУ, напряжение питания может быть снижено до 2В. Выход из этого режима возможен только подачей сигнала сброса. Перед сбросом должно быть установлено напряжение питания. IDL. Также предназначен для умменьшения энергопотребления. В этом режиме продолжает работать тактовый генератор и система прерываний. Выход возможен как подачей сигнала сброса, так и формированием запроса внешнего прерывания. После установки PD или IDL выполнение программы прекращается. 14.Базы данных (БД). Системы управления базами данных (СУБД). Состав СУБД и назначение компонентов. Сравнительные характеристики существующих СУБД. Основные этапы проектирования информационной системы. На сегодняшний день не существует единого понятия БД. Иногда под БД подразумевают хранилище информации, иногда совокупность данных, а иногда систему, обеспечивающую функционирование информационного комплекса. Будем понимать под БД:
Совокупность данных должна быть определённым образом организована, т.е:
Наиболее широко БД используются в управленческой деятельности благодаря следующим свойствам:
Системы управления базами данных (СУБД) используются для упорядоченного хранения и обработки больших объемов информации. В процессе упорядочения информации СУБД генерируют базы данных, а в процессе обработки сортируют информацию и осуществляют ее поиск.
Основные функции СУБД: 1. Непосредственное управление данными во внешней памяти. Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД. 2. Управление буферами оперативной памяти. СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. 3. Управление транзакциями. Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. 4. Журнализация. Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД. Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. 5. Поддержка языков БД Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). Состав СУБД. 1) внутреннее устройство Логически в современной реляционной СУБД можно выделить
2) интерфейс пользователя
Краткое сравнение СУБД
Основные этапы проектирования информационной системы. Информационные системы - это системы, которые информируют пользователя системы о той или иной сфере жизнедеятельности человека. Например: информационная система "Зарплата ", в которой содержится информация о сотрудниках, которые работают в фирме. Оболочка информационной системы - это программа, которая обеспечивает удобное взаимодействие пользователя и системы и чаще всего является СУБД. Пользователь, при помощи оболочки, может получить любую интересующую его информацию. Целью любой информационной системы является обработка информации и предоставление наглядных результатов пользователю. Стадия 1. Формирование требований к ИС.
Стадия 2. Разработка концепции ИС.
Стадия 3. Техническое задание.
Стадия 4. Эскизный проект.
Стадия 5. Технический проект.
Стадия 6. Рабочая документация.
Стадия 7. Ввод в действие.
Стадия 8. Сопровождение ИС.
15.Модели данных: иерархическая, реляционная, сетевая. Физическая организация данных в реляционных базах. Удаление, добавление, изменение записей. Индексация. На сегодняшний день не существует единого понятия БД. Иногда по БД подразумевают хранилище информации, иногда совокупность данных, а иногда систему, обеспечивающую функционирование информ комплекса. Будем понимать под БД совокупность данных, организованных с определённой целью. Совокупность данных должна быть определённым образом организована, т.е:
Модели данных.Модели данных характеризуют принцип построения БД. 1) модель управления файлами До появления СУБД все данные содержались в компьютерной системе постоянно в виде отдельных файлов. Система управления файлами, которая обычно являлась частью операционной системы, следила за именами и месторасположением файлов. В системах управления фалами модели данных, как правило, не использовались – эти системы ничего не знали о содержимом файлов. Знание содержимого и структуры файлов было целиком уделом прикладных программ, которые работали с этими файлами. Таким образом, для того, чтобы изменить структуру файла (например, добавить ещё одно поле) приходилось менять код всех программ, работавших с этими файлами. Проблемы сопровождения больших БД, основанных на файлах, привели к появлению СУБД – систем управления базами данных. В основе СУБД лежала простая идея – изъять из программ определение структуры содержимого файла и хранить её вместе с данными в БД. 2) иерархическая модель Эта модель была разработана для хранения данных, имеющих иерархическую структуру в виде дерева записей (например, БД библиотеки). В этой модели каждая запись представляла конкретный объект (например, книгу). Между записями существовали отношения типа «предок/потомок», связывающие записи между собой (например, автор à книга à том №1). Чтобы получить доступ к данным БД, программа могла: - найти конкретную книгу; - перейти «вниз» на 1 уровень к первому потомку (том №1); - перейти «вверх» на 1 уровень к предку (автор книги); - перейти «в сторону» к другому потомку (другая книга этого же автора). В данной БД можно найти все книги автора по его фамилии: задаём фамилию и находим все записи. Но что делать, если нам известно название книги, но неизвестен автор? Для получения результатов поиска по такому запросу придётся просматривать всех авторов. Книга может иметь несколько авторов, и, в то же время, одним и тем же автором написано несколько книг. Такой тип связи называется «многие-ко-многим» и он не может быть описан с помощью иерархической модели, т.к. в ней предполагается, что каждый потомок имеет только одного предка. Поэтому была придумана сетевая модель. 3) сетевая модель Является улучшенной иерархической моделью – в ней одна и та же запись может участвовать в нескольких отношениях «предок/потомок», а такой тип отношений называется множеством. Преимущества сетевых баз данных:
Недостатки имеют жёсткую структуру и наборы записей – их приходится задавать наперёд; изменение структуры БД обычно означает перестройку всей БД 4) реляционная модель. Реляционная база данных - это совокупность отношений или двумерных таблиц.  Отношение – это математическая концепция, описывающая, как соотносятся между собой элементы двух множеств. В нашем случае такими множествами являются множества строк и множества столбцов, поэтому отношение – это двумерная таблица с некоторыми спец свойствами. Отношение – это математическая концепция, описывающая, как соотносятся между собой элементы двух множеств. В нашем случае такими множествами являются множества строк и множества столбцов, поэтому отношение – это двумерная таблица с некоторыми спец свойствами.Концепция реляционной модели:
Таблица - основная структура хранения данных, состоящая из одного или нескольких столбцов и нуля или более строк (или записей, представляющих собой комбинацию значений столбцов). На пересечении столбцов и строк находятся значения полей.
Первичный ключ - столбец или набор столбцов, однозначно идентифицирующих каждую строку в таблице. Должен содержать конкретное значение
Внешний ключ - столбец или набор столбцов, содержащих ссылку на первичный ключ в той же самой или другой таблице. С помощью внешних ключей можно логически связывать информацию из нескольких таблиц
Объекты базы данных:
Физическая организация данных в реляционной БД. Все данные в РБД (реляционной базе данных) хранятся в таблицах, а связь между таблицами определяет саму структуру данных. Для каждой таблицы имеется свой файл данных и свой файл индекса. Файл индексов в десятки раз меньше файла данных и его размер зависит от того, что взяли в качестве ключа; файл индексов содержит структурированный набор данных, а файл данных – нет. 1) поиск записи Поиск записи в реляционной базе данных производится по файлу индексов. Найдя индекс удовлетворяющей запросу записи, далее по ссылке берутся данные из файла данных. 2) добавление записи При добавлении записи в базу данных без файла индекса приходилось бы просматривать всю БД в поисках необходимого места вставки (чтобы записи в файле данных были записаны по порядку), а затем переписывать весь файл БД заново: записываем часть БД до места вставки, добавляем запись, дописываем оставшуюся часть после добавления записи. При большом файле БД эти операции потребовали бы неоправданной нагрузки файловой подсистемы. При использовании файла индекса вставка (добавление) записи происходит так: в файл индекса (поскольку он в общем случае представляет собой таблицу с 2-мя полями) вставляем новую запись – индекс. При этом из-за малого размера файла индексов по сравнению с файлом данных мы не очень сильно нагружаем систему; сами же данные дописываются в конец файла данных, что даёт возможность производить добавление записей с одинаковой скоростью в независимости от размера БД. 3) удаление записи В реляционной БД при удалении записи не происходит её физического удаления из БД. В этом случае, удаляемая запись удаляется из файла индекса, а в файле данных помечается как удалённая и далее становится недоступной для обработки. Физическое удаление помеченных как «удалённые» записей происходит либо по команде от пользователя, либо по накоплению какого-то порогового значения удалённых записей (т.е. во время переиндексации). Тогда файл БД переписывается в порядке, обратном порядку добавления записи. 4) изменение записи На самом деле представляет собой последовательную комбинацию операций удаления старой записи и добавления новой с изменёнными значениями. 5) индексация Это процедура построения индекса для файла данных. Переиндексация может производиться по команде от пользователя либо при достижении определённых условий (например, количество помеченных на удаление записей превысило некоторое допустимое значение). При переиндексации текущий файл индексов удаляется, из файла данных физически удаляются помеченные на удаление записи и по обновлённому файлу данных заново строится файл индексов. 16.Реляционные базы данных. Реляционная_модель_основана_на_матем_понятии_отношения'>Основы реляционной алгебры. Отношения. Фундаментальные свойства отношений. Операции над отношениями. Общая интерпретация реляционных операций. Реляционная модель данных. Основные понятия реляционных баз данных. Нормализация и денормализация реляционной модели данных. Основные характеристики 1, 2, 3, нормальных форм. Реляционные системы управления базами данных. Реляционные базы данных Реляционная модель впервые была предложена Э.Ф.Коддом (E.F.Codd) в 1970. Цели создания реляционной модели формулировались следующим образом:
Коммерческие системы на основе реляционной модели данных начали появляться в конце 70-х – начале 80-х годов. В настоящее время существует несколько сотен ти пов различных РСУБД как для мейнфреймов, так и для микрокомпью теров, хотя многие из них не полностью удовлетворяют точному определению реля ционной модели данных. Примерами РСУБД для персональных компьютеров являются СУБД Access и FoxPro фирмы Microsoft, Paradox и Visual dBase фирмы Borland, а также R:Base фирмы Microrim. Благодаря популярности реляционной модели многие нереляционные системы те перь обеспечиваются реляционным пользовательским интерфейсом, независимо от используемой базовой модели. Основы реляционной алгебры Реляционная модель основана на матем понятии отношения, физ представлением которого является таблица. Отношение – это плоская таблица, состоящая из столбцов и строк. В любой реляционной СУБД предполагается, что пользователь воспринимает базу данных как набор таблиц. Однако это восприятие относит ся только к логической структуре базы данных. Подобное восприятие не относится к физ структуре базы данных, которая может быть реализована с помощью различных структур. Атрибут – это поименованный столбец отношения. В реляционной модели отношения используются для хранения информации об объектах, представленных в базе данных. Отношение обычно имеет вид двумерной табли цы, в которой строки соответствуют отдельным записям, а столбцы – атрибутам. При этом атрибуты могут располагаться в любом порядке, независимо от их переупорядочивания, отношение будет оставаться одним и тем же, а потому иметь тот же смысл. Домен – это набор допустимых значений для одного или нескольких атрибутов. Домены представляют собой чрезвычайно мощный компонент реляционной модели. Каждый атрибут реляционной базы данных определяется на некотором домене. Домены могут отличаться для каждого из атрибутов, но два и более атрибутов могут определяться на одном и том же домене. В табл. 2 представлен пример доменов для неко торых атрибутов отношений. Таблица 2 Домены некоторых атрибутов отношений 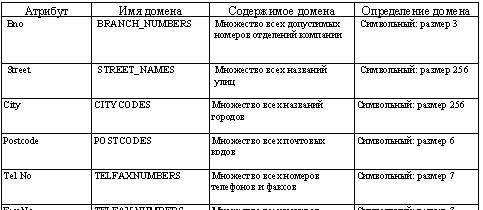 Элементами отношения являются кортежи, или строки таблицы. Кортеж – это строка отношения. Кортежи могут располагаться в любом порядке, при этом отношение будет оставать ся тем же самым, а значит, и иметь тот же смысл. Степень отношения определяется количеством атрибутов, кото рое оно содержит. Если Отношение имеет шесть атрибутов, следовательно, его степень равна шести. Это значит, что каждая строка таблицы является 6-арным кортежем. Отношение только с одним атрибутом имеет степень 1 и называется унарным (unary) отношением (или 1-арным кортежем). Отношение с двумя атрибутами называется бинарным (binary), отноше ние с тремя атрибутами – тернарным (ternary), а для отношений с большим количеством атрибутов используется термин n-арный (n-ary). Определение степени отношения является частью заголовка отношения. Реляционная база данных – набор нормализованных отношений. Реляционная база данных состоит из отношений, структура которых определяется с помощью особых методов, называемых нормализацией. Альтернативная терминология. Терминология, используемая в реляционной модели, порой может привести к пу танице, поскольку помимо предложенных терминов существует еще один. Отношение в нем называется файлом (file), кортежи – записями (records), а атрибуты – полями (fields). Эта терминология основана на том факте, что физически СУБД может хранить каждое отношение в отдельном файле. |
 Сдвиговые регистры приемника и передатчика
Сдвиговые регистры приемника и передатчика