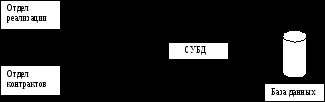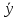Модуль 3. 1. Память эвм, ее характеристики. Структура памяти. Постоянные запоминающие устройства (программируемые маской, перепрограммируемые eprom, eeprom). Оперативные запоминающие устройства статического и динамического типов. Стек. Виртуальная память
 Скачать 2.32 Mb. Скачать 2.32 Mb.
|

Рис. 1. Связь между сущностямиСвязь представляется в виде линии, связывающей две сущности или ведущей от сущности к ней же самой. Обязательный конец связи изображается сплош ной линией, а необязательный – прерывистой линией. Как и сущность, связь – это типовое понятие, все экземпляры обеих пар связываемых сущностей подчиняются правилам связывания. На рис. 1. приведен пример изображения сущностей и связи между ними. Данная диаграмма может быть интерпретирована следующим образом: Каждый СТУДЕНТ учится только в одной ГРУППЕ; Любая ГРУППА состоит из одного или более СТУДЕНТОВ. На рис. 2 изображена сущность ЧЕЛОВЕК с рекурсив ной связью, связывающей ее с ней же самой. Лаконичной устной трактовкой изображенной диаграммы является следующая: Каждый ЧЕЛОВЕК является сыном одного и только одного ЧЕЛО ВЕКА; 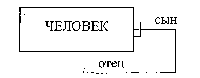 Рис. 2. Рекурсивная связь Каждый ЧЕЛОВЕК может являться отцом для одного или более ЛЮ ДЕЙ (“ЧЕЛОВЕКОВ”). Атрибутом сущности является любая деталь, которая служит для уточ нения, идентификации, классификации, числовой характеристики или вы ражения состояния сущности. Имена атрибутов заносятся в прямоуголь ник, изображающий сущность, под именем сущности и изображаются ма лыми буквами. Уникальным идентификатором сущности является атрибут, комбина ция атрибутов, комбинация связей или комбинация связей и атрибутов, уникально отличающая любой экземпляр сущности от других экземпля ров сущности того же типа. Это наиболее важные понятия ER-модели дан ных.  Модели данных 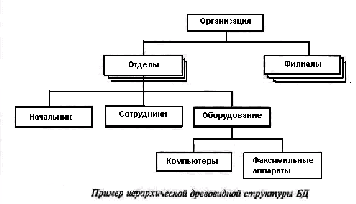 Рис. 3. Иерархическая древовидная структура БД Способ отображения сущностей, атрибутов и связей на структуры данных определяется моделью данных. Существуют 4 основные модели данных – списки, реляционные БД, иерархические и сетевые структуры. Рассмотрим их подробнее. Самый простой тип – это список – структура данных в виде линейной последовательности. Древовидные иерархические структуры широко используются в повседневной человеческой деятельности. Иерархические модели данных базируются на использовании графовой и табличной форм пред ставления данных. В графической диаграмме схемы базы данных вершина графа используется для интерпретации типов сущностей, а дуги – для интерпретации типов связей между типами сущностей. При реали зации вершины представляются таблицами описаний экземпляров сущностей соответствующего типа. На рис. 3 показан пример иерархической древовидной структуры БД. Основными внутренними ограничениями иерархической модели данных являются следующие: – все типы связей должны быть функциональными, т.е. 1:1, 1:М, М:1; – структура связей должна быть древовидной. Результатом действия этих ограничений явл. ряд особен ностей процесса структуризации данных в иерархической модели. 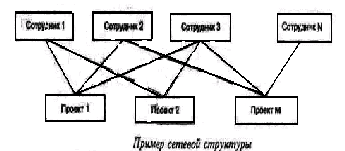 Рис. 5. Сетевая структура Сетевые модели дан ных также базируются на использовании графовой формы представления данных. Вершины графа используются для интер претации типов сущнос тей, а дуги – типов свя зей. Сетевая модель представления знаний – структура данных, в которой каждый объект, в отличие от иерархического представления, может иметь более одного господствующего узла (рис. 5). С появлением персональных ЭВМ реляци онные модели стали доминировать на рынке информационных систем. Реляционное представление знаний – представление знаний в виде отношений. В соответствии с реляционной моделью данных данные представляются в виде совокупности таблиц, над которыми могут выполняться операции, формулируемые в терминах реляционной алгебры или реляционного исчисления. Логическое_проектирование'>Логическое проектирование В предлагаемой методологии проектирования баз данных весь процесс разработки разделяется на три основные фазы: концептуальное, логическое и физическое проектирование. Логическое проектирование баз данных – это процесс конструирования общей информационной модели предприятия на основе отдельных моделей данных пользователей, которая является независимой от особенностей реально ис пользуемой СУБД и других физических условий. На предыдущем этапе получен набор локальных концептуальных моделей данных, отражающих представление пользователей о предметной среде. Однако эти модели могут содержать некоторые структуры данных, реализация которых в обычных типах СУБД будет затруднена. На этом эта пе подобные структуры данных преобразуются в такую форму, которая не вызовет затруднений при их реализации в среде существующих СУБД. На данном этапе выполняются следующие действия: 1. Удаление связей типа M:N. Если в концептуальной модели присутствуют связи типа M:N (“многие-ко-мно гим”), то их следует устранить путем определения некоторой промежуточной сущно сти. Связь типа M:N заменяется двумя связями типа 1:М, устанав ливаемыми со вновь созданной сущностью. 2. Удаление сложных связей. Сложной называется связь, существующая между тремя и больше типами сущно стей. Если в концептуальной модели присутствует сложная связь, ее следует устранить с помощью промежуточной сущности. Сложная связь заменяет ся необходимым количеством бинарных связей типа 1:М. 3. Удаление рекурсивных связей. Рекурсивными называются такие связи, в которых сущность некоторого типа взаимодействует сама с собой. Если концептуальная модель содержит рекурсивные связи, они должны быть устранены посредством определения неко торой промежуточной сущности. 4. Удаление связей с атрибутами. Если в концептуальной модели присутствуют связи, имеющие собственные атри буты, они должны быть преобразованы путем создания новой сущности.. 5. Удаление множественных атрибутов. Множественными называют атрибуты, которые могут иметь одновременно не сколько значений для одного и того же экземпляра сущности. Если в концептуальной модели присутствует множественный атрибут, его следует преоб разовать путем определения новой сущности. 6. Перепроверка связей типа 1:1. В процессе определения сущностей могли быть созданы две различные сущности, которые на самом деле представляют один и тот же объект в предметной области приложения.. В подобном случае следует объе динить эти две сущности в одну. 7. Удаление избыточных связей. Связь является избыточной, если одна и та же информация может быть получена не только через нее, но и с помощью другой связи. Система управления базами данных Система управления базами данных обладает следующими возможностями: 1) позволяет определять базу данных, что обычно осуществляется с помощью языка определения данных (DDL – Data Definition Language). Язык DDL предоставляет пользователям средства указания типа данных и их струк туры, а также средства задания ограничений для информации, хранимой в базе данных; 2) позволяет вставлять, обновлять, удалять и извлекать информацию из базы дан ных, что обычно осуществляется с помощью языка управления данными (DML – Data Manipulation Language). Существует две разновидности языков DML – процедурные (procedural) и непроцедурные (non-procedural) языки, – которые отличаются между со бой способом извлечения данных. Процедурные языки обычно обрабатывают информацию в базе данных последовательно, запись за записью, а непроцедурные опери руют сразу целыми наборами записей. Наиболее распространенным типом непроцедур ного языка является язык структурированных запросов (Structured Query Language – SQL). 3) предоставляет контролируемый доступ к базе данных с помощью перечис ленных ниже средств:
На рис. показан пример применения базы данных: физическая структура и способ хранения данных в этом слу чае контролируются с помощью СУБД. СУБД обладают как многообещающими потенциальными преимуществами, так и недостатками. Преимущества СУБД 1. Контроль за избыточностью данных. 2. Непротиворечивость данных.. 3. Совместное использование данных.. 4. Поддержка целостности данных. Целостность базы данных означает корректность и непротиворечивость хранимых в ней данных. 5. Повышенная безопасность. Безопасность базы данных заключается в защите базы данных от несанкциони рованного доступа со стороны пользователей.. 6. Применение стандартов.. 7. Повышение эффективности с ростом масштабов системы.. 8. Возможность нахождения компромисса для противоречивых требований. 9. Повышение доступности данных и их готовности к работе. 10. Улучшение показателей производительности. 11. Упрощение сопровождения системы за счет независимости от данных. 12. Развитые службы резервного копирования и восстановления. Недостатки СУБД1. Сложность. 2. Размер. 3. Стоимость СУБД. 4. Дополнительные затраты на аппаратное обеспечение. 5. Затраты на преобразование.. 6. Производительность.. 7. Более серьезные последствия при выходе системы из строя. Физическое проектирование Методология физического проектирования баз данных включа ет четыре основных этапа: 1. Разработка таблиц базы дан ных и установка необходимых ограничений целостности данных. 2. Выбор схемы хранения данных и определение методов доступа к таблицам базы данных. 3. Проектирование системы защиты базы данных от несанкциониро ванного доступа. 4. Организация процессов мониторинга созданной сис темы, задача которого состоит в выявлении и устранении любых проблем, связанных с производительностью приложений и вытекающих из особенностей реализации проекта. Здесь же осуществляется реализация новых и изменяющихся требований. 19.Компоненты базы данных и их назначение. Виртуальные таблицы, хранимые процедуры, функции определяемые пользователем, триггеры. Понятие транзакции. Организация взаимодействия интерфейса пользователя с хранилищем данных. Компоненты базы данных и их назначение.
Используются для фильтрации и предварительной обработки данных. Эта виртуальная таблица содержит результаты выполнения запроса (оператора SELCET) к одной или нескольким таблицам. Виртуальные таблицы также позволяют логически объединять данные из разных таблиц и представить их в виде более крупной таблицы. С помощью Виртуальных Таблиц можно также скрывать часть данных от определённой группы пользователей с целью обеспечения безопасности информации.
Процедура – именованный блок SQL, который позволяет задавать параметры и выполняет заданные действия. Как правило, процедура создается именно для выполнения определенной последовательности команд. Процедура может храниться, как объект базы данных. Хранимая процедура – это процедура, которая хранится в базе данных, как объект базы данных. Хранимая процедура создается командой CREATE PROCEDURE, а для вызова используется команда EXECUTE. Свойства хранимых процедур:
Существуют два типа хранимых процедур: системные и пользовательские. Первые используются для управления SQL Server’ом и отображения информации о БД и пользователях; вторые создаются пользователями для выполнения прикладных задач.
Триггеры – это блок SQL, который выполняется неявно при возникновении определенного события в базе данных или приложении. Триггер может быть триггером базы данных или триггером приложения:
Триггеры используются для того, чтобы гарантировать выполнение операций, связанных с определенным событием в базе данных (проверка заработной платы сотрудника, которая не может выходить за рамки тарифной сетки для данной должности, при обновлении информации о сотруднике) или в приложении (отображение определенной информации при нажатии на кнопку). Триггеры базы данных следует использовать только для общих операций, не зависящих от пользователя или приложения, выполняющих эти операции. Понятие транзакции. Под транзакцией будем понимать группу операций модификации разделяемой структуры данных, которая происходит атомарно (неделимо), не прерываясь никакими другими операциями с той же структурой данных. Т.о. можно сказать, что операции, относящиеся к одной транзакции, либо происходят все вместе, либо не происходят вообще. Транзакция – это несколько последовательных операторов SQL, которые рассматриваются как единое целое. Операторы, входящие в транзакцию, выполняют взаимосвязанные действия: каждый оператор выполняет свою часть задачи, но задача будет выполнена успешно только в том случае, если все команды отработают корректно. Транзакции в реляционной базе данных должны подчиняться следующему правилу: Операторы, входящие в транзакцию рассматриваются как неделимое целое. Либо все операторы должны быть выполнены успешно, либо не должен быть выполнен ни один оператор. Транзакция, которая дала ожидаемый результат, называется принятой (committed), в противном случае – отвергнутой (rolled back). СУБД обновляет записи, если транзакция принята или восстанавливает исходные данные, если транзакция отвергнута. Транзакция автоматически начинается с любой команды обработки данных. Далее происходит последовательное выполнение остальных операторов до тех пор, пока не произойдет одно из следующих событий:
Организация взаимодействия интерфейса пользователя с хранилищем данных. Сервер базы данных – это лишь одна сторона в системе клиент-сервер. Другим важным компонентом являются клиенты – приложения, взаимодействующие с сервером базы данных для получения, модификации и ввода данных. Клиентское приложение - интерфейсный компонент СУБД, с которым пользователи работают для считывания, ввода и анализа данных. Клиентские приложения могут быть «всех форм и размеров». Например, в системе управления складом основной задачей будет приложение управления запасами.
Именно разделение обязанностей между клиентом и сервером делает работу системы клиент-сервер столь эффективной. Поскольку наиболее сложная часть системы, многопользовательская система управления базой данных, является заранее разработанным пакетом программного обеспечения, который можно инсталлировать и использовать, разработка специальных приложений становится значительно более простой и продуктивной. Так как внешними интерфейсами СУБД являются клиентские приложения, для выполнения своей работы их должны применять все типы пользователей. Администраторы для управления сервером базы данных используют утилиты, конечные пользователи для выполнения работы запускают специальные клиентские приложения, а разработчики создают их. Основные особенности клиентских приложений:
Пример – использование Microsoft Access в качестве клиентского приложения. СУБД Microsoft Access для работы с данными использует процессор баз данных Microsoft Jet, объекты доступа к данным и средство быстрого построения интерфейса – Конструктор форм. Для получения распечаток используются конструкторы отчетов. Автоматизация рутинных операций может быть выполнена с помощью макрокоманд. В случае недостатка визуальных средств, пользователи могут обратиться к созданию процедур и функций. При этом как в макрокомандах можно использовать вызовы функций, так и из кода процедур и функций можно выполнять макрокоманды. В Microsoft Access присутствует язык программирования Visual Basic for Application, который позволяет создавать массивы, свои типы данных, вызывать DLL-функции, контролировать работу приложений с помощью OLE Automation. Можно даже полностью создавать базы данных с помощью кодирования, если в этом появляется необходимость. MS Access имеет один из самых лучших наборов визуальных средств среди аналогичных программных продуктов. Вся работа с базой данных осуществляется через окно программы ACCESS. Отсюда осуществляется доступ ко всем объектам: таблицам, запросам, формам, отчетам, макросам, модулям. Встроенный язык запросов SQL позволяет максимально гибко работать с данными и значительно ускоряет доступ к внешним данным. 20.Этапы процесса принятия решений. Принятие решения в условиях определенности. В условиях множества критериев. Основные этапы процесса сбора и анализа экспертами информации. 1. Сбор и анализ информации 2. Определение проблемной ситуации 3. Определение целей 4. Разработка прогноза развития ситуации 5. Генерирование альтернативных вариантов решения 6. Разработка оценочной системы 6.1. Определение критериев 6.2. Определение способов измерения критериев 6.3. Разработка правила выбора решения 7. Построение модели 8. Выбор решения 9. Согласование решения 10. Утверждение решения 11. Подготовка к вводу решения в действие 12. Управление применением решения 13. Проверка эффективности решения 1-5 – подготовительные этапы процесса принятия решений. 1) Получение информации. Информация может быть количественная – статистические данные с органов статистики, бухгалтерские, отчетные данные, результаты анализа окружающей среды; и качественная – обычно получается в результате опроса специалистов – экспертные оценки. Возникающие проблемы: – не всегда имеется достоверная и полная информация; – информация может быть избыточная (напр.: слухи). 2) Формулировка проблемы. – обычно осуществляется приблизительно (нулевое приближение проблемы). Причины: 1) Обычно проблему формулирует руководитель (это его субъективное видение). 2) Организация в которой формулируется проблема (проблемо-содержащая система) не является изолированной, она связана с другими организациями, т.е. имеет выше стоящую систему (надсистему) и окружающую среду. (Поэтому когда мы анализируем проблему надо определить источник.) Обычно возникает комплекс проблем – проблематика. Для определения проблематики необходимо привлекать всех заинтересованных лиц. К ним относятся люди которые ставят проблему; лица принимающие решения, от которых зависит решение проблемы; представители окружающей среды (могут быть пассивные, т.е. на них сказывается проблема; и активные – участвуют в решении проблемы); специалисты по системному анализу. 3) Определение целей Цель – это такое состояние объекта управления, к достижению которого стремится организация. Цели формируются руководством организации и могут быть субъективными, это зависит от ценностей: а) Теоретические ценности; т.е. получение новых знаний, открытия. б) Экономические (накопление капитала, получение прибыли) в) Политические (власть) г) Социальные (хорошие человеческие отношения в организации) д) Эстетические (гармония создаваемого продукта, определенные виды формы) е) Религиозные (отношение к людям, природе) Постановка задачи: Пусть х – решение, которое относится к множеству допустимых решений X. Каждое решение характеризуется множеством локальных критериев 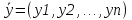 . Необходимо найти оптимальное решение Хо, определяемое двумя условиями: . Необходимо найти оптимальное решение Хо, определяемое двумя условиями:
Классы задач векторной оптимизации:
Основные проблемы, возникающие при решении задач векторной оптимизации:
|