10_Кластерный анализ. 10. 1 Процедура кластерного анализа 10 1 Основные понятия
 Скачать 391 Kb. Скачать 391 Kb.
|

10.5.2 Неиерархические методы кластерного анализа. Итеративные методыПроцесс неиерархической кластеризации всегда является итеративным. Итеративные методы кластеризации различаются выбором следующих параметров:
Такая неиерархическая кластеризация состоит в разделении набора данных на определенное количество отдельных кластеров. Существует два подхода. Первый заключается в определении границ кластеров как наиболее плотных участков в многомерном пространстве исходных данных, т.е. определение кластера там, где имеется большое "сгущение точек". Второй подход заключается в минимизации меры различия объектов. 10.5.3 Алгоритм k-средних (k-means)Наиболее распространен среди неиерархических методов алгоритм k-средних, также называемый быстрым кластерным анализом. В отличие от иерархических методов, которые не требуют предварительных предположений относительно числа кластеров, для этого метода необходимо иметь гипотезу о наиболее вероятном количестве кластеров. Алгоритм Общая идея алгоритма: объекты распределяются по Кластеризация осуществляется по следующему алгоритму:
Выбирается число кластеров
Каждый объект присоединяется к тому кластеру, расстояние до которого является наименьшим.
Вычисляются центры кластеров, как покоординатные средние кластеров. Объекты опять перераспределяются. Процесс вычисления центров и перераспределения продолжается до тех пор, пока не будет выполнено одно из условий останова:
На рис. 10.6 приведен пример работы алгоритма 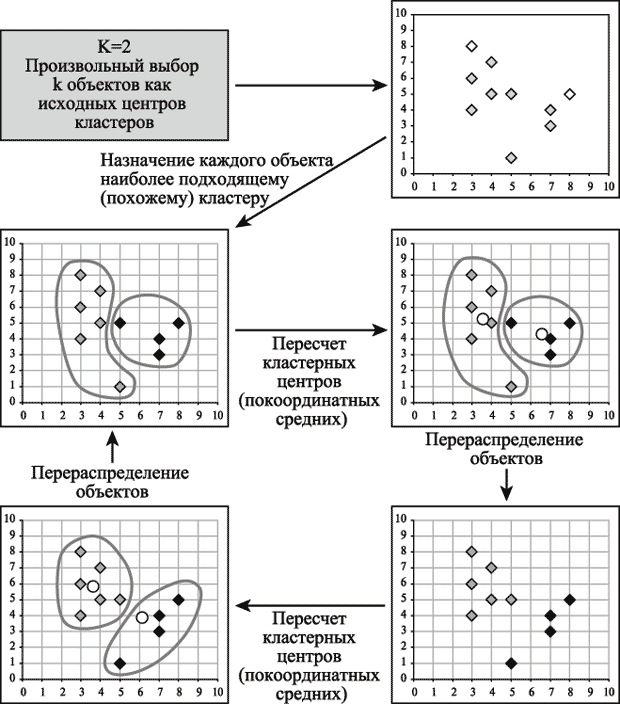 Рис. 10.6 Пример работы алгоритма После получений результатов кластерного анализа методом k-средних следует проверить правильность кластеризации (т.е. оценить, насколько кластеры отличаются друг от друга). Для этого рассчитываются средние значения для каждого кластера. При хорошей кластеризации должны быть получены сильно отличающиеся средние для всех измерений или хотя бы большей их части. Достоинства алгоритма
Недостатки алгоритма k-средних:
|