10_Кластерный анализ. 10. 1 Процедура кластерного анализа 10 1 Основные понятия
 Скачать 391 Kb. Скачать 391 Kb.
|

10.5.3 Определение количества кластеровВыбор числа кластеров является сложным вопросом. Предположения о числе кластеров могут базироваться на теоретических исследованиях или интуитивных соображениях. Если нет предположений относительно этого числа, то можно использовать предварительный иерархический кластерный анализ. Процессу группировки объектов в иерархическом кластерном анализе соответствует постепенное возрастание коэффициента, называемого критерием Если кластеризируемая совокупность слишком велика для иерархического анализа, то для предварительного определения числа кластеров можно произвести иерархический кластерный анализ на выборке из этой совокупности. Полученное число кластеров 10.6 Этапы процесса кластеризацииВ общем случае все этапы кластерного анализа взаимосвязаны, и решения, принятые на одном из них, определяют действия на последующих этапах. 1. Аналитику следует решить, использовать ли все наблюдения либо же исключить некоторые данные или выборки из набора данных. 2. Выбор метрики и метода стандартизации исходных данных. 3. Определение количества кластеров (для итеративного кластерного анализа). 4. Определение метода кластеризации (правила объединения или связи). По мнению многих специалистов, выбор метода кластеризации является решающим при определении формы и специфики кластеров. 5. Анализ результатов кластеризации. Этот этап подразумевает решение таких вопросов: не является ли полученное разбиение на кластеры случайным; является ли разбиение надежным и стабильным на подвыборках данных; существует ли взаимосвязь между результатами кластеризации и переменными, которые не участвовали в процессе кластеризации; можно ли интерпретировать полученные результаты кластеризации. 6. Проверка результатов кластеризации. Результаты кластеризации должны быть проверены формальными и неформальными методами. Формальные методы зависят от того метода, который использовался для кластеризации. Неформальные включают следующие процедуры проверки качества кластеризации:
Один из вариантов проверки качества кластеризации - использование нескольких методов и сравнение полученных результатов. Отсутствие подобия не будет означать некорректность результатов, но присутствие похожих групп считается признаком качественной кластеризации. Как и любые другие методы, методы кластерного анализа имеют определенные слабые стороны, т.е. некоторые сложности, проблемы и ограничения. При проведении кластерного анализа следует учитывать, что результаты кластеризации зависят от критериев разбиения совокупности исходных данных. При понижении размерности данных могут возникнуть определенные искажения, за счет обобщений могут потеряться некоторые индивидуальные характеристики объектов. Существует ряд сложностей, которые следует продумать перед проведением кластеризации.
Выбор метода кластеризации зависит от количества данных и от того, есть ли необходимость работать одновременно с несколькими типами данных. В пакете SPSS, например, при необходимости работы как с количественными (например, доход), так и с категориальными (например, семейное положение) переменными, а также при достаточно большом объеме данных используется метод Двухэтапного кластерного анализа. Этот метод представляет собой масштабируемую процедуру кластерного анализа, позволяющую работать с данными различных типов. Для этого на первом этапе работы записи предварительно кластеризуются в большое количество суб-кластеров. На втором этапе полученные суб-кластеры группируются в необходимое количество. Если это количество неизвестно, процедура сама автоматически определяет его. При помощи этой процедуры банковский работник может, например, выделять группы людей, одновременно используя такие показатели как возраст, пол и уровень дохода. Полученные результаты позволяют определить клиентов, входящих в группы риска невозврата кредита. В некоторых случаях требуется дополнительная подготовка данных перед проведением кластерного анализа. Пусть существует база данных клиентов фирмы, которых следует разбить на однородные группы. Каждый клиент описывается при помощи 25 переменных. Использование такого большого числа переменных приводит к выделению кластеров нечеткой структуры. В результате аналитику достаточно сложно интерпретировать полученные кластеры. Более понятные и прозрачные результаты кластеризации могут быть получены, если вместо множества исходных переменных использовать некие обобщенные переменные или факторы, содержащие в сжатом виде информацию о связях между переменными. Т.е. возникает задача понижения размерности данных до кластеризации. Она может решаться при помощи различных методов; один из наиболее распространенных - факторный анализ. 10.7 Сравнительный анализ иерархических и неиерархических методов кластеризацииПеред проведением кластеризации может возникнуть вопрос, какой группе методов кластерного анализа отдать предпочтение. Выбирая между иерархическими и неиерархическими методами, необходимо учитывать следующие их особенности. Неиерархические методы выявляют более высокую устойчивость по отношению к шумам и выбросам, некорректному выбору метрики, включению незначимых переменных в набор, участвующий в кластеризации. Однако при этом нужно заранее определить количество кластеров, количество итераций или правило остановки, а также некоторые другие параметры кластеризации. Если нет предположений относительно числа кластеров, рекомендуют использовать иерархические алгоритмы. Однако если объем выборки не позволяет это сделать, возможный путь - проведение ряда экспериментов с различным количеством кластеров, например, начать разбиение совокупности данных с двух групп и, постепенно увеличивая их количество, сравнивать результаты. За счет такого "варьирования" результатов достигается достаточно большая гибкость кластеризации. Иерархические методы, в отличие от неиерархических, отказываются от определения числа кластеров, а строят полное дерево вложенных кластеров. Сложности иерархических методов кластеризации: ограничение объема набора данных; выбор меры близости; негибкость полученных классификаций. Преимущество этой группы методов в сравнении с неиерархическими методами - их наглядность и возможность получить детальное представление о структуре данных. При использовании иерархических методов существует возможность достаточно легко идентифицировать выбросы в наборе данных и, в результате, повысить качество данных. Эта процедура лежит в основе двухшагового алгоритма кластеризации. Такой набор данных в дальнейшем может быть использован для проведения неиерархической кластеризации. Иерархические методы не могут работать с большими наборами данных, в таких случая возможно рассмотрение некоторой выборки из набора исходных данных. 10.8 Иерархический кластерный анализ в SPSSПроцедура иерархического кластерного анализа в SPSS предусматривает группировку как объектов (строк матрицы данных), так и переменных (столбцов). Можно считать, что в последнем случае роль объектов играют строки, а роль переменных - столбцы. Для исключения вероятности того, что классификацию будут определять переменные, имеющие наибольший разброс значений используется процедура стандартизации. В SPSS применяются следующие виды стандартизации:
Кроме того, возможны преобразования самих расстояний, в частности, можно расстояния заменить их абсолютными значениями, это актуально для коэффициентов корреляции. Можно также все расстояния преобразовать так, чтобы они изменялись от 0 до 1. Результат работы любого алгоритма кластеризации зависит от способов вычисления расстояния между объектами и определения близости между кластерами. Для определения расстояния между парой кластеров в процессе их объединения в SPSS предусмотрены следующие методы:
Проведение иерархического кластерного анализа путем агломерации представляется при помощи протокола объединения кластеров (таблица10.1) и дендрограммы. Дендрограмма для примера приведена на рис. 10.5. В протоколе указаны такие позиции:
Таблица 10.1. Порядок агломерации Cluster Combined Coefficients (протокол объединения кластеров)
Так, в таблице можно увидеть порядок объединения в кластеры: на первом шаге были объединены наблюдения 9 и 10, они образовывают кластер под номером 9, кластер 10 в обзорной таблице больше не появляется. На следующем шаге происходит объединение кластеров 2 и 14, далее 3 и 9, и т.д. В колонке Коэффициент приведено расстояние между двумя кластерами, определенное на основании выбранной меры расстояния. В данном случае это квадрат евклидова расстояния, определенный с использованием стандартизированных значений. 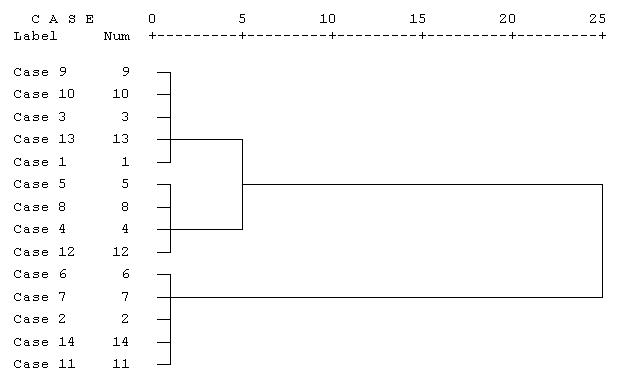 Рис. 10.7. Дендрограмма процесса агломерации Для определения числа кластеров анализируем изменение значений поля Coefficients: в примере это скачок с 1,217 до 7,516. Оптимальным считается количество кластеров, равное разности количества наблюдений (14) и количества шагов до скачкообразного увеличения коэффициента (12). Следовательно, после создания двух кластеров объединений больше производить не следует, хотя визуально можно предположить наличие трех кластеров. |