12 Сравнение языкового моделирования с другими подходами к информационному поиску
 Скачать 91.62 Kb. Скачать 91.62 Kb.
|

|
258 Глава 12. Языковые модели для информационного поиска 12.3. Сравнение языкового моделирования с другими подходами к информационному поиску Языковые модели отражают новую точку зрения на проблему поиска текста, связан- ную с большим количеством исследований, посвященных распознаванию речи и обра- ботке естественного языка. Как подчеркивают Понте и Крофт (Ponte and Croft, 1998), языковые модели в информационном поиске позволяют по-иному оценивать соответст- вие между запросам и документами, а также дают надежду на то, что вероятностные языковые модели точнее вычисляют веса, а значит, повышают качество поиска. Основ- ной проблемой остается оценка модели документа, например выбор эффективного спо- соба сглаживания. Языковые модели обеспечивают хорошие результаты поиска. По сравнению с другими вероятностными подходами, такими как модель BIM из главы 11, основное отличие непосредственно проявляется в том, что языковая модель не предна- значена для явного моделирования релевантности (в то время как именно релевант- ность — центральное понятие в рамках модели BIM). Однако, как указано в работах, описанных в разделе 12.5, это, возможно, не вполне корректные рассуждения. Языковые модели предполагают, что документы и выражения информационных потребностей — это объекты одного рода, и оценивают их соответствие с помощью инструментов, заим- ствованных из арсенала методов обработки речи и естественного языка. В результате возникает математически строгая, концептуально простая, вполне реализуемая с вычис- лительной точки зрения и интуитивно привлекательная модель. Это напоминает XML- поиск (глава 10); там также подходы, основанные на предположении о принадлежности запросов и документов одному типу, оказались наиболее успешными. С другой стороны, как и любые модели информационного поиска, языковые модели не лишены недостатков. Предположение об эквивалентности представления документа и информационной потребности нереалистично. В настоящее время используются очень простые, как правило, униграммные языковые модели. Без явного понятия релевантно- сти обратную связь по релевантности, как и предпочтения пользователей, трудно интег- рировать в модель. Кроме того, очевидно, существует необходимость выйти за пределы униграммных моделей, чтобы обеспечить сопоставление фраз и фрагментов, а также ис- пользование логических операторов. Более поздние работы в этой области были сосре- доточены именно на этих проблемах, в том числе на включении релевантности в модель и допущении языковых несоответствий между языками запросов и документов. Языковая модель тесно связана с традиционными моделями tf–idf. Частота термина в моделях tf–idf участвует непосредственно, причем в большинстве современных работ признается важность нормировки по длине документа. Смесь распределений вероятно- стей, определенных по документу и коллекции, немного напоминает idf; термины, кото- рые редко встречаются в коллекции и часто — в некоторых документах, оказывают бо- лее сильное влияние на ранжирование документов. В большинстве конкретных реализа- ций на основе того или иного подхода термины обрабатываются как независимые друг от друга. С другой стороны, интуиция лучше выражается в терминах вероятностей, а не в геометрии, математические модели являются более строгими, а не эвристическими, а де- тали, например использование частоты термина и длины документа, в языковых моделях и модели tf–idf отличаются. Результаты недавних экспериментов по информационному поиску показывают, что языковые модели более эффективны, чем модели tf–idf и BM25. Тем не менее имеющихся доказательств преимущества языковых моделей перед хорошо 12.4. Расширения языковых моделей 259 настроенными традиционными системами поиска на основе модели векторного про- странства все еще недостаточно для того, чтобы заменять ими существующие реализации. 12.4. Расширения языковых моделей В этом разделе мы кратко упомянем некоторые из работ, посвященных расширению фундаментального подхода, основанного на языковых моделях. Существуют альтернативные точки зрения на использование языковых моделей для информационного поиска. Вместо исследования вероятности того, что языковая модель документа Md сгенерирует запрос, можно ориентироваться на вероятность того, что язы- ковая модель запроса Mq сгенерирует документ. Основная причина невысокой популяр- ности модели правдоподобия документа (document likelihood model) заключается в том, что для построения языковой модели запроса имеется намного меньше текста, поэтому оценки в этой модели будут грубее, а значит, они будут сильнее зависеть от сглаживания с участием другой языковой модели. С другой стороны, нетрудно убедиться, что интег- рирование обратной связи по релевантности в такую модель осуществить намного легче. Мы можем расширить запрос за счет терминов, взятых из релевантных документов, и тем самым уточнить языковую модель Mq (Zhai and Lafferty, 2001, а). Действительно, при правильном выборе параметров этот подход приводит к модели BIM, описанной в главе 11. Примером модели правдоподобия документа является модель релевантности, предло- женная Лавренко и Крофтом (Lavrenko and Croft, 2001), в которую встроена обратная связь по псевдорелевантности. Это позволило достичь очень хороших эмпирических ре- зультатов. Вместо того чтобы следовать в одном из направлений, мы можем построить языко- вые модели как по документу, так и по запросу и сравнить их друг с другом. Лафферти и Жаи (Lafferti and Zhai, 2001) реализовали все три подхода к решению поставленной зада- чи (рис. 12.5) и разработали общий метод минимизации риска при поиске документа. Например, для оценки риска вернуть документ d в качестверелевантного запросу q мож- но использовать дивергенцию Кульбака–Лейблера (Kullback–Leibler divergence) между соответствующими языковыми моделями.  ( ) ; log ( ) P t M = = ∑∈ P t M q R d q KL M M P t M (12.14) d q q t V d ( ) ( ) ( )                            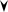              Рис. 12.5. Триподходакразработкеязыковоймодели:а)прав- доподобиезапроса,б) правдоподобиедокумента,в)модель сравнения Дивергенция Кульбака–Лейблера — это асимметричная мера дивергенции, исполь- зуемая в теории информации. Она позволяет оценить, насколько плохо распределение 260 Глава 12. Языковые модели для информационного поиска вероятностей Mq приближает распределение вероятностей Md (Cover and Thomas, 1991; Manning and Schutze, 1999). Лафферти и Жаи (Lafferty and Zhai, 2001) опубликовали ре- зультаты, позволяющие предположить, что модель сравнения является более эффектив- ной, чем модели правдоподобия документа и запроса соответственно. Дивергенция Куль- бака–Лейблера, используемая в качестве функции ранжирования, имеет один недостаток: невозможно сравнивать веса документов для разных запросов. Это не имеет большого значения для поиска по произвольному запросу (ad hoc retrieval), но важно для других приложений, например для отслеживания тем при обработке новостного потока. Краий и Спиттерс (Kraaij and Spitters, 2003) предложили альтернативный подход, в рамках кото- рого схожесть моделируется с помощью нормированного логарифмического отношения правдоподобия (или, что эквивалентно, как разница между значениями перекрестной энтропии). Основные языковые модели не учитывают альтернативные способы выражения, т.е. синонимы и любые другие различия в использовании языка между запросами и докумен- тами. Для того чтобы заполнить этот пробел, Бергер и Лафферти (Berger and Lafferty, 1999) ввели модели перевода. Модельперевода (translation model) позволяет генериро- вать слова запроса, не содержащиеся в документе, переводя их в альтернативные терми- ны, близкие по смыслу. Это также открывает возможность для создания многоязычных систем информационного поиска. Мы предполагаем, что модель перевода можно пред- ставить с помощью распределения условной вероятности T(⋅|⋅) по словарным терминам. Модель генерирования перевода запроса в этом подходе выглядит так. ( d ) ( d ) ( ) t q v V P q M P v M T t v ∈ ∈ = ∏∑ (12.15) Множитель P(v|Md) есть базовая модель языка документа, а множитель T(t|v) осуще- ствляет перевод. Разумеется, эта модель требует больше вычислений, к тому же необхо- димо построить модель перевода. Такая модель обычно создается с помощью отдельных ресурсов (например, традиционных тезаурусов, двуязычных словарей или словарей сис- тем машинного перевода, полученных с помощью статистических методов), но может быть построена и с помощью коллекции документов, если существуют фрагменты текста, представляющие собой естественный парафраз или резюме других фрагментов текста. В качестве кандидатов на включение в такую коллекцию выступают документы и их за- головки либо аннотации или документы и тексты гиперссылок на эти документы. Разработка расширенных языковых моделей остается областью активных исследова- ний. В целом модели перевода, модели с обратной связью по релевантности и подход на основе сравнения моделей продемонстрировали повышении производительности поиска по сравнению с базовыми языковыми моделями правдоподобия запроса. 12.5. Библиография и рекомендации для дальнейшего чтения Более подробно основы вероятностных языковых моделей и методов сглаживания описаны в книгах Маннинга и Шютце (Manning and Schütze, 1999), а также Джурафски и Мартина (Jurafsky and Martin, 2008). Впервые применение языковых моделей к задачам информационного поиска было описано в работах Понте и Крофта (Ponte and Croft, 1998), Хиемстры (Hiemstra, 1998), Бергера и Лафферти (Berger and Lafferty, 1999) и Миллера и др. (Miller et al., 1999). Дру- |