ГОСЫ. ГОСы. 76. каскадная модель жизненного цикла ис (основные этапы разработки по каскадной модели. Достоинства и недостатки каскадной модели)
 Скачать 5.37 Mb. Скачать 5.37 Mb.
|

|
94. УПРАВЛЕНИЕ ПРОЕКТОВ: ПРИНЯТИЕ РЕШЕНИЙ В УСЛОВИЯХ РИСКА. ДЕРЕВЬЯ ПРИНЯТИЯ РЕШЕНИЙ. Если решение принимается в условиях риска, то стоимости альтернативных решений описываются вероятностными распределениями. Поэтому принимаемое решение основывается на использовании критерия ожидаемого значения, в соответствии с которым альтернативные решения сравниваются с точки зрения максимизации ожидаемой прибыли или минимизации ожидаемых затрат. Предполагается, что прибыль (затраты), связанная с каждым альтернативным решением, является случайной величиной. Деревья решений – это графическое средство анализа решений в условиях риска. Деревья решений создаются для использования в моделях, в которых принимается последовательность решений, каждая из которых ведет к некоторому результату. Рисуют деревья слева направо. Построение и анализ дерева решений включают выполнение следующих этапов: Этап 1. Постановка проблемы и поиск альтернатив решения: выявление проблемы через сравнение достигнутого состояния и желаемого состояния; анализ причин, вызвавших проблему; выявление и определение значимых для постановки проблемы целей; определение перечня подпроблем, входящих в проблему, и логической последовательности их разрешения; подбор альтернативных решений для каждого из решений, в зависимости от условий внешней среды. Этап 2. Конструирование дерева решений в виде схематичного представления комплекса решаемых подпроблем. Дерево содержит узлы двух типов. Первый тип изображается в виде прямоугольника и соответствует решению определенной подпроблемы – место, где решение принимает человек. Таким образом, в этих узлах системным аналитиком производится выбор одной из альтернатив. Каждая из альтернатив представляется в виде дуги, выходящей из узла принятия решения. Необходимо отметить, что реализация r-го решения может быть связана с определенными затратами Сr. Эта величина со знаком минус указывается над дугой, соответствующей r-му решению (рис. 1). 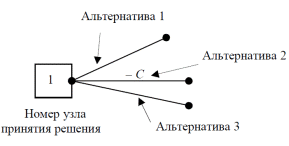 Рис. 1. Схематическое изображение узла принятия решения Затраты на реализацию решений могут быть связаны с проведением дополнительных экспериментов для получения более точной информации, разработкой проектов технического переоснащения предприятий и т.д. В том случае, если реализация альтернативы не требует затрат, то над дугой не проставляется никаких количественных значений, а только указывается наименование альтернативы. Второй тип узлов изображается в виде круга и соответствует моменту появления возможных исходов в зависимости от состояний внешней среды – место, где все решает случай. Такие узлы именуются как узлы-возможности, а каждая дуга отображает возможный исход. Возникновение возможных исходов количественно задается распределением условных вероятностей (рис.22.2). 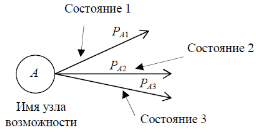 Рис. 2. Схематическое изображение узла возможностей Конечным исходам приписывается численная величина выигрыша либо полезности (рис. .3). 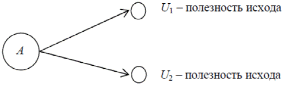 Рис. 3. Схематичное изображение конечных исходов Ветви обозначают линии, соединяющие узлы любых типов. Обобщенный фрагмент дерева решений представлен на рис. 4. 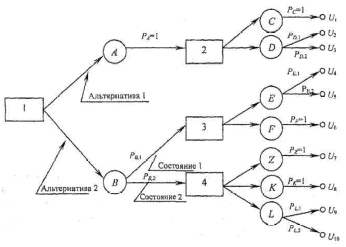 Рис. 4. Обобщенный фрагмент дерева Этап 3. Анализ дерева решений производится, начиная от конечных исходов к начальному узлу принятия решений. Такой процесс вычислений называется обратным пересчетом. Для узлов-возможностей определяется среднее значения выигрыша. В частности, для узла D: MD=U2PD,l+U3PD,2. В том случае, если для узла-возможностей имеется только одно состояние и только один конечный исход, то среднее значение выигрыша для такого узла равно выигрышу конечного исхода. Так, для узла F: MF=U6. В узле принятия решения реализуется принцип максимизации среднего выигрыша либо ожидаемой полезности, т.е. в каждом узле решения системный аналитик выбирает альтернативу, которая приводит к наибольшей ожидаемой полезности, и значение этой полезности приписывается узлу решений. В частности, для узла 3 полезность или выигрыш определяются из условия: М3(3)=max{ME,MF}. На основе значений полезности узлов принятия решений находятся средние значения полезности для узлов-возможностей, которые являются узлами-предками. Процесс продолжается до тех пор, пока для начального узла принятия решений, исходя из принципа максимальной полезности, не будет определена оптимальная альтернатива. После этого проводится просмотр дерева в прямом порядке и определяется перечень оптимальных альтернатив. Этап 4. Анализ устойчивости решения. Цель этого этапа состоит в определении предельных значениях вероятностей, при которых производится переход к другим альтернативным решениям. Этап 5. Оценка ожидаемой ценности точной информации. Этот этап целесообразно выполнять в том случае, если с помощью дополнительного мониторинга внешней среды можно получить точную информацию о состоянии среды. Очевидно, что проведение мониторинга требует дополнительных затрат, но приводит к увеличению максимального выигрыша либо полезности. Поэтому необходимо найти разность между значениями критерия при наличии точной информации о состоянии среды и значением критерия при отсутствии такой информации. Эта разность называется ожидаемым значением дополнительной информации. Это верхняя граница цены, которую можно заплатить за какую-либо частную дополнительную информацию. Тогда мониторинг целесообразно проводить, если затраты на его организацию меньше вычисленной разности критериев оценки выигрышей. Разница между ожидаемым доходом в условиях определенности и в условиях риска называется ожидаемой стоимостью полной информации. Это максимально возможный размер средств, которые можно потратить на получение полной информации. 95. ОСНОВНЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ БАЗ ДАННЫХ (бд) (ИНФОРМАЦИЯ, ДАННЫЕ, БАНК ДАННЫХ, СТРУКТУРА БАНКА ДАННЫХ, СУБД, АДМИНИСТРАТОР БАЗ ДАННЫХ). Информация - любые сведения о процессах и явлениях, которые в той или иной форме передаются между объектами материального мира (людьми; животными; растениями; автоматами и др.). Данные — факты и идеи, представленные в формализованном виде, позволяющем передавать или обрабатывать их при помощи некоторого процесса и соответствующих технических устройств. Банк данных (БнД) — информационная система, включающая в свой состав комплекс специальных методов и средств для поддержания динамической информационной модели с целью обеспечения информационных потребностей пользователей. Структура типового БнД, приведена на рис. 1, где представлены: ВС — вычислительная система, включающая технические средства (ТС) и общее программное обеспечение (ОПО);БД – базы данных; СУБД – система управления БД; АБД – администратор баз данных, а также обслуживающий персонал и словарь данных. БД – совокупность специальным образом организованных (структурированных) данных и связей между ними. Если в состав БнД входит одна БД, банк принято называть локальным;если БД несколько — интегрированным. 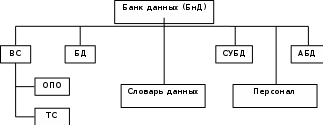 Рис. 1. Основные компоненты БнД. СУБД — специальный комплекс программ и языков, посредством которого организуется централизованное управление базами данных и обеспечивается доступ к ним. В состав любой СУБД входят языки двух типов:1) язык описания данных (с его помощью описываются типы данных, их структура и связи); 2) язык манипулирования данными (его часто называют язык запросов к БД), предназначенный для организации работы с данными в интересах всех типов пользователей. Администратор баз данных — это лицо (группа лиц), реализующее управление БД.В этой связи сам БнД можно рассматривать как автоматизированную систему управления базами данных. Функции АБД являются долгосрочными; он координирует все виды работ на этапах создания и применения БнД. На стадии проектирования АБД выступает как идеолог и главный конструктор системы; на стадии эксплуатации он отвечает за нормальное функционирование БнД, управляет режимом его работы и обеспечивает безопасность данных. На рис. 2 представлен типовой состав группы АБД, отражающий основные направления деятельности специалистов. 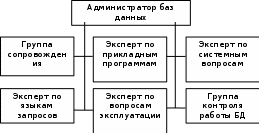 Рис. 2. Типовой состав группы АБД. 96. ОПИСАТЕЛЬНАЯ МОДЕЛЬ ПРЕДМЕТНОЙ ОБЛАСТИ (ЭТАПЫ ПРОЕКТИРОВАНИЯ БД, СУЩНОСТЬ, АТРИБУТ, СВЯЗЬ ИНФО- И ДАТОЛОГИЧЕСКОЕ ПРОЕКТИРОВАНИЕ Проектирование БД начинается с анализа предметной области и возможных запросов пользователей. В результате этого анализа определяется перечень данных и связей между ними. Завершается проектирование БД определением форм и способов хранения необходимых данных на физическом уровне. На рис. 3 представлены типовые этапы проектирования БД. На этапе инфологического (информационно-логического) проектирования осуществляется построение семантической модели, описывающей сведения из предметной области, которые могут заинтересовать пользователей БД. Семантическая модель — представление совокупности понятий в виде графа, в вершинах которого расположены понятия, в терминальных вершинах — элементарные понятия, а дуги представляют отношения между понятиями. 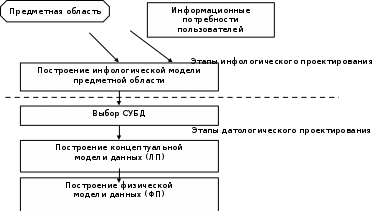 Рис. 3. Этапы проектирования БД. Датологическое проектирование подразделяется на логическое (построение концептуальной модели данных) и физическое (построение физической модели) проектирование. Главной задачей логического проектирования (ЛП) БД является представление выделенных на предыдущем этапе сведений в виде данных в форматах, поддерживаемых выбранной СУБД. Задача физического проектирования (ФП) — выбор способа хранения данных на физических носителях и методов доступа к ним с использованием возможностей, предоставляемых СУБД. Инфологическая модель "сущность—связь" представляет собой описательную (неформальную) модель, семантически определяющую в ней сущности и связи. При любом подходе к построению модели используют три основных конструктивных элемента: сущность; атрибут; связь. Сущность — это собирательное понятие некоторого повторяющегося объекта, процесса или явления окружающего мира, о котором необходимо хранить информацию в системе. Главной особенностью сущности является то, что вокруг нее сосредоточен сбор информации в конкретной ПрОбл. Тип сущности определяет набор однородных объектов, а экземпляр сущности — конкретный объект в наборе. Для идентификации конкретного экземпляра сущности и его описания используется один или несколько атрибутов. Атрибут — это поименованная характеристика сущности, которая принимает значения из некоторого множества значений. Связи в инфологической модели выступают в качестве средства, с помощью которого представляются отношения между сущностями, имеющими место в ПрОбл. При анализе связей между сущностями могут встречаться бинарные (между двумя сущностями) и, в общем случае, n-арные (между п сущностями) связи. Различают четыре типа связей: связь один к одному (1:1); связь один ко многим (1:М); связь многие к одному (М:1); связь многие ко многим (M:N). Связь один к одному определяет такой тип связи между типами сущностей А и В, при которой каждому экземпляру сущности А соответствует один и только один экземпляр сущности В, и наоборот. Связь один ко многим определяет такой тип связи между типами сущностей А и В, для которой одному экземпляру сущности А может соответствовать 0, 1 или несколько экземпляров сущности В, но каждому экземпляру сущности В соответствует один экземпляр сущности А. Связь многие к одному, по сути, эквивалентна связи один ко многим. Различие заключается лишь в том, с точки зрения какой сущности (А или В) данная связь рассматривается. Связь многие ко многим определяет такой тип связи между типами сущностей А и В, при котором каждому экземпляру сущности А может соответствовать 0, 1 или несколько экземпляров сущности В, и наоборот. 97. КОНЦЕПТУАЛЬНЫЕ МОДЕЛИ ДАННЫХ: ТИПЫ СТРУКТУР ДАННЫХ; ОПЕРАЦИИ НАД ДАННЫМИ; ОГРАНИЧЕНИЯ ЦЕЛОСТНОСТИ (МОДЕЛЬ ДАННЫХ, ЭЛЕМЕНТ ДАННЫХ, АГРЕГАТ ДАННЫХ, ЗАПИСЬ, НАБОР, БАЗА ДАННЫХ). Концептуальная модель описывает хранимые в ЭВМ данные и связи. Каждая модель данных неразрывно связана с языком описания данных конкретной СУБД. Модель данных — это совокупность трех составляющих: типов (структур) данных; операций над данными; ограничений целостности. Модель данных представляет собой некоторое интеллектуальное средство проектировщика, позволяющее реализовать интерпретацию сведений о ПрОбл в виде формализованных данных в соответствии с определенными требованиями, т.е. средство абстракции, которое дает возможность увидеть информационное содержание данных, а не отдельные конкретные значения данных. Используют пять типовых структур (в порядке усложнения): Элемент данных — наименьшая поименованная единица данных, к которой СУБД может адресоваться непосредственно и с помощью которой выполняется построение всех остальных структур данных. Агрегат данных — поименованная совокупность элементов данных, которую можно рассматривать как единое целое. Агрегат может быть простым или составным (если он включает в себя другие агрегаты). Запись — поименованная совокупность элементов данных и (или) агрегатов. Запись – это агрегат, не входящий в другие агрегаты. Запись может иметь сложную иерархическую структуру, поскольку допускает многократное применение агрегации. Набор — поименованная совокупность записей, образующих двухуровневую иерархическую структуру. База данных поименованная совокупность экземпляров записей различного типа, содержащая ссылки между записями, представленные экземплярами наборов. Операции, реализуемые СУБД, включают селекцию (поиск) данных; действия над данными. Селекция данных выполняется с помощью критерия, основанного на использовании либо логической позиции данного (элемента; агрегата; записи), либо значения данного, либо связей между данными. Селекция на основе логической позиции данного базируется на упорядоченности данных в памяти системы. Ограничения целостности — логические ограничения на данные — используются для обеспечения непротиворечивости данных некоторым заранее заданным условиям при выполнении операций над ними. По сути ограничения целостности — это набор правил, используемых при создании конкретной модели данных на базе выбранной СУБД. Различают внутренние и явные ограничения. Ограничения, обусловленные возможностями конкретной СУБД, называют внутренними ограничениями целостности. Ограничения, обусловленные особенностями хранимых данных о конкретной ПрОбл, называют явными ограничениями целостности. 98. КОНЦЕПТУАЛЬНЫЕ МОДЕЛИ ДАННЫХ: ИЕРАРХИЧЕСКАЯ МОДЕЛЬ; СЕТЕВАЯ МОДЕЛЬ; РЕЛЯЦИОННАЯ МОДЕЛЬ; БИНАРНАЯ МОДЕЛЬ; СЕМАНТИЧЕСКАЯ МОДЕЛЬ. Классической моделью является модель данных, в основе которой лежит иерархическая структура типа дерева. Дерево — орграф, в каждую вершину которого, кроме первой (корневой), входит только одна дуга, а из любой вершины (кроме конечных) может исходить произвольное число дуг. В иерархической структуре подчиненный элемент данных всегда связан только с одним исходным. Достоинства такой модели: простота представления предметной области, наглядность, удобство анализа структур и простота их описания. К недостаткам следует отнести сложность добавления новых и удаления существующих типов записей, невозможность отображения отношений, отличающихся от иерархических, громоздкость описания и информационную избыточность. Характерные примеры реализации иерархических структур — язык Кобол и СУБД семейства IMS (создана в рамках проекта высадки на Луну – "Аполлон") и System 2000 (S2K). Сетевая модель данных основана на представлении информации в виде орграфа, в котором в каждую вершину может входить произвольное число дуг. Вершинам графа сопоставлены типы записей, дугам — связи между ними. Преимущества: возможность отображения практически всего многообразия взаимоотношений объектов предметной области, непосредственный доступ к любой вершине сети (без указания других вершин), малая информационная избыточность. Вместе с тем в сетевой модели невозможно достичь полной независимости данных — с ростом объема информации сетевая структура становится весьма сложной для описания и анализа. В основе реляционной модели данных лежат не графические, а табличные методы и средства представления данных и манипулирования ими. В реляционной модели для отображения информации о предметной области используется таблица, называемая "отношением". Строка такой таблицы называется кортежем, столбец — атрибутом. Каждый атрибут может принимать некоторое подмножество значений из определенной области — домена. К достоинствам реляционной модели можно отнести наглядность, простоту изменения данных и организации разграничения доступа к ним. Основным недостатком реляционной модели данных является информационная избыточность, что ведет к перерасходу ресурсов вычислительных систем. |