Поручиков М.А. Анализ данных. А. поручиков
 Скачать 2.76 Mb. Скачать 2.76 Mb.
|

КЛАСТЕРНЫЙ АНАЛИЗОбщие сведенияКластерный анализ – (кластеризация) выявление групп (кластеров) объектов в выборке данных. В отличие от регрессии и классификации, кластеризация относится к типу задач обучения без учителя (Unsupervised Learning в терминах Machine Learning). В отличие от классификации, в кластерном анализе не используется выборка ранее классифицированных объектов. Принятие решения о принадлежности объекта к той или иной группе принимается на основе свойств объектов (рис. 40). Набор неклассифицированных объектов  Кластерный анализ Классы объектов   Рис. 40. Схема кластерного анализа Выборка данных в общем случае представляет собой таблицу (табл. 22). Таблица 22. Шаблон набора данных
Метод к-среднихСуществует большое число методов кластерного анализа [22, 23], а наиболее известным является метод (алгоритм) к-средних. Принцип: расчет средневзвешенного расстояния в нормированном эвклидовом пространстве свойств объектов (рис. 41). 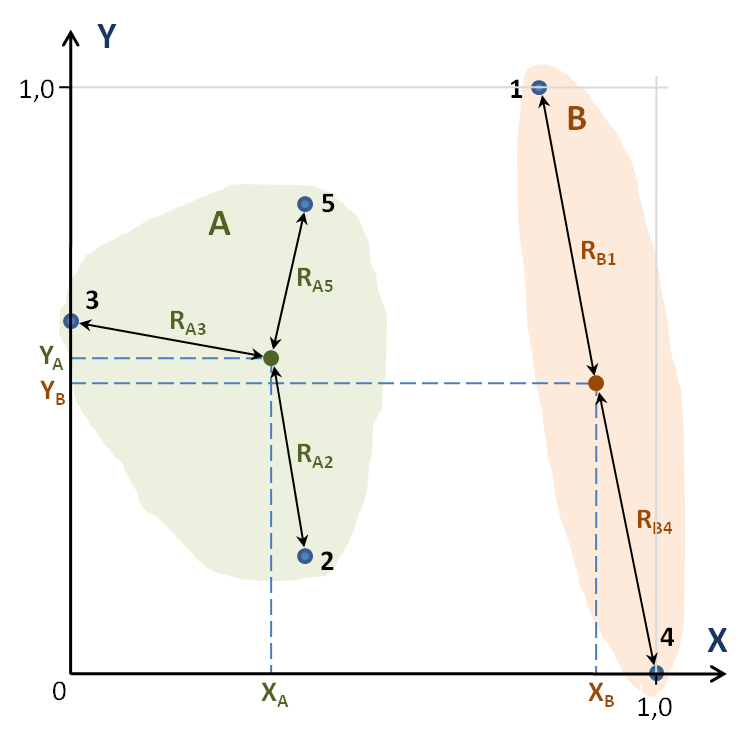 Рис. 41. Метод к-средних Метод к-средних представляет собой следующую последовательность операций: Пользователь задает количество кластеров. Производится первоначальное случайное распределение объектов из выборки данных по кластерам. Вычисляются коодинаты центров кластеров. Вычисляются расстояния от каждого объекта до центров соответствущих кластеров. Рассчитывается функция штрафа – сумма всех расстояний. Каждый из объектов «прикрепляется» к тому кластеру, расстояние до центра которого наименьшее. Шаги 3 – 6 повторяются до тех пор, пока не перестанут изменяться координаты центров кластеров. Особенностью метода к-средних является разный результат выполнения алгоритма при повторном проведении кластерного анализа одной и той же выборки данных, поэтому рекомендуется многократный повтор кластеризации и выбор наилучшего результата. Рассмотрим пример использования метода к-средних. Пусть имеется набор объектов, имеющих два свойства (табл. 23). Таблица 23. Объекты и их свойства
Проведем нормализацию исходных данных, т.е. приведение их к диапазону 0..1 по каждому свойству (измерению) (табл. 24). Таблица 24. Объекты и их нормализованные свойства
Последовательно применив алгоритм метода k-средних, получим следующие результаты (табл. 25). Таблица 25. Варианты распределения объектов по кластерам
Шаг 6 иллюстрирует следующая диаграмма (рис. 42). При этом найденное на этом шаге значение R2 является минимальным, что свидетельствует о наилучшем распределении объектов по кластерам на этом шаге. 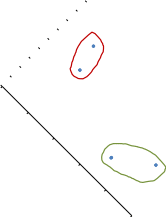  Свойство 2 9 8 7 6 5 4 3 2 1 0 0 10 20 30 40 50 Свойство 1 Рис. 42. Вариант распределения объектов по кластерам Таким образом, найдено следующее оптимальное распределение объектов по кластерам (табл. 26). Таблица 26. Распределение объектов по кластерам
Метод к-средних не дает ответа на вопрос о количестве кластеров в выборке данных. Для определения количества кластеров можно воспользоваться так называемым методом локтя (Elbow Method). Метод локтя предполагает выполнение следующих шагов: Выполняется кластеризация методом к-средних, при этом рассчитывается и записывается значение функции штрафа. Строится график зависимости функции штрафа от заданного числа кластеров. В качестве решения выбирается число кластеров, при котором происходит наибольший перегиб графика. Программноеобеспечениеkmeans Метод к-средних реализован в программном обеспечении kmeans. ПО kmeans предназначено для кластеризации набора объектов, имеющих два свойства и представлено в виде исполняемого файла для ОС Windows. Программное обеспечение имеет однооконный интерфейс (рис. 43). 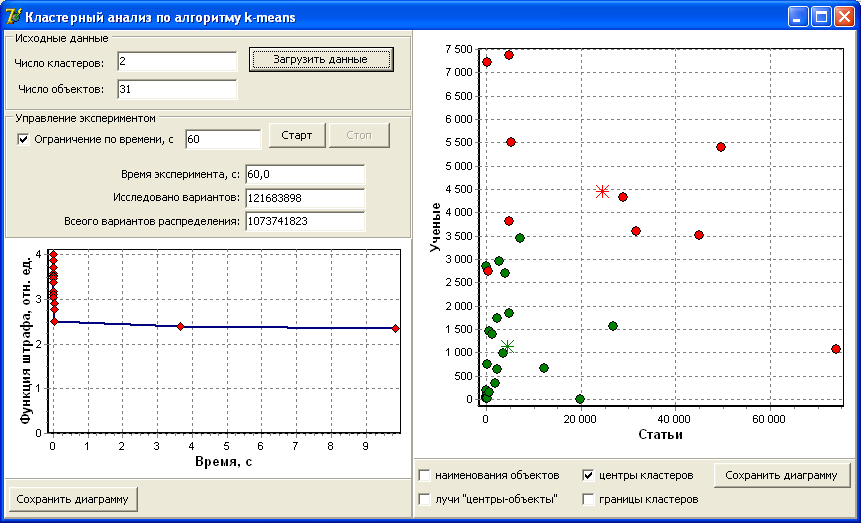 Рис. 43. Интерфейс программного обеспечения k-means Основные функции управления реализованы в панелях «Исходные данные» и «Управление экспериментом» (рис. 44). Панель «Исходные данные»: кнопка «Загрузить данные» предназначена для загрузки исходных данных для кластерного анализа; параметр «Число объектов» показывает количество объектов в загруженном файле данных; показатель «Число кластеров» предназначен для задания числа кластеров, по которым будет производиться разбивка объектов. Панель «Управление экспериментом»: выключатель «Ограничение по времени»; кнопка «Старт» предназначена для запуска процедуры кластеризации. Кластеризация будет происходить, пока не перебраны все возможные варианты или не закончилось время, отпущенное на эксперимент; показатель «Время эксперимента» показывает длительность эксперимента; показатель «Число вариантов» показывает сколько вариантов разбиения объектов по кластерам было исследовано на данный момент; показатель «Варианты распределения по кластерам» показывает число вариантов распределения объектов по кластерам. 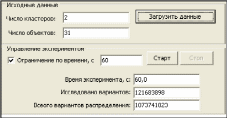 Рис. 44. Панели «Исходные данные» и «Управление экспериментом» График функции штрафа (рис. 45) показывает изменение функции штрафа со временем в процессе кластеризации. Диаграмма распределения по кластерам (рис. 46) показывает расположение объектов в декартовой системе координат и принадлежность объекта к тому или иному кластеру. Горизонтальной оси соответствует первый показатель из исходного файла данных, вертикальной оси – второй. Отображение диаграммы регулируется следующими элементами управления: 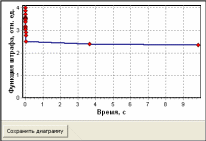 Рис. 45. График функции штрафа выключатель «Наименования объектов» позволяет подписать объекты на диаграмме; выключатель «Лучи “центры-объекты”» позволяет отобразить лучи от центра кластеров до всех объектов кластера; выключатель «Центры кластеров» позволяет отобразить условные центры кластеров; выключатель «Граница» позволяет отобразить условные границы кластеров. Граница представляет собой ломаную линию, объединяющую все объекты каждого кластера; кнопка «Сохранить диаграмму» записывает диаграмму в графический файл в формате PNG; кнопка «Сохранить кластеры» создает файл, cодержащий номера кластеров, координаты их центров и количество объектов в кластерах. 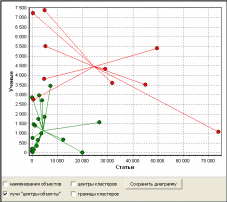 Рис. 46. Диаграмма распределения по кластерам Анализ данных с использованием ПО kmeansпроводится по следующей схеме (рис. 47).  Исходные данные Исходные данныеПараметры эксперимента Классифицированные   
Рис. 47. Схема эксперимента Исходные данные должны быть представлены в файле в формате CSV «Текст, разделенный». В файле должно быть три столбца: Наименования объектов. Значение первого свойства. Значение второго свойства. Первая строка файла должна содержать подписи свойств объектов. Подготовку исходных данных удобно производить в Microsoft Excel (рис. 48). После подготовки данных файл необходимо сохранить в формате CSV (разделители – запятые). 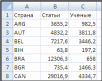 Рис. 48. Представление исходных данных в Microsoft Excel Убедиться в корректности подготовленного файла можно, открыв его в блокноте Windows (рис. 49). 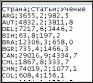 Рис. 49. Представление исходных данных в блокноте Windows | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||