|
|
Задания. Департамент образования, науки и молодежной политики Воронежской области Государственное бюджетное профессиональное образовательное учреждение Воронежской области Лискинский промышленнотранспортный техникум имени А. К. Лысенко
Некоторые ошибки можно исключить из отчета. Для просмотра ошибок, исключенных из отчета, введите команду:
errpt -t -F report=0 | pg
Если такие ошибки есть, включите в отчет все ошибки с помощью команды errupdate.
Некоторые ошибки могут не регистрироваться в протоколе. Для просмотра ошибок, исключенных из протокола, введите команду:
errpt -t -F log=0 | pg
Если такие ошибки есть, включите регистрацию в протоколе для всех ошибок с помощью команды errupdate. Регистрация всех ошибок в протоколе необходима для воссоздания ошибки системы.
Примеры подробных отчетов об ошибках
Ниже приведен пример записей отчета об ошибках, созданного с помощью команды errpt -a.
Класс ошибки H и тип ошибки PERM означают, что в системе была обнаружена ошибка устройства (драйвера адаптера SCSI), которую не удалось устранить.
С этим типом ошибки могут быть связаны данные диагностики.
Эта информация находится в конце сообщения об ошибке.
МЕТКА: SCSI_ERR1
ИД: 0502F666
Дата/Время: Jun 19 22:29:51
Порядковый номер: 95
ИД системы: 123456789012
ИД узла: host1
Класс: H
Тип: PERM
Имя ресурса: scsi0
Класс ресурса: adapter
Тип ресурса: hscsi
Расположение: 00-08
VPD:
Device Driver Level.........00
Diagnostic Level............00
Displayable Message.........SCSI
EC Level....................C25928
FRU Number..................30F8834
Manufacturer................IBM97F
Part Number.................59F4566
Serial Number...............00002849
ROS Level and ID............24
Read/Write Register Ptr.....0120
Описание ADAPTER ERROR
Возможные причины
ADAPTER HARDWARE CABLE
CABLE TERMINATOR DEVICE
Возможные сбои ADAPTER
CABLE LOOSE OR DEFECTIVE
Рекомендуемые действия
PERFORM PROBLEM DETERMINATION PROCEDURES
CHECK CABLE AND ITS CONNECTIONS
Подробные сведения
SENSE DATA
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
Порядковый номер протокола диагностики: 153
Проверенный ресурс: scsi0
Описание ресурса: SCSI I/O Controller
Расположение: 00-08
SRN: 889-191
Описание: Анализ
протокола ошибок указывает на неполадку аппаратного обеспечения.
Возможные FRU:
Шина SCSI FRU: нет 00-08
Вентилятор
SCSI2 FRU: 30F8834 00-08
Контроллер ввода-вывода SCSI
Класс ошибки H и тип ошибки PEND означают, что устройство (Token Ring) может в ближайшее время стать недоступным из-за большого количества ошибок, обнаруженных системой.
МЕТКА: TOK_ESERR
ИД: AF1621E8
Дата/Время: Jun 20 11:28:11
Порядковый номер: 17262
ИД системы: 123456789012
ИД узла: host1
Класс: H
Тип: PEND
Имя ресурса: TokenRing
Класс ресурса: tok0
Тип ресурса: Adapter
Расположение TokenRing
Описание
EXCESSIVE TOKEN-RING ERRORS
Возможные причины
TOKEN-RING FAULT DOMAIN
Возможные сбои TOKEN-RING FAULT DOMAIN
Рекомендуемые действия
REVIEW LINK CONFIGURATION DETAIL DATA
CONTACT TOKEN-RING ADMINISTRATOR RESPONSIBLE FOR THIS LAN
Подробные сведения
SENSE DATA
0ACA 0032 A440 0001 0000 0000 0000 0000 0000 0000 0000 0000 0000
0000 2080 0000 0000 0010 0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 78CC 0000 0000 0005 C88F 0304 F4E0 0000 1000 5A4F 5685
1000 5A4F 5685 3030 3030 0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000
Класс ошибки S и тип ошибки PERM означают, что в системе была обнаружена ошибка программного обеспечения, которую не удалось устранить.
МЕТКА: DSI_PROC
ИД: 20FAED7F
Дата/Время: Jun 28 23:40:14
Порядковый номер: 20136
ИД системы: 123456789012
ИД узла: 123456789012
Класс: S
Тип: PERM
Имя ресурса: SYSVMM
Описание
Data Storage Interrupt, Processor
Возможные причины
SOFTWARE PROGRAM
Возможные сбои SOFTWARE PROGRAM
Рекомендуемые действия
IF PROBLEM PERSISTS THEN DO THE FOLLOWING
CONTACT APPROPRIATE SERVICE REPRESENTATIVE
Подробные сведения
Data Storage Interrupt Status Register
4000 0000
Data Storage Interrupt Address Register
0000 9112
Segment Register, SEGREG
D000 1018
EXVAL
0000 0005
Класс ошибки S и тип ошибки TEMP означают, что в системе была обнаружена ошибка программного обеспечения. После нескольких попыток системе удалось устранить неполадку.
МЕТКА: SCSI_ERR6
ИД: 52DB7218
Дата/Время: Jun 28 23:21:11
Порядковый номер: 20114
ИД системы: 123456789012
ИД узла: host1
Класс: S
Тип: INFO
Имя ресурса: scsi0
Описание
SOFTWARE PROGRAM ERROR
Возможные причины
SOFTWARE PROGRAM
Возможные сбои SOFTWARE PROGRAM
Рекомендуемые действия
IF PROBLEM PERSISTS THEN DO THE FOLLOWING
CONTACT APPROPRIATE SERVICE REPRESENTATIVE
Подробные сведения
SENSE DATA
0000 0000 0000 0000 0000 0011 0000 0008 000E 0900 0000 0000 FFFF
FFFE 4000 1C1F 01A9 09C4 0000 000F 0000 0000 0000 0000 FFFF FFFF
0325 0018 0040 1500 0000 0000 0000 0000 0000 0000 0000 0000 0800
0000 0100 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
0000 0000
Класс ошибки O означает информационное сообщение.
МЕТКА: OPMSG
ИД: AA8AB241
Дата/Время: Jul 16 03:02:02
Порядковый номер: 26042
ИД системы: 123456789012
ИД узла: host1
Класс: O
Тип: INFO
Имя ресурса: OPERATOR
Описание
OPERATOR NOTIFICATION
Ошибки пользователя
errlogger COMMAND
Рекомендуемые действия
REVIEW DETAILED DATA
Подробные сведения
MESSAGE FROM errlogger COMMAND
hdisk1: Анализ протокола ошибок указывает на неполадку аппаратного обеспечения.
Пример краткого отчета об ошибках
Ниже приведен пример краткого отчета об ошибках, созданного с помощью команды errpt. Каждой записи об ошибке соответствует одна строка информации.
ERROR_
ИДЕНТИФИКАТОР СИСТЕМНОЕ_ВРЕМЯ Т КЛ ИМЯ_РЕСУРСА ОПИСАНИЕ_ОШИБКИ
192AC071 0101000070 I 0 errdemon Ведение протокола ошибок выключено
0E017ED1 0405131090 P H mem2 Сбой памяти
9DBCFDEE 0101000070 I 0 errdemon Ведение протокола ошибок включено
038F2580 0405131090 U H scdisk0 НЕОПРЕДЕЛЕННАЯ ОШИБКА
AA8AB241 0405130990 I O OPERATOR ИЗВЕЩЕНИЕ ОПЕРАТОРА
Создание отчета об ошибках
Выполните следующие действия, чтобы создать отчет об ошибках программного обеспечения или неполадках аппаратного обеспечения.
Определите, включено ли ведение протокола ошибок. Для этого проверьте, содержит ли протокол ошибок записи:
errpt -a
Команда errpt создает отчет об ошибках из записей системного протокола ошибок.
Если протокол ошибок пуст, ведение протокола ошибок было отключено. Активизируйте средство ведения протокола ошибок с помощью следующей команды:
/usr/lib/errdemon
Примечание: Для запуска этой команды необходимы права доступа пользователя root.
Демон errdemon запускает ведение протокола ошибок. Если демон не работает, протокол ошибок не ведется.
Создайте отчет об ошибках с помощью команды errpt. Например, для просмотра всех ошибок дискового накопителя hdisk1 введите команду:
errpt -N hdisk1
Создайте отчет об ошибках с помощью SMIT. Например, с помощью команды smit errpt:
smit errpt
Выберите 1, чтобы направить отчет об ошибках в стандартный вывод, или 2, чтобы отправить отчет на принтер.
Выберите yes, чтобы просматривать или распечатывать записи протокола ошибок по мере из добавления, в противном случае выберите no.
Укажите нужное имя устройства в опции Выбрать имена ресурсов (например hdisk1).
Выберите Do.
Завершение ведения протокола ошибок
В данном разделе описано завершение работы средства ведения протокола ошибок. Как правило, нет необходимости отключать средство ведения протокола ошибок. Вместо этого следует удалить из протокола ошибок старые и ненужные записи. Инструкции по очистке протокола ошибок приведены в разделе Очистка протокола ошибок.
Средство ведения протокола ошибок следует отключать при установке или проверке нового программного или аппаратного обеспечения. В этом случае демон ведения протокола ошибок не будет отнимать время центрального процессора на регистрацию известных вам ошибок.
Примечание: Для запуска применяемой в этой процедуре команды у вас должны быть права доступа пользователя root.
Введите команду errstop, чтобы отключить ведение протокола ошибок:
errstop
Команда errstop завершает работу демона ведения протокола.
Очистка протокола ошибок
Этот раздел содержит информацию по удалению из протокола ошибок старых и ненужных записей. Обычно очистка протокола автоматически выполняется ежедневно с помощью команды cron.
Если эта процедура не выполняется автоматически, следует время от времени очищать протокол ошибок вручную, предварительно проверив его на наличие записей о серьезных неполадках.
Кроме того, можно удалить записи о конкретных ошибках. Например, после замены дискового накопителя можно удалить из протокола ошибок записи об ошибках старого дискового накопителя.
Для удаления всех записей протокола ошибок выполните одно из следующих действий:
Вызовите команду errclear-d. Например, для удаления всех записей об ошибках программного обеспечения, введите команду:
errclear -d S 0
Команда errclear удаляет из протокола ошибок записи, внесенные раньше определенного числа дней. В предыдущем для удаления всех записей указано значение 0.
Введите команду smit errclear:
smit errclear
Копирование протокола ошибок на дискету или магнитную ленту
Выполните следующие действия, чтобы скопировать протокол ошибок:
С помощью команд ls и backup скопируйте протокол ошибок на дискету. Вставьте отформатированную дискету в дисковод и введите команду:
ls /var/adm/ras/errlog | backup -ivp
Для копирования протокола ошибок на магнитную ленту вставьте магнитную ленту в лентопротяжное устройство и введите команду:
ls /var/adm/ras/errlog | backup -ivpf/dev/rmt0
ИЛИ
С помощью команды snap соберите информацию о конфигурации системы в файл tar и скопируйте его на дискету. Вставьте отформатированную дискету в дисковод и введите команду:
Примечание: Для запуска команды snap у вас должны быть права доступа пользователя root.
snap -a -o
/dev/rfd0
В этом примере для сбора всей информации о конфигурации системы в команде snap указан флаг -a. Флаг -o позволяет скопировать сжатый файл tar на указанное устройство. /dev/rfd0 указывает дисковод.
Введите следующую команду, чтобы собрать всю информацию о конфигурации в файле tar и скопировать его на магнитную ленту:
snap -a -o /dev/rmt0
/dev/rmt0 указывает лентопротяжное устройство.
Текущий контроль
6семестр
Лабораторная работа
форма текущего контроля
по теме: Выявление и устранение ошибок программного кода информационных систем
Цель: выявлять и устранять ошибки программного кода информационных систем
По завершению практического занятия студент должен уметь: выявлять и устранять ошибки программного кода информационных систем
Продолжительность: 4 аудиторных часа (180 минут)
Необходимые принадлежности
Персональный компьютер, программное обеспечение: среда PowerDesigner.
Задание
Системы моделирования обладают множеством достоинств. Обычно в их составе имеются отладчики и средства вывода информации на печать, однако системы моделирования это всего лишь имитаторы. Отлаживаемая программа может успешно исполняться в системе моделирования и быть полностью неработоспособной в реальных условиях. Так что системы моделирования это лишь частичное решение. Ошибки программного обеспечения вполне могут пройти мимо системы моделирования и всплыть в реальном оборудовании.
|
Именно в этом и скрыта главная проблема: как показано на рис. 1, исправление ошибок, которые выявляются не на этапе тестирования, а в процессе использования, обходится значительно дороже. Если ошибка найдена в программе для не-встраиваемых систем, то можно выпустить обновленную версию программы с исправлениями, стоимость таких обновлений, как правило, сравнительно невысокая. Если же ошибка найдена во встроенной системе, то для ее исправления необходим возврат и модификация самих устройств с этой системой. Стоимость такого возврата может достигать астрономических величин, и стать причиной разорения компаний.
|
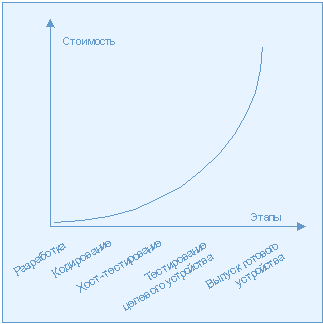 Рис. 1. Стоимость устранения ошибок во встраиваемых системах Рис. 1. Стоимость устранения ошибок во встраиваемых системах
|
|
На мой взгляд, сроки и затраты на выявление и устранение ошибок для встраиваемых систем приблизительно удваиваются (из-за описанных выше трудностей). В свете таких немыслимых затрат любой метод, который изначально будет препятствовать появлению ошибок, имеет неоценимое значение. К счастью для разработчиков встраиваемых систем, для предотвращения ошибок можно использовать некоторые из новых технологий программной разработки. Наиболее рекомендуемые две из них: стандарты программирования и блочное тестирование.
|
Правда, оба этих метода сегодня не столько применяются, сколько прославляются. Практически каждый разработчик программного обеспечения согласен с их высокой ценностью, но пользуются ими единицы. Подобная непоследовательность объясняется в большинстве случаев двумя причинами. Прежде всего, многие считают следование стандартам программирования и блочное тестирование весьма утомительным делом. Учитывая, сколько времени и сил эти подходы позволяют сэкономить в будущем, разработчикам следовало бы немножко потерпеть и избежать огромных трудозатрат (и возможного отказа от проекта) впоследствии.
|
Разработчикам систем реального времени еще труднее они в дополнение ко всему должны решать проблемы, связанные с соблюдением различных временных зависимостей. В конце статьи мы рассмотрим трудности, возникающие при отладке систем реального времени, и познакомимся с некоторыми методами отладки, которые рассчитаны на преодоление этих трудностей и которые также могут быть использованы при разработке любого программного обеспечения.
|
Способы отладки программ Отладка программ заключается в проверке правильности работы программы и аппаратуры. Программа, не содержащая синтаксических ошибок тем не менее может содержать логические ошибки, не позволяющие программе выполнять заложенные в ней функции. Логические ошибки могут быть связаны с алгоритмом программы или с неправильным пониманием работы аппаратуры, подключённой к портам микроконтроллера. Встроенный в состав интегрированной среды программирования отладчик позволяет отладить те участки кода программы, которые не зависят от работы аппаратуры, не входящей в состав микросхемы микроконтроллера. Обычно это относится к вычислению математических выражений или преобразованию форматов представления данных. Для отладки программ обычно применяют три способа:
Пошаговая отладка программ с заходом в подпрограммы;
Пошаговая отладка программ с выполнением подпрограммы как одного оператора;
Выполнение программы до точки останова.
Пошаговая отладка программ заключается в том, что выполняется один оператор программы и, затем контролируются те переменные, на которые должен был воздействовать данный оператор. Если в программе имеются уже отлаженные подпрограммы, то подпрограмму можно рассматривать, как один оператор программы и воспользоваться вторым способом отладки программ. Если в программе существует достаточно большой участок программы, уже отлаженный ранее, то его можно выполнить, не контролируя переменные, на которые он воздействует. Использование точек останова позволяет пропускать уже отлаженную часть программы. Точка останова устанавливается в местах, где необходимо проверить содержимое переменных или просто проконтролировать, передаётся ли управление данному оператору. Практически во всех отладчиках поддерживается это свойство (а также выполнение программы до курсора и выход из подпрограммы). Затем отладка программы продолжается в пошаговом режиме с контролем локальных и глобальных переменных, а также внутренних регистров микроконтроллера и напряжений на выводах этой микросхемы.
 Следуйте стандартам программирования! Следуйте стандартам программирования!
|

|
Самый лучший способ повысить качество ПО это стараться не допускать ошибок в процессе ввода исходного текста.
|
Первый шаг на пути предотвращения ошибок это осознание того, что ошибки действительно можно предотвратить. Больше всего препятствует контролю над ошибками распространенное убеждение в том, что ошибки неизбежны. Это заблуждение! Ошибки сами по себе не появляются их вносит в текст разработчик. Человеку свойственно ошибаться, так что даже самые лучшие программисты время от времени допускают ошибки, если у них есть такая возможность. Поэтому чтобы уменьшить число ошибок, надо сократить возможности их появления. Один из лучших способов здесь следование стандартам программирования, что ликвидирует благодатную почву для возникновения ошибок на первых этапах.
|
Стандарты программирования это специфичные для языка "правила", которые, если их соблюдать, значительно снижают вероятность внесения ошибок в процессе разработки приложения. Следовать стандартам программирования нужно на этапе написания программ, до их переноса в целевые платформы, при этом стандартизация должна существовать для всех языков. Поскольку большая часть разработчиков встраиваемых систем пользуется языком С, больше внимания уделим именно стандартам программирования на C, хотя такие же стандарты существуют и для других языков, включая С++ и Java.
|
Как правило, стандарты программирования делятся на две категории:
|
отраслевые стандарты программирования: правила, принятые всеми программистами на данном языке (например, запрет входа в цикл не через его заголовок).
|
специальные стандарты программирования: правила, соблюдаемые конкретной группой разработчиков, в рамках конкретного проекта, или даже единственным программистом. Существует три типа специальных стандартов, которыми может воспользоваться разработчик встраиваемой программной системы: внутренние стандарты, персональные стандарты и стандарты, определяемые целевой платформой.
|
Внутренние стандарты программирования это правила, которые специфичны для вашей организации или группы разработчиков. Так, уникальные для организации правила присвоения имен это пример внутренних стандартов программирования.
|
Персональные стандарты это правила, которые помогут вам избежать ваших наиболее частых ошибок. Каждый раз при появлении какой-либо ошибки программист должен проанализировать причину ее появления и выработать собственное правило, препятствующее повторному ее возникновению. Например, если в операторе условия вы часто пишете знак присваивания вместо знака проверки на равенство (т.е. "if (a=b)" вместо "if (a= =b)"), то вам необходимо создать для себя следующий стандарт: "Остерегаться применения знака присваивания в операторе проверки условия".
|
Стандарты, определяемые целевой платформой, это правила, нарушение которых в данной платформе может привести к появлению определенных проблем. Например, такими стандартами могут быть ограничения на использование памяти или размер переменных, налагаемые целевой платформой.
|
Чтобы лучше разобраться в том, что такое стандарты программирования и как они работают, познакомимся с ними на конкретных примерах. Рассмотрим следующую запись на языке С:
|
char *substring (char string[80], int start_pos, int length)
|
{
|
.
|
.
|
.
|
}
|
Здесь размер одномерного массива декларируется в списке аргументов функции. Это опасная конструкция, поскольку в языке С аргумент-массив передается как указатель на его первый элемент, и в разных обращениях к функции в числе ее фактических аргументов могут указываться массивы с разной размерностью. Создав такую конструкцию, вы предполагаете пользоваться буфером фиксированного размера на 80 элементов, считая, что именно такой буфер и будет передаваться функции, а это может привести к разрушению памяти. Если бы автор этого оператора следовал стандарту программирования "не объявлять размер одномерного массива в числе аргументов функции" (взятому из набора стандартов программирования на языке С одной из ведущих телекоммуникационных компаний), то этот текст выглядел бы следующим образом и проблем с разрушением памяти удалось бы избежать:
|
char *substring (char string[], int start_pos, int length)
|
{
|
.
|
.
|
.
|
}
|
Стандарты программирования позволяют также избегать проблем, которые до момента портирования кода на другую платформу могут не проявляться. Например, следующий кусок кода будет исправно работать на одних платформах и порождать ошибки после переноса его на другие платформы:
|
#include
|
void test(char c) {
|
if( a <= c && c <= z ) { // Неправильно
|
}
|
if(islower(c)) {// Правильно
|
}
|
while ( A <= c && c <= Z ) { // Неправильно
|
}
|
while (isupper(c)) { // Правильно
|
}
|
}
|
Проблемы портации могут быть связаны с символьными тестами, в которых не используется функции ctype.h (isalnum, isalpha, iscntrl, isdigit, isgraph, islower, isprint, ispunct, isspace, isupper, isxdigit, tolower, toupper). Функции ctype.h для символьной проверки и преобразования прописных букв в строчные и наоборот работают с самыми разными наборами символов, обычно очень эффективны и гарантируют международную применимость программного продукта.
|
Лучший способ внедрить эти и другие стандарты программирования это обеспечить их автоматическое применение в составе какой-либо технологии программирования, вместе с набором целенаправленных отраслевых стандартов и механизмами создания и поддержки стандартов программирования, ориентированных на конкретную систему. При выборе подобной технологии необходимо сначала найти ответы на вопросы, среди которых следующие:
|
Применима ли она к данной программе и/или компилятору?
|
Содержит ли она набор отраслевых стандартов программирования?
|
Позволяет ли она создавать и поддерживать специальные стандарты программирования (включая стандарты, определяемые целевой платформой)?
|
Легко ли структурировать отчеты в соответствии с вашими групповыми и проектными приоритетами?
|
Насколько легко она интегрируется в существующий процесс разработки?
|
Блочное тестирование
|
|
Зачастую, слыша о блочном тестировании, разработчики воспринимают его как синоним модульного тестирования. Другими словами, проверяя отдельный модуль или подпрограмму более крупной программной единицы, разработчики считают, что выполняют блочное тестирование. Конечно, модульное тестирование имеет очень большое значение и, безусловно, должно проводиться, но это не тот метод, на котором я бы хотел остановиться. Говоря о "блочном тестировании", я имею в виду тестирование на еще более низком уровне: тестирование самых минимально возможных программных единиц, из которых состоит прикладная программа, всё ещё находясь в инструментальной среде (хост-системе) в случае языка С, это будут функции, которые проверяются сразу же после их компиляции.
|
Блочное тестирование значительно повышает качество программного обеспечения и эффективность процесса разработки. При тестировании на уровне объектов вы гораздо ближе к этой методике и обладаете гораздо большими возможностями построения входных наборов, выявляющих ошибки со стопроцентным покрытием (рис. 2). Кроме того, тестируя блок кода сразу после того, как он был написан, вы тем самым избегаете необходимости "продираться" через наслоения ошибок, чтобы найти и исправить единственную исходную в данном случае вы сразу ее устраняете, и вся проблема решена. Это существенно ускоряет и облегчает процесс разработки, поскольку на поиск и устранение ошибок тратится значительно меньше материальных и временных ресурсов.
|
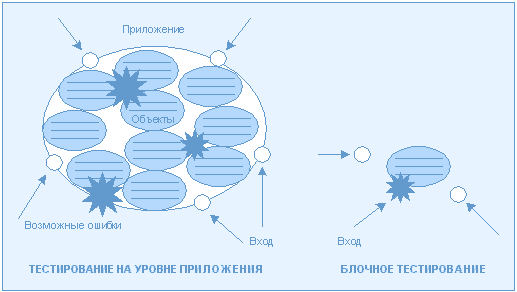 Рис. 2. Простота нахождения ошибок при блочном тестировании Рис. 2. Простота нахождения ошибок при блочном тестировании
|
|
Блочное тестирование можно разделить минимум на два отдельных процесса. Первый это тестирование "черного ящика", или процесс определения функциональных проблем. На уровне отдельных блоков тестирование "черного ящика" заключается в проверке функциональных характеристик посредством определения степени соответствия параметров открытого интерфейса функции ее спецификации; подобная проверка выполняется без учета способов реализации. Результатом тестирования "черного ящика" на блочном уровне является уверенность в том, что данная функция ведет себя в полном соответствии с определением и что незначительная функциональная ошибка не приведет к лавине трудноразрешимых проблем.
|
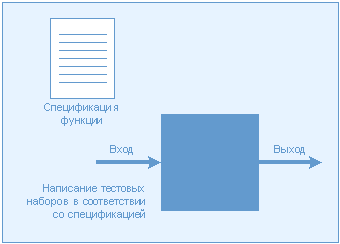 Рис. 3. Тестирование "черного ящика" Рис. 3. Тестирование "черного ящика"
|
|
Второй процесс называется тестированием "белого ящика" и предназначен для выявления конструктивных недостатков. На уровне отдельных блоков проверяется, не произойдёт ли крах всей программы при передаче в функцию неожидаемых ею параметров. Этот вид тестирования должен проводиться специалистом, имеющим полное представление о способе реализации проверяемой функции. После такой проверки можно быть уверенным в том, что приводящих к краху системы ошибок нет и что функция будет устойчиво работать в любых условиях (т.е. выдавать предсказуемые результаты даже при вводе непредвиденных входных параметров).
|
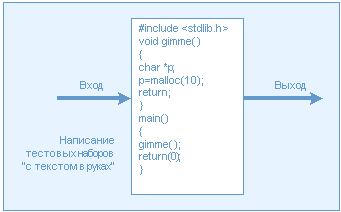 Рис. 4. Тестирование "белого ящика" Рис. 4. Тестирование "белого ящика"
|
|
Оба вышеописанных процесса могут служить основой третьего, регрессивного тестирования. Сохранив тестовые наборы для "черного" и "белого" ящиков, можно использовать их для регрессивного тестирования на уровне блоков и контролировать целостность кода по мере того, как вы его модифицируете. Концепция регрессивного тестирования на этом уровне является новым оригинальным подходом. При выполнении регрессивного тестирования на уровне блоков можно сразу же после изменения вами текста определять, не появились ли новые проблемы, и устранять их немедленно после возникновения, тем самым препятствуя распространению ошибки по вышележащим уровням.
|
Главная проблема, связанная с блочным тестированием, заключается в том, что если не пользоваться технологиями автоматического блочного тестирования, проводить его трудно, утомительно и слишком долго. Рассмотрим вкратце причины, по которым включать неавтоматизированное блочное тестирование в сегодняшние процессы разработки трудно (если вообще возможно).
|
Первый этап блочного тестирования ПО встраиваемых систем заключается в создании такой среды, которая позволит запускать и тестировать интересующую функцию в хост-системе. Это требует выполнения следующих двух действий:
|
разработка программного текста, который будет запускать функцию,
|
написание фиктивных модулей, которые будут возвращать результаты вместо внешних ресурсов, к которым обращается функция и которые в текущий момент отсутствуют или недоступны.
|
Второй этап разработка тестовых наборов. Для полноты охвата конструктивных и функциональных особенностей функции необходимо создавать тестовые наборы двух типов: для "черного ящика" и для "белого ящика".
|
Основой разработки тестовых наборов для "черного ящика" должна стать спецификация функции. В частности, для каждой записи в спецификации должен быть создан хотя бы один тестовый набор, при этом желательно, чтобы эти наборы учитывали указанные в спецификации граничные условия. Проверять того, что некоторые входные параметры приводят к ожидаемым результатам, недостаточно; необходимо определить диапазон взаимосвязей входов и выходов, который позволит сделать вывод о корректной реализации указанных функциональных характеристик, и затем создавать тестовые наборы, полностью покрывающие данный диапазон. Можно также тестировать не указанные в спецификации и ошибочные условия.
|
Цель тестовых наборов для "белого ящика" обнаружить все скрытые дефекты путем всестороннего тестирования функции разнообразными входными параметрами. Эти наборы должны обладать следующими возможностями:
|
обеспечивать максимально возможное (100%) покрытие функции: как уже говорилось, такая степень покрытия на уровне блоков возможна, поскольку создавать наборы для тестирования каждой характеристики функции вне приложения гораздо проще (стопроцентное покрытие во всех случаях невозможно, но это цель, к которой надо стремиться);
|
выявлять условия краха функции.
|
Следует заметить, что самостоятельно создание подобных наборов, не владея технологиями их построения, невероятно тяжелое занятие. Чтобы создать эффективные тестовые наборы для "белого ящика", необходимо сначала получить полное представление о внутренней структуре функции, написать наборы, обеспечивающие максимальное покрытие функции, и найти совокупность входов, приводящих к отказу функции. Получить спектр покрытия, необходимый для высокоэффективного тестирования "белого ящика", возможно лишь при исследовании значительного числа путей прохода по функции. Например, в обычной программе, состоящей из 10000 операторов, имеется приблизительно сто миллионов возможных путей прохода; вручную создать тестовые наборы для проверки всех этих путей невозможно.
|
После создания тестовых наборов необходимо провести тестирование функции в полном объеме и проанализировать результаты с целью выявления причин ошибок, крахов и слабых мест. Необходимо иметь способ прогона всех тестовых наборов и быстрого определения, какие из них приводят к возникновению проблем. Необходимо также иметь инструмент измерения степени покрытия для оценки полноты тестирования функции и определения необходимости в дополнительных тестовых наборах.
|
При любых изменениях функции следует проводить регрессивное тестирование, чтобы убедиться в отсутствии новых и/или устранении предыдущих ошибок. Включение блочного регрессивного тестирования в процесс разработки позволит защититься от многих ошибок они будут обнаружены сразу же после возникновения и не смогут стать причинами распространения ошибок в приложении.
|
Регрессивное тестирование можно проводить двумя способами. Первый заключается в том, что разработчик или испытатель анализирует каждый тестовый набор и определяет, на работе которого из них может сказаться измененный код. Этот подход характеризуется экономией машинного времени за счет работы, проводимой человеком. Второй, более эффективный, заключается в автоматическом прогоне на компьютере всех тестовых наборов после каждого изменения текста. Данный подход гарантирует большую эффективность труда разработчика, поскольку он не должен тратить время на анализ всей совокупности тестовых наборов, для того чтобы определить, какие наборы следует прогонять, а какие нет.
|
Если вы сможете автоматизировать процесс блочного тестирования, то не только повысите качество тестирования, но и высвободите для себя значительно больше временных и материальных ресурсов, чем уйдёт на этот процесс. Если вы пишете программы на языке С, то для автоматизации блочного тестирования можете воспользоваться существующими технологиями. Чем больше процессов вы сможете автоматизировать, тем больше пользы вы получите.
|
При выборе технологии блочного тестирования сначала следует ответить на следующие вопросы:
|
Подходит ли эта технология для вашего текста и/или компилятора?
|
Может ли она автоматически создавать тестовые схемы?
|
Может ли она автоматически генерировать тестовые наборы?
|
Позволяет ли она вводить создаваемые пользователем тестовые наборы и фиктивные модули?
|
Автоматизировано ли регрессивное тестирование?
|
Имеется ли в ее составе технология или связь с технологией автоматического распознавания ошибки в процессе прогона?
|
Средства отладки, не меняющие режим работы программ
|
|
Из-за того, что операционные системы реального времени должны выполнять определенные задачи в условиях заранее определенных временных ограничений, временные соотношения превращаются в важнейший параметр, который разработчики должны учитывать при установке тестового ПО. Обычно в процессе исполнения программ возникает множество различных прерываний, и чрезвычайно необходимо, чтобы в момент возникновения прерывания приложение реагировало корректно. Ситуация еще более усложняется, когда несколько прерываний возникает сразу или когда в системе исполняется несколько приложений с несколькими взаимодействующими друг с другом тредами. По сути, это приложения с несколькими одновременными путями исполнения различные кодовые последовательности как бы исполняются в одно и то же время, даже если в системе всего один центральный процессор. Интересно заметить, что если бы эти приложения исполнялись в нескольких процессорах, то различные треды на практике были бы загружены в разные процессоры.
|
Если возникающие в приложениях реального времени ошибки проявляются во взаимодействиях между программой и прерываниями, то они будут в значительной мере чувствительны ко времени. В этом случае критически важно регистрировать порядок возникновения ошибок, поскольку это позволит разобраться в причинах и следствиях каждой ошибки. В этом как раз и кроется главная проблема отладки систем реального времени: существует достаточное количество трудновыявляемых ошибок, которые проявляются только при определенных временных соотношениях.
|
Эта проблема осложняется тем, что подобные ошибки не так-то просто воспроизводятся. Очень трудно воссоздать ситуацию с такими же временными соотношениями, что и приведшие к возникновению ошибки в реальной программе. Механизм отладки таких приложений должен быть максимально возможно щадящим . Любое вмешательство в ход исполнения программ может привести к изменению ее временных характеристик и отсутствию условий возникновения ошибок. Конечно, создание условий, при которых ошибки не возникают, это хорошо, но в данном случае это является препятствием отладке программы.
|
Теоретической основой проблемы отладки систем реального времени может послужить известный всем из курса физики принцип неопределенности немецкого физика Вернера Гейзенберга, согласно которому одновременно определить скорость и местоположение движущейся частицы невозможно. Гейзенберг считал, что, определяя координаты частицы, экспериментатор тем самым изменяет её местоположение, что не позволяет определить её координаты точно. Операция измерения влияет на измеряемый объект и искажает результаты измерения. Принцип неопределенности это одна из аксиом квантовой механики.
|
Применительно же к нашей теме, этот принцип означает, что отладка системы требует сбора информации о ее состоянии. Однако сбор информации о состоянии системы меняет ее временные характеристики и существенно затрудняет надежное воспроизведение условий возникновения ошибки.
|
Таким образом, суть этой проблемы в том, что нужно найти способ обнаружения ошибок реального времени и анализа поведения программы без влияния на существующие временные соотношения. Наверное, вашим первым порывом было бы обращение к отладчику, но отладчики, как правило, прерывают исполнение программы и, соответственно, изменяют ее временные характеристики. Малопригодны и системы моделирования, поскольку они не могут воссоздать временные характеристики реальных технических средств. Еще никто не создал такую систему моделирования, которая могла бы смоделировать режим реального времени; временные параметры можно определить, только загрузив программу в само железо.
|
Последнее требует наличия специального механизма для упрощенной регистрации состояния системы. Один из возможных и подходящих механизмов запись информации в оперативную память, поскольку такая операция выполняется чрезвычайно быстро. Один из способов применения этого механизма организация где-нибудь в памяти специального буфера и использование в вашей программе указателя на этот буфер. Указатель всегда ссылается на начало буфера. В программу вставляются операции записи в ячейку, определяемую указателем. После каждой операции записи значение указателя меняется соответствующим образом. Иногда полезно пользоваться кольцевым буфером (т.е. когда после записи в последнюю ячейку буфера указатель начинает показывать на начало буфера), что позволяет отслеживать ситуации, приводящие к возникновению проблемы. Необходимо при этом предусмотреть способ сохранения содержимого буфера после нормального или аварийного завершения программы, чтобы впоследствии иметь к нему доступ и проводить так называемую "посмертную отладку". Способ реализации зависит от аппаратных средств, обычно это можно сделать, если не выполнять повторную инициализацию (reset) оборудования.
|
Теперь вам нужен механизм чтения этой памяти. Здесь можно использовать и отладчик, и другие средства извлечения информации из оперативной памяти. В частности, можно написать простенькую программу, которая будет пересылать эти данные в файл или на принтер. Каким бы средством вы не пользовались, конечным этапом, вероятнее всего, будет ручной анализ содержимого буфера. Если ваш буфер кольцевой, то вам необходимо иметь точные сведения о значении указателя; события, которые стали началом последовательности, будут непосредственно перед указателем, события, которые возникли непосредственно перед крахом, будут сразу же после указателя.
|
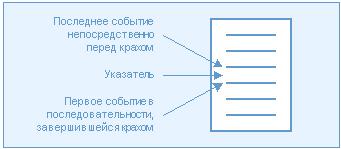 Рис. 5. Последовательность событий в кольцевом буфере Рис. 5. Последовательность событий в кольцевом буфере
|
|
Теперь ваша главная задача попытаться разобраться в последовательности данных, записанных в буфере. Эта задача аналогична исследованию причин катастрофы самолета по показаниям приборов, зарегистрированных "черным ящиком" самолета. Анализ характеристик программы в этом случае проводится после свершившегося события, что, естественно, гораздо меньше влияет на ее исполнение, чем контроль в течение работы.
|
Иногда бывает очень трудно восстановить приведшие к краху события, и четкого понятия о моменте возникновения ошибки нет. Только на выяснение причины ошибки могут уходить многие месяцы. В таких случаях для поиска ошибочного оператора можно воспользоваться логарифмическим методом отладки. В разных местах отлаживаемого кода расставляются маркеры (например, операторы типа exit), а перед ними операторы записи в память. Затем запускаете программу и ожидаете момента краха. В случае краха вы знаете, между какими маркерами он произошел. Этот метод позволяет выявлять и проблемы согласования по времени, поскольку он позволяет находить сегменты кода, в которых возникают нарушения временных соотношений.
|
Ещё одно решение это применение в качестве технологии отладки так называемых брандмауэров. Брандмауэр это точка в логическом потоке программы, в которой доказывается справедливость предположений, на которые опирается последующий код. Проверка этих предположений отличается от обычного контроля ошибок. Срабатывание брандмауэра представляет собой сигнал разработчику о том, что внутреннее состояние системы неустойчиво. Это может произойти, например, если ожидающая строго положительного аргумента функция получает нулевую или отрицательную величину. Неискушённым разработчикам большинство брандмауэров кажутся тривиальными и ненужными. Однако опыт разработки крупных проектов показывает, что по мере развития и совершенствования программных систем неявные предположения в отношении среды исполнения нарушаются все чаще и чаще. Во многих случаях даже сам автор затрудняется сформулировать, что представляют собой надлежащие условия исполнения того или иного участка кода.
|
Реализуемые внутри встраиваемых систем брандмауэры нуждаются в специальных средствах связи для передачи сообщений во внешний мир; обсуждение способа установления таких каналов передачи выходит за рамки настоящей статьи.
|
Заключение
|
|
Рассмотренные выше методы предотвращения и обнаружения ошибок, а также технологии отладки могут значительно повысить качество программного обеспечения встраиваемых систем и уменьшить затрачиваемые на проведение отладки материальные и временные ресурсы. Вышеупомянутые методы без особого труда могут быть использованы в разработке самых разных проектов программного обеспечения встраиваемых систем, причем накопленный опыт полностью сохраняет свою ценность и при реализации иных проектов и целевых технологий. Кроме того, они позволяют гарантировать простоту сопровождения, модификации и портации созданных программ в устройства новых типов. И говоря коротко, рассматриваемые методы дают возможность не только совершенствовать существующие встроенные приложения и процессы разработки, но и гарантировать, что с распространением новых встраиваемых устройств у вас уже будет накоплен опыт, необходимый для разработки высокоэффективных приложений для этих технологий причем вовремя и в соответствии с выделенным бюджетом.
|
|
|
|
 Скачать 7.79 Mb.
Скачать 7.79 Mb.