Эконометрика. Этапы вероятностностатистического моделирования. 4
 Скачать 338.27 Kb. Скачать 338.27 Kb.
|

Фиктивные переменные. Использование фиктивных переменных для моделирования сезонных компонентов.Фиктивная переменная (англ. dummy variable) — качественная переменная, принимающая значения 0 и 1, включаемая в эконометрическую модель для учёта влияния качественных признаков и событий на объясняемую переменную. Данный метод заключается в построении модели регрессии, включающей фактор времени и фиктивные переменные. Количество фиктивных переменных определяется как , где - число периодов в цикле (сезонов внутри года), так при моделировании поквартальных данных модель будет содержать три фиктивные переменные и фактор времени Каждому периоду будет соответствовать свое сочетание фиктивных переменных, каждая из которых равна или , сезон, для которого значения всех фиктивных переменных равны , принимается за эталон сравнения. В остальных сезонах одна из фиктивных переменных равна . Например, при моделировании поквартальных данных модель должна включать 4 независимые переменные. Каждая фиктивная переменная отражает сезонную (циклическую) компоненту временного ряда для какого-либо одного периода. Она равна единице для данного периода и нулю для всех остальных периодов. Пусть имеется временной ряд, содержащий циклические колебания периодичностью к. Модель регрессии с фиктивными переменными для этого ряда будет иметь вид: 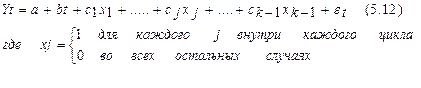 Например, при моделировании сезонных колебаний на основе поквартальных данных за несколько лет число кварталов внутри одного года к=4, а общий вид модели следующий: 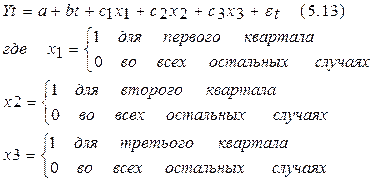 Уравнение тренда для каждого квартала будет иметь следующий вид: для I квартала: для II квартала: для III квартала: для IV квартала: Таким образом, фиктивные переменные позволяют дифференцировать величину свободного члена уравнения регрессии для каждого квартала. Она составит: для I квартала: а+с1 для II квартала: а+с2 для III квартала: а+с3 для IV квартала: а Параметр b в этой модели характеризует среднее абсолютное изменение уровней ряда под воздействием тенденции. В сущности, модель (5.13) есть аналог аддитивной модели временного ряда, поскольку фактический уровень временного ряда есть сумма трендовой, сезонной и случайной компонент. |
Панельные данные, преимущества применения панельных данныхТермин "панельные данные" (panel data) пришел из обследований индивидов, и в этом контексте "панель" представляла собой группу индивидов, за которыми регулярно осуществляли наблюдения в течение определенного периода времени. В настоящее время методы анализа панельных данных получили большое распространение, и понимание панельных данных стало намного шире. Наряду с термином "панельные данные" иногда также используется термин "лонгитюдные данные" (longitudinal data). Панельные данные состоят из повторных наблюдений одних и тех же выборочных единиц, которые осуществляются в последовательные периоды времени. В качестве объектов наблюдения могут выступать индивиды, домашние хозяйства, фирмы, страны и т.д. Примером панельных данных могут быть ежегодные обследования одних и тех же домашних хозяйств или индивидов (например, для определения изменения их благосостояния), ежеквартальные данные об экономической деятельности отдельных компаний, ежегодные социально-экономические показатели для регионов одной страны или для группы стран и т.д. Панельные данные совмещают в себе как пространственные данные, так и временные ряды и сочетают достоинства каждого их этих видов данных. Это позволяет строить более адекватные и содержательные модели для изучения истинной причинно-следственной связи между различными переменными, что представляется невозможным в рамках только временных или только пространственных данных. Выделяют следующие преимущества использования панельных данных. 1. Панельные данные позволяют учитывать индивидуальную неоднородность. Временные ряды или пространственные данные не всегда позволяют учесть неоднородность индивидов, фирм, регионов или стран, что может привести к смещенным оценкам. Так, например, в исследовании Б. Балтаги и Д. Левина изучался спрос на сигареты в США. Спрос моделировался как функция от лагов потребления, цены и дохода. Эти переменные отличались по штатам и во времени. Однако существовало множество других факторов, различающихся по штатам или во времени, которые могли оказывать влияние на потребление, например, такие факторы, как религия, образование и реклама на телевидении и радио. При измерении этих переменных для каждого штата и периода времени возникают определенные трудности и очень сложно достигнуть того, чтобы их можно было включить в уравнение потребления. Однако пропуск этих переменных приведет к смещению в оценках. Панельные данные способны учитывать переменные, отличающиеся по штатам и во времени, вне зависимости от того, измеряемы они или нет, в то время как временные ряды или пространственные данные не позволяют этого сделать. Таким образом, панельные данные дают возможность избежать ошибки спецификации, возникающей из-за того, что существенные переменные не включены в модель. 2. Панельные данные содержат большое число наблюдений и тем самым предоставляют исследователю большее количество информации, им свойственна большая вариация и меньшая коллинеарность объясняющих переменных, они дают большее число степеней свободы и обеспечивают большую эффективность оценок. При анализе временных рядов исследователи часто сталкиваются с мультиколлинеарностью факторов. Например, в рассмотренном выше случае со спросом на сигареты существовала высокая зависимость между ценой и доходом в агрегированных временных рядах для США. Высокая коллинеарность между этими факторами будет менее вероятна при использовании панельных данных по штатам, так как пространственное измерение немного увеличивает вариацию факторов и делает более информативными данные по цене и доходу. Действительно, вариация в данных может быть разложена на две составляющие: вариацию между штатами разных размеров и с различными характеристиками и вариацию внутри штатов, при этом последняя обычно всегда больше. К тому же более информативные данные могут привести к более надежным оценкам параметров. 3. Панельные данные предоставляют возможность изучать динамику изменений индивидуальных характеристик единиц совокупности. Панельные данные хорошо подходят для изучения перемены работы, периода безработицы, изменений в доходах, для исследования длительности пребывания в определенном экономическом состоянии, например, в бедности или в качестве безработного, а также могут помочь изучить скорость приспособления индивидов к изменениям в экономической политике. Так, при измерении безработицы пространственные данные позволяют оценить, какую долю в совокупности составляют безработные в конкретный момент времени; временные данные могут показать, как эта доля менялась во времени; и только панельные данные позволяют оценить, какая доля тех, кто являлся безработным в один период, останется безработным в другой период. |