|
|
Информационные технологии управления. Информационные технологии и информационные системы Информация. Информатика. Микроэлектроника
Классы систем Data Mining - DM
DM - Data Mining - является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории БД и др. (см. рисунок). Отсюда обилие методов, алгоритмов и математических правил, реализованных в различных действующих системах DM , среди них можно выделить:
Регрессионный, дисперсионный и корреляционный анализ
Реализован в большинстве современных статистических пакетов, в частности в продуктах компаний SAS Institute, StatSoft и др.;
Необходимость в фильтрации возникает, когда нужно отделить полезную информацию от искажающего его шума за счет сглаживания, очистки, редактирования аномальных значений, устранения незначащих факторов, понижения размерности информации и т.д. Применение фильтрации в системах анализа данных относится к первичной обработке данных и позволяет повысить качество исходных данных, а, следовательно, и точность результата анализа.
Анализ эмпирических моделей
Анализ эмпирических моделей конкретной предметной области, часто применяемые, например, в недорогих средствах финансового анализа;
Кластерный анализ подразделяет гетерогенные данные на гомогенные или полугомогенные группы для объединения сходных событий в группы на основании сходных значений нескольких полей в наборе данных. Метод позволяет классифицировать наблюдения по ряду общих признаков. Кластеризация расширяет возможности прогнозирования. Кластерные модели (иногда также называемые моделями сегментации) весьма популярны при создании систем прогнозирования
Нейросетевые алгоритмы, идея которых основана на аналогии с функционированием нервной ткани и заключается в том, что исходные параметры рассматриваются как сигналы, преобразующиеся в соответствии с имеющимися связями между «нейронами», а в качестве ответа, являющегося результатом анализа, рассматривается отклик всей сети на исходные данные. Здесь для предсказания значения целевого показателя используется наборы входных переменных, математических функций активации и весовых коэффициентов входных параметров. Нейронные сети реализуют алгоритмы на основе сетей обратного распространения ошибки, самоорганизующихся карт Кохонена, RBF-сетей, сетей Хэмминга и других подобных алгоритмов анализа данных.
Ассоциативные правила выявляют причинно следственные связи и определяют вероятности или коэффициенты достоверности, позволяя делать соответствующие выводы. Примером такого правила служит утверждение, что в том случае, если произошло событие А, то произойдет и событие В с вероятностью C. Их можно использовать для прогнозирования или оценки неизвестных параметров (значений). Впервые это задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
Иерархическая структура, базирующаяся на наборе вопросов, подразумевающих ответ «Да» или «Нет». Позволяют представлять правила в последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение. Под правилом понимается логическая конструкция, представленная в виде "если... то...". Определяют естественные "разбивки" в данных, основанные на целевых переменных. Деревья решений применяются при решении задач поиска оптимальных решенийна основе описанной модели поведения.
Алгоритмы сопоставления/прецедентов
(Memory-based Reasoning, MBR/ Case-Based Reasoning, CBR) — выбор близкого аналога исходных данных из уже имеющихся исторических данных. Эти алгоритмы основаны на обнаружении некоторых аналогий в прошлом, наиболее близких к текущей ситуации, с тем чтобы оценить неизвестное значение или предсказать возможные результаты (последствия)Называются также методом «ближайшего соседа»;
Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора, вычисляющие частоты комбинаций простых логических событий в подгруппах данных;
Этот метод использует итеративный процесс эволюции последовательности поколений моделей, включающий операции отбора, мутации и скрещивания. Генетические алгоритмы применяются при решении задач оптимизации. Эти методы были открыты при изучении эволюции и происхождения видов. Для отбора определенных особей и отклонения других используется "функция приспособленности" (fitness function).
Эволюционное программирование
Поиск и генерация алгоритма, выражающего взаимозависимость данных, на основании изначально заданного алгоритма, модифицируемого в процессе поиска; иногда поиск взаимозависимостей осуществляется среди каких-либо определенных видов функций (например, по линомов).

Каждый из методов имеет свои преимущества и недостатки. Преимущество деревьев решений и ассоциативных правил состоит в их читабельности - они похожи на предложения на естественном языке. Однако при большом количестве факторов данных бывает очень сложно понять смысл такого представления. Недостаток: они не предназначены для широких числовых интервалов. Это связано с тем, что каждое правило или узел в дереве решений представляет одну связь (зависимость, отношение). Чтобы представить зависимости для большого интервала значений потребуется слишком много правил или узлов. Преимущество нейронных сетей в компактном представлении числовых отношений для широкого диапазона значений. А недостаток - в сложности интерпретации.
|
Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора были предложены в середине 60-х годов М.М. Бонгардом для поиска логических закономерностей в данных. С тех пор они продемонстрировали свою эффективность при решении множества задач из самых различных областей.
Эти алгоритмы вычисляют частоты комбинаций простых логических событий в подгруппах данных. Примеры простых логических событий: X = a; X < a; X > a; a < X < b и др., где X — какой либо параметр, “a” и “b” — константы. Ограничением служит длина комбинации простых логических событий (у М. Бон-гарда она была равна 3). На основании анализа вычисленных частот делается заключение о полезности той или иной комбинации для установления ассоциации в данных, для классификации, прогнозирования и пр.
|
Генетические алгоритмы
DM - Data Mining - не основная область применения генетических алгоритмов. Их нужно рассматривать скорее как мощное средство решения разнообразных комбинаторных задач и задач оптимизации. Тем не менее, генетические алгоритмы вошли сейчас в инструментарий методов DM.
Первый шаг при построении генетических алгоритмов — это кодировка исходных логических закономерностей в базе данных, которые именуют хромосомами, а весь набор таких закономерностей называют популяцией хромосом. Далее для реализации концепции отбора вводится способ сопоставления различных хромосом. Популяция обрабатывается с помощью процедур репродукции, изменчивости (мутаций), генетической композиции. Эти процедуры имитируют биологические процессы. Наиболее важные среди них: случайные мутации данных в индивидуальных хромосомах, переходы (кроссинговер) и рекомбинация генетического материала, содержащегося в индивидуальных родительских хромосомах (аналогично гетеросексуальной репродукции), и миграции генов. В ходе работы процедур на каждой стадии эволюции получаются популяции с все более совершенными индивидуумами.
Генетические алгоритмы имеют ряд недостатков. Критерий отбора хромосом и используемые процедуры являются эвристическими и далеко не гарантируют нахождения “лучшего” решения. Как и в реальной жизни, эволюцию может “заклинить” на какой-либо непродуктивной ветви. И, наоборот, можно привести примеры, как два неперспективных родителя, которые будут исключены из эволюции генетическим алгоритмом, оказываются способными произвести высокоэффективного потомка. Это особенно становится заметно при решении высокоразмерных задач со сложными внутренними связями.
|
Деревья решений (decision trees)
Деревья решения являются одним из наиболее популярных подходов к решению задач DM . Они создают иерархическую структуру классифицирующих правил типа "если... то..." (if - then), имеющую вид дерева. Для принятия решения, к какому классу отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид "значение параметра A больше X?". Если ответ положительный, осуществляется переход к правому узлу следующего уровня, если отрицательный — то к левому узлу; затем снова следует вопрос, связанный с соответствующим узлом. Деревья решений не способны находить “лучшие” (наиболее полные и точные) правила в данных. Они реализуют наивный принцип последовательного просмотра признаков и “цепляют” фактически осколки настоящих закономерностей, создавая лишь иллюзию логического вывода.
|
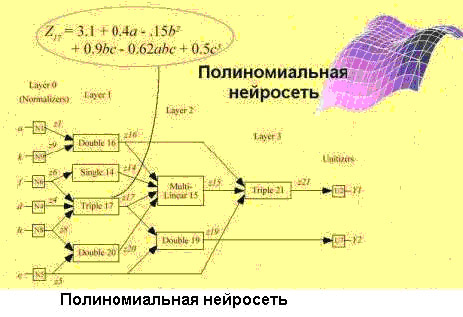
Нейронные сети
Это большой класс систем, архитектура которых имеет аналогию с построением нервной ткани из нейронов. В одной из наиболее распространенных архитектур, многослойном персептроне с обратным распространением ошибки, имитируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д. Эти значения рассматриваются как сигналы, передающиеся в следующий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как ответ — реакция всей сети на введенные значения входных параметров. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо "натренировать" на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам.
Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки. Другой существенный недостаток заключается в том, что даже натренированная нейронная сеть представляет собой черный ящик. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком.
|
Предметно-ориентированные аналитические системы
Предметно-ориентированные аналитические системы очень разнообразны. Наиболее широкий подкласс таких систем, получивший распространение в области исследования финансовых рынков, носит название "технический анализ". Он представляет собой совокупность нескольких десятков методов прогноза динамики цен и выбора оптимальной структуры инвестиционного портфеля, основанных на различных эмпирических моделях динамики рынка. Эти методы часто используют несложный статистический аппарат, но максимально учитывают сложившуюся своей области специфику (профессиональный язык, системы различных индексов и пр.)
|
Системы для визуализации многомерных данных
В той или иной мере средства для графического отображения данных поддерживаются всеми системами DM . Вместе с тем, весьма внушительную долю рынка занимают системы, специализирующиеся исключительно на этой функции. Примером здесь может служить программа DataMiner 3D словацкой фирмы Dimension5 (5-е измерение).
В подобных системах основное внимание сконцентрировано на дружелюбности пользовательского интерфейса, позволяющего ассоциировать с анализируемыми показателями различные параметры диаграммы рассеивания объектов (записей) БД. К таким параметрам относятся цвет, форма, ориентация относительно собственной оси, размеры и другие свойства графических элементов изображения. Кроме того, системы визуализации данных снабжены удобными средствами для масштабирования и вращения изображений. Стоимость систем визуализации может достигать нескольких сотен долларов.
|
Системы рассуждений на основе аналогичных случаев
Case Based Reasoning (CBR)
Идея систем Case Based Reasoning (CBR) на первый взгляд крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Поэтому этот метод еще называют методом "ближайшего соседа" (nearest neighbor). В последнее время распространение получил также термин memory based reasoning, который акцентирует внимание, что решение принимается на основании всей информации, накопленной в памяти.
Главным недостатком CBR считают то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт — в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов CBR системы строят свои ответы. Другой недостаток заключается в произволе, который допускают системы CBR при выборе меры "близости". От этой меры самым решительным образом зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза.
|
Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также элементы DM . Но основное внимание в них уделяется все же классическим методикам — корреляционному, регрессионному, факторному анализу и другим.
Недостатком систем этого класса считают требование к специальной подготовке пользователя. Также отмечают, что мощные современные статистические пакеты являются слишком "тяжеловесными" для массового применения в финансах и бизнесе, к тому же часто эти системы весьма дороги.
Принципиальным недостатком статистических пакетов, ограничивающий их применение в DM , является то, что большинство методов, входящих в состав пакетов опираются на статистическую парадигму, в которой главными фигурантами служат усредненные характеристики выборки. А эти характеристики при исследовании реальных сложных жизненных феноменов часто являются фиктивными величинами.
|
Эволюционное программирование
Cистемы PolyAnalyst
Современное состояние данного подхода лучше всего проиллюстрировать на примере системы PolyAnalyst — российской разработке, получившей сегодня общее признание на рынке DM. В данной системе гипотезы о виде зависимости целевой переменной от других переменных формулируются в виде программ на некотором внутреннем языке программирования. Процесс построения программ строится как эволюция в мире программ (этим подход немного похож на генетические алгоритмы). Когда система находит программу, более или менее удовлетворительно выражающую искомую зависимость, она начинает вносить в нее небольшие модификации и отбирает среди построенных дочерних программ те, которые повышают точность. Таким образом, система "выращивает" несколько генетических линий программ, которые конкурируют между собой в точности выражения искомой зависимости. Специальный модуль системы PolyAnalyst переводит найденные зависимости с внутреннего языка системы на понятный пользователю язык (математические формулы, таблицы и пр.).
Другое направление эволюционного программирования связано с поиском зависимости целевых переменных от остальных в форме функций какого-то определенного вида. Например, в одном из наиболее удачных алгоритмов этого типа — методе группового учета аргументов (МГУА) зависимость ищут в форме полиномов.
| |
|
|
 Скачать 2.04 Mb.
Скачать 2.04 Mb.