|
|
Информационные технологии управления. Информационные технологии и информационные системы Информация. Информатика. Микроэлектроника
Data Mining (DM) - интеллектуальный анализ данных
Data Mining - DM
Data Mining (DM) — это технология поддержки процесса принятия решений, основанная на выявления скрытых закономерностей и систематических взаимосвязей между переменными внутри больших массивов информации, которые затем можно применить к новым совокупностям данных. При этом накопленные сведения автоматически обобщаются до информации, которая может быть охарактеризована как знания. Обнаружение новых знаний можно использовать для повышения эффективности бизнеса.
В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки информационной руды в самых различных областях. Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т.д.) теперь сопровождается регистрацией и записью всех подробностей его деятельности. Многие компании годами накапливают важную бизнес-информацию, надеясь, что она поможет им в принятии решений.
Корпоративная база данных любого современного предприятия обычно содержит набор таблиц, хранящих записи о тех или иных фактах либо объектах (например, о товарах, их продажах, клиентах, счетах). Как правило, каждая запись в подобной таблице описывает какой-то конкретный объект или факт. Например, запись в таблице продаж отражает тот факт, что такой-то товар продан такому-то клиенту тогда-то таким-то менеджером, и по большому счету ничего, кроме этих сведений, не содержит.
Пример.
C помощью средств DM менеджер по маркетингу может предлагать клиентам индивидуальные котировки акций, обновлять новости, проводить специальные кампании по продвижению и передавать другую индивидуальную информацию, которая может их заинтересовать. При этом существенно сокращаются средства на рекламу и повышаются доходы. Кроме того, процесс полностью автоматизирован, ПО моментально обнаруживает любые изменения в поведении клиента, в отличие от специальных сервисов, представленных на сегодняшний день в Web, которые требуют от людей заполнения различных опросных листов и анкет.
Однако совокупность большого количества таких записей, накопленных за несколько лет, может стать источником дополнительной, гораздо более ценной информации, которую нельзя получить на основе одной конкретной записи, а именно — сведений о закономерностях, тенденциях или взаимозависимостях между какими-либо данными.
Пример.
Cведения о том, как зависят продажи определенного товара от дня недели, времени суток или времени года, какие категории покупателей чаще всего приобретают тот или иной товар, какая категория клиентов чаще всего вовремя не отдает предоставленный кредит, какая часть покупателей одного конкретного товара приобретает другой конкретный товар.
Подобного рода информация обычно используется при прогнозировании, стратегическом планировании, анализе рисков, и ценность ее для предприятия очень высока, поэтому процесс ее поиска и получил название Data Mining (mining по-английски означает «добыча полезных ископаемых», а поиск закономерностей в огромном наборе фактических данных действительно сродни этому).
Синонимами DM можно считать следующее.
Синонимы Data Mining - DM
Обнаружение знаний в БД (Knowledge Discovery In Databases, KDD)
Это процесс поиска полезных знаний в "сырых" данных. KDD включает в себя вопросы подготовки данных, выбора информативных признаков, очистки данных, применения методов DM, а также обработки и интерпретации полученных результатов
Интеллектуальный анализ данных (IAD)
Концепция интеллектуального анализа данных определяет задачи поиска функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов.
Термин Data Mining
Термин Data Mining обозначает не столько конкретную технологию, сколько сам процесс поиска корреляций, тенденций, взаимосвязей и закономерностей посредством различных математических и статистических алгоритмов: кластеризации, создания субвыборок, регрессионного и корреляционного анализа. Цель этого поиска — представить данные в виде, четко отражающем бизнес-процессы, а также построить модель, при помощи которой можно прогнозировать процессы, критичные для планирования бизнеса (например, динамику спроса на те или иные товары или услуги либо зависимость их приобретения от каких-то характеристик потребителя).
Пример.
Анализ потребительской корзины, применяемый, чтобы выявить предпочтения потребителей и, соответственно, лучше удовлетворить спрос и повысить доход с клиентов. Однако характер покупательского поведения присутствует в данных неявно, и для его определения необходимо использовать именно Data Mining. И теперь можно выяснить, к примеру, что клиент, собирающийся купить товар X, будет не прочь приобрести заодно и товар Y. Эта информация ляжет в основу последующих решений: может быть, стоит располагать эти товары на витрин е магазин а рядом или, например, продвигать один из них, чтобы повысить продаж и обоих.
В отличие от оперативной аналитической обработки данных (OLAP) в DM задача формулировки гипотез и выявления необычных (unexpected) алгоритмов переложено с человека на компьютер. Если при статистическом анализе или при применении OLAP обычно формулируются вопросы типа «Каково среднее число неоплаченных счетов заказчиками данной услуги?», то применение DM , как правило, то подразумевает ответы на вопросы типа «Существует ли типичная категория клиентов, не оплачивающих счета?». При этом именно ответ на второй вопрос нередко обеспечивает более нетривиальный подход к маркетинговой политике и к организации работы с клиентами.
Примеры заданий на такой поиск при использовании DM - Data Mining приведены в таблице.
Примеры формулировок задач при использовании методов OLAP и DM - Data Mining
OLAP
|
DM - Data Mining
|
Каковы средние показатели травматизма для курящих и некурящих?
|
Встречаются ли точные шаблоны в описаниях людей, подверженных повышенному травматизму?
|
Каковы средние размеры телефонных счетов существующих клиентов в сравнении со счетами бывших клиентов (отказавшихся от услуг телефонной компании)?
|
Имеются ли характерные портреты клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании?
|
Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке?
|
Существуют ли стереотипные схемы покупок для случаев мошенничества с кредитными карточками?
|
Важное положение DM - Data Mining
Важное положение DM — нетривиальность (нестандартность и неочевидность) разыскиваемых алгоритмов (шаблонов). Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (unexpected) регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge). Иными словами, средства DM отличаются от инструментов статистической обработки данных и средств OLAP тем, что вместо проверки заранее предполагаемых пользователями взаимозависимостей они на основании имеющихся данных способны находить такие взаимозависимости самостоятельно и строить гипотезы об их характере.
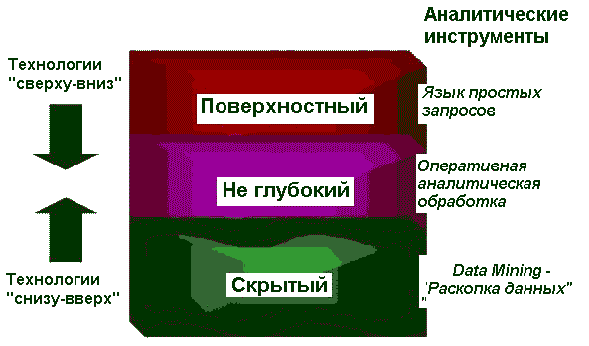
Применение DM - Data Mining
Следует отметить, что применение средств DM не исключает использования статистических инструментов и OLAP-средств, поскольку результаты обработки данных с помощью последних, как правило, способствуют лучшему пониманию характера закономерностей, которые следует искать.
Применение DM оправданно при наличии достаточно большого количества данных, в идеале — содержащихся в корректно спроектированном ХД (собственно, сами ХД обычно создаются для решения задач анализа и прогнозирования, связанных с поддержкой принятия решений). Данные в хранилище представляют собой пополняемый набор, единый для всего предприятия и позволяющий восстановить картину его деятельности на любой момент времени, а структура данных хранилища проектируется таким образом, чтобы выполнение запросов к нему осуществлялось максимально эффективно. Впрочем, существуют средства DM , способные выполнять поиск закономерностей, корреляций и тенденций не только в хранилищах данных, но и в OLAP-кубах, то есть в наборах предварительно обработанных статистических данных.
Эксперты считают, что в ближайшее десятилетие DM станет одним из перспективных направлений разработки ПО. За счет выявления содержательной структуры в собранной информации и ее анализа в режиме реального времени данная технология станет ключевым методом разработки «индивидуальной Сети», приспособленной под конкретные нужды каждого пользователя.
|
Технологии, используемые в Data Mining и типы закономерностей
В данном разделе будут рассмотрены вопросы:
Классификация
Типы закономерностей
|
Классификация
Методы DM по применяемому типу анализа можно подразделить на две группы.
Группы методов DM - Data Mining
Cегментация (обнаружение)
Подразумевает анализ существующих данных с целью обнаружения некоторых групп. Основана только на параметрах клиентов, алгоритмы кластеризации позволяют выявить гомогенные группы или типы клиентов. Для этих групп можно определить присущий им тип клиентов. В результате, удается лучше оценить свою клиентскую базу и планировать более эффективные маркетинговые мероприятия.
Прогнозирование требует некоторой выборки данных для того отношения, которое нужно прогнозировать или моделировать. К наиболее распространенным методам моделирования относятся регрессия, нейронные сети и деревья решений. Например, используя демографические показатели и покупательские характеристики за прошлые периоды, модель может сгенерировать некоторый балл для каждого потенциального клиента. Этот балл покажет, какова вероятность того, что данный заказчик вновь сделает покупку. Такие баллы используются для ранжирования клиентов при осуществлении целевых маркетинговых программ. Кроме того, можно выявить повторяющиеся и разовые покупки или предсказать отказ прежних клиентов от услуг. Анализ чувствительности позволяет выявить те характеристики клиентов, которые в наибольшей степени влияют на прогнозируемый фактор.
Инструменты DM можно классифицировать по применяемым технологиям.
Классификация DM - Data Mining - по применяемым технологиям:
(Визуальное представление информации). Качество визуализации определяется возможностями графического отображения значений данных. Варьирование графического представления путем изменения цветов, форм и других элементов упрощает выявление скрытых зависимостей. Визуализация используется для поиска исключений, общих тенденций и зависимостей и помогает в извлечении данных на начальном этапе проекта.
Эффективность методов машинного обучения в основном определяется их способностью исследовать большее количество взаимосвязей данных, чем может человек. Машинное обучение используется позднее для поиска зависимостей в уже отлаженном проекте. Машинное обучение предполагает использование различных методов, например:
Деревья решений предназначены для классификации данных, они используют весовые коэффициенты для распределения элементов данных на всё более и более мелкие группы;
Метод ассоциативных правил классифицирует данные на основе набора правил, подобных правилам в экспертных системах. Эти правила можно генерировать, используя процесс поиска и проверки комбинаций правил, или извлекать правила из деревьев решений;
Генетических алгоритмов
Нейронных сетей
Знания представлены в виде связей, соединяющих набор узлов. Сила связей определяет зависимости между факторами данных.
|
Типы закономерностей
Выделяют пять стандартных типов закономерностей (алгоритмов), выявляемых методами DM.
Типы алгоритмов, выявляемых методами DM - Data Mining:
Имеет место в том случае, если несколько событий с высокой вероятностью связаны друг с другом (например, один товар часто приобретается вместе с другим).
Пример.
Исследование, проведенное в супермаркете, может показать, что 65% купивших кукурузные чипсы берут также и "кока-колу", а при наличии скидки за такой комплект "колу" приобретают в 85% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Высокая вероятность цепочки связанных во времени событий (например, в течение определенного срока после приобретения одного товара будет с высокой степенью вероятности приобретен другой.
Пример.
После покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
Выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект или событие. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства DM самостоятельно выделяют различные однородные группы данных.
Наличие шаблонов в динамике поведения тех или иных данных (типичный пример — сезонные колебания спроса на те или иные товары либо услуги), используемых для прогнозирования . Именно историческая информация, хранящаяся в БД в виде временных рядов, служит основой для всевозможных систем. Если удается найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
| |
|
|
 Скачать 2.04 Mb.
Скачать 2.04 Mb.