Количественные методы в источниковедении - Шендерюк М.Г.. Количественные методы в источниковедении
 Скачать 1.67 Mb. Скачать 1.67 Mb.
|

|
Раздел 3. ИСТОЧНИКОВЕДЧЕСКИЕ ЗАДАЧИ 3.1. Компьютерное источниковедение В клиометрических исследованиях трудно отделить этап исторического построения от собственно источниковедческого анализа, поскольку все они нацелены на решение конкретных исторических проблем путем освоения новых комплексов массовых источников или извлечения из источника новой, скрытой, информации, т.е. так или иначе носят источниковедческий характер. В связи с этим в центре внимания клиометристов всегда стояли задачи адекватной формализации и репрезентации информации источника, создания баз данных, учитывающих специфику исторических источников. «Микрокомпьютерная революция» конца 80-х – начала 90-х годов привела к тому, что из квантитативной истории выделилось особое направление, ориентированное на компьютерные технологии анализа исторических источников, - историческая информатика. Предмет и содержание новой дисциплины определены в первом в нашей стране учебнике по исторической информатике, созданном сотрудниками лаборатории исторической информатики им. академика И.Д. Ковальченко кафедры источниковедения Московского государственного университета им. М.В. Ломоносова14. Историческая информатика – это научная дисциплина, изучающая закономерности процесса информатизации исторической науки и образования; в основе исторической информатики лежит совокупность теоретических и прикладных знаний, необходимых для создания и использования в исследовательской практике машиночитаемых версий исторических источников всех видов. Теоретической основой исторической информатики является современная концепция информации (включая социальную информацию) и теоретическое источниковедение, а прикладной – информационные (компьютерные) технологии. Область интересов исторической информатики включает разработку общих подходов к применению информационных технологий в исторических исследованиях (в том числе – специализированного программного обеспечения); создание исторических баз и банков данных/знаний; применение информационных технологий представления данных и анализа структурированных, текстовых, изобразительных и др. источников; компьютерное моделирование исторических процессов; использование информационных сетей (Internet и др.); развитие и применение мультимедиа и других новых направлений информатизации исторической науки; а также применение информационных технологий в историческом образовании. Новые информационные технологии позволяют реализовывать источнико-ориентированный и проблемно-ориентированный подходы в исследовании, поэтому органическими составляющими исторической информатики являются «источниковедческая» (компьютерное источниковедение) и «аналитическая» компоненты. Обратимся к проблемам компьютерного источниковедения. Компьютерное источниковедение – это совокупность методов и технологий создания машиночитаемых исторических источников. Машиночитаемые источники – это источники, переведенные в «электронную» форму. Однако, поскольку в машиночитаемую часть переводится только часть информации, потенциально содержащейся в источнике, то более корректным и часто употребляемым является термин «машиночитаемые данные» (МЧД). Вместе с тем машиночитаемые версии источников могут рассматриваться и как новые источники – машиночитаемые источники. Создание и использование машиночитаемых данных началось в квантитативной истории еще в эпоху больших ЭВМ, когда исследователи не преследовали цель полного перевода источников в машиночитаемую форму и МЧД являлись не только информационной базой, но и результатом исследования. Крупные университеты и исследовательские центры стали коллекционировать машиночитаемые данные. Рост их числа привел к необходимости создания банков и архивов МЧД. С другой стороны, уже с 60-х годов официальные учреждения во многих странах стали производить машиночитаемую информацию, а к 80-м годам в США и Западной Европе около 80% правительственной документации создавалось в машиночитаемой форме. Машиночитаемые данные появились во многих архивах, библиотеках и музеях. Актуальными в связи с этим стали задачи разработки и совершенствования приемов создания и использования коллекций машиночитаемых данных. Микрокомпьютерная революция 80-х гг. открыла для решения этих задач новые перспективы. Современные компьютерные технологии позволяют создавать машиночитаемые копии источников, максимально приближенные к оригиналу. Это расширяет возможности обработки и анализа данных источников, проведения историко-сравнительных исследований, обращения к архивам данных, созданным другими исследователями. Коллекции машиночитаемых данных получили название баз данных. В широком смысле база данных – это массив данных, хранимый в вычислительной системе. Однако не всякий информационный массив является базой данных в строгом смысле этого понятия, поскольку согласно технологии баз данных организация информации в базе данных должна быть подчинена определенным требованиям. Более корректным в этой связи является следующее определение базы данных15: База данных – это совокупность структурированных взаимосвязанных данных при такой минимальной избыточности, которая допускает их использование для различных приложений в определенной предметной области. Стандартные требования к организации базы данных: - Интегрированность (централизованное хранение информации). Неинтегрированные базы данных по одной и той же проблеме (созданные, например, в разное время и с разными целями) почти неизбежно обладают избыточностью и не являются непротиворечивыми. - Взаимосвязанность и структурированность, отражающие существенные свойства объектов реального мира. - Независимость описания данных от прикладных программ (логическая и физическая независимость), т.е. изменения, касающиеся логической структуры данных, не должны влиять на их расположение в памяти системы. В современной технологии баз данных эти задачи решаются централизованно с помощью систем управления базами данных (СУБД). Главная роль СУБД состоит в обеспечении пользователя необходимыми инструментальными средствами описания данных и средствами манипулирования данными как на логическом, так и на физическом уровне, а также в обеспечении защиты данных (от несанкционированного доступа, от разрушения при сбоях оборудования) и их целостности (непротиворечивости). Проблемы проектирования и работы с базами данных рассматриваются в специальной литературе. Помимо названного учебника по исторической информатике, основные принципы и концепции создания баз данных и их специфика для исторических исследований излагаются в монографии И.М.Гарсковой16. Информационные системы на больших ЭВМ, построенные с использованием технологии баз данных, получили название банков данных. Банк данных – это система информационных, математических, программных, языковых, организационных и технических средств, предназначенных для централизованного накопления и коллективного многоаспектного использования данных для получения необходимой информации. Основными компонентами банка данных как информационной системы являются (см. рис. 5)17: 1) база данных (БД); 2) система управления базой данных (СУБД); 3) администратор базы данных (АБД); 4) словарь-каталог данных; 5) вычислительная система; 6) обслуживающий персонал. 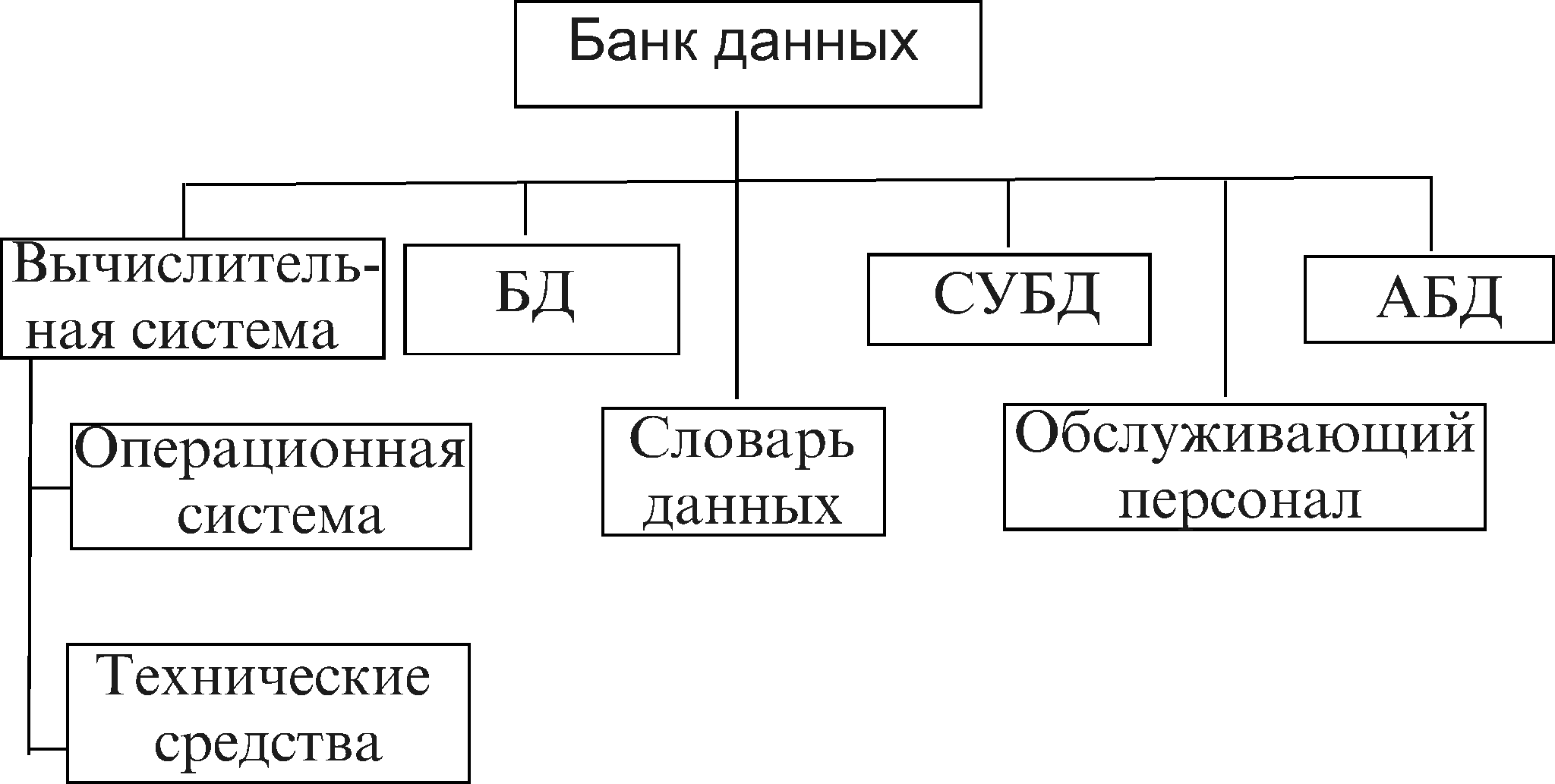 Рис. 5. Основные компоненты банка данных Как уже отмечалось, появление и использование машиночитаемых данных привели к созданию во многих странах банков и архивов МЧД по различным гуманитарным исследованиям, а в последние годы возникли и специализированные архивы машиночитаемых исторических данных. Перечень архивов и банков данных, которые могут представлять интерес для историка, приводится в таблице 318. Наиболее значительную коллекцию машиночитаемых данных в области социальных наук имеет крупнейший архив – Межуниверситетский Консорциум по политическим и социальным исследованиям (ICPSR) в Анн-Арборе (Мичиган, США), основанный в 1962 г. как сообщество Исследовательского Центра Мичиганского университета и 21 других университетов США. Сейчас в ICPSR входит более 350 колледжей, университетов и архивов, в том числе более 20 иностранных членов (архивов и университетов). В нашей стране процесс создания банков и архивов машиночитаемых исторических данных находится на начальном этапе. Первые базы данных на материалах исторических источников в строгом понимании этого термина появились в начале 90-х гг. В это же время был создан Консорциум Таблица 3 Банки данных и архивы МЧД, представляющие интерес для историка
по базам данных в отечественной истории, который в 1992 г. преобразован в Банк машиночитаемых данных по истории России. И.М.Гарскова в своей монографии приводит описания некоторых коллекций МЧД, уже заявленных разработчиками19. Среди них, например, описываются реляционная база данных по аграрной истории России первой половины XVII в., созданная по материалам писцовых книг; просопографическая база данных по депутатам I Государственной Думы, составленная на основе справочных печатных изданий, посвященных депутатскому корпусу первой Думы, и др. Информационные системы на больших ЭВМ создавались и обслуживались большим числом лиц. С внедрением в исследовательскую практику персональных компьютеров часто одно и то же лицо становится и разработчиком, и пользователем, и администратором, и программистом, а сам банк данных состоит лишь из двух компонент: БД и СУБД, т.е. из базы данных в соответствующей системе управления базой данных. Такие банки данных стали называться персональными. Вопросы проектирования баз данных требуют отдельного рассмотрения, поэтому коснемся лишь сюжетов построения баз данных, связанных со спецификой разных исторических источников. Определяющее значение для перевода источников в машиночитаемую форму имеет уровень их структурированности, в соответствии с этим источники можно разделить на статистические, структурированные, текстовые (нарративные) и графические. Статистические источники представляют собой таблицы статистических показателей (количественных данных), собранных по всем объектам некоторой совокупности (хозяйствам, губерниям, отраслям промышленности, группам населения и т.п.). Важными свойствами статистических источников являются массовый характер первичных сведений и агрегирование первичной информации. Статистические данные обычно являются либо первичными, либо агрегированными. Структура организации данных на основе первичных данных статистических источников (на микроуровне) представляет собой обычную таблицу «объекты – признаки». Структура на макроуровне (на основе агрегированных данных) – это сложные многомерные группировки по иерархическому принципу или принципу таблиц сопряженности на основе некоторых критериев (тематических, пространственных или хронологических). Формулярные источники, совсем недавно получившие название структурированных (highly structured historical sources), изначально имеют четкую структуру (формуляр), что делает их наиболее удобными для перевода в машиночитаемый вид. К структурированным источникам относятся материалы переписей, книг церковной или гражданской регистрации рождения, крещения, брака и смерти, личные дела и личные карточки, анкеты, справочники. Основными особенностями этих источников являются отсутствие агрегированной информации и соединение разнотипной информации (текстовой, числовой, логической) в одном формуляре. Формуляр источника часто представляет собой практически готовую структуру базы данных (надо только описать атрибуты объектов). Текстовые (нарративные) источники являются наиболее трудными для формализации и перевода в машиночитаемую форму. Основная особенность этих источников - отражение в них структуры естественного языка. Хотя в тексте может присутствовать и формальная структура (разделы, параграфы, абзацы и т.п.), степень формализации текстовых источников невысока. Текст можно хранить в полном виде как линейную последовательность символов или в формализованном виде (с некоторой потерей информации), в последнем случае необходимо внести в текст специальные коды, поместить в нем нужные смысловые единицы. Наконец, в последнее время создаются базы данных, содержащие, наряду с описательной, графическую информацию. Графическую информацию в исторических исследованиях представляют изобразительные источники, фотодокументы, географические карты и др. Однако и обычные тексты (особенно это касается средневековых текстов) могут быть представлены в виде графических изображений, если их вводить с помощью устройства оптического ввода – сканера. Итак, при построении баз данных необходимо учитывать особенности структуры исторических источников, на основе которых они создаются. При этом исследователь, имеющий дело с менее структурированным источником, может не только вводить в память компьютера полный его текст, но и формировать некоторые структуры, внешние по отношению к тексту, которые позволяют извлекать из этого текста новую информацию в соответствии с задачами исследования. Таким образом, современные компьютерные технологии создания баз и банков машиночитаемых данных открывают новые перспективы для исторических исследований, не только расширяя круг источников (как первичных, так и производных, ранее не существовавших), но и совершенствуя методический инструментарий историка. Рассмотрим теперь, как с помощью количественных методов решаются задачи классического источниковедения. 3.2. Изучение происхождения источника Многие древние памятники дошли до нас в десятках списков и редакций, поэтому их источниковедческий анализ предполагает прежде всего установление взаимоотношений редакций и списков, выявление генетической связи всех сохранившихся и утраченных текстов памятника и воссоздание истории текстов. Эти задачи решаются путем довольно сложного сравнительно-текстологического анализа, облегчить который можно с помощью компьютерного построения классификации списков. Рассмотрим, как применяются количественные методы и компьютер в изучении происхождения нарративных источников на ставшем классическим примере построения «генеалогического древа» (стеммы) древнейшего юридического памятника славянского права IX века – «Закона Судного Людем»20. В основе построения классификации лежит метод «групп», предложенный французским текстологом Д.Ж. Фроже. Главная идея метода заключается в следующем: если списки-«потомки» приобретают все особенности списков-«предков», то история копирования списков вполне определенным образом зашифрована в разночтениях списков. Тогда на основе анализа структуры разночтений можно построить генеалогическое древо списков. Метод «групп» имеет довольно жесткие условия: 1) у каждого списка имеется только один протограф; 2) в каждом списке содержатся все ошибки его протографа; 3) одинаковые ошибки не содержатся в списках, имеющих в качестве своих протографов независимые списки. Логическая схема метода «групп» легко формализуема с помощью языка теории множеств и теории графов. Однако модель Фроже упрощает реальный процесс копирования списков, что значительно сужает круг источников, к которым данный метод можно применить. В качестве предмета исследования Л.В.Милов и Л.И.Бородкин выбрали один из древнейших памятников славянской юридической мысли «Закон Судный Людем» (ЗСЛ), исходя из того, что характер этого произведения (свод законов) налагает жесткие ограничения на процесс копирования, приближая его к модельному. ЗСЛ – раннехристианский юридический памятник, созданный в 60-х годах IX в. одним из славянских просветителей Кириллом-Константином в пределах Велико-Моравского княжества. Позже ЗСЛ нашел практическое применение в Болгарии конца IX – начала X века. Однако тексты этого памятника сохранились только на Руси в составе древнерусских юридических сборников XIII – XVII вв. Для анализа использовалось академическое издание краткой редакции ЗСЛ, содержащее 54 списка 4-х изводов. Поскольку применение метода «групп» требует сличения всех списков с некоторым исходным экземпляром – «экземпляром ссылок», то в качестве исходного был взят наиболее древний датированный список – список ЗСЛ из Новгородской кормчей 1280 г. Все разночтения текста, полученные при сличении всех списков с «экземпляром ссылок», были закодированы и составили более 15 тысяч вариантов разночтений. Этот материал и послужил исходной информацией для реализации метода «групп». В процессе компьютерной обработки информации выявились некоторые противоречия между реальной структурой вариантов разночтений и требованиями модели, которые были ликвидированы в результате экспертной оценки специалиста-историка. В целом анализ характера противоречий позволил сделать вывод о том, что реальный процесс копирования списков ЗСЛ можно описать моделью метода «групп». 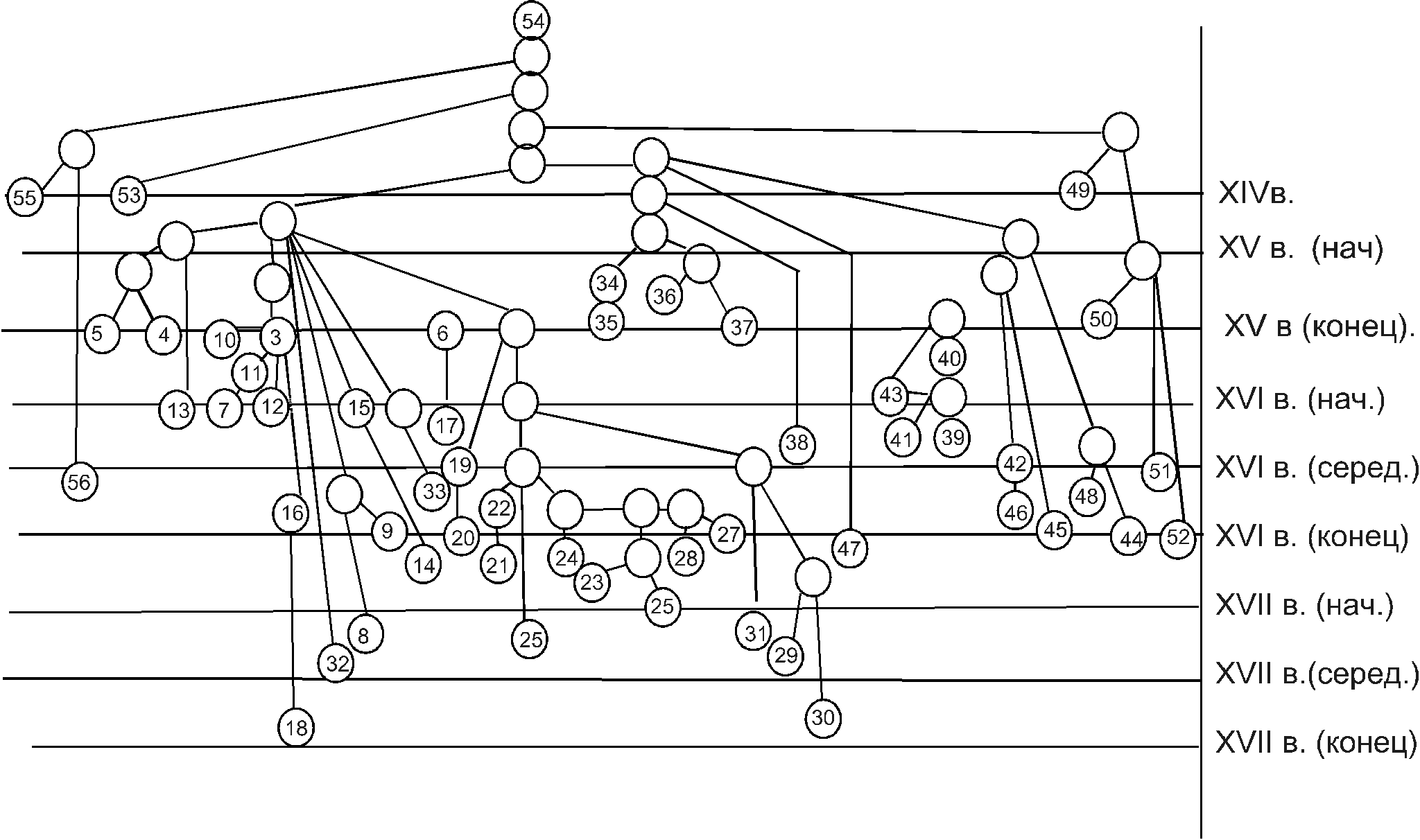 |