Количественные методы в источниковедении - Шендерюк М.Г.. Количественные методы в источниковедении
 Скачать 1.67 Mb. Скачать 1.67 Mb.
|

Рис. 6. Стемма «Закона Судного Людем»Итогом работы стало построение генеалогического древа – стеммы (рис. 6), отражающей историю текста ЗСЛ и дающей новую, принципиально важную информацию. Каждый из четырех изводов выделился на стемме в отдельное «прадерево», т.е. все списки каждого извода имеют одного общего «предка», при этом изводы не пересекаются. Интересным результатом, подтверждающим корректность проведенной классификации, стало то, что построенная стемма не содержит хронологических противоречий: все сохранившиеся списки выстроились в цепях генеалогического древа точно по фактической хронологии, хотя сведения о дате списков в компьютер не вводились (названия нумерованных списков памятника даны в таблице 4). Кроме того, компьютер «реконструировал» большое число несохранившихся списков (на стемме они обозначены пустыми кружочками). По отношению к известным 54 спискам они составляют примерно 60% (31 реконструкция). При этом каждая реконструкция поставлена на определенное место в генеалогии списков, что позволяет судить о том, что было, казалось, навсегда утрачено. ЗСЛ краткой, т.е. древнейшей, редакции сохранился в большинстве списков в одних и тех же юридических сборниках с Русской Правдой – «Кормчих книгах». Из всех списков только в Устюжской Кормчей, Иосифовской Кормчей и Варсонофьевской Кормчей нет текста Русской Правды. При этом соседство в книгах является не просто механическим. Как доказал М.Н.Тихомиров, тексты каждой из кормчих книг носят следы единой редакции, поэтому можно предположить, что генеалогии списков Русской Правды и ЗСЛ будут совпадать. Историками проведено фундаментальное текстологическое исследование ста с лишним списков Русской Правды Пространной редакции. Вся совокупность списков типологически была разделена на три вида: 1) Синодально-Троицкий вид, списки которого сохранились в составе Кормчих книг и Мерил Праведных; 2) Пушкинско-Археографический вид, списки которого сохранились в юридических сборниках особого состава; 3) Карамзинский вид, списки которого сохранились в позднейших сборниках XV-XVI вв. В свою очередь виды подразделяются на изводы. Так, Синодально-Троицкий вид делится на Чудовский извод (или Розенкампфовский), Софийский извод (или Новгородско-Софийский), Ферапонтовский извод, извод Мерила Праведного и т.д. Таким образом, если классификация списков Русской Правды Синодально-Троицкого вида, проведенная историками-текстологами традиционными методами, совпадает со стеммой, созданной исследователями с помощью компьютера на основе метода «групп», тогда можно говорить о корректности и эффективности компьютерной классификации. Таблица 4 Перечень списков «Закона Судного Людем»
Окончание табл. 4
Сопоставление стеммы с классификацией списков Пространной Русской Правды, данной в академическом издании текстов Русской Правды, показало их полное совпадение. Основные группы ветвей генеалогического древа по составу списков оказались идентичны группам, составленным учеными «вручную». Кроме того, Л.И.Бородкину и Л.В.Милову удалось решить ряд спорных вопросов21. Так, один из изводов Русской Правды В.П.Любимов назвал Розенкампфовским по Розенкампфовскому списку, а М.Н.Тихомиров считал, что наиболее важным для всего извода является Чудовский список. Стемма показала, что в основании извода лежит именно Чудовский список и извод должен называться Чудовским. Стемма внесла существенные коррективы в оценку целой ветви списков ЗСЛ (и Русской Правды) – Ферапонтовского извода. В.П.Любимов полагал, что этот извод очень позднего происхождения и является скорее свидетельством того, что Русская Правда была уже в XVI-XVII вв. литературным памятником, а не правовым кодексом. Итоги компьютерной классификации показали весьма древнее происхождение Ферапонтовского извода, сформировавшегося ранее Чудовского извода и являвшегося действующим источником права. Вместе с тем стало ясно, что до наших дней дошли лишь «обломки» извода, его самые позднейшие списки, а его костяк составляли несохранившиеся, но высчитанные компьютером протографы. Как уже отмечалось, в качестве «экземпляра ссылок» исследователями был выбран древнейший список Новгородской кормчей 1280 г. Однако после построения стеммы возникает задача более правильного выбора исходного протографа – переориентации «корня» генеалогического древа на основе экспертной работы историка, при этом соотношения списков в стемме меняться не будут. После содержательного анализа в качестве исходного протографа был выбран несохранившийся список, от которого ведут начало два списка (Устюжский и Иоасафовский), находящиеся в кормчих книгах Устюжского типа. При этом Устюжская кормчая, кроме ЗСЛ, содержит текст «Номоканона 50 титулов» византийского юриста Иоанна Схоластика в древнейшем славянском переводе, предпринятом, по мнению многих ученых, Мефодием в период его жизни в Моравии в 60-80-х годах IX в. Соседство этих двух памятников IX в. позволило исследователям предположить, что Устюжская кормчая ведет к древнейшему сборнику Кирилло-Мефодиевской эпохи, откуда и проник на Русь Закон Судный Людем. Таким образом, построенное генеалогическое древо списков ЗСЛ имеет большое значение для исследования происхождения не только текста ЗСЛ, но и многих текстов, входящих в состав Кормчих книг и Мерил Праведных. Прежде всего, компьютерная классификация дает принципиально новые возможности для изучения истории происхождения Пространной Русской Правды. 3.3. Атрибуция источника Наряду с изучением происхождения нарративных источников важной источниковедческой задачей является их атрибуция. Установление авторства нарративных текстов является одной из самых сложных проблем в отечественном источниковедении. Связано это с тем, что до XVII в. включительно в большинстве своем литературные и исторические произведения были анонимны. Открытое объявление имени считалось нескромным и даже греховным. При этом анонимность выражается не только и не столько в отсутствии авторской подписи, сколько в слабости авторского начала, что отражает специфику средневекового литературного произведения. Во-первых, органическую часть средневекового памятника составляют многочисленные цитирования текстов религиозно-философского, литературно-религиозного и церковно-канонического содержания, лишающие текст его индивидуальных черт. Во-вторых, в силу существования так называемого «литературного этикета» литературные произведения разных жанров написаны согласно канонизированным жанровым и стилистическим приемам по определенному формуляру, т.е. личное начало поглощено традиционными книжными приемами. Наконец, средневековый авторский текст необычайно подвижен и изменчив, поскольку целые поколения русских книжников: авторов, редакторов и писцов традиционно вмешивались в текст, становясь практически его соавторами. Все это приводит к значительным трудностям атрибуции нарративных текстов традиционными методами. Сложность определения авторского стиля средневекового памятника объясняет тот факт, что многие десятилетия вопросы атрибуции того или иного произведения являются в историографии либо спорными, либо не до конца решенными. К числу дискутирумых проблем относятся споры об авторе «Повести временных лет», о подлинности «Слова о полку Игореве», о принадлежности публицистических сочинений Ивана Пересветова перу Ивана Грозного и др. Новые перспективы в решении спорных проблем атрибуции нарративных источников открылись с внедрением в исследовательскую практику количественных методов. Более двух десятилетий группа исследователей под руководством члена-корреспондента РАН, профессора Л.В.Милова ведет работу по атрибуции повествовательных (прежде всего древнерусских) текстов X-XVIII вв. на основе новой методики формализации авторского стиля. Итоги многолетних исследований нашли отражение в фундаментальной коллективной монографии22. Традиционно выявление авторских особенностей осуществляется путем выявления деталей стиля, присущих тому или иному автору (излюбленных слов, оборотов и выражений), которые являются субъективно-осознанными или субъективно признанными существенными для стиля автора. Однако такая методика часто оказывается малоэффективной, поскольку лексика автора может диктоваться жанром или автор может подражать авторитету. Более полезным для атрибуции оказывается учет подсознательных особенностей стиля автора. Подсознательные особенности письменного языка какого-либо автора выражаются в специфике употребления и чередования им различных грамматических форм (существительных, прилагательных, глаголов и т.п.) безотносительно к их лексическому содержанию. Предложенная исследователями методика заключается в формализации конкретного авторского текста путем перевода его в систему грамматических форм (классов) и применении к формализованному таким образом тексту метода анализа парных встречаемостей грамматических классовслов. Система грамматических классов слов включает 150 наименований (кодов) модификаций частей речи русского языка, которая применяется в двух вариантах: а) с учетом всех грамматических классов слов, т.е. всех 150 кодов – первая система кодирования; б) с учетом лишь знаменательных слов, т.е. без союзов, предлогов и частиц – вторая система кодирования, включающая 135 кодов. Суть метода анализа парных встречаемостей грамматических классов слов заключается в следующем. 1. Выявляются частоты парных встречаемостей тех или иных грамматических классов (форм) в авторском тексте из 1000 значимых слов (размер выборки в 1000 слов установлен экспериментально). При этом частоты парных встречаемостей у различных авторов будут различаться. Исключение составляют откровенные подражания и «плагиаты», но и в этих случаях обнаруживается минимум индивидуальных особенностей. 2. На основе лишь связи «слева - направо», т.е. в направлении развертывания текста, строится матрица частот парной встречаемости (статистических связей) и задается порог частоты встречаемости. 3. Полученная система статистических связей грамматических классов формализуется на языке теории графов построением графа сильных связей. Граф состоит из вершин и дуг, где вершина – это грамматический класс, а дуга – сильная связь (не ниже заданного порога). Анализ графа дает представление о стилевых особенностях автора. Рассмотрим пример построения графа сильных связей по условной матрице парных встречаемостей (рис. 7)23. На матрице отражены частоты встречаемостей в тексте шести грамматических классов (1 – существительное, 2 – глагол, 3 – наречие, 4 – прилагательное, 5 – причастие, 6 – предлог). Возьмем порог встречаемости не ниже 6. На матрице видно, что частота 6 и больше встречается у пар в первой строке – 1:4 (8) и 1:5 (12); во второй строке – 2:6 (7); в третьей строке – 3:1 (8) и 3:4 (9); в четвертой строке – 4:4 (6) и 4:6 (6); в пятой строке - сильных связей нет; в шестой строке – 6:2 (6) и 6:3 (7). В соответствии с этим строятся вершины 1-6 классов, а дуги обозначают направления сильных связей. В построенном графе вершины несут разную «нагрузку» по числу дуг. Вершины с числом дуг не меньше трех называются узлами.
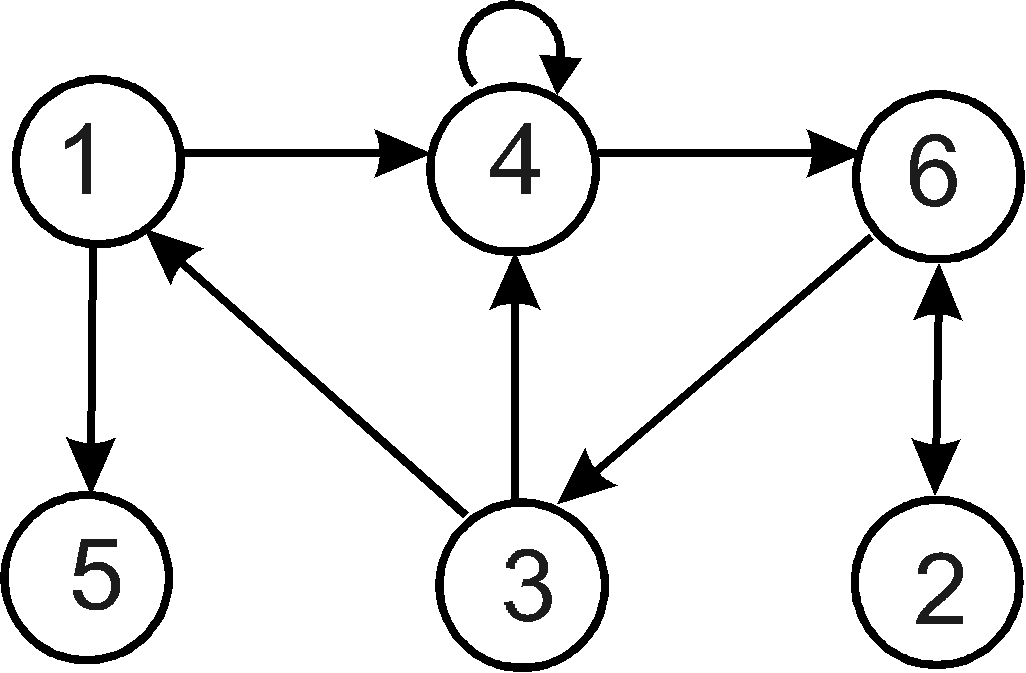 Рис. 7. Условные матрица и граф Обратимся теперь к конкретным результатам атрибуции древних текстов на основе метода анализа парных встречаемостей грамматических классов слов. Одной из наиболее интересных источниковедческих проблем, обсуждаемых в литературе уже два столетия, является проблема авторства «Повести временных лет» (ПВЛ). Хотя в историографии преобладала точка зрения о создании этого памятника монахом Киево-Печерского монастыря Нестором, против нее всегда выдвигались аргументы, основанные на анализе значительных расхождений между летописью и житийными произведениями, принадлежащими перу Нестора. Сопоставление текстов житийных произведений с некоторыми летописными статьями «Повести временных лет» (рассказами о Киево-Печерском монастыре и о гибели Бориса и Глеба, помещенными под 1051, 1074 гг. и 1015 г.) на основе новой методики позволило Л.В.Милову сделать ряд принципиально важных выводов24. Графы текстов бесспорно несторовских произведений («Жития Феодосия» и «Чтения о Борисе и Глебе») оказались достаточно схожи по структуре не только друг с другом, но и с графами Печерской повести 1051, 1074 гг. и летописной статьи 1015 г. Сильное сходство графов «Чтения о Борисе и Глебе» и «Жития Феодосия», с одной стороны, и Печерской повести, с другой - подтверждают и построенные исследователем общие графы (рис. 8-9).  Рис. 8. Общий граф «Чтения о Борисе и Глебе» и Печерской повести Общий граф «Чтения о Борисе и Глебе» и Печерской повести (рис. 8) имеет 21 связь, а коэффициент близости очень высок (0,38), что свойственно текстам одного автора. Общий граф «Жития Феодосия» и Печерской повести (рис. 9) также имеет 21 связь. Коэффициент близости равен 0,32, что тоже свидетельствует о том, что автором обоих текстов являлось одно лицо. В качестве контрастного примера Л.В.Милов приводит общий граф Печерской повести и «Сказания о Борисе и Глебе» - произведения той же эпохи и того же жанра, но бесспорно признанного другого авторства (рис. 10). В нем всего 14 связей и соответственно более низкий коэффициент близости (0,21). 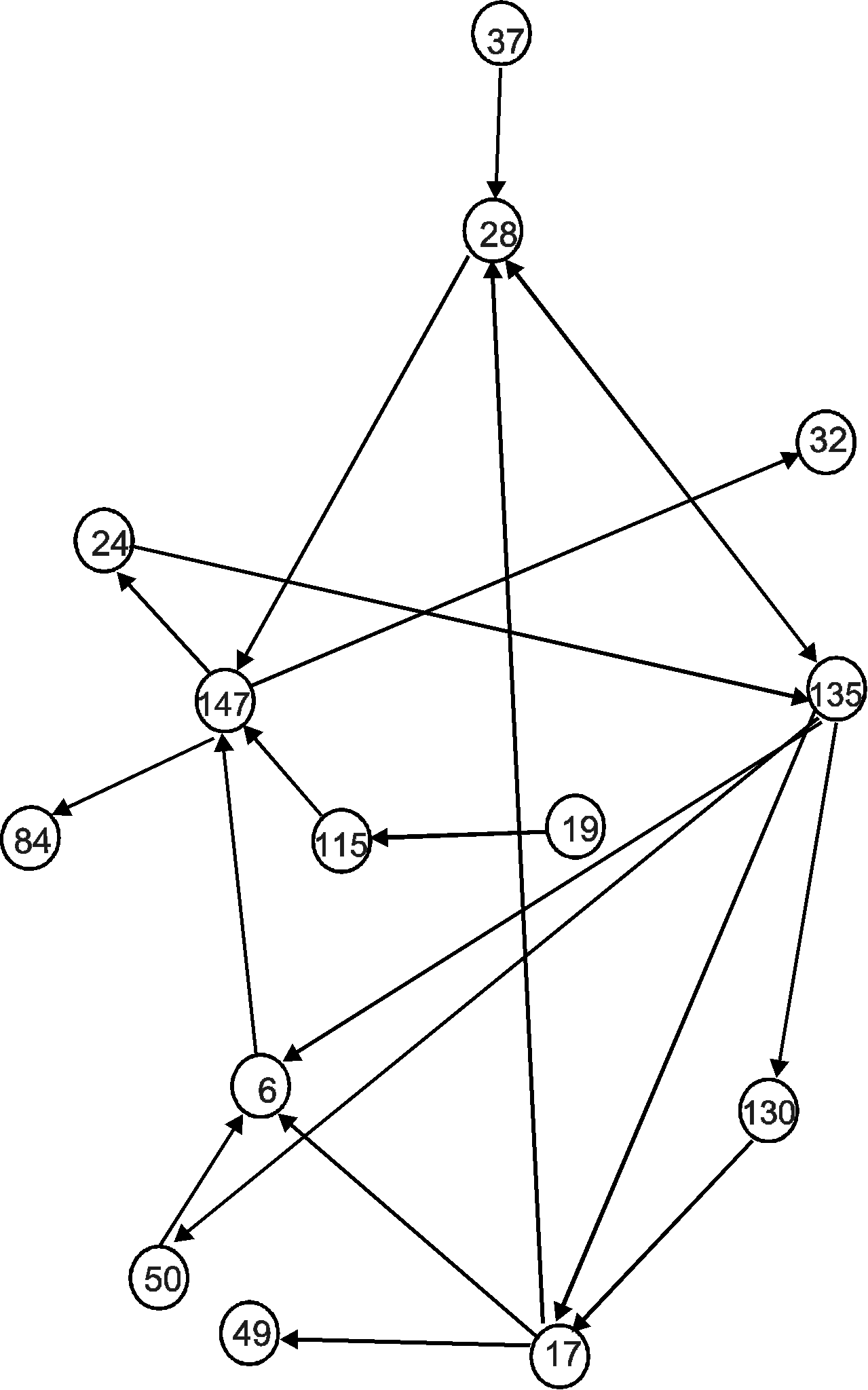 Р 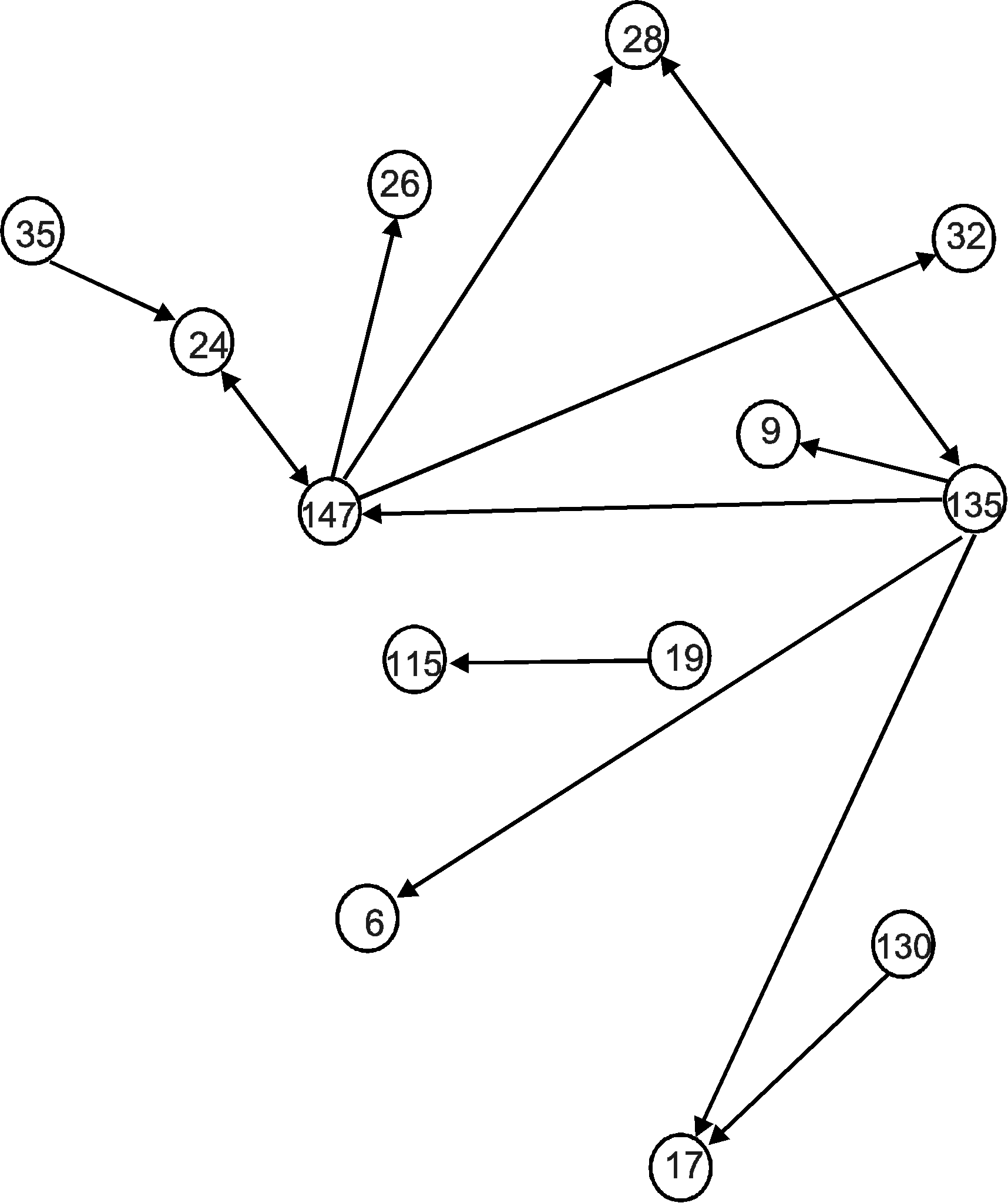 ис. 9. Общий граф «Жития Феодосия» и Печерской повести Рис. 10. Общий граф Печерской повести и «Сказания о Борисе и Глебе» Аналогичным образом автор сравнивает несторовские житийные произведения с графом летописной статьи 1015 г. Анализ текстов с помощью применения новой методики позволяет исследователю отвергнуть господствующее в литературе мнение о том, что летописная статья 1015 г. написана вероятным создателем Начального свода на основе «Сказания о Борисе и Глебе». Л.В.Милов полагает, что статья была создана Нестором, а затем поздний редактор ПВЛ (вероятно, Сильвестр) внес фактические исправления в текст, опираясь уже на данные «Сказания о Борисе и Глебе». Таким образом, подводя итоги изучения текстов древнейшего русского летописного свода, исследователь призывает прекратить более чем вековые споры об авторе «Повести временных лет»: «Создателем этого летописного свода, как выясняется, был все-таки знаменитый печерский черноризец Нестор»25. Метод анализа парных встречаемостей грамматических классов слов позволил историкам-клиометристам достаточно эффективно решить сложные проблемы атрибуции ряда других древних памятников: - Убедительно доказано, что внутренняя структура знаменитого шедевра древнерусской словесности – «Слова о полку Игореве» - является структурой языка XII столетия, что исключает возможность позднейшей подделки. - Опровергнуто распространенное мнение о составлении памятника XVI века Степенной книги митрополитом Афанасием и выявлен автор целой серии очерков в составе Степенной книги – писатель Василий-Варлаам, сотрудничавший в литературной дружине митрополита Макария при создании Великих Четьи-Миней. - При обнаружении некоторого стилевого сходства сочинений Ивана Грозного, Андрея Курбского и Ивана Пересветова, объясняемого активным вмешательством переписчиков и канцеляристов в авторский текст, отвергнуты гипотезы, согласно которым Иван Пересветов – это псевдоним Ивана Грозного, а переписка Грозного и Курбского создана князем Шаховским в 20-30-х гг. XVII века. - Определены авторы двух анонимных произведений конца XVIII в. – «Писем к Фалалею» (Денис Фонвизин) и «Деревенского зеркала или общенародной книги» (Андрей Болотов). Перспективы развития данного направления квантитативной истории исследователи связывают с созданием банка данных всех атрибутированных и анонимных нарративных текстов. Тогда «история древнерусской и русской культуры обогатится огромным количеством новых действующих лиц, а круг известных историографии авторов обогатится произведениями, созданными ими, но по тем или иным причинам ставшими анонимными»26. 3.4. Определение достоверности и репрезентативности источника До сих пор рассматривалось, как с помощью количественных методов решаются задачи источниковедческой критики нарративных источников. Обратимся теперь к массовым источникам. Основной целью источниковедческого анализа массовых источников является установление достоверности и репрезентативности зафиксированных в них количественных данных. Как было показано в первом разделе настоящего пособия, решая вопрос о достоверности конкретно-исторических данных, исследователь должен изучить историю происхождения и судьбу источников. Однако, наряду с содержательным анализом, для определения достоверности можно использовать некоторые математико-статистические методы. Часто в распоряжении историка имеется несколько источников, содержащих данные по изучаемой им проблеме, и необходимо решить вопрос об их сравнительной достоверности. Для решения этого вопроса полезно сравнить статистические характеристики (средние и меры вариации) одних и тех же признаков, полученные по данным разных источников. Но сравнения описательных характеристик бывает недостаточно для суждения о действительном сходстве данных, содержащихся в разных источниках. Для определения степени их сходства используется корреляционный анализ, позволяющий выявлять тесноту взаимосвязей между признаками. При этом может возникнуть несколько ситуаций: 1. Данные источника, достоверность которого неизвестна, сравниваются с данными достоверного источника. Тогда высокие коэффициенты корреляции между соответствующими показателями источников будут свидетельствовать о достоверности исследуемого источника, а низкие – о его недостоверности. 2. Сравниваются несколько источников неизвестной достоверности. Если корреляционная взаимосвязь данных, извлеченных из этих источников, достаточно высока, то источники рисуют одинаковую картину и, следовательно, отличаются высокой достоверностью. Если же сопряженность показателей источников отсутствует, то либо все эти источники недостоверны, либо один из них достоверен, а другой (другие) – нет. Решить проблему достоверности в этом случае можно путем включения данных того или иного источника в совокупность других показателей, характеризующих систему, в которую входит и изучаемое явление. Если рассматриваемые данные вписываются в систему других показателей (сопряжены с ними), то они являются достоверными. В противном случае они недостоверны. Рассмотрим варианты применения корреляционного анализа для определения достоверности источников на конкретных примерах. Б.Н.Миронов сравнивает данные об урожаях ржи по сведениям губернаторских отчетов, достоверность которых признается некоторыми исследователями сомнительной, с признанными достоверными данными частных хозяйств за 1841-1850 гг. (табл. 5)27. Таблица 5 Урожаи ржи в Европейской России по губернаторским отчетам (I) и по записям частных хозяйств (II) в 1841-1850 гг. (в «самах»)
По приведенным данным можно вычислить средние арифметические, вариации признака и коэффициент корреляции между рядами урожаев по двум источникам. Получим: Очевидно, что уровень урожаев источники отражают по-разному, а динамику урожаев – практически одинаково. Высокий коэффициент корреляции позволяет исследователю сделать вывод о достоверности сведений губернаторских отчетов в отношении синхронности и пропорциональности колебаний урожаев. При этом различия в уровне урожаев, зафиксированные в источниках, он объясняет тем, что данные губернаторов охватывали всю крестьянскую и помещичью пашню, а записи частных хозяйств – пашню отдельных помещиков. Конечно, в вопросе о достоверности губернаторских отчетов еще рано ставить точку (слишком уж существенны различия в данных об урожайности этих двух источников). Однако результаты проведенного анализа свидетельствуют о том, что не следует пренебрегать сведениями губернаторских отчетов, считая их полностью недостоверными. Анализ достоверности урожайной статистики по данным трех независимых источников (Центрального статистического комитета (ЦСК), Министерства земледелия и земств) с помощью методов математической статистики проводился Д.Н. Иванцовым еще в начале XX века28. Общие итоги корреляции данных показали, что эти разные источники рисуют очень сходную картину динамики урожайности. Так, корреляционная взаимосвязь динамики урожайности ржи по 50 губерниям Европейской России в 1885-1908 гг., по данным ЦСК и Министерства земледелия, равнялась у крестьян и у частных владельцев 0,92. При этом по отдельным губерниям коэффициенты корреляции превышали 0,90 у помещиков в 32 и у крестьян в 36 губерниях из 50, а были менее 0,75 соответственно в 4 и 1 губерниях. Что касается сведений ЦСК и земств, то в среднем по 18 губерниям эти данные дают коэффициенты корреляции 0,92 у крестьян и 0,89 у помещиков. По отдельным губерниям взаимосвязь погодных средних урожаев значительно превышает 0,90 (табл. 6). Таким образом, динамику урожайности данные разных источников урожайной статистики отражают одинаково, что свидетельствует о достаточно высокой ее достоверности в рассмотренном аспекте. Таблица 6 Взаимосвязь погодных средних урожаев по сведениям ЦСК и земств
Проблему достоверности сведений разных источников, сопряженность которых отсутствует, изучал И.Д.Ковальченко по данным переписи 1897 г. и Комиссии 16 ноября 1901 г. о сельскохозяйственных наемных рабочих29. Для этого по данным двух источников им были вычислены коэффициенты корреляции между долей наемных сельскохозяйственных рабочих (наемные рабочие в процентах к общему числу работников) и другими показателями социально-экономического развития по 50 губерниям Европейской России (табл. 7). Таблица 7 Корреляционная взаимосвязь обеспеченности сельскохозяйственными рабочими с другими факторами социально-экономического развития
Данные переписи 1897 г. о наемных рабочих тесно взаимосвязаны с долей хозяйств, применявших наемный труд (0,75), т.е. с признаком, отличавшимся высокой достоверностью. Взаимосвязь с размерами посевов отсутствует (-0,01), т.е. относительные размеры земледельческого производства не определяли степени применения наемного труда. Наблюдается слабая связь с обеспеченностью продуктивным скотом и урожайностью и тесная взаимосвязь с грамотностью населения (0,81), которая отражает общий уровень буржуазно-капиталистического развития. Все это свидетельствует о достоверности данных переписи 1897 г. о наемных рабочих как показателе сравнительного уровня применения наемного труда в сельском хозяйстве отдельных губерний. Иная картина с данными Комиссии 16 ноября 1901 г. Здесь показатели применения наемного труда имеют связь лишь с размерами посевов (0,57), что объясняется тем, что данные 1901 г. о наемных рабочих исчислялись исходя из учета их потребности в земледелии. С долей хозяйств, применявших наемный труд, и степенью грамотности, т.е. с ведущими факторами, сведения 1901 г. совсем не связаны. Следовательно, сведения 1901 г. не отражают сравнительной степени применения наемного труда в сельском хозяйстве отдельных губерний. Таким образом, достоверными данными об обеспеченности сельскохозяйственными наемными рабочими располагает перепись 1897 г., а сведения Комиссии 16 ноября 1901 г. в этом отношении недостоверны. Другой важной задачей источниковедческого анализа массовых источников является определение репрезентативности (представительности) содержащихся в них конкретно-исторических данных. Как уже отмечалось в первом разделе работы, исследователь должен установить качественную и количественную репрезентативность данных. Качественная репрезентативность (достаточность данных для раскрытия внутренней сути изучаемого явления или процесса) определяется на основе их содержательного анализа. Проблема репрезентативности данных в количественном отношении решается с помощью выборочного метода математической статистики. Применение выборочного метода оказывается наиболее эффективным, когда в распоряжении историка имеются большие объемы массовых источников, сплошная обработка которых весьма затруднительна, да и вряд ли целесообразна, поскольку на основе репрезентативных выборок можно получить достаточно надежные результаты. Примером успешного использования выборочного метода для формирования репрезентативных данных является исследование В.З.Дробижевым, А.К.Соколовым и В.А.Устиновым социальной структуры рабочего класса по материалам профессиональной переписи 1918 года30. Профессиональная перепись рабочих и фабрично-заводских служащих России 1918 г. охватила территорию 31 губернии, на которые в то время распространялась Советская власть. Перепись коснулась 6973 фабрик и заводов с 1246343 рабочими и служащими, она явилась одной из самых массовых по охвату фабрично-заводского персонала и более полной по объему полученных сведений, чем многие последующие обследования рабочего класса. Первичный бланк переписи включал 37 важных с точки зрения социального анализа вопросов: национальность, место рождения, возраст, возраст первоначального поступления на предприятие, должность, профессия, стаж в должности и профессии, потомственность, уровень квалификации, наличие земли в деревне и характер связи с сельским хозяйством и т.д. Первичные материалы переписи составляют более миллиона личных карточек рабочих. Понятно, что такой огромный массив данных можно изучать лишь на основе выборочного метода. При определении путей выборочной обработки переписи исследователи провели выборочный эксперимент на материалах Ярославской и Воронежской губерний, поскольку Ярославская принадлежала к промышленно развитым губерниям и имела значительное число рабочих, а материалы Воронежской губернии дают представление о рабочих сельскохозяйственного района. При этом было решено взять несколько выборок. Так, из первичных материалов Ярославской губернии механическим способом были отобраны каждые десятая, двадцатая и сотая анкеты (10, 5 и 1 %-ные выборки). Исходя из анализа распределений признаков в выборках различных объемов, определялся оптимальный вариант, обеспечивающий репрезентативность анализируемых данных. Расчеты показали, что достаточно точное (с вероятностью 95 %) представление обо всех параметрах социальных слоев рабочего класса дает 5 %-ная выборка. Вместе с тем обнаружилось, что сравнительно небольшая часть рабочих – рабочие, занятые в сфере общественного управления на производстве, - в 5 %-ную выборку практически не попадала. Тогда доля отбора для этой категории была увеличена (по некоторым губерниям обрабатывались сведения обо всех рабочих данной группы). Таким образом, сочетание содержательного анализа с корректным проведением выборочного обследования позволило исследователям сформировать систему репрезентативных данных, в полной мере характеризующих социальную структуру рабочего класса Советской России в 1918 году. Более сложным вопросом источниковедческого анализа массовых источников является установление репрезентативности «естественных выборок». В этом случае историк должен доказать, что сохранившиеся сведения носят случайный характер, поскольку случайность данных является главным условием их представительности. Здесь преимущественную роль играет историко-содержательный анализ. Однако дополнительную проверку случайности естественной выборки можно осуществить с помощью метода «критерия знаков». Применение метода «критерия знаков» сводится к следующему: Сохранившиеся данные по какому-либо признаку записываются в той последовательности, в какой они встречаются в источнике. Затем из каждого последующего значения вычисляется каждое предыдущее, соответствующая разность оказывается либо положительной (+), либо отрицательной (-). В итоге получается определенное число плюсов и минусов. Если различия между значениями случайны, т.е. если выборка случайна, то число плюсов (или минусов) не выходит за рамки критических границ, определенных в специальных таблицах для каждого объема выборки. Метод «критерия знаков» использует, например, Б.Н.Миронов для определения репрезентативности данных о ценах четверти ржи за 1708 г. по 36 уездам31. Проведенный содержательный анализ позволяет рассматривать сохранившиеся данные о хлебных ценах за 1708 г. как случайную выборку (никакой преднамеренности в сборе сведений о ценах и сохранении их в архивах не было). Чтобы убедиться в этом, исследователь обращается к методу «критерия знаков» (табл. 8). Как видно из таблицы 8, число плюсов равно 15, а число минусов – 18. Критические границы для выборки в 36 единиц составляют 12-24 плюсов (или минусов). Следовательно, поскольку полученные плюсы и минусы не выходят за пределы критических границ, выборку можно считать случайной. Таков основной круг источниковедческих задач, решение которых с помощью количественных методов дает эффективные результаты. Таблица 8 Проверка случайности выборки методом «критерия знаков»
ЗАКЛЮЧЕНИЕ Современные тенденции развития науки и компьютерная революция привели к потребности в математизации и компьютеризации научного знания, что в исторической науке связано с необходимостью решения задач расширения источниковой базы исследований и повышения информативной отдачи источника. Расширение источниковой базы осуществляется путем вовлечения в научный оборот обширных комплексов массовых источников, на основе которых создаются базы и банки машиночитаемых данных. Применение к историческим источникам математических методов, реализующих системный подход, позволяет извлекать из них новую, скрытую информацию. В вопросе применения количественных методов в исторических исследованиях принципиальное значение имеет соотношение количественного и качественного анализа. Количественный анализ не противостоит качественному, а является составной частью исследования, качественный анализ в котором обязателен и имеет преимущественное значение. При этом, поскольку всякому качеству присуще определенное количество, сфера применения количественных методов практически не ограничена. Проблема заключается лишь в выявлении метода, адекватно отражающего суть изучаемого явления или процесса, и корректном его применении. Самое широкое применение в исследовательской практике историков получили методы математической статистики. Эти методы особенно эффективны при изучении массовых исторических источников. Они позволяют решать задачи статистического описания совокупности объектов (методы дескриптивной статистики), статистического оценивания параметров генеральной совокупности по выборочным данным (выборочный метод), статистического анализа взаимосвязей (методы корреляционного и регрессионного анализа), классификации объектов или признаков (методы кластерного и факторного анализа), сжатия информации (методы факторного анализа). Применяя методы математической статистики, историк получает информацию, которая не может быть выявлена описательными методами. Это позволяет строить модели изучаемых явлений и процессов, адекватно отражающие их внутреннюю суть, итогом анализа которых является приращение знания. Значительных успехов квантитативная история достигла в источниковедении массовых и нарративных источников. Введение в практику исторических исследований новых компьютерных технологий, связанных с созданием баз и банков машиночитаемых данных, открывает новые возможности хранения и использования исторических источников, изменяет информационную среду, совершенствует методику анализа. Применение количественных методов дает возможность более плодотворно решать ряд источниковедческих задач: выявлять происхождение и авторство нарративных памятников, устанавливать достоверность и репрезентативность массовых источников. Таким образом, квантификация исторических исследований позволяет значительно углубить изучение многих явлений и процессов действительности. При этом главным условием успешного применения количественных методов является глубина содержательного анализа, что должно учитываться на всех этапах клиометрического исследования: от постановки исследовательской задачи до интерпретации полученных результатов. Контрольно-проверочные вопросы
Список рекомендуемой литературы Барг М.А. Принцип системности в историческом исследовании // История СССР. 1981. № 2. Бокарев Ю.П. Социалистическая промышленность и мелкое крестьянское хозяйство в СССР в 20-е годы: источники, методы исследования, этапы взаимоотношений. М., 1989. Бородкин Л.И. Многомерный статистический анализ в исторических исследованиях. М., 1986. Буховец О.Г. Социальные конфликты и крестьянская ментальность в Российской империи начала XX века: новые материалы, методы, результаты. М., 1996. Воронкова С.В. Российская промышленность начала XX века: источники и методы изучения. М., 1996. Гарскова И.М. Базы и банки данных в исторических исследованиях. М., 1994. Дробижев В.З., Соколов А.К., Устинов В.А. Рабочий класс Советской России в первый год диктатуры пролетариата (Опыт структурного анализа). М., 1975. Историческая информатика / Под ред. Л.И.Бородкина, И.М.Гарсковой. М., 1996. Кахк Ю.Ю. Нужна ли новая историческая наука? // Вопросы истории. 1969. № 3. Кахк Ю.Ю., Лиги Х.М. О связи между антифеодальными выступлениями крестьян и их положением // История СССР. 1976. № 2. Кащенко С.Г. Реформа 19 февраля 1861 г. на Северо-Западе России (Количественный анализ массовых источников). М., 1995. Ковальченко И.Д. Русское крепостное крестьянство в первой половине XIX века. М., 1967. Ковальченко И.Д. Исторический источник в свете учения об информации (к постановке проблемы) // История СССР. 1982. № 3. Ковальченко И.Д. Методы исторического исследования. М., 1987. Ковальченко И.Д., Бородкин Л.И. Аграрная типология губерний Европейской России на рубеже XIX –XX веков (опыт многомерного количественного анализа) // История СССР. 1979. № 1. Ковальченко И.Д., Бородкин Л.И. Структура и уровень аграрного развития районов Европейской России на рубеже XIX–XX веков (Опыт многомерного анализа) // История СССР. 1981. № 1. Ковальченко И.Д., Милов Л.В. Всероссийский аграрный рынок. XVIII – начало XX в. (Опыт количественного анализа). М., 1974. Ковальченко И.Д., Моисеенко Т.Л., Селунская Н.Б. Социально-экономический строй крестьянского хозяйства Европейской России в эпоху капитализма: (источники и методы исследования). М., 1988. Ковальченко И.Д., Селунская Н.Б., Литваков Б.М. Социально-экономический строй помещичьего хозяйства Европейской России в эпоху капитализма: Источники и методы изучения. М., 1982. Ковальченко И.Д., Сивачев Н.В. Структурализм и структурно-количествен-ные методы в современной исторической науке // История СССР. 1976. № 5. Количественные методы в гуманитарных науках. М., 1981. Количественные методы в исторических исследованиях: Учеб. пособие / Под ред. И.Д. Ковальченко. М., 1984. Количественные методы в советской и американской историографии: Материалы советско-американских симпозиумов. Балтимор, 1979, Таллинн, 1981. М., 1983. Краткий клиометрический словарь / Сост. М.Г. Шендерюк. Калининград, 1994. Массовые источники по социально-экономической истории России периода капитализма. М., 1979. Массовые источники по социально-экономической истории советского общества. М., 1979. Математические методы в исторических исследованиях. М., 1972. Математические методы в исследованиях по социально-экономической истории. М., 1975. Математические методы в историко-экономических и историко-культурных исследованиях. М., 1977. Математические методы в социально-экономических и археологических исследованиях. М., 1981. Математические методы и ЭВМ в исторических исследованиях. М., 1985. Математические методы и ЭВМ в историко-типологических исследованиях. М., 1989. Методы количественного анализа текстов нарративных источников. М., 1983. Милов Л.В., Булгаков М.Б., Гарскова И.М. Тенденции аграрного развития России первой половины XVII столетия. Л., 1986. Миронов Б.Н., Степанов З.В. Историк и математика. М., 1975. Миронов Б.Н. История в цифрах. Л., 1991. От Нестора до Фонвизина. Новые методы определения авторства / Под ред. чл.-кор. РАН Л.В. Милова. М., 1994. Россия и США на рубеже XIX – XX столетий (Математические методы в исторических исследованиях). М., 1992. Славко Т.И. Математико-статистические методы в исторических исследованиях. М., 1981. Становление российского парламентаризма начала XX века / Под ред. Н.Б. Селунской. М., 1996. Устинов В.А., Фелингер А.Ф. Историко-социальные исследования, ЭВМ и математика. М., 1973. Хвостова К.В. Количественный подход в средневековой социально-экономической истории. М., 1980. Хвостова К.В. Количественные методы в историческом познании // Вопросы истории. 1983. № 4. СОДЕРЖАНИЕ Введение ………………………………………………………………………. 3 |