Курс. Курс лекций по ар-реКомп. Курс лекций по дисциплине Архитектура компьютеров для студентов, обучающихся по направлению 230700. 62 Прикладная информатика
 Скачать 1.69 Mb. Скачать 1.69 Mb.
|

|
Лекция 2 Классификация вычислительных систем Вопросы: 1. Классификация вычислительных систем по Флинну 2. Вычислительные системы класса SIMD Наиболее перспективным и динамичным направлением увеличения скорости решения прикладных задач является широкое внедрение идей параллелизма в работу вычислительных систем. К настоящему времени в существующих вычислительных системах нашли свое применение самые разнообразные архитектуры и виды параллельной обработки данных. В научно-технической литературе можно найти более десятка различных названий, характеризующих лишь общие принципы функционирования параллельных систем: векторно-конвейерные, системы с массовой параллельной обработкой, систолические массивы, гиперкубы, спецпроцессоры и мультипроцессоры, иерархические и кластерные компьютеры, машины потоков данных, матричные ЭВМ и многие другие. Если же к подобным названиям для полноты описания добавить еще и данные о таких важных характеристиках, как, например, организация памяти, топология связи между процессорами, то станет очевидной сложность классификации вычислительных систем.  а) 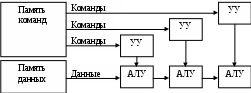 б) Команды Команды в) 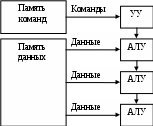 г) 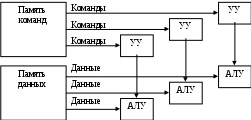 Рис. 1.3. Классификация вычислительных систем по Флинну: а - SISD; б - MISD; в - SIMD; г - MIMD Основной вопрос - что заложить в основу классификации- может решаться по-разному, в зависимости от того, на решение какой задачи данная классификация направлена. Так, часто используемое разделение компьютеров на персональные ЭВМ, рабочие станции, мини-ЭВМ, большие универсальные ЭВМ, минисупер-ЭВМ и супер-ЭВМ, позволяет примерно оценить стоимость компьютера. Общепринятой является классическая систематика Флинна. Классификация базируется на понятии потока, под которым понимается последовательность команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD (рис. 1.3). SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины или, иначе, машины фон-неймановского типа. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Увеличение скорости вычислений в системах достигается следующим образом. Совмещением во времени различных этапов решения различных задач, при котором в системе одновременно работают различные устройства: ввода, вывода и собственно обработки информации. Введением конвейера команд. Использованием конвейера арифметических и логических операций, в котором команды разбиваются на некоторое число микроопераций, образуя, таким образом, несколько потоков микрокоманд. MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако не существует такого класса задач, в которых одна и та же последовательность данных подвергалась бы обработке по нескольким разным программам. По этой причине в чистом виде такая схема до настоящего времени не реализована. SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производиться либо процессорной матрицей, либо с помощью конвейера. MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. Укажем типичных представителей каждого из этих классов. В SISD, как уже отмечалось, входят однопроцессорные последовательные компьютеры типа VAX 11/780. Однако, следует отметить, что в этот класс можно включить и векторно-конвейерные машины, если рассматривать вектор как одно неделимое данное для соответствующей команды. В таком случае в этот класс попадут и такие системы, как CRAY-1, CYBER 205, машины семейства FACOM VP и многие другие. Представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1. В таких системах единое управляющее устройство контролирует множество процессорных элементов. Каждый процессорный элемент получает от устройства управления в каждый фиксированный момент времени одинаковую команду и выполняет ее над своими локальными данными. В этот же класс можно включить классические процессорные матрицы и векторно-конвейерные машины, например, CRAY-1. В этом случае каждый элемент вектора надо рассматривать как отдельный элемент потока данных. Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы: Cm*, C.mmp, Denelcor HEP, BBN Butterfly, Intel Paragon, CRAY T3D и многие другие. Интересно то, что если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) не над одиночным векторным потоком данных, а над множественным скалярным потоком, то все рассмотренные выше векторно-конвейерные компьютеры можно расположить и в данном классе. Предложенная схема классификации является наиболее применяемой при начальной характеристике той или иной вычислительной системы, она позволяет определить базовый принцип ее работы. Однако такой классификации присущи некоторые недостатки. В частности, некоторые архитектуры, например dataflow и векторно-конвейерные машины, четко не вписываются в данную классификацию. Другой недостаток - это чрезмерная заполненность класса MIMD. Необходимо средство, более избирательно систематизирующее архитектуры, которые по Флинну попадают в один класс, но совершенно различны по числу процессоров, природе и топологии связи между ними, по способу организации памяти и, конечно же, по технологии программирования. Недостатком можно считать также наличие пустого класса (MISD). Интересно упомянуть о принципиально ином направлении в развитии компьютерных архитектур - машинах потоков данных. В машинах потоков данных могут одновременно выполняться сразу много команд, для которых готовы операнды. Некоторые элементы этого подхода нашли свое отражение в современных суперскалярных микропроцессорах, имеющих много параллельно работающих функциональных устройств и буфер команд, ожидающих готовности операндов. В качестве примеров таких микропроцессоров можно привести HP РА-8000 и Intel Pentium Pro. Укажем на другую возможную классификацию вычислительных систем. Рассмотрим в качестве примера компьютер Advanced Scientific Computer фирмы Texas Instruments (TI ASC). В основном режиме он работает с 64-х разрядным словом, причем все разряды обрабатываются параллельно. Арифметико-логическое устройство имеет четыре одновременно работающих конвейера, содержащих по восемь ступеней. Такая организация дает 4x8=32 бита в каждом битовом слое, и, значит, компьютер TI ASC может быть представлен в виде (64,32). На основе введенных понятий все вычислительные системы в зависимости от способа обработки информации, заложенного в их архитектуру, можно разделить на четыре класса. Разрядно-последовательные пословно-последовательные (n=m=1). В каждый момент времени такие компьютеры обрабатывают только один двоичный разряд. Представителем данного класса служит давняя система MINIMA с естественным описанием (1,1). Разрядно-параллельные пословно-последовательные (n > 1 , m = 1). Большинство классических последовательных компьютеров, принадлежит к данному классу: IBM 701 с описанием (36,1), PDP-11 (16,1), IBM 360/50 и VAX 11/780 - с описанием (32,1). Разрядно-последовательные пословно-параллельные (n = 1 , m > 1). Как правило, вычислительные системы данного класса состоят из большого числа одноразрядных процессорных элементов, каждый из которых может независимо от остальных обрабатывать свои данные. Типичными примерами служат STARAN (1, 256) и MPP (1,16384) фирмы Goodyear Aerospace, прототип известной системы ILLIAC IV компьютер SOLOMON (1, 1024) и ICL DAP (1, 4096). Разрядно-параллельные пословно-параллельные (n > 1, m > 1). Большая часть существующих параллельных вычислительных систем, обрабатывая одновременно mn двоичных разрядов, принадлежит именно к этому классу: ILLIAC IV (64, 64), TI ASC (64, 32), C.mmp (16, 16), CDC 6600 (60, 10), BBN Butterfly GP1000 (32, 256). Недостатки предложенной классификации достаточно очевидны и связаны со способом вычисления ширины битового слоя m. По существу, не обозначается никакого различия между совершенно разными вычислительными системами (процессорными матрицами, векторно-конвейерными и многопроцессорными системами). Не определяется важное обстоятельство - за счет чего компьютер может одновременно обрабатывать более одного слова: множественности функциональных устройств, реализации в них конвейеров или же какого-то числа независимых процессоров. Если в системе N независимых процессоров имеют каждый по F конвейерных функциональных устройств с длиной конвейера L, то для вычисления ширины битового слоя надо просто найти произведение данных характеристик. Однако достоинством такой классификации является введение единой числовой метрики для всех типов вычислительных систем, которая вместе с другими характеристиками позволяет сравнить любые две системы между собой. 2.2. Вычислительные системы класса SIMD SIMD-системы были первыми вычислительными системами, состоящими из большого числа процессоров, и среди первых систем, на которых была достигнута производительность порядка GFLOPS (миллиард операций с плавающей запятой в секунду). Как отмечалось ранее, к классу SIMD относятся вычислительные системы, где множество элементов данных подвергается параллельной, но однотипной обработке. В SIMD-системах имеется одно устройство управления, обеспечивающее последовательное выполнение команд программы. На стадии выполнения общая команда транслируется множеству процессоров (в простейшем случае — АЛУ), каждый из которых обрабатывает свои данные. В настоящее время принято считать, что класс SIMD составляют векторные (векторно-конвейерные), матричные, систолические, вычислительные системы с командными словами сверхбольшой длины. 2.2.1. Векторные и векторно-конвейерные вычислительные системы. Хотя производительность ВС общего назначения неуклонно возрастает, по-прежнему остаются задачи, требующие существенно большей вычислительной мощности. К таким, прежде всего, следует отнести задачи моделирования реальных процессов и объектов, для которых характерна обработка больших регулярных массивов чисел в форме с плавающей запятой. Указанные массивы представляются матрицами и векторами, а алгоритмы их обработки описываются в терминах матричных операций. Как известно, основные матричные операции сводятся к однотипным действиям над парами элементов исходных матриц, которые чаще всего можно производить параллельно. В универсальных ВС, ориентированных на скалярные операции, обработка матриц выполняется поэлементно и последовательно. При большой размерности массивов последовательная обработка элементов матриц занимает слишком много времени, что и приводит к неэффективности универсальных ВС для рассматриваемого класса задач. Для обработки массивов требуются вычислительные средства, позволяющие с помощью единой команды производить действие сразу над всеми элементами массивов — средства векторной обработки. Под вектором понимается одномерный массив однотипных данных (обычно в форме с плавающей точкой), регулярным образом расположенный в памяти вычислительной системы. Если обработке подвергаются многомерные массивы, их также рассматривают как векторы. Векторный процессор – процессор, в котором операндами некоторых команд могут выступать упорядоченные массивы данных – векторы. Векторный процессор может быть реализован в двух вариантах. В первом он представляет собой дополнительный блок к универсальной вычислительной машине (системе). Во втором – векторный процессор является как основой самостоятельной ВС. Наиболее распространенными подходами к архитектуре средств векторной обработки являются: конвейерное АЛУ; массив АЛУ; массив процессорных элементов (матричная ВС). Понятие векторного процессора имеет отношение к первым двум подходам, которые представлены на рис. 1.4. 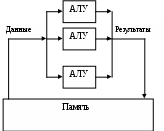 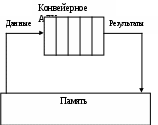 а) б) Рис. 1.4. Варианты векторной обработки: а – конвейерное АЛУ; б – массив АЛУ В варианте с конвейерным АЛУ предполагается, что операции над числами достаточно сложны и поддаются разбиению на отдельные фазы. Например, операция сложения над числами в форме с плавающей запятой (ПЗ) предполагает наличие следующих фаз обработки: выравнивание порядков; сдвиг мантиссы; сложение мантисс; нормализация. В варианте с массивом АЛУ одновременные операции над элементами векторов проводятся с помощью нескольких параллельно используемых АЛУ. 1.5.2. Матричные вычислительные системы. Назначение матричных вычислительных систем во многом схоже с назначением векторных ВС — обработка больших массивов данных. В основе матричных систем лежит матричный процессор (array processor), состоящий из регулярного массива процессорных элементов (ПЭ). Организация систем подобного типа на первый взгляд достаточно проста. Они имеют общее управляющее устройство, генерирующее поток команд, и большое число ПЭ, работающих параллельно и обрабатывающих каждый свой поток данных. Однако на практике, чтобы обеспечить достаточную эффективность системы при решении широкого круга задач, необходимо организовать связи между процессорными элементами так, чтобы наиболее полно загрузить процессоры работой. 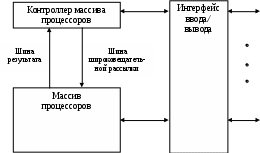 Рис. 1.5. Структура матричной вычислительной системы Именно характер связей между ПЭ и определяет разные свойства системы. Ранее уже отмечалось, что подобная схема применима и для векторных вычислений. Между матричными и векторными системами есть существенная разница. Матричный процессор интегрирует множество идентичных функциональных блоков (ФБ), логически объединенных в матрицу и работающих в SIMD-стиле. Не столь существенно, как конструктивно реализована матрица процессорных элементов — на едином кристалле или на нескольких. Важен сам принцип — ФБ логически скомпонованы в матрицу и работают синхронно, то есть присутствует только один поток команд для всех блоков. Векторный процессор имеет встроенные команды для обработки векторов данных, что позволяет эффективно загрузить конвейер из функциональных блоков. В свою очередь, векторные процессоры проще использовать, потому что команды для обработки векторов — это более удобная для человека модель программирования, чем SIMD. Структура матричной вычислительной системы приведена на рис. 1.5. Массив процессоров (МПр) производит параллельную обработку множественных элементов данных. Единый поток команд, управляющий обработкой данных в массиве процессоров, генерируется контроллером массива процессоров (КМП). КМП выполняет последовательный программный код, реализует операции условного и безусловного перехода, транслирует в МПр команды, данные и сигналы управления. Команды выполняются процессорами в режиме жесткой синхронизации. Сигналы управления используются для синхронизации команд и пересылок, а также для управления процессом вычислений. Команды, данные и сигналы управления передаются из КМП в массив процессоров по шине широковещательной рассылки. Поскольку выполнение операций условного перехода зависит от результатов вычислений, результаты обработки данных в массиве процессоров транслируются из КМП по шине результата. Массив процессоров помимо множества процессоров должен включать в себя множество модулей памяти. Кроме того, в массиве должна быть реализована сеть взаимосвязей, как между процессорами, так и между процессорами и модулями памяти. Таким образом, под термином массив процессоров понимается блок, состоящий из процессоров, модулей памяти и сети соединений. В матричных SIMD-системах распространение получили распространение два основных типа архитектурной организации массива процессорных элементов. В первом варианте “процессорный элемент-процессорный элемент“ (“ПЭ-ПЭ“) все процессорные элементы (ПЭ) связаны между собой сетью соединений. Каждый ПЭ – это процессор с локальной памятью. Процессорные элементы выполняют команды, получаемые из КМП по шине широковещательной рассылки, и обрабатывают данные как хранящиеся в их локальной памяти, так и поступающие из КМП. Для трансляции результатов из отдельных ПЭ в КМП служит шина результата. Второй вид архитектуры - “процессор-память“. В этом случае двунаправленная сеть соединений связывает множество процессоров с множеством модулей памяти. Процессоры управляются через шину широковещательной рассылки. Обмен данными между процессорами осуществляется как через сеть, так и через модули памяти. В качестве процессорных элементов в большинстве матричных SIMD-систем применяются простые RISC-процессоры с локальной памятью ограниченной емкости. Сведения о систолических вычислительных системах и вычислительных системах с командными словами сверхбольшой длины содержатся в [16]. |