Курс. Курс лекций по ар-реКомп. Курс лекций по дисциплине Архитектура компьютеров для студентов, обучающихся по направлению 230700. 62 Прикладная информатика
 Скачать 1.69 Mb. Скачать 1.69 Mb.
|

Синицын И.В., Терновсков В.Б. Курс лекций по дисциплине «Архитектура компьютеров » для студентов, обучающихся по направлению 230700.62 «Прикладная информатика» Москва 2011 УДК 681.306 ББК 32.073 Т34 Синицын И.В., Терновсков В.Б.
В курсе раскрываются архитектура и организация вычислительных систем, современные микропроцессоры, топологии и технологии сетей и коммуникаций, метрики эффективности и т.д.. Данный курс обеспечивает лекционные занятия по дисциплине «Архитектура компьютеров » во втором и третьем триместре. Рекомендовано к изданию решением учебно-методического совета Финансового университета при правительстве РФ (протокол № ___ от «___» _____________ 2011 г.) УДК 681.306 ББК 32.073 Т34 © Финансовый университет при правительстве РФ © Синицын Иван Васильевич © Терновсков Владимир Борисович Оглавление Способы организации и типы вычислительных систем…………………4 Классификация вычислительных систем………………………………..16 Вычислительные системы класса MIMD………………………………..27 Системный блок вычислительной системы ………………….…………37 Организация памяти в вычислительных системах ……………….…….45 Архитектура современных ЛВС ……………………………………….. 50 Архитектура информационно-вычислительных сетей……………….…58 Топология. Методы коммутации данных…………………………….… 73 Стек коммуникационных протоколов ТСР/IP. Протоколы TCP и IP………………………………………………..…….. 84 Организация процесса передачи данных. Методы доступа к сети ЛВС…………………………………….………. 94 Лекция 1 Способы организации и типы вычислительных систем Вопросы: Определение понятия архитектура вычислительных систем Фон-неймановская архитектура Архитектура процессоров вычислительных систем При рассмотрении данного вопроса следует первоначально определить понятия вычислительная машина (ВМ) и вычислительная система (ВС). Существуют различные подходы. Так, согласно одному из них [7], к ВС относятся вычислительные средства, имеющие в своем составе специализированные аппаратные модули и/или специализированное программное обеспечение. Воспользуемся наиболее общими из существующих определений [5], в основе которых лежит различие между ВМ и ВС по признаку множественности вычислительных модулей и, соответственно, параллельной обработки. Вычислительная машина – комплекс технических и программных средств, предназначенный для автоматизации подготовки и решения задач пользователей. Вычислительная система – совокупность взаимосвязанных и взаимодействующих процессоров или вычислительных машин, периферийного оборудования и программного обеспечения, предназначенная для подготовки и решения задач пользователя. Таким образом, основной отличительной чертой вычислительных систем является наличие в них средств, реализующих параллельную обработку за счет построения параллельных ветвей в вычислениях, что не предусматривается классической структурой вычислительной машины. Очевидно, что различия между ВМ и ВС не могут быть точно определены. Так, современные вычислительные машины с одним процессором обладают развитыми средствами распараллеливания вычислительного процесса (например, средствами параллельного выполнения итераций вложенных циклов). С другой стороны, вычислительные системы могут состоять из традиционных ВМ и процессоров. Принято разделять понятия архитектуры вычислительных систем и архитектуры вычислительных машин. Под архитектурой вычислительных машин, как правило, понимается логическое построение ВМ, то есть то, какой представляется машина программисту, разрабатывающему программу на машинноориентированном языке. Это определение архитектуры в “узком” смысле. Оно охватывает следующее: перечень и формат команд, формы представления данных, механизмы ввода-вывода, способы адресации памяти, назначение и состав регистров общего назначения, а также других адресуемых регистров. Однако при таком подходе из рассмотрения выпадают такие важные вопросы как состав устройств, сложность процессора, емкость памяти, тактовая частота. Круг этих вопросов принято определять понятием организация или структурная организация. Более часто применительно к ВМ используется понятие архитектуры в “широком“ смысле или просто архитектуры, объединяющее в себе как архитектуру в “узком” смысле, так и организацию ВМ. Термин “архитектура” применительно к вычислительным системам дополнительно включает в себя вопросы выделения составляющих ВС (иерархии ВС), распределения функций между ними и определение взаимодействия между составляющими. 1.2. Фон-неймановская архитектура Для современных ВМ исходной является концепция Дж. фон Неймана, согласно которой определяется автономно работающая универсальная машина, объединяющая устройство управления, двоичное арифметическое устройство, память, устройства ввода и вывода (рис. 1.1). 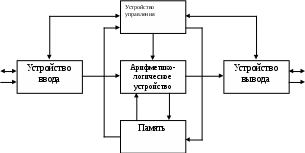 Рис. 1.1. Структура фон-неймановской вычислительной машины Вычисления осуществляются последовательно под централизованным управлением от команд. Набор команд составляет машинный язык низкого уровня реализации простых операций над элементарными операндами. Память достаточно большой емкости, хранящая как команды, так и данные, состоит из ячеек фиксированного размера, линейно организованных в линейном пространстве. Эти положения составляют концептуальную основу обычных ВМ. Следует отметить, что концепция неймановской архитектуры предусматривает единственное арифметическое устройство и одну глобальную основную память, что обуславливает последовательную обработку и тем самым ограничивает скорость выполнения вычислений. Это узкое место последовательной неймановской архитектуры призваны устранить параллельные архитектуры. Для этих архитектур во всех случаях независимо от формы реализации обработка распараллеливается по нескольким процессорам и осуществляется с совмещением по времени. 1.3. Архитектура процессоров вычислительных систем 1.3.1. Конвейеризация вычислений Рассмотрим использование конвейерной обработки на примере конвейера команд. Как известно, цикл выполнения команды представляет собой последовательность этапов. Возложив реализацию каждого из них на самостоятельное устройство и последовательно соединив такие устройства, можно получить классическую схему конвейера команд. Выделим в цикле выполнения команд шесть этапов. Выборка команды (ВК). Чтение очередной команды из памяти и занесение ее в регистр команды. Декодирование (ДК). Определение кода операции и способов адресации операндов. Вычисление адресов операндов (ВА). Вычисление исполнительных адресов операндов в соответствии с указанным в команде способом их адресации. Выборка операндов (ВО). Извлечение операндов из памяти. Эта операция не нужна для операндов, находящихся в регистрах. Исполнение команды (ИК). Исполнение указанной операции. Запись результата (ЗР). Занесение результата в память. Пусть команды выполняются на конвейерной системе с шестью ступенями, соответствующими шести этапам цикла команды. Предполагается, что каждая команда обязательно проходит все шесть ступеней, все этапы имеют одинаковую длительность, равную одной единице времени, и могут выполняться одновременно. Тогда выполнение девяти команд заняло бы 9 6 = 54 единицы времени, А использование конвейера позволяет снизить это время до 14 единиц. На практике в силу возникающих в конвейере конфликтных ситуаций достичь предельно возможной производительности не удается. Конфликтные ситуации в конвейере обусловлены следующими причинами: попыткой нескольких команд одновременно обратиться к одному и тому же ресурсу (структурный риск); взаимосвязью команд по данным (риск по данным); неоднозначностью при выборке следующей команды в случае команд перехода (риск по управлению). Суперконвейерные процессоры. Эффективность конвейера находится в прямой зависимости от того, с какой частотой на его вход подаются объекты обработки. Добиться n-кратного увеличения темпа работы конвейера можно двумя путями: разбиением каждой ступени конвейера на n «подступеней» при одновременном повышении тактовой частоты внутри конвейера также в n раз; включением в состав процессора n конвейеров, работающих с перекрытием. В сущности, суперконвейеризация сводится к увеличению количества ступеней конвейера как за счет добавления новых ступеней, так и путем дробления имеющихся ступеней на несколько простых подступеней. Главное требование — возможность реализации операции в каждой подступени наиболее простыми техническими средствами, а значит, с минимальными затратами. Вторым, не менее важным, условием является одинаковость задержки на всех подступенях. Критерием для причисления процессора к суперконвейерным служит число ступеней в конвейере команд. К суперконвейерным относят процессоры, где таких ступеней больше шести. Первым серийным суперконвейерным процессором считается MIPS R4000, конвейер команд которого включает в себя восемь ступеней. 1.3.2. Архитектуры с полным и сокращенным набором команд Современная технология программирования ориентирована на языки высокого уровня (ЯВУ), главная задача которых — облегчить процесс написания программ. Операции, характерные для ЯВУ, отличаются от операций, реализуемых машинными командами. Эта проблема получила название семантического разрыва и ведет она к недостаточно эффективному выполнению программ. Пытаясь преодолеть семантический разрыв, разработчики ВМ расширяют систему команд, дополняя ее командами, реализующими сложные операторы ЯВУ на аппаратурном уровне, вводят дополнительные виды адресации и т. п. Вычислительные машины, где реализованы эти средства, принято называть ВМ с полным набором команд (CISC — Complex Instruction Set Computer). К типу CISC можно отнести значительную часть ВМ, выпускаемых в настоящее время. Характерные для CISC способы решения проблемы семантического разрыва, вместе с тем ведут к усложнению архитектуры ВМ, главным образом устройства управления, что, в свою очередь, негативно сказывается на производительности в целом. Кроме того, в CISC очень сложно организовать эффективный конвейер команд, который является одним из наиболее перспективных путей повышения производительности ВМ. Анализ программы, получаемые после компиляции с ЯВУ, позволил обнаружить следующие закономерности. Реализация сложных команд, эквивалентных операторам ЯВУ, требует увеличения емкости управляющей памяти в микропрограммном устройстве управления. Микропрограммы сложных команд могут занимать до 60% управляющей памяти, в то время, как их доля в общем объеме программы зачастую не превышает 0,2%. В откомпилированной программе операторы ЯВУ реализуются в виде процедур (подпрограмм), поэтому на операции вызова процедуры и возврата из нее приходится от 15 до 45% вычислительной нагрузки. При вызове процедуры вызывающая программа передает этой процедуре некоторое количество аргументов. Выяснилось, что в 98% случаев число передаваемых аргументов не превышает шести. Примерно такое же положение сложилось с параметрами, которые процедура возвращает вызывающей программе. Более 80% переменных, используемых программой, являются локальными, то есть создаются при входе в процедуру и уничтожаются при выходе из нее. Почти половину операций в ходе вычислений составляет операция присваивания, сводящаяся к данных между регистрами и памятью. Детальный анализ результатов исследований привел к пересмотру традиционных архитектурных решений, следствием чего стало появление архитектуры с сокращенным набором команд (RISC – Reduced Instruction Set Computer). Главные усилия в архитектуре RISC направлены на построение эффективного конвейера команд, то есть такого конвейера, в котором все команды извлекаются из памяти и поступают в ЦП на обработку в виде равномерного потока. При этом ни одна команда не должна находиться в состоянии ожидания, а ЦП должен оставаться загруженным на протяжении всего времени. Кроме того, идеальным считается вариант, при котором любой этап цикла команды выполняется в течение одного тактового периода. Последнее условие относительно просто можно реализовать для этапа выборки. Необходимо лишь, чтобы все команды имели стандартную длину, равную ширине шины данных, соединяющей ЦП и память. Унификация времени исполнения для различных команд — значительно более сложная задача, поскольку наряду с регистровыми командами существуют также команды с обращением к памяти. Помимо одинаковой длины команд, важно иметь относительно подсистему декодирования и управления: сложное устройство управления (УУ) будет вносить дополнительные задержки в формирование сигналов управления. Очевидный путь существенного упрощения УУ — сокращение числа выполняемых команд, форматов команд и данных, а также видов адресации. В сокращенном списке команд должны оставаться те, которые используются наиболее часто. Исследования показали, что 80-90% времени выполнения типовых программ приходится на относительно малую часть команд (10-20%). К наиболее часто используемым действиям относятся пересылка данных, арифметические и логические операции. Основная причина, препятствующая сведению всех этапов цикла команды к одному тактовому периоду - потенциальная необходимость доступа к памяти для выборки операндов и/или записи результатов. Следует максимально сократить число команд, имеющих доступ к памяти. Это положение отображается в следующих двух принципах, которые должны быть добавлены к описанию архитектуры RISC: доступ к памяти во время исполнения осуществляется только командами “Чтение“ и “Запись”; все операции, кроме “Чтение“ и “Запись”, имеют тип “регистр- регистр“. Для упрощения выполнения большинства команд и приведения их к типу “регистр- регистр“ требуется снабдить ЦП значительным числом регистров общего назначения. Большое число регистров в регистровом файле ЦП позволяет обеспечить временное хранение промежуточных результатов, используемых как операнды в последующих операциях, и ведет к уменьшению числа обращений к памяти, ускоряя выполнение операций. Минимальное число регистров, равное 32, принято как стандарт де-факто большинством производителей RISC-компьютеров. Концепция RISC-компьютера сводится к следующим положениям. Выполнение всех (или, по крайней мере, 75% команд) за один цикл. Стандартная однословная длина всех команд, равная естественной длине слова и ширине шины данных и допускающая унифицированную поточную обработку всех команд. Малое количество команд (не более 128). Малое количество форматов команд (не более 4). Малое число способов адресации (не более 4). Доступ к памяти только посредством команд “Чтение“ и “Запись” Все команды, за исключением команд “Чтение“ и “Запись”, используют внутрипроцессорные межрегистровые пересылки. Устройство управления с “жесткой” логикой. Большой ( не менее 32, до 500 и более) процессорный файл регистров общего назначения. Сравнивая достоинства и недостатки CISC и RISC, невозможно сделать однозначный вывод о неоспоримом преимуществе одной архитектуры над другой. Достоинствами RISC-архитектуры являются: сравнительно простая структура устройства управления, которое занимает в RISC II не более 10% площади кристалла. При этом остается больше места для других узлов ЦП и для дополнительных устройств: кэш-памяти, блока арифметики с плавающей точкой, части основной памяти, блока управления памятью, портов ввода/вывода. высокое быстродействие, связанное с унификацией набора команд, ориентацией на потоковую конвейерную обработку, унификацией размера команд и длительности их выполнения. К недостаткам RISC-архитектуры следует отнести: принципиальный недостаток — сокращенное число команд: на выполнение ряда функций приходится тратить несколько команд вместо одной в CISC. Это удлиняет код программы, увеличивает загрузку памяти и трафик команд между памятью и ЦП. Исследования показывают, что RISC-программа в среднем на 30% длиннее CISC-программы, реализующей те же функции; хотя большое число регистров дает существенные преимущества, само по себе оно усложняет схему декодирования номера регистра, тем самым увеличивается время доступа к регистрам; устройство управления с «жесткой» логикой, реализованное в большинстве RISC-систем, менее гибко, более склонно к ошибкам, затрудняет поиск и исправление ошибок, уступает устройству управления с «гибкой» логикой при выполнении сложных команд. 1.3.3. Суперскалярные процессоры Поскольку возможности по совершенствованию элементной базы уже практически исчерпаны, дальнейшее повышение производительности ВМ лежит в плоскости архитектурных решений. Как уже отмечалось, один из наиболее эффективных подходов в этом плане — введение в вычислительный процесс различных уровней параллелизма. Ранее рассмотренный конвейер команд — типичный пример такого подхода. Тем же целям служат и арифметические конвейеры, где конвейеризации подвергается процесс выполнения арифметических операций. Дополнительный уровень параллелизма реализуется в векторных и матричных процессорах, но только при обработке многокомпонентных операндов типа векторов и массивов. Здесь высокое быстродействие достигается за счет одновременной обработки всех компонентов вектора или массива, однако подобные операнды характерны лишь для достаточно узкого круга решаемых задач. Основной объем вычислительной нагрузки обычно приходится на скалярные вычисления, то есть на обработку одиночных операндов, таких, например, как целые числа. Для подобных вычислений дополнительный параллелизм реализуется значительно сложнее, но, тем не менее, возможен и примером могут служить суперскалярные процессоры. Суперскалярным называется центральный процессор (ЦП), который одновременно выполняет более чем одну скалярную команду. Это достигается за счет включения в состав ЦП нескольких самостоятельных функциональных (исполнительных) блоков, каждый из которых отвечает за свой класс операций и может присутствовать в процессоре в нескольких экземплярах. Так, в микропроцессоре Pentium III блоки целочисленной арифметики и операций с плавающей точкой дублированы, а в микропроцессорах Pentium 4 и Athlon — троированы. Структура типичного суперскалярного процессора включает в себя шесть блоков (рис. 1.2.): выборки команд, декодирования команд, диспетчеризации команд, распределения команд по функциональным модулям, блок исполнения и блок обновления состояния. Блок выборки команд извлекает команды из основной памяти через кэш-память команд. Этот блок хранит несколько значений счетчика команд и обрабатывает команды условного перехода. Блок декодирования расшифровывает код операции, содержащийся в извлеченных из кэш-памяти командах. В некоторых суперскалярных процессорах, например, в микропроцессорах фирмы Intel, блоки выборки и декодирования совмещены. Блоки диспетчеризации и распределения взаимодействуют между собой и реализуют в суперскалярном процессоре управление трафиком. В обоих блоках находятся очереди декодированных команд. Очередь блока распределения часто рассредоточивается по нескольким самостоятельным буферам (накопителям команд), предназначенным для хранения команд, которые уже декодированы, но еще не выполнены. Каждый такой накопитель связан со своим функциональным модулем (ФМ), поэтому число накопителей обычно равно числу ФМ. Если в процессоре используется несколько однотипных ФМ, то им придается один общий накопитель. Блок распределения в каждом цикле своей работы проверяет каждую команду в своих очередях на наличие всех необходимых для ее выполнения операндов и после этого начинает выполнение команд в соответствующем функциональном модуле. Блок диспетчеризации кроме очереди команд хранит также список свободных функциональных модулей, который используется для отслеживания состояния очереди распределения. Такое отслеживание состоит в извлечении блоком диспетчеризации команд из очереди и считывании из памяти или регистров операндов этих команд. Далее, в зависимости от состояния списка свободных функциональных модулей, команды и значения операндов могут быть помещены в очередь распределения. 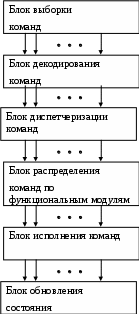 Рис. 1.2. Организация параллельного выполнения команд в суперскалярном процессоре Блок исполнения состоит из функциональных модулей. Примерами ФМ могут служить целочисленные операционные блоки, блоки умножения и сложения с плавающей запятой, блок доступа к памяти. Блок обновления состояния записывает и анализирует результат исполнения команды. При этом обеспечивается учет полученного результата теми командами в очередях распределения, для которых это результат выступает в качестве одного из операндов. | ||||||||
