Курс. Курс лекций по ар-реКомп. Курс лекций по дисциплине Архитектура компьютеров для студентов, обучающихся по направлению 230700. 62 Прикладная информатика
 Скачать 1.69 Mb. Скачать 1.69 Mb.
|

|
Лекция 3 Вычислительные системы класса MIMD Вопросы: Симметричные мультипроцессорные системы Системы с неоднородным доступом к памяти Системы с массовой параллельной обработкой Кластерные вычислительные системы MIMD-системы обладают большой гибкостью. Они могут функционировать и как высокопроизводительные однопользовательские системы, и как и многопрограммные ВС, выполняющие множество задач параллельно. MIMD-системы состоят из процессорных элементов (ПЭ), каждый из которых выполняет свою программу достаточно независимо от других ПЭ, тем не менее, взаимодействуя с ними. По варианту реализации такого взаимодействия MIMD-системы разделяются на ВС с общей памятью и системы с распределенной памятью. В системах с общей памятью, которые характеризуются как сильно связанные системы, имеется общая память данных и команд, доступная всем ПЭ. К этому типу относятся симметричные мультипроцессорные системы и системы с неоднородным доступом к памяти. В системах с распределенной памятью, называемых также слабо связанными системами, вся память распределена между ПЭ, и каждый блок памяти доступен только “своему“ процессору. Представителями систем этого типа являются системы с массовым параллелизмом и кластерные системы. 3.1. Симметричные мультипроцессорные системы Симметричные мультипроцессорные системы (SMP - Symmetric Multi-Processing) можно определить как вычислительные системы, обладающие следующими характеристиками: имеются два или более процессоров сопоставимой производительности; процессоры совместно используют основную память и работают в едином виртуальном и физическом пространстве; все процессоры связаны между собой посредством шины или по иной схеме так, что время доступа к памяти любого из них одинаково; все процессоры разделяют доступ к устройствам ввода/вывода либо через одни и те же каналы, либо через разные каналы, обеспечивающие доступ к одному и тому же внешнему устройству; все процессоры способны выполнять одинаковые функции; любой из процессоров может обслуживать внешние прерывания; вычислительная система управляется интегрированной операционной системой, которая организует и координирует взаимодействие между процессорами и программами на уровне заданий, задач, файлов и элементов данных. SMP-системы называются симметричными именно в связи с функциональной одинаковости составляющих ее ПЭ. Однако на время загрузки один из процессоров получает статус ведущего. Применение SMP-систем целесообразно в тех случаях, когда решаемая задача может быть разделена на подзадачи, которые могли быть реализованы параллельно. На рис.1.6 в общем виде представлена организация симметричной мультипроцессорной системы. Типовая SMP-система содержит от двух до 32 идентичных процессоров. Это могут быть CISC- или RISC-процессоры. Каждый процессор снабжен локальной кэш-памятью. Все процессоры ВС имеют равноправный доступ к разделяемым основной памяти и устройствам ввода/вывода. Такая возможность обеспечивается коммуникационной системой. Обычно процессоры взаимодействуют между собой через основную память (область общих данных). В некоторых SMP-системах предусматривается также прямой обмен сигналами между процессорами. Память системы обычно строится по модульному принципу и организована так, что допускает одновременное обращение к ее модулям. 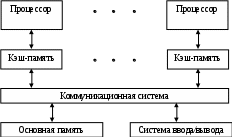 Рис.1.6. Организация симметричной мультипроцессорной системы Поскольку процессоры одновременно работают с данными, хранящимися в основной памяти, в SMP-системах обязательно должен быть механизм обеспечения когерентности данных. Когерентность данных означает, что в любой момент времени для каждого элемента данных в любом модуле памяти существует только одно его значение, несмотря на возможное одновременное существование несколько копий этого элемента данных, расположенных в разных видах памяти и обрабатываемых разными процессорами. В современных SMP-системах когерентность данных обеспечивается аппаратными средствами. Механизм когерентности является критичным для эффективной параллельной работы SMP-системы и должен иметь малое время задержки. Типичные SMP-системы в качестве аппаратной реализации механизма поддержки когерентности используют шину слежения (snoopy bus). Для того чтобы данные в кэш-памяти всех процессоров оставались когерентными, каждый процессор отслеживает передачу данных по шине, осуществляя поиск тех операций считывания и записи между другими процессорами и основной памятью, которые влияют на содержимое его собственной кэш-памяти. Если процессор "В" запрашивает ту часть основной памяти, которая обрабатывается процессором "А", то процессор "А" перехватывает этот запрос и помещает свои значения области памяти на шину, где "В" их считывает. Когда процессор "А" записывает измененное значение обратно из своей кэш-памяти в основную память, то все другие процессоры “видят” как эта запись проходит по шине и удаляют устаревшие данные из своей кэш-памяти. Недостатком данной архитектуры является необходимость организации канала процессоры - память с очень высокой пропускной способностью. Важным аспектом архитектуры SMP-систем является способ взаимодействия процессоров с общими ресурсами (памятью и системой ввода-вывода). С этих позиций можно выделить следующие виды архитектуры этих систем 16: с общей шиной и временным разделением; с коммутатором в виде многошинной перекрестной структуры; с многопортовой памятью; с централизованным управлением. 3.2. Системы с неоднородным доступом к памяти Системы с неоднородным доступом к памяти (NUMA - non uniform memory access) состоят (рис. 1.7) из однородных базовых узлов (плат), содержащих небольшое число процессоров с модулями двухуровневой кэш-памяти (L1 и L2), блок основной памяти, локальную шину. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной. В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитекту- ре cc-NUMA (cache-coherent NUMA) – кэш-когерентным доступом к неоднородной памяти. Обычно вся система работает под управлением единой ОС, как в SMP-системах. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000). Поддержание единого адресного пространства выражается в том, что каждая ячейка любой локальной основной памяти имеет уникальный системный адрес. Когда процессор инициирует доступ к памяти и нужная ячейка не представлена в его локальной кэш-памяти, то кэш-память второго уровня (L2) этого процессора организует операцию выборки. 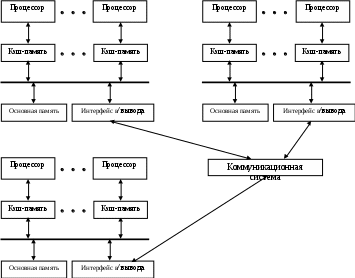 Рис.1.7. Организация системы с неоднородным доступом к памяти Если содержимое нужной ячейки находится в локальной основной памяти, выборка производится с использованием локальной шины. Если же требуемая ячейка находится в памяти другого узла, то автоматически формируется запрос по коммуникационной системе на нужную локальную шину и уже по ней к подключенному к данной локальной шине кэшу. Необходимо отметить, что каждый узел содержит справочник, где хранится информация о местоположении в системе каждой составляющей единого адресного пространства, а также о состоянии кэш-памяти. Обеспечение когерентности модулей кэш-памяти является одной из основных проблем NUMA-систем. 3.3. Системы с массовой параллельной обработкой Системы с массовой параллельной обработкой (МРР - Massively Parallel Processing) состоят (рис. 1.8) из нескольких однородных вычислительных узлов, включающих один или несколько процессоров, локальную для каждого узла память, коммуникационный процессор или сетевой адаптер. Узлы объединяются через высокоскоростную сеть или коммутатор. Основной признак МРР-систем – количество входящих в них процессоров, которое может быть от десятков до нескольких тысяч (так, вычислительная система Intel Paragon содержит 6768 процессоров). Главными особенностями МРР-систем являются: стандартные микропроцессоры; физически распределенная память; сеть соединений с высокой пропускной способностью и малыми задержками; хорошая масштабируемость; асинхронность работы узлов при использовании пересылки сообщений; реализация программы в виде множества процессов, имеющих отдельные адресные пространства; наличие единственного управляющего устройства (процессора), который формирует очередь заданий, распределяет их между множеством подчиненных ему устройств, контролирует ход выполнения заданий и работу подчиненных процессоров. Можно считать, что на центральном процессоре выполняется ядро операционной системы (планировщик заданий), а на подчиненных ему – приложения. Подчиненность между процессорами может быть реализована как на аппаратном, так и программном уровне. Взаимосвязи между узлами (и между копиями ОС, принадлежащими каждому узлу) не требуют аппаратно поддерживаемой когерентности, так как каждый узел имеет собственную ОС и, следовательно, свое уникальное адресное пространство физической памяти. Когерентность реализуется программными средствами, с использованием техники передачи сообщений. 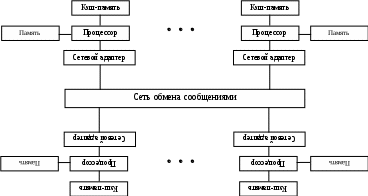 Рис.1.8. Структура вычислительной системы с массовой параллельной обработкой Задержки, которые присущие программной поддержке когерентности на основе сообщений, обычно в сотни и тысячи раз больше, чем те, которые получаются в системах с аппаратными средствами. С другой стороны, их реализация значительно менее сложная. В МРР-системах программная поддержка когерентности используется именно для того, чтобы обеспечить подсоединение возможно большего число процессоров (сотни и тысячи узлов). Известно, что производительность МРР-систем весьма чувствительна к задержкам, определяемым программной реализацией протоколов и аппаратной реализацией среды передачи сообщений (будь то коммутатор, или сеть). Вообще говоря, одним из необходимых элементов организации функционирования МРР-систем является распределение данных для того, чтобы минимизировать трафик между узлами. Эффективность распараллеливания во многих случаях сильно зависит от топологии соединения процессорных узлов. Наиболее эффективная топология по принципу “каждый с каждым“ технически трудно реализуется. Как правило, процессорные узлы в МРР-системах образуют либо двухмерную решетку или гиперкуб. В связи с тем, что в МРР-системах нет аппаратной поддержки ни для разделенной памяти, ни для когерентности кэшей, подсоединить большое число процессоров очень просто. Такие системы обеспечивают высокий уровень производительности для приложений с большой интенсивностью вычислений, со статистически разделяемыми данными и с минимальным обменом данными между узлами. Недостатком МРР-систем может считаться наличие единственного управляющего устройства (процессора), при выходе из строя которого вся система оказывается неработоспособной. Следует отметить также, что в настоящее время существует немного приложений (задач), которые могут эффективно выполняться на МРР-системе. 3.4. Кластерные вычислительные системы Под кластером понимается группа взаимосвязанных соединенных вычислительных систем (узлов), работающих совместно и составляющих единый вычислительный ресурс. Кластер состоит из двух или более узлов, удовлетворяющих следующим требованиям: каждый узел работает со своей копией ОС; каждый узел работает со своей копией приложения; узлы делят общий пул других ресурсов, таких как накопители на дисках. В качестве узла кластера может выступать как однопроцессорная ВМ, так и ВС типа SMP или MPP. Важно лишь то, что каждый узел в состоянии функционировать самостоятельно и отдельно от кластера. В плане архитектуры суть кластерных вычислений сводится к объединению нескольких узлов высокоскоростной сетью. Узлы кластеров могут содержать как одинаковые ВС (гомогенные кластеры), так и разные (гетерогенные кластеры). По своей архитектуре кластерная ВС является слабо связанной системой. Кластер на уровне аппаратного обеспечения представляет собой совокупность независимых вычислительных систем, объединенных сетью. При соединении машин в кластер почти всегда поддерживаются прямые межмашинные связи. Эти связи могут быть простыми, основывающимися на одной из стандартных сетевых технологий (например, Ethernet), или сложными, на основе высокоскоростных сетей с пропускной способностью в сотни мегабитов в секунду. Узлы кластера контролируют работоспособность друг друга и обмениваются с этой целью специальными сигналами. Эти сигналы, передаваемые между узлами, являются подтверждениями их нормального функционирования. Важное значение для функционирования кластера имеет специализированное программное обеспечение, на которое возлагается задача бесперебойной работы при отказе одного или нескольких узлов. Такое программное обеспечение производит перераспределение вычислительной нагрузки при отказе одного или нескольких узлов в кластере, восстановление вычислений при сбое в узле, а также поддерживает единую файловую систему при наличии совместно используемых дисков. Лекция 4 . Системный блок вычислительной системы Вопросы: 1. Взаимодействие устройств 2.Как CPU(APU) реагирует на прерывания 3. Определение используемых в системе прерываний. 4. Каскадные IRQ 5. Передача информации вслед за IRQ. Порты ввода-вывода С 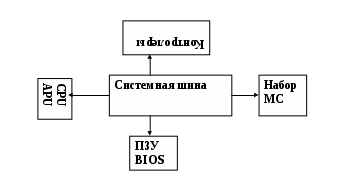 истемный блок содержит сложные микросхемы такие как CPU,APU,GPU, модули памяти ОЗУ (RAM) и ПЗУ с Bios,различные контролеры-COM,LPT,USB,LAN и т.д. . Все это может быть интегрировано в материнскую плату или быть представлено отдельными блоками. Кроме того на материнской плате находятся слоты расширения, куда включаются разнообразные платы и контролеры, такие как модемы, сетевые адаптеры или видео карты. Эти устройства расширяют устройство компьютера. В любой материнской плате есть еще и шины – которые служат для подключения каждого компонента и обеспечения взаимодействия микросхем. Материнская плата содержит множество микросхем подключенных к разным шинам, которые позволяют им взаимодействовать. Основная шина называется системной. Оно объединяет ЦПУ,ОЗУ, BIOS и другие микросхемы в набор микросхем ( Чипсет) Системная шина которая объединяет СPU(APU), модули RAM, ПЗУ BIOS и другие быстродействующие микросхемы которые характеризуются высшей скоростью работы. Долгое время системной шины в зависимости от типа компьютера и скорости CPU(APU) работали с тактовой частотой от 66 – 100 Мгц. В современных компьютерах системная шина работает на частоте ,более 2000 Мгц. Тем не менее системная шина значительно уступает по скорости процессору. Разработчики аппаратных средств для сведения к минимуму ограничения быстродействия материнской платы применяют р  азличные методы ускорения работы и повышения производительности системной шины. В большинстве компьютеров используют слоты расширения PCI Express и PCI (Peripheral Component Interconnect – взаимное соединение компонентов). Шина PCI и подключаемые к ней устройства обычно работают с тактовой частотой 33-66 МГц . Подключение к слоту устройств должно быть способным взаимодействовать с CPU(APU). Для соединения более медленной шины PCI с системной шиной, которая обеспечивает взаимодействие ЦПУ и устройств расширения в материнской плате используется устройство называемое “Северным мостом” Северный мост может также соединять шину PCI и AGP c системной шиной. AGP – accelerate grafics port реализует 100 МГц соединения с видеокартой. AGP-является модификацией локальной шиной PCI и предназначена для подключения видео-акселераторов. Шина PCI Express нацелена на использование только в качестве локальной шины. Так как программная модель PCI Express во многом унаследована от PCI, то существующие системы и контроллеры могут быть доработаны для использования шины PCI Express заменой только физического уровня, без доработки программного обеспечения. Высокая пиковая производительность шины PCI Express позволяет использовать её вместо шин AGP и тем более PCI и PCI-X. Де-факто PCI Express заменила эти шины в персональных компьютерах. Взаимодействие устройств Внутри системного блока устройства взаимодействуют посредством обмена электрическими сигналами. Например, при перемещении мыши ее электроника передает сигналы CPU(APU). Когда сетевой контролер принимает данные, он также передает сигналы CPU(APU) и т.д. Устройства отправляют CPU(APU) сигналы по специальным линиям запроса на прерывание IRQ (interrupt-request) – уведомляя процессор, что требуется его внимание. Прерывание ( interrupt) — сигнал, сообщающий процессору о наступлении какого-либо события. При этом выполнение текущей последовательности команд п  риостанавливается и управление передаётся обработчику прерывания, который реагирует на событие и обслуживает его, после чего возвращает управление в прерванный код. Название IRQ связано с тем, что при появлении на одной из линий сигнала, CPU(APU) “прерывает” текущие операции, для обслуживания устройства, которое генерирует прерывание. Каждое устройство взаимосвязаное с CPU(APU) посредством прерываний, обладает собственной линией IRQ. Мышь Прерывания не является обязательным системным ресурсом для устройства ,но его наличие значительно оптимизирует работу компьютеров и позволяет реализовать механизм защиты памяти. Современный компьютер поддерживает 24 линии IRQ. В табл.1 перечислены первые 16 устройств, которые традиционно используют определенные линии IRQ.
Табл.1 Как CPU(APU) реагирует на прерывания Программа – это реализация алгоритма посредством команд, выполняемых CPU(APU) для решения некоторой задачи. Предположим, вы используете браузер для навигации в WEB, CPU(APU) в свою очередь затрачивает большую часть времени на выполнение команд браузера для отображения текста и графики. Процессор занят обработкой команд, но компьютер реагирует на движение мыши, перемещая курсор на экране. Для этого CPU(APU) реагирует на прерывания, генерируемые мышью. Когда CPU(APU) обнаруживает прерывания, он останавливает выполнение текущей задачи для выполнения команд относящихся к определенному устройству. Последовательность команд, выполняемых CPU(APU) для обнаружения и обслуживания устройства называется обработчиком прерываний устройства. После обработки прерываний CPU(APU) продолжает выполнение предыдущей задачи. Когда процессор принимает прерывания на линии 12, не предполагается, что оно вызвано мышью. Более того, CPU(APU) не имеет значения какое устройство генерирует событие. Вместо этого процессор содержит таблицу адресов памяти, в которой каждому прерыванию соответствует запись. Когда возникает прерывание CPU(APU) , начинает выполнение команд обработчика прерываний, которое занимает адрес памяти соответствующий ему. Процессору безразлично, для какого устройства он выполняет команды.   Обработчик прерываний Обработчик прерываний   0200 0200 Область памяти Не все устройства подключаемые к компьютеру требуют наличия IRQ. При установке устройств в системный блок его подключают к шине определенного типа. Шина – это просто набор проводников. Устройство включаемое в слот расширения обычно требует собственной линии прерываний. Возможен и другой вариант, когда устройство подключается к универсальной последовательной шине USB (universal serial bus) или SCSI-шине. В этом случае шина используется для взаимодействия с контроллером (электронной схемой (МС), которая управляет шиной). Контроллер в свою очередь исполняет прерывание для взаимодействия с CPU(APU)          Мышь DVD A:B Модем НDD,SSD Выбор линии IRQ для устройства, которые взаимодействуют с CPU(APU) . Устройства, которые взаимодействуют с CPU(APU) , исключая прерывания для обладающих собственной линией IRQ. При попытке использования одной и той же линии IRQ двумя устройствами возникает конфликт, который не позволяет функционировать обоим устройствам. Их называют IRQ-конфликтами. Методика выбора IRQ для устройства зависит от его типа. В некоторых случаях использует переключатель, которые находятся на плате устройства. Иногда это перемычки - их паяют или используют специальные программы. Чтобы избежать конфликтов при установке нового устройства нужно знать как оно функционирует с CPU(APU) . Если устройство подключено к USB или SCSI,SATA шине для него не нужно указывать линию IRQ. Такие устройства самоконфигурируются, чтобы использовать ресурсы незанятые системой. При подключении устройства не Plug and Play в слот материальной платы, необходимо определить какие прерывания достигаются в данный момент, а затем сконфигурировать устройство таким образом, чтобы оно использовало доступную линию IRQ. Определение используемых в системе прерываний. Сведения о закрепленных прерываниях можно получить с помощью утилиты MS Windows «Сведения о системе». Так же существует множество других утилит позволяющих решить данную проблему(Evererest, AIDA, Sisandra и др.) .
Каскадные IRQ. Первые компьютеры архитектуры x86 поддерживали 8 линий прерываний . С появлением CPU 80286 был добавлен 2-ой контроллер прерываний , что обеспечивает поддержку 16 линий прерываний . В таблице прерываний указано , что когда CPU(APU) принимает прерывание по линии 2 , CPU(APU) распознаёт , что IRQ соответствует 2-му котроллеру , а следовательно прерываниям от 8-15. 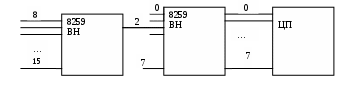 После приёма сигнала прерывания по линии 2 или 9 процессор анализирует порты ввода\вывода OxAO и OxA1 , чтобы определить какое прерывание на 2м контроллере в действительности. Передача информации вслед за IRQ. Порты ввода-вывода С помощью прерываний устройство сигнализирует CPU(APU) о том , что для ни необходимо выполнить определённые действия . После получения запроса на прерывание , процессор запускает коды соответствующего обработчика. Обработчик прерываний принимает от устройства информацию об операциях , которое CPU(APU) выполняет для устройства. Например , когда перемещаем мышь , её электроника генерирует прерывание по линии 12. Тоже происходит при щелчках на кнопки мыши. Обработчик прерываний должен определить какое действие с мышью вызвало прерывание. Для передачи этой информации обработчик прерываний использует специальные. область памяти, называемые портами ввода\вывода ( I\O). Адрес порта используемого для взаимодействия с CPU(APU) зависит от типа устройства. Каждое устройство используещее прерывание обладает уникальным адресом портов . Например клавиатура: 0060-сброс контроллера клавиатуры, 0064-составляет коды контроллера. Уникальные адреса также необходимы устройствам как и уникальные линии IRQ. Если два устройства используют один адрес порта , возникает ошибка, которая исключает их правильное функционирование. При установке платы расширения, которая не поддерживает автоматически конфигурируемые устройства нужно обеспечить, чтобы устанавливаемые параметры порта устройства не конфликтовали с существующими устройствами. Предпринимаемые для установки адресов порта действия зависят от типа устройства. В одних устройствах используется переключатели , в других джамперы, в третьих программные средства. Порты ввода-вывода являются обязательными системными ресурсами для любых компьютерных контролеров и устройств через которые обеспечивается их взаимодействие с CPU(APU). Порты адресуются в архитектуре x86 c 0 до 65535. Определении адресов портов использующих системой. Сведения о закрепленных портах ввода-вывода можно получить с помощью утилиты MS Windows «Сведения о системе». Так же существует множество других утилит позволяющих решить данную проблему(Evererest, AIDA, Sisandra и др.) . Ресурсы аппарата X000-000F прямой доступ к памяти DMA …………………. …………………..    I/O IRQ  Обмен большими объемами данных с устройством. Если устройства требуют обмена небольшими объемами информации, оно может взаимодействовать с обработчиком прерываний посредством портов ввода/вывода. Порт идеально подходит для мыши, которая движется предавая небольшой объем информации. ( величина перемещения или щелчок, двойной щелчок – распознается по интервалу времени между двумя обычными щелчками). Устройства, которые обрабатываются большие массивы данных, такие как DVD,BLU-RAY,HDD,SSD обычно использует стандартные области памяти для хранения информации, с которой привод читает или в которую записывает. Начальный адрес такой области называется базовым адресом устройства. При установке нового устройства может возникнуть необходимость указать уникальный базовый адрес ОЗУ, которое не используются другими устройствами. Отобразить области памяти можно с помощью утилиты «Сведения о системе». Так же существует множество других утилит позволяющих решить данную проблему(Evererest, AIDA, Sisandra и др.) .  Прямой доступ к памяти DMA. Как уже говорилось выше, устройства с помощью прерываний уведомляют CPU(APU) о необходимости выполнения для них некоторых действий. Количество выполняемых операций зависит от типа устройства. Для процессора важно быстро завершить обработку прерывания, чтобы продолжать выполнение предыдущей задачи. Если прерывание сгенерировала мышь, CPU(APU) обычно быстро завершает его обработку. Однако операции чтения/записи (R/W) дисковым накопителем требует передачи большого объема данных между ОЗУ и устройствам, что может потребовать значительных затрат времени процессора. Чтобы повысить эффективность использования CPU(APU) разработали специальную микросхему DMA (direct memory acсses – прямой доступ к памяти)– называемую контроллер DMA. CPU(APU) может контролирующую ее функционирование, чтобы обеспечить обмен данными между ОЗУ и устройством. Используя микросхему DMA для перемещения данных, CPU(APU) упрощает себе задачу передачи каждого бита данных. Это позволяет CPU(APU) выполнять другие задачи, пока микросхема DMA контролирует перемещение данных. Например, для чтения информации с диска в память CPU(APU) может конфигурировать микросхему DMA, указав ей начальный адрес сектора, количество секторов и область памяти, которую данные должны занять. В свою очередь контроллер DMA будет выполнять операции с диском, пока CPU(APU) занят другими задачами. Когда контроллер DMA завершит свою задачу, он посредством прерывания сообщит об этом CPU(APU) . CPU(APU) может проанализировать порты DMA, чтобы определить состояние выполняемой операции. Большинство современных компьютеров имеет 2 микросхемы DMA, которые подобно контроллеру прерываний функционируют каскадно. Устройства, которые используют DMA можно увидеть в “Сведения о системе” . Так же существует множество других утилит позволяющих решить данную проблему(Evererest, AIDA, Sisandra и др.) . Ресурсы аппаратуры | | -Канал DMA Автоматическая конфигурация устройства Plug- and –Play Несложно догадаться, что необходимость присвоения верных значений параметров для прерываний, портов ввода/вывода и базовых адресов может сделать установку аппаратного средства сложной задачей. Пользователи называют аппаратные средства, которые требуют ручной настройки подобных параметров – традиционными устройствами. К таким устройствам можно отнести сетевой адаптер, звуковую карту и т.д. Часто при попытке установки традиционного устройства возникает аппаратный конфликт, пользователю остается лишь отказаться от использования нового устройства. Устранение потенциальных конфликтов может оказаться непосильной задачей для многих. Чтобы упростить процесс установки плат расширения изготовители ПК и комплектующих, а также разработчики ОС, совместно выработали спецификацию конфигурации устройств (Plug-and-Play) включай и работай. Обычно при подключении автоматически конфигурируемого устройства, оно взаимодействует с BIOS, другими устройствами и ОС, чтобы определить какие прерывания, порты и области памяти, доступные в данный момент. Затем устройство выбирает необходимые ему ресурсы из доступных. После этого устройство уведомляет остальные аппаратные средства о сделанном выборе. Это избавляет пользователя от необходимости выявлять свободные ресурсы и конфигурировать устройства вручную. Таким образом спецификация Р & Р существенно упрощает установку аппаратных устройств. К сожалению, традиционные устройства не участвуют в коммуникации автоматически конфигурируемых устройств, направленной на координацию использующихся ресурсов. Устройства, соответствующие Р & Р могут выбирать ресурсы, уже занятые традиционными устройствами. Когда возникает такие конфликты, их следует устранять, т.к оба устройства не могут нормально функционировать. Устранение конфликтов устройств Мы уже знаем, что когда 2 устройства пытаются используя одну линию IRQ возникает конфликт прерываний. Подобно этому конфликт возникает когда 2 устройства имеют один адрес порта или базовый адрес памяти. Обычно в таких случаях одно или оба устройства оказываются неработоспособными. Часто диспетчер устройств в MS WINDOWS обнаруживает конфликты, отображает индикатор конфликта (правой кнопкой мыши по ярлыку «Мой компьютер» , появляется окно свойства-> система-> устройства -> по типам) Windows указывает конфликты устройств с помощью жёлтого значка с восклицательным знаком. Когда возникают подобные конфликты, нужно изменить настройки использования ресурсов для одного или двух конфликтующих устройств. Для этого в зависимости от типа устройства используются: переключатели, перемычки или программные средства. Зарезервировать ресурсы, используемые традиционными устройствами, можно с помощью программы Setup редактирующей специальную область памяти ,которая называется CMOS память. Использование диспетчера устройств для контроля или изменения используемых устройствами ресурсов. Когда возникает аппаратный конфликт, просмотреть информацию об используемых устройствах можно с помощью Диспетчера устройств (правой кнопкой на Мой компьютер ->свойства -> Device Manager), выбрать устройства и дважды щёлкнуть левой кнопкой мыши Если устройство использует ресурсы, такие, как прерывания или адрес I/О диалоговое окно, содержит вкладку Ресурсы. Её необходимо открыть. Изменить настройки можно с помощью перемычек, джамперов или программных средств. Чтобы быстро определить доступные ресурсы, можно воспользоваться утилитой Информация о системе. В некоторых случаях изменять параметры используемых ресурсов можно с помощью Диспетчера устройств в окне Ресурсы. Для этого необходимо 1)Сбросить флаг «Автоматическая настройка» 2)Затем щёлкнуть на кнопке Изменить настройку. Если утилита позволяет изменять параметры используемых устройствами ресурсов, отобразится соответствующёё диалоговое окно. В противном случае будет выведено окно с сообщением о том, что изменить прерывание устройства нельзя….. Обнаружение устройств использующие одинаковые номера прерываний Если просмотреть настройки IRQ с помощью утилиты “Информация о системе” можно заметить, что несколько устройств используют один и тот же номер прерывания, что казалось бы нарушает принципы обслуживания устройств. В действительности подключаемые к шине PCI устройства довольно часто осуществляют совместное использование прерываний. Когда 2 и более устройств используют одно и тоже прерывание , система выстраивает коды обработчика в цепочку. Сначала попытка ответить первому, затем второму и т.д. Обработчик прерываний (набор команд выполняемых ПК в случае прерывания) анализирует состояние различных портов чтобы определить условие когда прерывание сгенерировало обслуживающее устройство. ОС продолжает последовательно выполнять обработчики, пока один из них не сможет обслуживать прерывания. Даже если устройство поддерживает совместное использование прерываний нужно попытаться присвоить ему неиспользуемый номер прерывания, чтобы упростить процесс и повысить быстродействие системы. Т.к. идентификация устройства, вызвавшего прерывание занимает некоторое время, последовательный перебор прерываний снижает быстродействие системы. |
