курсовая6. Курсовая работа Кредитный рынок и его место в системе макроэкономического кругооборота
 Скачать 340.59 Kb. Скачать 340.59 Kb.
|

Реализация алгоритма арифметического кодирования:Ниже показан фрагмент псевдокода процедур кодирования и декодирования. Символы в нем нумеруются как 1,2,3... Частотный интервал для i-го символа задается от cum_freq[i] до cum_freq[i-1]. Пpи убывании i cum_freq[i] возрастает так, что cum_freq[0] = 1. (Причина такого "обpатного" соглашения состоит в том, что cum_freq[0] будет потом содеpжать ноpмализующий множитель, котоpый удобно хpанить в начале массива). Текущий pабочий интеpвал задается в [low; high] и будет в самом начале pавен [0; 1) и для кодиpовщика, и для pаскодиpовщика. Алгоритм кодирования: С каждым символом текста обpащаться к пpоцедуpе encode_symbol(). Пpовеpить, что "завеpшающий" символ закодиpован последним. Вывести полученное значение интеpвала [low; high). encode_symbol(symbol, cum_freq) { … range = high - low high = low + range*cum_freq[symbol-1] low = low + range*cum_freq[symbol] … } 2.5 . Сжатие данных с использованием преобразования Барроуза-Вилер Майкл Барроуз и Давид Вилер (Burrows-Wheeler) в 1994 году предложили свой алгоритм преобразования (BWT). Этот алгоритм работает с блоками данных и обеспечивает эффективное сжатие без потери информации. В результате преобразования блок данных имеет ту же длину, но другой порядок расположения символов. Алгоритм тем эффективнее, чем больший блок данных преобразуется (например, 256-512 Кбайт). Последовательность S, содержащая N символов ({S(0),… S(N-1)}), подвергается N циклическим сдвигам (вращениям), лексикографической сортировке, а последний символ при каждом вращении извлекается. Из этих символов формируется строка L, где i-ый символ является последним символом i-го вращения. Кроме строки L создается индекс I исходной строки S в упорядоченном списке вращений. Существует эффективный алгоритм восстановления исходной последовательности символов S на основе строки L и индекса I. Процедура сортировки объединяет результаты вращений с идентичными начальными символами. Предполагается, что символы в S соответствуют алфавиту, содержащему K символов. Для пояснения работы алгоритма возьмем последовательность S= “abraca” (N=6), алфавит X = {`a','b','c','r'}. 1. Формируем матрицу из N*N элементов, чьи строки представляют собой результаты циклического сдвига (вращений) исходной последовательности S, отсортированных лексикографически. По крайней мере одна из строк M содержит исходную последовательность S. Пусть I является индексом строки S. В приведенном примере индекс I=1, а матрица M имеет вид:
2. Пусть строка L представляет собой последнюю колонку матрицы M с символами L[0],…,L[N-1] (соответствуют M[0,N-1],…,M[N-1,N-1]). Формируем строку последних символов вращений. Окончательный результат характеризуется (L,I). В данном примере L='caraab', I =1. Процедура декомпрессии использует L и I. Целью этой процедуры является получение исходной последовательности из N символов (S). 1. Сначала вычисляем первую колонку матрицы M (F). Это делается путем сортировки символов строки L. Каждая колонка исходной матрицы M представляет собой перестановки исходной последовательности S. Таким образом, первая колонка F и L являются перестановками S. Так как строки в M упорядочены, размещение символов в F также упорядочено. F='aaabcr'. 2. Рассматриваем ряды матрицы M, которые начинаются с заданного символа ch. Строки матрицы М упорядочены лексикографически, поэтому строки, начинающиеся с ch упорядочены аналогичным образом. Определим матрицу M', которая получается из строк матрицы M путем циклического сдвига на один символ вправо. Для каждого i=0,…, N-1 и каждого j=0,…,N-1, M'[i,j] = m[i,(j-1) mod N] В рассмотренном примере M и M' имеют вид
Подобно M каждая строка M' является вращением S, и для каждой строки M существует соответствующая строка M'. M' получена из M так, что строки M' упорядочены лексикографически, начиная со второго символа. Таким образом, если мы рассмотрим только те строки M', которые начинаются с заданного символа ch, они должны следовать упорядоченным образом с учетом второго символа. Следовательно, для любого заданного символа ch, строки M, которые начинаются с ch, появляются в том же порядке что и в M', начинающиеся с ch. В нашем примере это видно на примере строк, начинающихся с `a'. Строки `aabrac', `abraca' и `acaabr' имеют номера 0, 1 и 2 в M и 1, 3, 4 в M'. Используя F и L, первые колонки M и M' мы вычислим вектор Т, который указывает на соответствие между строками двух матриц, с учетом того, что для каждого j = 0,…,N-1 строки j M' соответствуют строкам T[j] M. Если L[j] является к-ым появлением ch в L, тогда T[j]=1, где F[i] является к-ым появлением ch в F. Заметьте, что Т представляет соответствие один в один между элементами F и элементами L, а F[T[j]] = L[j]. В нашем примере T равно: (4 0 5 1 2 3). 3. Теперь для каждого i = 0,…, N-1 символы L[i] и F[i] являются соответственно последними и первыми символами строки i матрицы M. Так как каждая строка является вращением S, символ L[i] является циклическим предшественником символа F[i] в S. Из Т мы имеем F[T[j]] = L[j]. Подставляя i =T[j], мы получаем символ L[T(j)], который циклически предшествует символу L[j] в S. Индекс I указывает на строку М, где записана строка S. Таким образом, последний символ S равен L[I]. Мы используем вектор T для получения предшественников каждого символа: для каждого i = 0,…,N-1 S[N-1-i] = L[Ti[I]], где T0[x] =x, а Ti+1[x] = T[Ti[x]. Эта процедура позволяет восстановить первоначальную последовательность символов S (`abraca'). Последовательность Ti[I] для i =0,…,N-1 не обязательно является перестановкой чисел 0,…,N-1. Если исходная последовательность S является формой Zp для некоторой подстановки Z и для некоторого p>1, тогда последовательность Ti[I] для i = 0,…,N-1 будет также формой Z'p для некоторой субпоследовательности Z'. Таким образом, если S = `cancan', Z = `can' и p=2, последовательность Ti[I] для i = 0,…,N-1 будет [2,4,0,2,4,0]. Описанный выше алгоритм упорядочивает вращения исходной последовательности символов S и формирует строку L, состоящую из последних символов вращений. Для того, чтобы понять, почему такое упорядочение приводит к более эффективному сжатию, рассмотрим воздействие на отдельную букву в обычном слове английского текста. Возьмем в качестве примера букву “t” в слове `the' и предположим, что исходная последовательность содержит много таких слов. Когда список вращений упорядочен, все вращения, начинающиеся с `he', будут взаимно упорядочены. Один отрезок строки L будет содержать непропорционально большое число `t', перемешанных с другими символами, которые могут предшествовать `he', такими как пробел, `s', `T' и `S'. Аналогичные аргументы могут быть использованы для всех символов всех слов, таким образом, любая область строки L будет содержать большое число некоторых символов. В результате вероятность того, что символ `ch' встретится в данной точке L, весьма велика, если ch встречается вблизи этой точки L, и мала в противоположном случае. Это свойство способствует эффективной работе локально адаптивных алгоритмов сжатия, где кодируется относительное положение идентичных символов. В случае применения к строке L, такой кодировщик будет выдавать малые числа, которые могут способствовать эффективной работе последующего кодирования, например, посредством алгоритма Хафмана. 2.6 Алгоритм Зива-Лемпеля В 1977 году Абрахам Лемпель и Якоб Зив предложили алгоритм сжатия данных, названный позднее LZ77. Этот алгоритм используется в программах архивирования текстов compress, lha, pkzip и arj. Модификация алгоритма LZ78 применяется для сжатия двоичных данных. Эти модификации алгоритма защищены патентами США. Алгоритм предполагает кодирование последовательности бит путем разбивки ее на фразы с последующим кодированием этих фраз. Позднее появилась модификация алгоритма LZ78 - Lempel-Ziv Welsh (использует словарь для байтов для потоков октетов). Суть алгоритма заключается в следующем: Если в тексте встретится повторение строк символов, то повторные строки заменяются ссылками (указателями) на исходную строку. Ссылка имеет формат <префикс, расстояние, длина>. Префикс в этом случае равен 1. Поле расстояние идентифицирует слово в словаре строк. Если строки в словаре нет, генерируется код символ вида <префикс, символ>, где поле префикс =0, а поле символ соответствует текущему символу исходного текста. Отсюда видно, что префикс служит для разделения кодов указателя от кодов символ. Введение кодов символ, позволяет оптимизировать словарь и поднять эффективность сжатия. Главная алгоритмическая проблема здесь заключатся в оптимальном выборе строк, так как это предполагает значительный объем переборов. Рассмотрим пример с исходной последовательностью U=0010001101 (без надежды получить реальное сжатие для столь ограниченного объема исходного материала). Введем обозначения: P[n] - фраза с номером n. C - результат сжатия. Разложение исходной последовательности бит на фразы представлено в таблице ниже.
P[0] - пустая строка. Символом « . » (точка) обозначается операция объединения (конкатенации). Формируем пары строк, каждая из которых имеет вид (A.B). Каждая пара образует новую фразу и содержит идентификатор предыдущей фразы и бит, присоединяемый к этой фразе. Объединение всех этих пар представляет окончательный результат сжатия С. P[1]=P[0].0 дает (00.0), P[2]=P[1].0 дает (01.0) и т.д. Схема преобразования отражена в таблице ниже.
Все формулы, содержащие P[0] вовсе не дают сжатия. Очевидно, что С длиннее U, но это получается для короткой исходной последовательности. В случае материала большего объема будет получено реальное сжатие исходной последовательности.
3.1. Алгоритм JPEG Сжатие с потерями – это представление, которое позволяет воспроизводить нечто «очень похожее» на первоначальный набор данных. Преимущество использования методов сжатия с потерями заключается в том, что они зачастую позволяют получать намного более компактные представления данных по сравнению с методами сжатия без потерь. Чаще всего методы сжатия с потерями применяются для обработки изображений, звуковых файлов и видео. Сжатие с потерями в этих областях может оказаться уместным благодаря тому, что человек воспринимает битовую комбинацию цифрового изображения/звука не с «побитовой» точностью, а скорее оценивает музыку или изображение в целом. JPEG (произносится англ. Joint Photographic Experts Group, по названию организации-разработчика) — один из популярных графических форматов, применяемый для хранения фото изображений и подобных им изображений. Файлы, содержащие данные JPEG, обычно имеют расширения. jpeg, .jfif, jpg, JPG, или. JPE. Однако из них .jpg является самым популярным на всех платформах. Алгоритм JPEG в наибольшей степени пригоден для сжатия фотографий и картин, содержащих реалистичные сцены с плавными переходами яркости и цвета. Наибольшее распространение JPEG получил в цифровой фотографии и для хранения и передачи изображений с использованием сети Интернет. С другой стороны, JPEG малопригоден для сжатия чертежей, текстовой и знаковой графики, где резкий контраст между соседними пикселами приводит к появлению заметных артефактов. Такие изображения целесообразно сохранять в форматах без потерь, таких как TIFF, GIF или PNG.JPEG(как и другие методы искажающего сжатия) не подходит для сжатия изображений при многоступенчатой обработке, так как искажения в изображения будут вноситься каждый раз при сохранении промежуточных результатов обработки . JPEG не должен использоваться и в тех случаях, когда недопустимы даже минимальные потери, например, при сжатии астрономических или медицинских изображений. В таких случаях может быть рекомендован предусмотренный стандартом JPEG режим сжатия Lossless JPEG(который, однако, не поддерживается большинством популярных кодеков) или стандарт сжатия JPEG-LS. Процесс сжатия изображения JPEG достаточно сложен и часто для достижения приемлемой производительности требует специальной аппаратуры. Поэтому просто опишем основные шаги, лежащие в основе этого алгоритма. Алгоритм сжатия изображения JPEG можно разделить на несколько этапов: Перевод в цветовое пространство YCbCr. YCbCr, Y′CbCr, илиYPb/CbPr/Cr, также пишется какY'CBCR или YCBCR— семейство цветовых пространств, которое используются для передачи цветных изображений в компонентном видео и цифровой фотографии [16]. Y'- компонента яркости,CB и CRявляются синей и красной цветоразностными компонентами.Y'(с апострофом) отличается отYкоторой обозначают яркость без предыскажения. Апостроф означает, что интенсивность света кодируется нелинейно с помощью гамма-коррекции. Y'CbCrне является абсолютным цветовым пространством, скорее, это способ кодирования информации сигналов RGB. Для систем отображения используются сигналы основных цветов RGB (красный, зелёный и синий). Эти сигналы не являются эффективными для хранения и передачи изображений, так как они имеют большую избыточность. Поэтому перевод в системуY'CrCbпозволяет передать информацию о яркости с полным разрешением, а для цветоразностных компонент произвести субдискретизацию, то есть выборку с уменьшением числа передаваемых элементов изображения, так как человеческий глаз менее чувствителен к перепадам цвета. Это повышает эффективность системы, позволяя уменьшить поток видеоданных. Значение, выраженное вY'CbCr будет предсказуемо, если первично использовались сигналы основных цветов RGB. 1. ДКП (Дискретно Косинусоидальное Преобразование) Изображение разбивается на компоненты 8×8 пикселов, к каждой компоненте применятся ДКП. Это приводит к уплотнению энергии в коде. Преобразования применяются к компонентам независимо. 2. Квантование Человек практически не способен замечать изменения в высокочастотных составляющих, поэтому коэффициенты, отвечающие за высокие частоты можно хранить с меньшей точностью. Для этого используется покомпонентное умножение (и округление) матриц, полученных в результате ДКП, на матрицу квантования. На данном этапе тоже можно регулировать степень сжатия (чем ближе к нулю компоненты матрицы квантования, тем меньше будет диапазон итоговой матрицы). RLE — кодирование. Используется особый вид RLE-кодирования: выводятся пары чисел, причём первое число в паре кодирует количество нулей, а второе значение после последовательности нулей. Т.е. код для последовательности 0 0 15 42 0 0 0 44 будет следующим (2;15)(0;42)(3;44). Кодирование методом Хаффмана. Используется описанный выше алгоритм Хаффмана. При кодировании используется заранее определённая таблица. Алгоритм декодирования заключается в обращении выполненных преобразований. К достоинствам алгоритма можно отнести высокую степень сжатие (5 и более раз), относительно невысокая сложность (с учётом специальных процессорных инструкций), патентная чистота. Недостаток – артефакты, заметные для человеческого глаза . Фрактальное сжатие. Фрактальное сжатие – это относительно новая область. Фрактал – сложная геометрическая фигура, обладающая свойством само подобия. Алгоритмы фрактального сжатия сейчас активно развиваются, но идеи, лежащие в их основе можно описать следующей последовательностью действий. Как и у всего алгоритм сжатия имеет свои недостатки. Недостатком метода JPEG является также то, что нередко горизонтальные и вертикальные полосы на дисплее абсолютно не видны, и могут проявиться только при печати в виде муарового узора. Он возникает при наложении наклонного растра печати на полосы изображения. По этой причине JPEG не рекомендуется использовать в полиграфии при высоких коэффициентах сжатия. 3.2.Рекурсивный (волновой) алгоритм Английское название рекурсивного сжатия — wavelet. На русский язык оно переводится как волновое сжатие и как сжатие с использованием всплесков. Ориентирован алгоритм на цветные и черно-белые изображения с плавными переходами. Коэффициент сжатия варьируется в пределах 5 - 100. Идея алгоритма заключается в том, что вместо кодирования собственно изображений сохраняется разница между среднимизначениями соседних блоков в изображении, которая обычно принимает значения, близкие к 0. Так, два числа a2i и a2i+1 всегда можно представить в виде b1i= =(a2i+a2i+1)/2 и b2i=(a2i-a2i+1)/2. Аналогично последовательность ai может быть попарно переведена в последовательность b1,2i. Рассмотрим пример. Пусть мы сжимаем строку из восьми значений яркости пикселов (ai): (220, 211, 212, 218, 217, 214, 210, 202). Получим следующие последовательности b1i, и b2i: (215.5, 215, 215.5, 206) и (4.5, -3, 1.5, 4). Заметим, что значения b2iдостаточно близки к 0. Повторим операцию, рассматривая b1i как a i. Данное действие выполняется как бы рекурсивно, откуда и название алгоритма. Из (215.5, 215, 215.5, 206) получим (215.25, 210.75) (0.25, 4.75). Полученные коэффициенты, округлив до целых и сжав, например, с помощью алгоритма Хаффмана, можно считать результатом кодирования. Заметим, что мы применяли наше преобразование к цепочке только два раза. Реально можно позволить себе применение wavelet-преобразования 4-6 раз, что позволит достичь заметных коэффициентов сжатия. Алгоритм для двумерных данных реализуется аналогично. Если у нас есть квадрат из четырех точек с яркостями a2i ,2j , a2i+1 , 2j, a2i , 2j+1 , и a2i+1 , a 2j+1 , то 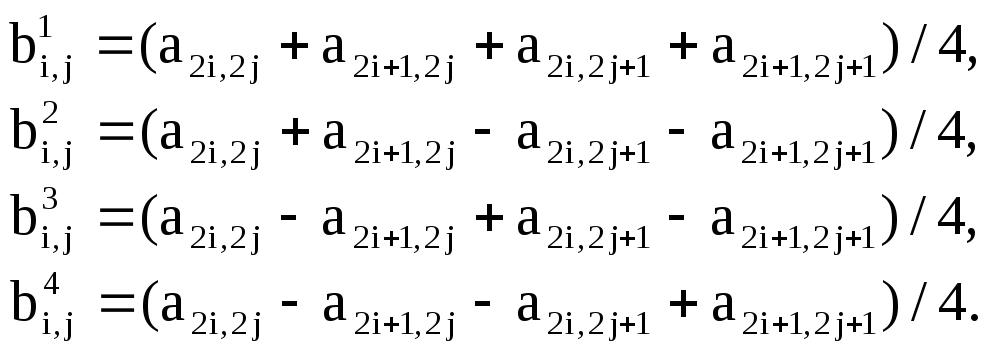 (1) (1)Используя эти формулы, для изображения 512х512 пикселов получим после первого преобразования уже 4 матрицы размером 256х256 элементов (рис. 5)
  (Рис. 5) В первой хранится уменьшенная копия изображения, во второй - усредненные разности пар значений пикселов по горизонтали, в третьей - усредненные разности пар значений пикселов по вертикали, в четвертой - усредненные разности значений пикселов по диагонали. Можно повторить преобразование и получить вместо первой матрицы 4 матрицы размером 128х128. Повторив преобразование в третий раз, получим в итоге 4 матрицы 64х64, 3 матрицы 128х128 и 3 матрицы 256х256. Дальнейшее сжатие происходит за счет того, что в разностных матрицах имеется большое число нулевых или близких к нулю значений, которые после квантования эффективно сжимаются. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||