Лекции_Вычислительные машины_new. Лекция История развития вычислительной техники
 Скачать 5.16 Mb. Скачать 5.16 Mb.
|

Таблица 2.6Форматы чисел блоков SSE
Мнемоника имен целочисленных SIMD-команд включает префикс и суффиксы, указывающие на характер выполняемой операции и тип используемых данных: - префикс p указывает на то, что команда выполняет параллельные операции над несколькими элементами данных; - суффиксы b,w,d и q указывают на используемый тип данных; - суффиксы u или s указывают на использование данных со знаком или без знака соответственно. Так, например, команда умножения pmulhuw работает с данными типа «упакованные 16-разрядные слова без знака». Однако использование нового набора команд SSE2 требует специальной оптимизации программ, которая имеет достаточно большие перспективы. Из-за чего AMD собирается реализовать SSE2 в своем новом процессоре Hammer. Старые программы никакого прироста в производительности при использовании Pentium 4 не получат. Более того, время, необходимое на выполнение обычных операций с вещественными числами, в сопроцессоре возросло по сравнению с Pentium III в среднем на 2 такта. Обмен данными на частоте 400 МГц на процессорной системной шине осуществляется с использованием учетверенной тактовой частоты 100 МГц контроллера чипсета. На частоте 400 МГц работает только участок FSB между процессором и чипсетом. Такая шина – совершенно новая процессорная системная шина FSB, и трудно установить, какой в действительности прирост производительности даст ее введение. По аналогии лишь можно заметить, что системная шина EV6 МП Athlon AMD 200 МГц в сочетании со всеми сильными и слабыми сторонами своего чипа отнюдь не дает двукратного преимущества по производительности над процессорами Pentium III с FSB 100 МГц. Процессор Pentium 4 Процессор Pentium 4 выпущен в серию в последнем квартале 2000 г. по технологии 0.18 мкм с использованием алюминиевых соединений на основе архитектуры NetBurst. Его ядро Willamette создано на основе 32-битной микроархитектуры IA-32, содержит 42 млн транзисторов и имеет площадь 217 кв.мм. Это более чем в 2 раза больше, чем площадь ядра Athlon или Pentium III. Pentium 4 в версиях с частотами 1.4 и 1.5 ГГц предназначен для работы с напряжением питания 1.7 В в специальных системных платах с 423-контактным процессорным разъемом Socket 423. Переход на медные соединения Intel планирует произвести одновременно с внедрением технологии 0.13 мкм. Процессор Intel Pentium 4 выпускается в FC-PGA упаковке, однако само ядро закрыто специальной металлической крышкой, защищающей его от повреждения. Из-за большого ядра тепловыделение новых кристаллов достаточно высокое. В частности, Pentium 4 1.4 ГГц, работающий при напряжении питания 1.7 В и потребляющий примерно 32 A, рассеивает около 52 Вт (Pentium 4 1.5 ГГц 55 Вт) тепла. Поэтому радиатор для Pentium 4 должен иметь большую площадь поверхности, обеспечивающую необходимую температуру кристалла. Укрупненная схема МП Pentium 4 представлена на рис. 2.21. Рассмотрим назначение и характеристики устройств, показанных на схеме.  Рис. 2.21. Укрупненная схема МП Pentium IV Pentium 4 содержит кэш второго уровня (Advanced Transfer Cache), работающий на частоте процессора, объемом 256 Кб. Интегрированный в кристалл L2 кэш имеет широкую 256-битную внутреннюю шину, как и в Pentium III, обеспечивающую пропускную способность 32 1.4 = 44.8 Гб/с (48 Гб/с для 1.5 ГГц), более высокую, чем 64-битная шина кэша МП AMD. Также как и в Pentium III, L2 кэш имеет 8 областей ассоциативности и строки длиной 128 байт. Однако, в отличие от Pentium III, каждая строка может быть изъята не целиком, а по половинкам в 64-байт. Фирма Intel увеличила пропускную способность кэша второго уровня в Pentium 4 в 2 раза благодаря передаче данных из него на каждый процессорный такт, в то время как данные из L2 Pentium III передаются только на каждый второй такт. Таким образом, пропускная способность L2 кэша Pentium 4 1.4 ГГц имеет величину 44.8 Гб/с (у Pentium III 1 ГГц она равна 16 Гб/с). Архитектура NetBurst поддерживает и кэш третьего уровня размером до 4 Мб, зарезервированный для будущего применения в серверных процессорах. Кэш данных первого уровня 8 Кб в Pentium IV предназначен для хранения и передачи чисел. Intel был вынужден сократить объем кэша первого уровня в Pentium IV, так как ядро этого процессора и без того получалось слишком большим. Архитектура NetBurst может поддерживать L1 кэш и большего размера, поэтому при переходе на технологический процесс 0.13 мкм, очевидно, объём этого кэша будет увеличен. Для увеличения производительности МП Pentium 4 Intel применил для доступа к L1 кэшу новый алгоритм, чем уменьшил латентность этого кэша до двух тактов вместо трех тактов в Pentium III. Таким образом, время реакции L1 кэша Pentium 4 1.4 ГГц составляет всего 1.4 нс против 3 нс у L1 кэша Pentium III 1 ГГц. L1 кэш Pentium 4 является, также как и в Pentium III, ассоциативным с прямой записью и с 4 направлениями. Длина одной строки кэша равна 64 байтам. Для кэширования инструкций в Pentium 4 используется трассирующий кэш. По сравнению с обычным L1 кэшем он имеет преимущество, направленное на минимизацию простоев процессора при выполнении неправильных предсказаний переходов. Трассирующий кэш является вместе с блоком ВТВ первой ступенью 20-стадийного конвейера, где команды, извлекаемые из L2, транслируются в последовательность микроопераций. Эта последовательность поступает одновременно на выполнение и запоминание для ускорения организации циклов или повторного выполнения участков программ. Pentium 4 использует системный интерфейс и процессорную шину, работающую с частотой 400 МГц с «четырехкратной накачкой». В нем тактовая частота системной шины (сигнал BCLK) составляет 100 МГц. По шине адреса, разделенной по синхронизации на две части, на частоту следования 100 МГц информация (действительный адрес) передается с удвоенной частотой по обоим фронтам адресного строба. Такой способ синхронизации аналогичен режиму 2x порта AGP, а также передаче по шине ATA в режиме Ultra DMA. По шине данных информация передается с четырехкратной частотой, для чего используется пара стробирующих сигналов удвоенной частоты (200 МГц). Эти стробы сдвинуты друг относительно друга на половину периода, и синхронизация по их спадам и дает учетверенную частоту передачи (как в AGP 4x). Стробы синхронизации подключают источник данных к ШД, причем каждые 16 бит данных пользуются отдельными линиями и стробами, что обеспечивает точность синхронизации на высокой частоте. Каждая пара байтов шины данных может передаваться в прямом или инверсном виде, независимо от других байтов, и источник данных сигнализирует приемнику о текущем способе представления соответствующим сигналом. Решение о том или ином способе передачи принимается источником перед передачей каждой порции данных с таким расчетом, чтобы количество линий данных, изменяющих свое состояние, было минимальным. Это позволяет уменьшить броски тока и электромагнитные помехи. Разрядность шины данных, как и в предыдущих двух поколениях процессоров, составляет 64 бита (8 байт), что в режиме 4x дает максимальную пропускную способность 10048=3.2 Гб/с. Благодаря этому минимизируются простои процессора Pentium IV в ожидании данных из ОЗУ. У процессоров Pentium III шина обеспечивала 1338=1.06 Гбайт/с, так что по этому параметру Pentium IV имеет троекратное улучшение. Шина адреса имеет разрядность 36 бит, что позволяет адресовать те же 64 Гб памяти, из которых кэшируются только первые 4 Гб. Системная шина адреса и данных контролируется битами паритета. Вторичный кэш имеет ECC-контроль, позволяющий обнаруживать и исправлять ошибки. По набору программно-доступных регистров Pentium 4 повторяет процессор Pentium III, так как входит в модель современных 32-разрядных процессоров, которые имеют системные, в том числе и скрытые регистры, как указывалось в п.2.2, а также регистры отладки, тестирования и модельно-специфические регистры. Для выполнения операций процессор имеет: - регистры общего назначения и целочисленное АЛУ; - блок регистров FPU/MMX с математическим сопроцессором и АЛУ MMX; - блок XMM. Набор 32-разрядных регистров общего назначения (EAX, EBX, ECX, EDX), индексных регистров (ESI, EDI), указателя базы (EBP) и стека (ESP), указателя инструкций (EIP) и регистра флагов (EFLAGS) существовал без приставки “E” еще в 16-разрядных процессорах 8086/88 и 80286. В наборе также имеются 16-битные сегментные регистры CS, SS, DS, ES, FS и GS, из них 2 последних в 16-разрядных процессорах отсутствовали. На этом наборе регистров построена вся система адресации к памяти и вводу-выводу, с их помощью исполняются все инструкции целочисленной арифметики, включая умножение и деление, логические инструкции, а также организуются ветвления, вызовы процедур и обработка прерываний. Операндами могут быть биты, цепочки бит, целые двоичные числа со знаком и без знака размером в байт (8 бит), слово (16 бит), двойное слово (32 бита), учетверенное слово (64 бита), а также упакованные (двухтетрадные) и неупакованные (однотетрадные) двоично-десятичные числа, занимающие один байт. Целочисленное АЛУ над операндами всех этих типов выполняет операции классическим способом: одна инструкция обрабатывает один комплект операндов. То есть, к примеру, можно одной инструкцией сложить два числа, получив один результат.  Рис. 2.22. Операционные блоки МП Pentium 4 Блок из 8 программных 80-битных регистров FPU/MMX используется одним из 2 способов. В режиме классического математического сопроцессора FPU обеспечивает выполнение многих команд, включая возведение в степень и извлечение корней, вычисление логарифмов, тригонометрические функции и ряд других. Операнды могут быть: целыми двоичными числами (16, 32 или 64 бита); 18-разрядными двоично-десятичными числами; вещественными числами в формате с плавающей точкой. Кроме блока из 8 регистров, организованных в стек, FPU содержит еще несколько вспомогательных регистров (см. «Регистры сопроцессора»). В режиме MMX те же 8 регистров с плавающей точкой FPU используются иначе – в каждом из этих регистров может быть упаковано 8 отдельных байт, или 4 слова, или 2 двойных слова, или же может располагаться 1 учетверенное слово (64 бита). Новые инструкции MMX могут обрабатывать сразу целую “упаковку” операндов, что и называется принципом SIMD. Таким способом могут выполняться инструкции сложения, вычитания, умножения, а также комбинации сложения и умножения, логические инструкции и сдвиги. Кроме того, есть вспомогательные инструкции преобразований форматов и пересылки данных. Для арифметических инструкций появился новый режим исполнения – с насыщением. Арифметика с насыщением отличается тем, что в случае получения результата, не укладывающегося в разрядность регистров, вместо циклического переполнения фиксируется предельно возможное значение (максимальное или минимальное). Такая арифметика более пригодна для обработки сигналов и мультимедийных приложений, на которые и ориентирован блок MMX. Первые модели Pentium, а также процессор Pentium Pro этого блока не имели. В процессорах Pentium II/ III для блока MMX появилось около десятка новых инструкций, работающих с блоком MMX. Эмуляция отсутствующего блока MMX не предусмотрена, так как технология MMX предназначена лишь для решения проблем производительности. Недостатком блока MMX является его конфликт с сопроцессором FPU. Если есть необходимость использования и того, и другого, то появляются большие потери времени по сохранению и восстановлению контекста при переключениях режима использования блока. Блок XMM содержит восемь 128-разрядных регистров, в каждом из которых может размещаться 4 вещественных числа одинарной точности. Блок XMM появился с процессорами Pentium III, где он реализует так называемое потоковое расширение SSE. В те времена, когда будущий Pentium III называли еще Kathmai, фирма Intel объявила о новых инструкциях KNI (Kathmai New Instruction), так что SSE – это синоним “староинтеловского” KNI. Блок позволяет выполнять параллельные и скалярные инструкции (см. «Процессор Pentium III»). Параллельные инструкции реализуют операции сразу над четырьмя комплектами операндов. Скалярные инструкции работают с одним комплектом операндов – младшим 32-битным словом. При выполнении инструкций с XMM традиционное оборудование FPU/MMX не используется, что позволяет эффективно смешивать инструкции MMX с инструкциями над операндами с плавающей точкой. Здесь блоки процессора меняются ролями – регистры MMX, наложенные на регистры традиционного сопроцессора, используются для целочисленных потоковых вычислений, а вычисления с плавающей точкой (правда, только с одинарной точностью, но для мультимедийных приложений ее хватает) возлагаются на новый блок XMM. Кроме инструкций с новым блоком XMM в расширение SSE входят и дополнительные целочисленные инструкции с регистрами MMX, а также инструкции управления кэшированием. В отличие от блока MMX, который для операционной системы неотличим от сопроцессора, блок XMM содержит совершенно новый набор регистров, и операционная система должна специально заботиться о его содержимом при переключении задач. Для сохранения и восстановления контекста блока XMM, а также FPU/MMX введены новые инструкции. Как и MMX, блок XMM не допускает программной эмуляции в случае его отсутствия. В процессоре Pentium III над вещественными операндами в XMM возможны арифметические операции (сложение, вычитание, умножение, деление, извлечение квадратного корня), нахождение максимальных и минимальных значений. Возможны и логические операции, для которых операнды трактуются как 32-битные слова. Имеются специальные инструкции пересылки данных, преобразования форматов и переупаковки. В процессоре Pentium IV набор инструкций получил очередное расширение – SSE2, в основном касающееся добавления новых типов 128-битных операндов (см. табл. 2.6) для блока XMM: - упакованная пара вещественных чисел двойной точности; - упакованные целые числа: 16 байт, 8 слов, 4 двойных слова или пара учетверенных (по 64 бита) слов. В процессор введена поддержка 64-разрядной целочисленной арифметики SIMD, добавлены инструкции преобразований для новых форматов данных, а также расширены возможности “перемешивания” данных в блоке XMM. Кроме того, расширена поддержка управления кэшированием и порядком исполнения операций с памятью. Инструкции SSE2 предназначены для 3D-графики, кодирования/декодирования видео, а также шифрования данных. Под давлением общественного мнения Intel отказалась от применения в процессоре Pentium IV уникального серийного номера, так по существу и не задействованного в реальных приложениях электронной коммерции. Одновременно с Willamette должен выйти Tehama с четырьмя модулями двухканальной RDRAM с теоретической полосой пропуска памяти 3.2 Гб/с. Также должен появиться упрощенный вариант – чипсет Tulloch с двумя модулями RDRAM. Архитектура IА-64 В последние годы появились две альтернативы традиционной 64-разрядной RISC-архитектуре: метод явных параллельных вычислений команд EPIC и многопоточные архитектуры [11]. Первая составляет одну из ключевых особенностей 64-битной ЭВМ архитектуры IA-64 фирм Intel и Hewlett-Packard, а вторая пока реализуется только в разработках компании Tera Computer Systems. EPIC нашли свое реальное воплощение в первых процессорах IA-64 Intel под торговым названием Itanium, разрабатываемых 7 лет под названием Merced, и AMD Sledgehammer. Itanium, который появился в 2001 г., не является 64-разрядным расширением архитектуры МП Intel х86. Он имеет новую систему команд и работает на частоте 800 МГц. Новая микросхема Intel, при производстве которой применяется 0.18-микронная КМОП технология, – это первый 64-разрядный процессор для серверов и рабочих станций, отличающийся относительно невысокой ценой. Он сразу вышел в лидеры по производительности, особенно в задачах с плавающей запятой. Одна из главных задач IA-64 – параллельное выполнение в конвейере из 10 стадий до 6 команд за такт. Однако последовательная структура кода программ и большая частота ветвлений делают решение этой задачи крайне сложной. Современные процессоры содержат огромное количество управляющих элементов для того, чтобы минимизировать потери производительности, связанные с ветвлениями. Они изменяют порядок команд во время исполнения программы, предсказывают и выполняют команды до вычисления условий ветвления, но в среднем выполняют только 2 команды за такт. Для выполнения 6 команд за такт и для извлечения большего "скрытого параллелизма" из кода программ в EPIC используются следующие способы: - упаковка компилятором команд по 3 в 128-битный пакет (связку) из 3 простых команд, содержащих три 7-битных поля РОН, для параллельной обработки явно указанной при трансляции путем переупорядочивания и оптимизации кода; - определение компилятором наличия сдваивания или страивания команд для одновременного выполнения их в такте синхронизации и помещение информации в шаблон (Т-template) длиной в несколько бит; - добавление компилятором двух команд предварительной загрузки из памяти и проверка загрузки для каждой команды программы, допускающей промах или задержку при обращении к кэш на основе интеллектуальной оценки данных, позволяющей предугадывать, какие именно данные потребуются для выполнения команды, и сокращать тем самым время ожидания процессором данных из памяти; - одновременное выполнение всех ветвей программы "отмеченных команд" компилятором для устранения потерь производительности из-за неправильно предсказанных переходов и определения "истинной" ветви с сохранением необходимых результатов и сбрасыванием остальных. Способ упаковки компилятором команд по группам на основании "интеллектуального планирования использования ресурсов" предназначен обеспечить оптимизацию параллельной загрузки ресурсов конвейера в Itanium при выполнении конкретной программы на этапе трансляции в машинный код. Ранее эта функция возлагалась на аппаратные средства. Надо отметить, что компилятор не просто освобождает процессор от решения этих задач. Он решает их заранее, так что в процессе параллельной обработки выполняется загрузка МП большим объемом работ. Для обеспечения такой загрузки 3 команды упаковываются в 128-разрядное командное слово, которое называется связкой, и имеет следующий вид
В связке 5 разрядов отводится под поле шаблона Т, который указывает тип команды в каждом из трех «слотов» связки и возможность параллельного исполнения этой и последующих команд. Для того чтобы определить возможность параллельного выполнения команд, аппаратура IA-64 использует «стоп-биты», явно кодируемые на ассемблере. Шаблон пакета указывает не только на то, какие команды в пакете могут выполняться независимо, но и какие команды из следующего пакета могут выполняться параллельно. Команды в пакетах не обязательно должны быть расположены в том же порядке, что в программе, и могут принадлежать к различным путям ветвления. Компилятор может также помещать в один пакет зависимые и независимые команды, поскольку возможность параллельного выполнения определяется шаблоном пакета. Команды могут быть не упорядочены, но должны быть сгруппированы в соответствии с переходами. Код поступает в процессор как бы отформатированным для параллельной обработки несколькими конвейерами. Применение шаблона связки позволяет не выдавать на одновременное выполнение больше команд, чем имеется исполнительных ресурсов МП. Во время выполнения программы IA-64 просматривает шаблоны, выбирает взаимно независимые команды и распределяет их по функциональным узлам. После этого производится распределение зависимых команд. Благодаря применению шаблонов удаляются соответствующие декодеры, что позволяет упростить узлы распределяющего коммутатора, т.к. некоторые «маршруты» команд становятся невозможными. Команды разного типа направляются в разные порты, обеспечивая параллельное выполнение команд смежных связок. При этом возможны следующие варианты связки из 3 команд: - К1||K2||K3 – все команды К1, К2, К2 исполняются параллельно (страивание); - K1&K2||K3 – сначала К1, затем исполняются параллельно К2 и К3; - K1||K2&K3 – параллельно исполняются К1 и К2 (сдваивание), после них – К3; - K1&K2&K3 – последовательно исполняются К1, К2, К3. При этом каждая команда в связке длиннее, чем 32-битные RISC-команды (порядка 40 бит), кодируется 5 полями следующего вида
Поля имеют следующее назначение: КОП – код операции; PR – 6-битное поле, содержащее 64 предиката; GPR – 7-битное поле, определяющее адрес одного из 128 РОН. Как видно из назначения и структуры команд IA-64, они ничего общего не имеют и не совместимы с системой команд х86, где они могут иметь длину от 8 до 108 бит. Поэтому в Itanium существует 2 режима декодирования команд: VLIW и старый CISC. Для перехода в режим х86 и передачи в нем данных в Itanium добавлен ряд команд, а его ОС будут содержать как 32, так и 64 разрядные части. Способ предсказания ветвления (в среднем каждая шестая команда является командой ветвления) используется и во многих других процессорах. В Itanium предсказание ветвления основывается на анализе исполняемой программы компилятором и принятии решений, какие из ветвей нужно просчитывать, а какие нет. Кроме того, компиляторы для IA-64 используют технологию "отмеченных команд". Когда компилятор находит оператор ветвления в исходном коде, он решает, стоит ли его "отмечать", и тогда помечает все команды, относящиеся к одному пути ветвления, идентификатором, называемым предикатом. Например, путь, лежащий по дуге «истинно», помечается предикатом Р1, а каждая команда другого пути – предикатом Р2. Таким образом, одновременно в IA-64 могут быть использованы для разметки 64 различных предиката. После того как команды "отмечены", компилятор определяет, какие из них могут выполняться параллельно. Это требует от компилятора оптимизации решений на основе знаний архитектуры конкретного процессора, числа и функций узлов, а также учета зависимости в данных (команды, которые используют результат другой, не могут выполняться параллельно). Однако каждый путь ветвления имеет свои особенности, и в них не зависит от других, поэтому " явный параллелизм команд" компилятором всегда будет найден. Заметим, что некоторые ветвления не могут быть отмечены из-за использования динамических методов вызова и распределения памяти. В других случаях применение этой технологии может привести к увеличению времени вычислений. Когда процессор встречает "отмеченное" ветвление при выполнении программы, он одновременно выполняет все ветви и вычисляет флаги, которые заносит в предикатные регистры. После определения "истинной" ветви по состоянию 64 предикатных однобитных регистров РR0-РR63 процессор сохраняет необходимые результаты и сбрасывает остальные. Способ позволяет устранить более половины задержек в вычислениях от ветвлений в типичной программе и уменьшить более чем в два раза число возможных ошибок в предсказаниях. Если компилятор не "отметил" ветвление, IA-64 действует почти так же, как предыдущие процессоры на основе предположения и данных блока ВТВ. Методика предположения, позволяющая добиться как низких задержек, так и более 90 % правильных вычислений, заключается в том, что инструкции и данные загружаются во время простоя в процессор и используют его как кэш до того, как они могут понадобиться. Способ добавления компилятором двух команд предварительной загрузки из памяти позволяет загружать данные задолго до момента использования. Тем самым сокращается время ожидания на их загрузку из памяти при работе МП. Сначала компилятор просматривает код программы, определяя команды, использующие данные из памяти. Везде, где возможно, к ним добавляется команда предварительной загрузки на наибольшем удалении и, при наличии ветвлений, команда проверки загрузки непосредственно перед командой, использующей данные. Если команда, инициировавшая предварительную загрузку, относится к неверному пути, загрузка признается неудачной командой проверки загрузки на основании уже вычисленных условий ветвления, и генерируется исключение. Если же путь верен, то исключение не генерируется. Основные аппаратные компоненты МП Itanium представлены на укрупненной схеме рис. 2.23. К ним относятся: БПВ – блоки прогнозирования ветвлений, которые определяют загрузку конвейеров, порядок вычислений; Кэш – буферное ОЗУ команд и данных первого L1 и второго L2 уровней; ОБ – операционные блоки, которые включают: конвейеры целочисленных операций ОЦ (4 целочисленных АЛУ, 4 мультимедийных ММХ исполнительных устройства, 3 устройства обработки команд перехода), конвейеры операций с плавающей точкой ОПТ (2 устройства с плавающей запятой, работающих с данными расширенной точности, 2 устройства с плавающей запятой одинарной точности) и 2 устройства загрузки регистров/записи в память; IA-32 – блоки декодирования и управления х86-программ. В МП интегрирован кэш первого уровня емкостью 216 Кб и 96 Кб кэш второго уровня. Процессор с кэш третьего уровня упаковывается в картридж (всего 320 млн транзисторов, из них 25 млн транзисторов содержит процессор). Картридж оснащается 2 или 4 Мб кэш памяти третьего уровня, работающей на тактовой частоте процессора. МП выпускается в вариантах 733 или 800 МГц и работает с набором ИС Intel 460GX или NEC Azusa с оперативной памятью SDRAM в компьютерах, содержащих до 4 процессоров. Системная шина 266 МГц с пропускной способность 2.1 Гб/с предусматривает использование кода с исправлением ошибок ЕСС. Четыре вида порта M, F, I, B закреплены соответственно за операциями с памятью, с плавающей запятой, целочисленными преобразованиями и вычислениями адресов команд перехода. Это обеспечивает выполнение от 8 до 20 параллельных операций за такт. Кэш-память Itanium не блокируется при возникновении ситуации непопадания в кэш. В результате конвейер встает только тогда и там, когда и где требуется реально отсутствующие данные, и возобновляет свою работу, как только они станут доступны. Двухпортовый кэш данных первого уровня имеет емкость 16 Кб и является 4-канальным наборно-ассоциативным с длиной строки 32 байта с режимом сквозной записи, обеспечивающим одновременно 2 операции загрузки регистров записи в память в любом сочетании за 2 такта. Из-за с малой емкости L1-кэша загрузка операндов с плавающей запятой всегда начинается с кэша второго уровня. Кэш команд первого уровня емкостью 16 Кб также является 4-канальным наборно-ассоциативным и может доставлять одну строку (32 байта) за такт. 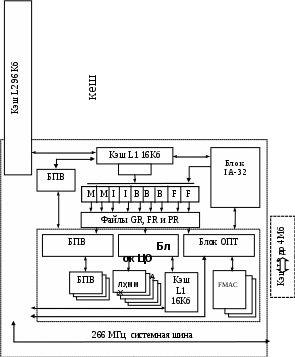 Рис. 2.23. Укрупненная схема МП Itanium Двухпортовый кэш второго уровня содержит и команды, и данные. Он является 6-канальным наборно-ассоциативным, с длиной строки 64 байта. Выполняет 2 операции с памятью за такт в режиме обратной записи. Время выполнения команды загрузки для целочисленных операндов равно 6 тактам, а для операндов с плавающей запятой – 9 тактам. Внешний кэш третьего уровня имеет длину строки 64 байта. Он является 4-канальным наборно-ассоциативным и может работать на частоте ядра процессора. Максимальная пропускная способность при передаче данных из кэша третьего уровня в кэш второго уровня – 13 Гб/с. Кроме трехуровневого кэша в микроархитектуре Itanium имеются 2 полностью ассоциативных буфера быстрой переадресации TLB. Каждый буфер имеет два уровня: 32-строчный первого уровня (задержка при непопадании в него равна 10 тактам) и 96-строчный второго уровня (задержка при непопадании – 23 такта). TLB поддерживают различные размеры страниц: 4/8/16/64/256 Кб, 1/4/16/64/256 Мб. Кроме того, предусмотрен однотактный TLB-буфер команд емкостью 64 строки, также являющийся полностью ассоциативным. Важнейшей частью конвейера Itanium является фронтальная стадия «расцепление» (decoupling) с использованием буфера расцепления, имеющего емкость в 8 связок, осуществляющая опережающую выборку еще не затребованных команд. Этот подход способствует распараллеливанию выполнения команд и позволяет скрыть задержки кэша команд и предсказания переходов. Предварительная выборка команд, инициируемая соответствующими командами IA-64, выбирает коды из кэша второго уровня и помещает их в потоковый буфер расцепления. На фронтальной стадии конвейера используется иерархическая система предсказаний перехода. В случае неверного предсказания на перезагрузку конвейера потребуется задержка в 9 тактов. Для уменьшения задержек в Itanium применяется до 4 «уровней подсказок». При этом можно использовать три вида «подсказок» о переходах: командой brp, командой пересылки в регистр переходов и с помощью кодируемой в команде br подсказки. Первый и второй уровень – это традиционные 4-канальные наборно-ассоциативные таблицы предсказания переходов, которых в Itanium имеется две – BPT и MBPT (Multiway BPT). Обе таблицы работают на основе адресов связок. В них применяется двухуровневый предиктор с 4-разрядным полем предыстории ветвлений (счетчик переходов). ВРТ имеет емкость 512 элементов для обычных переходов, а МВРТ – 64 строки для переходов на несколько ветвей. Следующий уровень предсказания переходов использует 64 строки кэша адресов перехода TAC, заполняемый командами brp, br или аппаратурой предсказания. Он содержит по одной строке на связку, регистр адресов перехода TAR разрядностью в 4 строки (по одной строке на пару связок) и буфер адресов возврата RSB, используемый для команд возврата емкостью 8 строк. Для управления счетчиком команд IP имеется два блока коррекции адреса перехода: BAC1 и BAC2. TAR содержит не только признак, но и адрес перехода, устанавливаемый командой предсказания перехода brp.imp. Если в TAR указан соответствующий признак попадания (hit), переход будет выполнен независимо от ВРТ/МВРТ. Предсказание TAR может игнорироваться только тогда, когда счетчик цикла LC или ЕС указывает на выход из цикла. Если в МВРТ/ВРТ имеется признак попадания, то из ТАС берется соответствующий адрес перехода. Если же переход отсутствует в МВРТ/ВРТ, но в ТАС есть признак попадания, переход будет осуществлен. ТАС содержит одну строку на связку, поэтому кроме адреса связки в нем указывается еще и номер слота в связке. Средняя часть конвейера отвечает за своевременную доставку команд и операндов в операционные блоки МП. На этих стадиях 6 входящих команд распределяются между 9 портами выдачи, и осуществляется отображение виртуальных номеров регистров из программного кода в физические регистры. Эти 9 портов включают 2 порта для команд группы М, 2 для команд 1, 2 для команд F и 3 для команд группы B. Для автоматического сохранения/восстановления регистров или при «переполнении/переизбытке» используется аппаратный стек RSE. Он приостанавливает выполнение и сохраняет команды, ждущие операнды или РОН без режима перезаполнения конвейера. Стекирование регистров и их вращение с учетом виртуальных и физических номеров осуществляется с использованием набора из 98 сумматоров и 42 мультиплексоров. Архитектура IA-64 характеризуется очень большими емкостями файлов регистров. Файл из 128 регистров общего назначения GR в Itanium имеет 8 портов чтения и 6 портов записи. Эти порты поддерживают одновременно 2 М-операции и 2 I-операции за такт. Файл из 128 регистров с плавающей запятой FR обеспечивает одновременную работу двух М-операций и двух команд FMAC («умножить/сложить»). Для увеличения эффективности работы он разделен на четные и нечетные банки и имеет 8 портов чтения и 4 порта записи. Файл из 64 однобитных регистров-предикатов PR имеет 15 портов чтения и 11 записи. На стадии выполнения эффективность работы функциональных устройств увеличена за счет возможности прямой подачи результата выполнения на вход другой команды, минуя запись в регистр записи результата. «Целочисленное исполнительное ядро» имеет 4 порта: 2 порта памяти и 2 порта целочисленных операций. Все 4 порта могут выдавать на выполнение арифметические команды, команды сдвига, логические команды, команды сравнения и большинство целочисленных мультимедийных SIMD команд. М-порты могут также «выполнять» команды загрузки регистров и записи в память, а через I-порты могут реализоваться целочисленные команды: проверка состояния разряда, поиск нулевого байта и некоторые виды сдвигов. Для повышения эффективности работы с предикатами в Itanium предусмотрена возможность их использования сразу в момент вычисления из файла спекулятивных предикатных регистров SPRF. Блок операций с плавающей точкой ускоряет обработку данных, связанных с защитой информации и 3D-графики. Он содержит два модуля FMAC, каждый из которых может на двух 82-разрядных операндах выполнять две операции с плавающей точкой. FMAC – устройства с плавающей запятой, имеют возможность одновременной работы в формате с 82-разрядным представлением чисел с плавающей запятой одинарной, двойной и расширенной точности при выполнении операций умножение и сложение. В результате Itanium имеет пиковую производительность в 4 операции с плавающей запятой двойной точности за такт или 3.2 GFLOPS при частоте 800 МГц. При работе с одинарной точностью с плавающей запятой Itanium может выполнить 8 операций за такт, используя SIMD-команды (через 2 дополнительных FMAC). FMAC-устройства выполняют за 5 тактов не только команды FMAC, но и многие другие команды с плавающей запятой. Еще один конвейер с плавающей запятой выполняет команды сравнения, вычисления обратного квадратного корня и др. Деление в Itanium реализуется программным путем. Чтобы достигнуть пиковой производительности, 2 FMAC-устройства нужно снабжать шестью операндами за такт. Кэш второго уровня доставляет 4 операнда за такт, и еще 2 операнда берутся из файла FR. Для повышения быстродействия FP-конвейер операций с плавающей запятой связан с целочисленным. Эта связь позволяет пересылать данные между файлами FR и GR за 2 такта, а в обратном направлении – за 9 тактов. Системная шина Itanium с тактовой частотой 133 МГц и с 2 передачами за такт имеет ширину 64 разрядов для данных и 8 разрядов для кодов ECC. Адресная шина 44-разрядная автономная. Рассмотренная архитектура Itanium по сравнению с предыдущими х86 МП имеет следующие преимущества: - позволяет использовать 64-разрядные данные и адреса, тем самым увеличить точность и быстродействие вычислений операций с фиксированной запятой в АЛУ и увеличивать адресуемое пространство памяти до 264 ячеек, а емкость адресуемой памяти до 18 млрд Гб (18 Эбайт); - предусматривает по 128 регистров для выполнения операций с фиксированной и плавающей точкой, позволяющих увеличить гибкость программирования, число одновременно выполняемых микроопераций и уменьшить количество обращений к памяти. К недостаткам Itanium относится: - не обеспечивает функционирование х86-программ с «достигнутой скоростью» в МП К6 и Р6 без перекомпилирования приложений; - требует перекомпиляции программ при переходе от одного поколения процессоров к следующему поколению при их архитектурных отличиях; - компиляция занимает больше времени и требует гораздо больше действий и программного обеспечения. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||