Лекции_Вычислительные машины_new. Лекция История развития вычислительной техники
 Скачать 5.16 Mb. Скачать 5.16 Mb.
|

|
Рис. 2.6. SIMD-регистры с плавающей точкой Регистр состояния и управления используется для установки флагов обнаружения арифметических исключений, флагов режимов обработки арифметических исключений, режима округления, режима flush-to-zero и для просмотра флага состояния [11]. Содержимое этого регистра может быть загружено с помощью инструкций ldmxcsr и fxrstor. На рис. 2.7 показан формат и кодирование полей в регистре MXCSR. Биты 0-5 содержат 6 флагов, которые служат признаками детектирования арифметических SIMD исключений с плавающей точкой. Если флаг установлен в 1, то обнаружено соответствующее исключение. Эти флаги могут быть очищены инструкцией LDMXCSR записью нулей. Если команда LDMXCSR очищает битовую маску и устанавливает соответствующий бит флага исключения, исключение не будет немедленно сгенерированно. Исключение произойдет только после следующей команды SSE. Расширение SIMD использует только один флаг исключения для каждой исключительной ситуации. В ситуации, когда происходит несколько идентичных исключительных ситуаций при обработке одной команды, соответствующий флаг исключения обновляется и указывает, что хотя бы одно из этих условий произошло. По умолчанию эти флаги сбрасываются.  Рис. 2.7. SIMD регистр состояния и управления MXCSR Биты 7-12 (поле маскирования исключений) определяют, как обрабатываются обнаруженные исключения. Если флаг установлен, то соответствующее исключение маскировано и обрабатывается процессором, который формирует приемлемый результат (в соответствии с процедурой, установленной по умолчанию) и продолжает выполнение программы. Если флаг сброшен, то вызывается программный обработчик для этого исключения. По умолчанию флаги устанавливаются в 1. Биты 13-14 (RC) устанавливают режим округления результатов при выполнении SIMD-команд над данными с плавающей точкой. По умолчанию устанавливается режим округление до ближайшего. Поле управления округлением (RC) регистра MXCSR (биты 13 и 14) определяет четыре режима округления: округление до ближайшего (биты 0 и 0), до меньшего или равного (0 и 1), до большего или равного (1 и 0) и в сторону нуля (1 и 1). Округление по умолчанию до ближайшего обеспечивает наиболее точную и статистически несмещенную оценку правильного результата. Режимы округления до большего и меньшого называются округлением по направлению и могут быть использованы для реализации интервальной арифметики. Для определения верхней и нижней границы точного решения в многошаговых вычислениях, когда промежуточный результат вычислений округляется. Режим округления в сторону нуля обычно используется при вычислении целых. Бит 15 (FZ) по умолчанию установлен в 0. Флаг FZ регистра MXCSR включает режим flush-to-zero, когда произошло исчезновение порядка и бит установлен в 1. Тогда процессор выполняет следующие действия: - возвращает нулевое значение в качестве результата, присваивая ему знак истинного результата; - устанавливает в 1 биты 4 и 5 регистра MXCSR (флаги обнаружения исключений исчезновения порядка и неточного результата). Указанные действия выполняются в том случае, если исключение исчезновения порядка маскировано (бит 11 регистра MXCSR установлен в 1). При таком режиме увеличивается скорость работы программ, в которых часто происходит исчезновение порядка результата. Достигается это, однако, ценой снижения точности вычислений. Остальные биты регистра MXCSR (биты 16-31 и бит 6) зарезервированы и установлены в 0. Лекция 7. Модели процессоров Процессор i486 ЭВМ на базе процессора i486 появились в 1989 г., когда Intel впервые продемонстрировала СБИС i486DX. Процессор i486 в дальнейшем был усовершенствован с использованием новой технологии и, как указывалось выше, имеет несколько модификаций. Наиболее важные его возможности следующие [21]: - совместимость с системой команд i86, i286, i386; - 32-битная шина адреса и 32-битная шина данных; - совместимость FPU с сопроцессорами i87, i287, i387 и поддержка 32/64/80-битных форматов чисел; - наличие кэш первого уровня с быстродействием регистров МП; - конвейеризация команд, т.е. их параллельная подготовка к выполнению; - пакетные циклы обмена, снижающие общее время вычислений и передачи данных между МП и DRAM с использованием внутренних буферов записи; - управление обратной записью с очисткой кэш второго уровня, обеспечивающей согласованность данных в V-режиме. Схема процессора i486 представлена на рис. 2.8. Он содержит устройство управления (УУ), арифметико-логическое устройство (АЛУ), устройство с плавающей точкой (FPU), устройства сегментации и страничного преобразования, кэш-память (КЭШ), устройство предвыборки команд и шинный интерфейс. В составе устройств на схеме показаны все пользовательские и системные регистры процессора. Рассмотрим более подробно назначение устройств процессора. Шинный интерфейс – это устройство связи i486 с шиной процессора и через контроллер шины с другими блоками ЭВМ. Он обеспечивает двунаправленную передачу данных и адресов, формирование управляющих сигналов (УС) для подключения внешних блоков к контроллеру шины. Передача данных и их прием осуществляется через буферные регистры интерфейса в режиме сквозной записи и пакетного обмена. Для повышения быстродействия данные и команды (коды) поступают в процессор в режиме опережающей выборки и располагаются в сверхбыстродействующем кэш. Кэш емкостью 8 Кб предназначен для хранения данных и кодов, непосредственно участвующих в вычислениях. Информация в кэш располагается ячейками (строками) по 16 байт, соответствует физическим адресам (ФА) в ОЗУ. Обычно часть (21 старший разряд) ФА представлена в кэш как тэг для обеспечения быстрого ассоциативного поиска. При обращении к кэш процессор передает из устройств сегментации или страничного преобразования ФА. Если по данному ФА информация в кэш имеется, то нужная строка в 16 байт считывается в буфер заполнения, затем из нее 8/16/32-разрядные данные передаются на внутреннюю шину данных (ВШД). Если данный ФА отсутствует в кэш (“промах”), то осуществляется обращение к ОЗУ. Считанная из ОЗУ информация передается по ШД на ВШД и параллельно в буфер заполнения кэш. В следующие такты (опережающая выборка) в буфер заполнения передаются еще 3 старших ячейки ОЗУ по значению ФА. 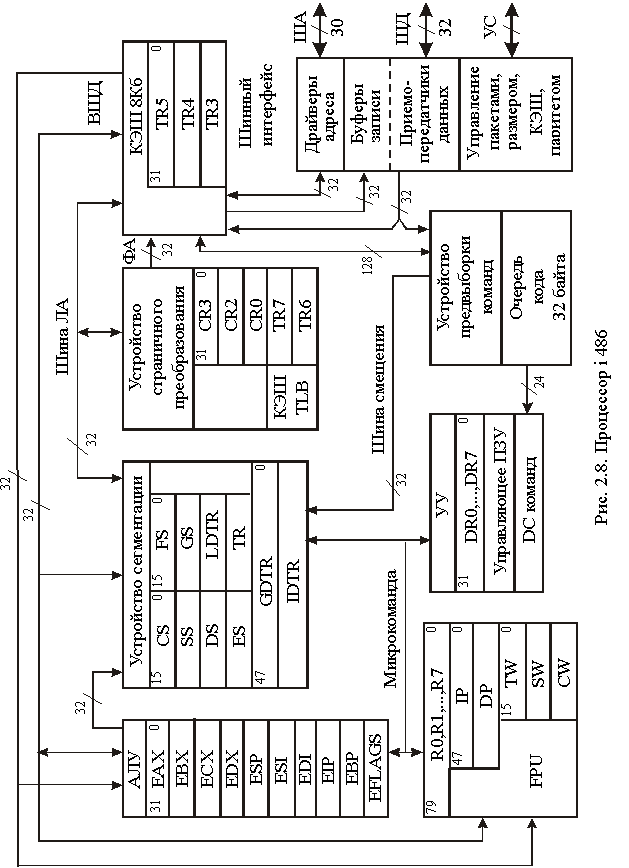  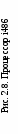 Затем информация из буфера заполнения размерностью строки кэш заносится в ячейку кэш по адресу ФА(11, 4), соответствующему 7 младшим разрядам ФА, начиная с четвертого, и в направлении, определенном блоком достоверности (LRU). Так как данные и коды в программах располагаются чаще всего возле близлежащих адресов, такой режим позволяет уменьшить число промахов при обращении к кэш. При объявлении строки недостоверной по шине адреса А(31,4) передается ФА, и при обнаружении этого адреса в кэш соответствующий бит достоверности в блоке LRU сбрасывается. Устройство предвыборки команд предназначено для уменьшения времени на обработку команды при передаче ее в УУ. Считывание команд в устройство предвыборки осуществляется 16-байтными блоками, которые параллельно записываются в кэш и извлекаются оттуда, если в программе встречаются циклы. Команды в блоке располагаются в естественном порядке возрастания адресов и сдвигаются для передачи в УУ. В процессе сдвига они образуют очередь из 32 байт, которая параллельно обрабатывается (конвейеризация) в каждом такте синхронизации, проходя через первую, а затем и вторую ступени дешифрации на выполнение. Первая ступень дешифрации позволяет обратиться команде к памяти еще до момента передачи ее на выполнение в УУ. Тем самым в момент выполнения команды соответствующие микрокоманды УУ реализуют ее за 1,2 такта, включая передачу результата в регистр. При ветвлениях в программе и смене естественного порядка следования адресов устройство предвыборки очищается, а затем заполняется новой очередью команд. Устройство управления i486 микропрограммного типа оптимизировано с целью уменьшения числа микрокоманд для обработки каждой команды. Кроме того, часть микроопераций для выполнения операции каждой команды реализуется в результате конвейеризации в устройстве предвыборки команд. Другая часть микроопераций выполняется аппаратно в целочисленном устройстве (АЛУ) и сопроцессоре. Поэтому на последнем шаге выполнения многие команды имеют одну микрокоманду, которая выполняется за один такт синхронизации. Микрооперации этой микрокоманды чаще всего управляют АЛУ, FPU или устройством сегментации, где определяется выбор конкретного сегмента. Системные регистры DR0 DR7 используются в УУ для отладки программ. Устройство с плавающей точкой (FPU) предназначено для вычисления математических операций с повышенной точностью аналогично по выполняемым функциям сопроцессору 80387. Оно имеет одинаковую систему команд и набор регистров (см. рис. 2.5) стека R0 - R7, указатель команд IP, указатель данных DP, регистры: тэгов TW, состояния SW и управления CW. Все команды FPU начинаются с кода <11011> в поле кода операции и по этому признаку передаются в регистр IP, где при необходимости используются для обработки особых случаев. Повышенная точность вычислений достигается использованием представления чисел с плавающей точкой и увеличением разрядности представления нормализованной мантиссы до 64 бит. Устройство страничного преобразования используется для программ, обрабатывающих множество данных и кодов, больше емкости ОЗУ. Для этого все данные и коды размещаются по страницам емкостью 4 Кб (каждой странице присваивается линейный адрес). В процессе работы программы страницы с диска последовательно загружаются в ОЗУ по новым физическим адресам страниц (кадр). Устройство страничного преобразования вычисляет их новый адрес по линейному адресу в программе, используя в работе регистры CR0, CR2 и CR3. Для повышения быстродействия вычислений физического адреса данных в кадре предназначен ассоциативный буфер преобразования (TLB), который можно контролировать регистрами TR6, TR7. Устройство сегментации обеспечивает поиск данных и кодов, распределенных по разным областям ОЗУ. Такое распределение информации позволяет избежать влияния одних задач на другие, исключить ошибки программирования и реализовать привилегии для системных программ. Для определения адреса данных или кода используются селекторы CS, SS, DS, ES, FS, GS, LDTR и TR. Каждый селектор имеет теневой регистр, в который по содержимому селектора и регистров GDTR или LDTR загружается из глобальной или локальной дескрипторной таблицы базовый адрес сегмента. По адресам теневых регистров вычисляются линейные адреса данных и кода, используемых программой. Регистр TR обеспечивает работу i486 в многозадачном V-режиме, постоянно перезагружаясь со сменой задач с сохранением контекста (значений пользовательских и системных регистров) в сегменте состояния задачи (TSS). АЛУ целочисленного типа предназначено для выполнения арифметических операций с фиксированной точкой, сдвига данных, логических операций, операций в двоично-десятичном представлении, обмена между портами, хранения и вычисления адресов данных и следующих команд. В состав его входят 8 регистров общего назначения, счетчик команд EIP и регистр флагов EFLAGS. Многие команды в АЛУ выполняются за один такт. Более подробно работа блоков процессора i486 рассмотрена ниже. Процессоры Pentium и PentiumMMX Следующему, пятому поколению МП Intel 80586, которые разрабатывались как Р5, для регистрации авторских прав было присвоено название Pentium. Серийное изготовление этого процессора началось в 1993 г. с рабочей частотой 60, а затем 66 МГц и напряжением питания 5 В. Кристалл, потребляя 16 Вт мощности, сильно нагревался и обдувался вентилятором. Через год биполярная КМОП-технология была усовершенствована с 0,8 до 0,6 мкм на элемент, снижено напряжение питания до 3,3 В и повышена внутренняя рабочая частота процессора до 75, затем 90 и 100 МГц. Эти процессоры второго поколения (Р54С) получены на кристалле, содержащем 3,3 млн транзисторов, в корпусе SPGA с 296 выводами, по суперскалярной архитектуре. Под скалярным понимается МП с единственным конвейером (все МП до Pentium). Процессор Pentium имеет 2 конвейера, а Pentium Pro является трехпотоковым [4]. Эти МП способны обрабатывать несколько команд за такт, поэтому их называют суперскалярными. Понятие «суперскалярная архитектура» связано обычно с высокопроизводительными RISC - процессорами. Pentium является одним из первых CISC - процессоров, который параллельно обрабатывает 2 команды, так как его архитектура объединяет 2 конвейера i486 в своем корпусе, которые обозначаются U и V. Ведущий U - конвейер выполняет все операции, а второй V - конвейер выполняет простые операции с целыми числами и часть операций с плавающей запятой. Многие программы допускают одновременное выполнение двух последовательных команд, когда работают оба конвейера и процессор выполняет сдваивание команд. В некоторых случаях не все команды допускают сдваивание, тогда работает только U - конвейер. С целью получения большей производительности МП программы транслируют с наибольшим числом случаев сдваивания команд, чтобы обеспечить преимущество суперскалярной технологии в параллельной обработке. По сравнению с i486 Pentium (P5) имеет следующие усовершенствования: - имеется два конвейера U и V в результате объединения двух i486 в суперскалярную архитектуру, позволяющие одновременно обрабатывать 2 последовательные команды, допускающие сдваивание; - внедрен блок динамического предсказания ветвлений ВТВ, обеспечивающий выполнение команд не дожидаясь вычисления условий ветвлений; - используются два внутренних кэш-1 с отложенной сквозной или обратной записью результатов вычислений в буфере до освобождения шины; - расширена шина данных (до 64 бит), удваивающая скорость передачи данных; - кэш-1 одновременно доступен для 2 конвейеров, если они обращаются к разным банкам памяти; - внедрен режим конвейерной обработки данных в устройстве с плавающей точкой FPU и увеличена его производительность в 2 - 10 раз; - расширена система команд, в которую включена команда CPUID опроса модели МП, и расширен размер страницы до 4 Мб при страничной переадресации; - расширено число регистров тестирования (TR1 - TR12); - введена возможность совместной работы двух МП; - расширены средства контроля и увеличена достоверность передачи и вычислений, введены средства снижения энергопотребления. Обработка закодированной команды требует определенных затрат времени (тактов, т. е. импульсов синхронизации). Чем сложнее команда, тем больше требуется тактов и определенных последовательностей микроопераций на ее выполнение. Для повышения быстродействия вычислений последние модели МП обрабатывают команды по шагам в очереди поэтапно в нескольких операционных блоках. Набор блоков и правила обработки команд в этих блоках характеризует тип конвейера МП. В каждом такте в конвейер поступает одна команда, которая обрабатывается на первой ступени. Затем в следующем такте она сдвигается на вторую ступень и через несколько тактов (равное или меньшее числа ступеней) команда окончательно исполняется на последней ступени. На каждой ступени команда занимает один из блоков, в котором вычисляет адреса операндов, извлекает их в РОН МП, выполняет операции в АЛУ и т. д. В каждом блоке выполняется от одной до нескольких микроопераций. Один конвейер позволяет сократить время на выполнение любой команды до времени, равного длительности одного импульса синхронизации. Дальнейшее увеличение быстродействия может быть получено за счет параллельной обработки команд на нескольких конвейерах (суперскалярная архитектура). Так, в Pentium используется 2 пятиступенчатых конвейера, позволяющих за один такт при сдваивании обрабатывать 2 команды. Таким образом, чем больше ступеней конвейера, тем большее число последовательных микроопераций может быть включено в команду, а чем больше конвейеров, тем больше одновременно команд может быть обработано в одном такте синхронизации. Чтобы уменьшить время ожидания вычисления адресов команд управления, изменяющих естественный порядок их обработки, используется буфер адреса ветвления (ВТВ). В Pentium имеется ВТВ на 256 элементов (вхождений) по схеме динамического предсказания ветвлений. В данный буфер с опережением считываются адреса и содержимое команд условных переходов из очереди предвыборки. «Предвидение» переходов и опережающая подготовка характеристик ветвления позволяет обрабатывать команды с максимальным быстродействием. Динамическое предсказание ветвлений осуществляется с учетом накопления статистики выполнения условных переходов и анализа предыстории вычислений. Процесс обработки команд в конвейерах U, V и FPU можно пояснить с помощью рис. 2.9 [8]. Блок предварительной выборки команд (PF), имеющий четыре 256- разрядных независимых буфера, поочередно из программного кэш извлекает команды в естественном порядке по 16 байт с учетом прогноза флага команды условного перехода, т. е. в направлении, предсказанном буфером адреса ветвлений ВТВ. Если предсказание не подтвердилось, то блок PF очищается, предвыборка повторяется в новом направлении с потерей 3 - 4 циклов вычислений. Если команды зависят друг от друга, то первая запускается в U - конвейер, а V - конвейер простаивает. Если предсказание не вычисляется, то команды обрабатываются в естественном порядке. 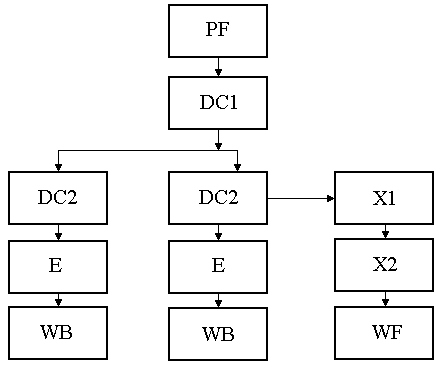 Рис. 2.9. Блок - схема конвейерной обработки МП Pentium После предвыборки команды продвигаются по мере освобождения конвейеров на дальнейшую обработку и вначале проходят первую ступень дешифрации DC1. В этой ступени выявляется возможность сдваивания команд. При наличии сдваивания 2 команды передаются на вторые ступени дешифрации DC2, где могут вычисляться адреса операндов в памяти с использованием многоканального сумматора или может осуществляться передача их в трехступенчатый конвейер FPU (X1- X2 - WF). На четвертой ступени целочисленного конвейера Е происходит передача операндов для выполнения операции в АЛУ, после чего результаты передаются в буфер записи в память WB. Схема процессора Pentium изображена на рис. 2.10. Он имеет такую же, как и i486, 32-разрядную шину адреса, позволяющую обращаться к 4 Гб памяти, буфер адреса ветвления и схемы, обеспечивающие двухпроцессорный режим обработки информации. Процессоры Pentium MMX (P55C) появились в начале 1997 г. для эффективного выполнения мультимедийных приложений, а также 2D и 3D- графики [9]. Они выполнены по 0,35 мкм технологии на кристалле, содержащем 4,5 млн транзисторов. Сначала МП обрабатывали команды с частотой 166 МГц, затем 200 и 233 МГц. 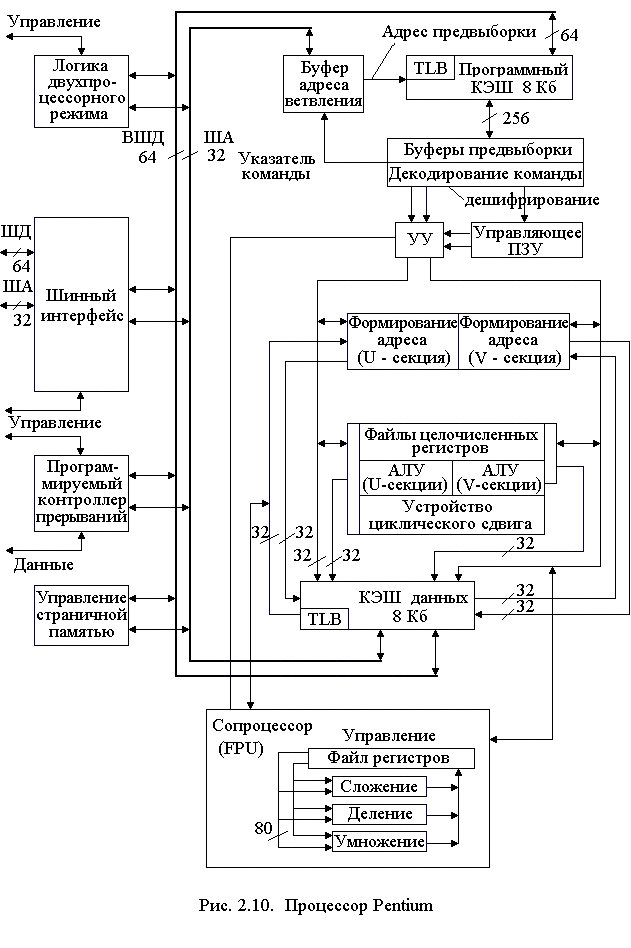 В архитектуре Pentium MMX один из конвейеров FPU был специализирован для обработки 4 новых типов данных и 57 ММХ команд в восьми 64-битных регистрах с прямой адресацией MMX0-MMX7. Основная идея расширения ММХ заключается в использовании способа SIMD, который предусматривает одновременную обработку нескольких операндов, находящихся в 64-битном формате ММХ, под управлением одной команды за один такт. В формате ММХ могут находиться упакованные 8 байт, 4 слова, 2 двойных слова и учетверённое слово. Над этими данными могут выполняться арифметические операции, такие как сложение без переполнения (с насыщением), умножение, сравнение данных на равенство, преобразование форматов, сдвиги, пересылки, логические (И, И-НЕ, ИЛИ, Исключающее ИЛИ), обнуление регистров MMX0 - MMX7. Регистры MMX принадлежат FPU, поэтому они 80-разрядные. Эти же регистры используются при выполнении операций с плавающей запятой. Поэтому MMX и FPU команды несовместны, их частое чередование с настройкой конвейера на обработку существенно снижает быстродействие вычислений. В зависимости от типа команды ММХ за один такт могут обрабатываться параллельно как 8 однобайтных, так и 4 двухбайтных или 2 четырехбайтных операнда. Pentium MMX способен выполнять 2 SIMD команды с 16-битными данными за 1 такт. В нем U- и V- конвейеры имеют равные приоритеты и команды распределяются в них без жесткой привязки. Он имеет лучшие характеристики в отличие от Pentium и при выполнении обычных команд. Кроме того, Pentium MMX имеет 4 буфера записи WR, которые могут быть использованы любым конвейером, удвоенную емкость внутреннего кэш (16+16 Кб). Для синтаксического разбора инструкций в конвейере МП введена дополнительная ступень F после ступени PF. Если в результате синтаксического разбора двух команд выявляется возможность их параллельного выполнения, они направляются: в два АЛУ ММХ; один ускоренный умножитель для операций умножения с задержкой на 3 цикла, но в каждом такте; один сдвигатель для левого или правого сдвига операндов на количество бит, указанных в операнде источнике. Команды ММХ при наличии микроопераций обращения к кэш-1 или к обычным РОН выполняются только в U-конвейере и не допускают в нем сдваивания с обычными командами х86. Архитектура процессоров семейства P6 Процессоры семейства P6 представляют собой реализацию наиболее современных процессоров в семействе IA: Pentium Pro, Pentium II, Celeron, Pentium III. В проектировании процессоров семейства P6 одной из главных задач было значительное увеличение производительности процессоров Pentium благодаря улучшению архитектуры. Принципиальное отличие этого семейства состоит в том, что P6 преобразует команды x86 во внутренние RISC-подобные команды, называемые микрокомандами (micro-ops). Микрокод – это элементарная инструкция, которая выполняется одним из шести блоков процессора параллельно. Это позволяет устранить многие ограничения, свойственные набору команд x86, такие как нерегулярность кодирования команд, операции целочисленных пересылок «регистр – память» и переменная длина непосредственных операндов. Процессоры семейства P6 имеют трехходовую суперскалярную конвейерную архитектуру. Термин “трехходовая суперскалярная” означает, что, используя технику параллельной обработки, процессор может в среднем за один такт декодировать, диспетчеризировать и выполнить три команды. На рис. 2.11 показан обобщенный вид конвейера. 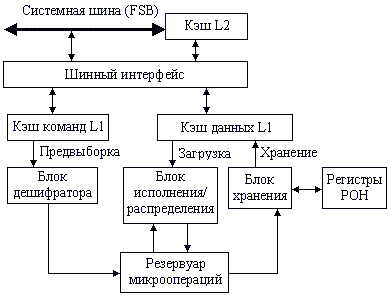 Рис 2.11. Функциональная схема процессора типа P6 Для постоянного поступления команд и данных конвейер процессора P6 включает два уровня кэша. Кэш L1 состоит из кэша команд и кэша данных, каждый емкостью по 8 и более Кб, они вплотную присоединены к конвейеру. Кэш L2 может быть 256 Кб и более. Это статическое ОЗУ, которое присоединено к ядру процессора через 64-битную шину кэша. Центральная часть архитектуры семейства процессоров P6 это введение механизма “динамического выполнения”. Динамическое выполнение включает 3 концепции обработки информации: - глубокое прогнозирование ветвлений; - динамический анализ потока данных; - прогностическое выполнение. Прогнозирование ветвлений – это концепция, которая позволяет процессору с опережением декодировать команды ветвлений для полного использования конвейеров. В семействе процессоров P6 блок выборки/декодирования команд использует оптимизированный алгоритм прогнозирования ветвлений для предсказания направления потока команд в многоуровневом ветвлении, вызовах процедур и возвратах из них. В семействе процессоров P6 блок диспетчеризации/выполнения команд может одновременно следить за многими командами и выполнять их в порядке, который оптимизирует множественное выполнение до тех пор, пока сохраняется целостность данных. Такой режим держит занятым блок выполнения команд даже тогда, когда происходит кэш-промах, и при зависимости данных в командах. Прогностическое выполнение – это возможность процессора выполнять команды впереди счетчика команд, но фиксировать результаты в порядке поступления команд. Для обеспечения возможности прогностического выполнения в микроархитектуре семейства процессоров P6 разделяется диспетчеризация и выполнение команд. Процессорные блоки диспетчеризации/выполнения используют анализ потока данных для выполнения всех доступных команд в накопителе команд и временно сохраняют результаты в буферных регистрах. Блок сброса ищет в накопителе команд выполненные команды, в которых нет зависимостей данных с другими командами или неразрешенных ветвлений. Когда завершенные команды найдены, блок сброса фиксирует результаты этих команд в памяти или в регистрах в порядке их поступления и удаляет эти команды из накопителя команд. На рис. 2.12 показана более подробная функциональная схема архитектуры семейства процессоров P6, которая включает следующие подсистемы обработки: - подсистема памяти; - устройство выборки/декодирования; - накопитель команд (буфер переупорядочивания); - устройство диспетчеризации/выполнения; - блок сброса. Подсистема памяти для семейства процессоров P6 состоит из основного ОЗУ, первичного кэша (L1) и вторичного кэша (L2). Блок интерфейса шины обращается к системе памяти через внешнюю системную шину разрядностью 64 бит. Эта шина работает на основе транзакций – каждая операция доступа к шине обрабатывается как отдельная операция запроса и ответа. Пока шинный интерфейс ожидает ответ на запрос к шине, он может выполнить множество дополнительных запросов. Например, обращаться к кэшу L2 через 64‑битную (в последних моделях – 256-битную) шину кэша. Блок интерфейса шин обращается к вторичному кэшу по отдельной 64-битной шине, также ориентированной на транзакции. Эта шина способна обслуживать до четырех одновременных запросов. Тактовая частота шины кэша, в зависимости от модели процессора, равна частоте ядра или ее половине. Доступ к первичному кэшу идет по внутренней шине, работающей на частоте ядра. Четырехканальный наборно-ассоциативный первичный кэш инструкций имеет размер 8 Кб. Двухканальный наборно-ассоциативный первичный кэш данных (тоже 8 Кб) является двухпортовым – за один такт он может одновременно выполнить 1 запись и 1 чтение. Обмен кэша и памяти поддерживается протоколом MESI, который позволяет работать и в мультипроцессорных конфигурациях. Запросы к памяти от исполнительных блоков процессора проходят через блок интерфейса памяти и блок переупорядочивания запросов к памяти. Эти блоки предназначены для выравнивания потоков запросов к памяти через кэш и предотвращают блокировку (заторы) запросов. Первичный кэш свои промахи автоматически направляет к вторичному, а если промах произойдет и во вторичном кэше, то запрос через системную шину выйдет уже на основную память. Запросы к основной памяти и вторичному кэшу проходят через блок переупорядочивания запросов к памяти, который выступает в роли планировщика и диспетчера. В его ведении находятся все запросы к памяти, и он может менять порядок их исполнения для предотвращения блокировок и повышения производительности. Он может выполнять и спекулятивные чтения (но не записи). Устройство выборки/декодирования включает блок выборки команд, буфер возможных переходов, декодер команд, последовательность микрокода и таблицу псевдонимов регистров. Устройство диспетчеризации/выполнения содержит буфер резервации, 2 АЛУ, 1 блок с плавающей точкой x87, 2 блока генерации адреса и 2 SIMD-блока с плавающей точкой. Накопитель команд имеет массив регистров переупорядочивания. Блок сброса фиксирует результат прогностического выполнения микрокода в постоянное машинное состояние и удаляет микрокод из буфера переупорядочивания. Как и буфер резервации, блок сброса непрерывно проверяет состояние микрокода в буфере переупорядочивания – ищет те операции, которые были выполнены и у которых нет никаких зависимостей с другими микрооперациями в накопителе команд. Затем он “сбрасывает” завершенные микрооперации в их оригинальном порядке, принимая во внимание прерывания, исключения и промахи в прогнозировании перехода. Суперконвейеризация в семействе P6 делит ступени стандартного конвейера на более мелкие части. Очевидно, что с увеличением числа ступеней каждая отдельная ступень выполняет меньшую работу и, следовательно, содержит меньше аппаратной логики в каждой схеме. 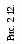                                   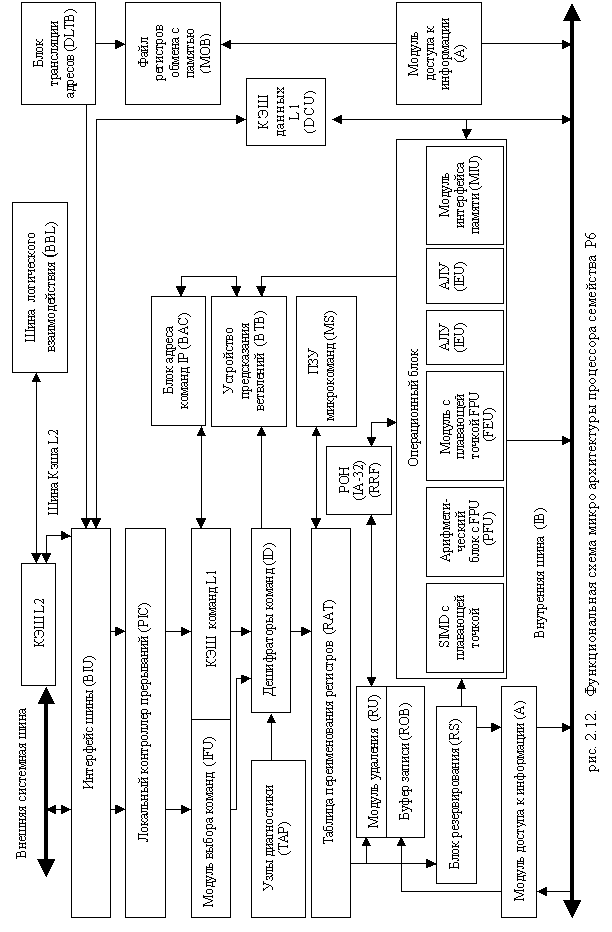 Временной интервал между поступлением набора входных воздействий на входы схемы и появлением результирующих сигналов на ее выходах (задержка распространения) в результате становится существенно меньше. Благодаря более коротким задержкам распространения сигнала в каждой отдельно взятой ступени конвейера становится возможным существенное повышение тактовой частоты. Рассмотрим поэтапную работу конвейера процессора P6, состоящего из 10 стадий, представленных в табл. 2.3. Конвейер можно разделить на 3 самостоятельных функциональных части: входной блок упорядоченной обработки, отвечающий за декодирование и обработку команд; ядро исполнения с изменением последовательности, где, собственно, и происходит выполнение команд, и конвейер упорядоченного вывода команд из последовательности. Блок выборки команды IFU считывает поток инструкций из L1 кэша команд строками по 32 байта за такт. Для поиска начального адреса команды используется текущий указатель команды IP. По этому адресу извлеченные и выровненные до 16 байт команды передаются на три дешифратора. Если команда находится в конце первой строки кэша, считывается вторая строка кэша. Указатель команды управляется блоком вычисления адреса команды BAC с помощью информации, полученной от буфера адреса перехода BTB, учитывающей предысторию ветвлений. Таблица 2.3 |