Лекции_Вычислительные машины_new. Лекция История развития вычислительной техники
 Скачать 5.16 Mb. Скачать 5.16 Mb.
|

Структура конвейера процессора Р6
Предсказание переходов (ветвлений) призвано свести к минимуму холостую работу конвейера и обеспечить его непрерывным потоком команд. Вообще, в среднем до 10 % кода программы составляют безусловные переходы, передающие управление по новому указанному адресу, и от 10 до 20 % – условные переходы, которые меняют или не меняют ход выполнения программы в зависимости от результата вычисления условия (состояния флага). В случае, если условный переход не выполняется, программа просто продолжает выполнение следующей по порядку команды. Безусловные переходы задержек не вызывают, процессор просто начинает выборку команд по указанному адресу. Команды условных переходов представляют определенные трудности, потому что процессор не знает, будет ли выполнен переход до тех пор, пока команда не пройдет исполнительную ступень конвейера. Однако ожидание, пока команда ветвления покинет исполнительную ступень, означает временный отказ от возможности выборки и обработки дальнейших команд. Для предсказания переходов процессор использует расширенный алгоритм Йеха (Yeh), позволяющий с большой достоверностью спрогнозировать, будет ли выполняться переход. Буфер возможных переходов на 512 адресов анализирует наборы команд программы. Внутри этого набора команд может быть несколько ветвлений, вызовов процедур и возвратов из них, и все они должны быть правильно предсказаны. Если предсказание окажется верным, то исполнение продолжится с малой задержкой или совсем без задержки. Если же предположение ошибочно, то частично выполненные команды придется удалять из конвейера, а новые команды выбирать из области памяти с правильным адресом, декодировать и выполнять их. Это повлечет за собой существенное снижение производительности, напрямую зависящее от глубины конвейера – для архитектуры P6 в случае ошибочного предсказания перехода потери составят от 4 до 15 тактов. Алгоритм предсказания ветвлений выбран динамическим двухуровневым. Он основывается на анализе поведения команд перехода за предшествующий период времени в цикле, а также на поведении конкретных групп команд, для которых с большой вероятностью можно предсказать переход. Точность предсказания данного алгоритма составляет около 90 %. Выровненные 16-байтовые команды передаются в дешифратор команд, состоящий из трех параллельно работающих дешифраторов ID 0-2, два из которых – простые и один – сложный. Задача каждого дешифратора – преобразование IA инструкции в одну или несколько микрокоманд (на каждый микрокод два логических источника и один логический результат). Простые дешифраторы, обрабатывая команды x86, транслируют их в единственную микрокоманду. Сложный дешифратор работает с командами, которым соответствуют от одной до четырех микрокоманд. Некоторые особенно сложные команды невозможно непосредственно декодировать даже сложным дешифратором, поэтому они передаются в планировщик последовательности микрокоманд MIS, генерирующий необходимое число и последовательность микрокоманд. Если простой дешифратор встречает команду, которая не поддается трансляции, то она передается в сложный дешифратор либо в планировщик последовательности микрокоманд. Такая пересылка замедляет дешифрацию, что за счет буферизации с помощью станции-резервуара (RS) не очень значительно сказывается на производительности. Последним этапом перед выполнением команд является закрепление микроопераций за дополнительными свободными физическими регистрами (отображение), осуществляемое в таблице псевдонимов регистров RAT. Для назначения внутренних регистров поставленные в очередь микрооперации из дешифратора команд посылаются в таблицу псевдонимов регистров RAT, где логические регистры IA преобразуются во внутренние ссылки на физические регистры. Программная архитектура x86 предусматривает только восемь 32-разрядных регистров общего назначения и вероятность того, что две соседние команды при параллельном исполнении будут использовать один регистр, относительно велика. Поэтому процессор "размножает клонированием" ограниченное число программных регистров и отслеживает, какие «клоны» содержат наиболее поздние значения. Это предотвращает задержки, которые в противном случае были бы внесены в процесс параллельной обработки команд в результате конфликтных обращений к регистрам. Распределитель в таблице псевдонимов регистров добавляет бит статуса и флаги к микрокоду (готовит для нестандартного выполнения) и посылает результирующую микрооперацию в накопитель команд. При отображении регистров происходит преобразование программных ссылок на архитектурные регистры в ссылки на 40 физических регистров микрокоманд, реализованных в буфере восстановления последовательности. Эти регистры могут содержать целые значения и числа с плавающей точкой. В случае, если сложные и простые команды выровнены, то дешифраторы способны генерировать в общей сложности 6 микрокоманд за такт. Но, как правило, из всех 3 дешифраторов за один такт выдаются 3 микрокоманды, соответствующие в среднем 2-3 IA командам, которые передаются в буфер восстановления последовательности (ROB). ROB – это массив ассоциативной памяти, который содержит 40 регистров размером 254 бит. Каждый из них может хранить микрокоманду, 2 связанных с ней операнда, результат и несколько флагов состояния. Станция-резервуар RS выступает диспетчером и планировщиком микрокоманд, для чего непрерывно сканирует буфер восстановления последовательности, выбирает и раздает команды, готовые к исполнению (имеющие все исходные операнды). Результат выполнения возвращается назад в буфер RRF и сохраняется вместе с микрокомандой до вывода. Порядок исполнения команд основывается не на их первоначальной последовательности, а на факте готовности команды и ее операндов к исполнению, это и есть исполнение с изменением последовательности. Когда одновременно доступны две или более микрооперации одного типа (например, операции над целыми), они выполняются буфером переупорядочивания в порядке "первым пришел - первым обслужился". Если дешифраторы приостановили работу, исполнительные блоки продолжают работать, пользуясь микрокомандами, поставляемыми резервуаром, а в случае занятости исполнительных устройств резервуар приостанавливает работу дешифраторов. Выполнение до пяти микрокоманд за такт процессора осуществляется двумя целочисленными блоками АЛУ(IEU), двумя блоками вычислений с плавающей точкой FPU и PFU и одним блоком взаимодействия с памятью MIU. Два целочисленных блока способны исполнять две целочисленные микрооперации одновременно. Один из блоков разработан специально для анализа перехода. Он способен обнаруживать ошибочно предсказанный переход и оповещать буфер предсказания переходов о необходимости перезапуска конвейера. Рассмотрим это подробнее. Дешифратор прикрепляет к команде перехода оба адреса – предсказанный адрес перехода и предварительно признанный неудачным. Когда целочисленный блок исполнения выполняет операцию перехода, он в состоянии определить, какая из ветвей была выбрана. В случае перехода по предсказанию все предварительно накопленные и выполненные команды данной ветви маркируются как годные для дальнейшего использования и продолжается исполнение данной ветви программы. В противном случае блок выполнения перехода в целочисленном блоке изменяет статус всех команд данной ветви на "подлежащие удалению". Потом передает в буфер адреса перехода правильный адрес перехода, и буфер, в свою очередь, перезапускает конвейер с этого адреса. Блок взаимодействия с памятью отвечает за выполнение микрокоманд загрузки и сохранения. Загрузка требует только указания адреса памяти, поэтому может быть представлена одной микрокомандой. Сохранение требует также указания содержимого для сохранения, поэтому кодируется двумя микрокомандами. Часть блока, обрабатывающая микрокоманды сохранения, имеет два порта, что позволяет обрабатывать адреса и данные параллельно. Также возможно параллельное выполнение операций загрузки и сохранения в одном такте. Для операций с плавающей точкой предусмотрены два блока вычислений FPU и PFU, причем второй предназначен для обработки SIMD-инструкций. Команды, которые исполняются не в той последовательности, которая предписана программой, располагаются затем в должной последовательности – иначе процессор не всегда сможет получить правильные результаты. Буфер восстановления последовательности сохраняет статус исполнения и результаты каждой микрокоманды. Микрокоманда выводится блоком вывода, который подобно станции-резервуару сканирует буфер восстановления последовательности на предмет обнаружения микрокоманд, которые уже не повлияют на выполнение других микрокоманд. Такие команды признаются завершенными, и блок вывода выстраивает их в первоначальную последовательность, учитывая прерывания, исключения, точки останова и неверные предсказания переходов. Блок вывода способен выводить 3 микрокоманды за такт. При выводе микрокоманды результаты записываются в выводящий регистровый файл RRF или память. Выводящий регистровый файл содержит 8 регистров общего назначения и 8 регистров для данных с плавающей точкой. После того, как микрокоманда выведена, она удаляется из буфера восстановления последовательности. Операции записи в память откладываются до тех пор, пока команда не будет выведена. Для этого в P6 предусмотрен буфер упорядочения обращений к памяти MOB, в котором по командам, выдаваемым блоком записи в память, сохраняется информация о данных и адресах. Буфер упорядочения обращений к памяти пересылает данные в память только после того, как буфер восстановления последовательности уведомит его о том, что микрокоманда, произведшая запись в память, удаляется. Процессор PentiumProНачиная с 1995 г. Intel приступила к выпуску серийного CISC-процессора P6 шестого поколения i686 под торговой маркой Pentium Pro с напряжением питания около 3 В. Он содержит 5 500 тысяч транзисторов на кристалле и изготовлен по 0,35 мкм технологии в корпусе с 387 выводами. В создании этого процессора разработчики воспользовались всеми техническими решениями, ранее применяемыми в суперЭВМ. К таким решениям относятся включение в структуру процессора устройств динамического определения порядка выполнения команд и нескольких многоступенчатых конвейеров. В отличии от двух 5-ступенчатых конвейеров Pentium, P6 имеет три 10-ступенчатых. Увеличение числа конвейеров и ступеней обработки команд в них позволило увеличить внутреннюю тактовую частоту синхронизации, которая стала равной 133, 166, 180, 200 МГц и более. В Pentium Pro для повышения производительности вычислений за счет увеличения внутренней тактовой частоты внедрены следующие структурные дополнения в семейство х86: - применено динамическое исполнение команд, при котором команды, не зависящие от вычислений ранних операций в программе, выполняются в измененном сдвоенном порядке с передачей результатов в закрепленном в программе порядке; - использован тыльный кэш-2 с двумя раздельными системными шинами обмена: скоростной короткой для обмена между МП и кэш-2; традиционной процессорной с частотой синхронизации 66,6 МГц; - внешний кэш-2 емкостью 256 или 512 Кб размещен в корпусе МП; - внедрены дополнительные средства контроля ECC при обмене в системной шине, кэш-2, ОЗУ и возможность контроля дублированием вычислений вторым МП в режиме FRC; - системная шина с программируемым контроллером и интерфейсом APIC обеспечивает мультипроцессорную обработку до 4 МП, объединенных в единую систему. Увеличение частоты синхронизации позволяет повысить быстродействие обработки команд, что, в свою очередь, требует повышения скорости обмена с внешним ОЗУ. Чтобы исключить задержки обмена с ОЗУ, в кристалле процессора смонтирована буферная память второго уровня (кэш-2) емкостью 256 Кб. Блок кэш-2 связан внутри процессора через интерфейс памяти собственной синхронной внутренней 64-разрядной шиной данных, работающей на тактовой частоте процессора. С целью эффективного вычисления последовательности команд в Pentium Pro используется буфер предсказания ветвлений ВТВ0, ВТВ1 на 512 входов. Использование этих блоков позволило разработчикам добиться наибольшей загрузки двух блоков целочисленной арифметики (АЛУ), сопроцессора (FPU), блоков записи и загрузки, увеличив производительность по сравнению с Pentium на 35 – 45 %. Эта производительность оказалась всего лишь в 1,5 раза меньше, чем у самого быстрого RISC-процессора DEC Alpha 21164. Схема МП Pentium Pro показана на рис. 2.13. Процессор Pentium Pro выполняет вычисления в конвейере в следующей последовательности. Операционная система загружает из ОЗУ через системную шину в кэш-2 массивы данных и набор команд для выполнения программ, которые образуют очередь с приоритетами и привилегиями. Первая программа из очереди одновременно загружается в кэш-1 команд, а операнды, с которыми она работает, передаются в кэш-1 данных. Адреса команд и данных располагаются в блоке тэгов обоих кэш-1, и в случае промаха при обращении к кэш-1 недостающие команды или данные постоянно доизвлекаются чаще всего из кэш-2 и реже, при отсутствии в нем, из основного ОЗУ. На первой ступени дешифрирования (DC) три команды динамически распределяются на параллельную обработку во вторую ступень дешифрации ID1 (распределение на параллельную обработку в целочисленные АЛУ и FPU). В результате после второй ступени дешифрации в каждом такте могут появляться одновременно до шести микроопераций, подлежащих выполнению в операционном блоке (Port 0 - 4) ядра процессора. Эти микрооперации закрепляются за регистрами в блоке переименования регистров и выделения ресурсов RAT. Блок переименования регистров RAT позволяет закрепить для выполнения операций более восьми РОН, используемых для программирования. При наличии нескольких конвейеров это даёт возможность одновременно выполнять несколько команд, ссылающихся на одни и те же регистры в разных конвейерах по мере их освобождения. 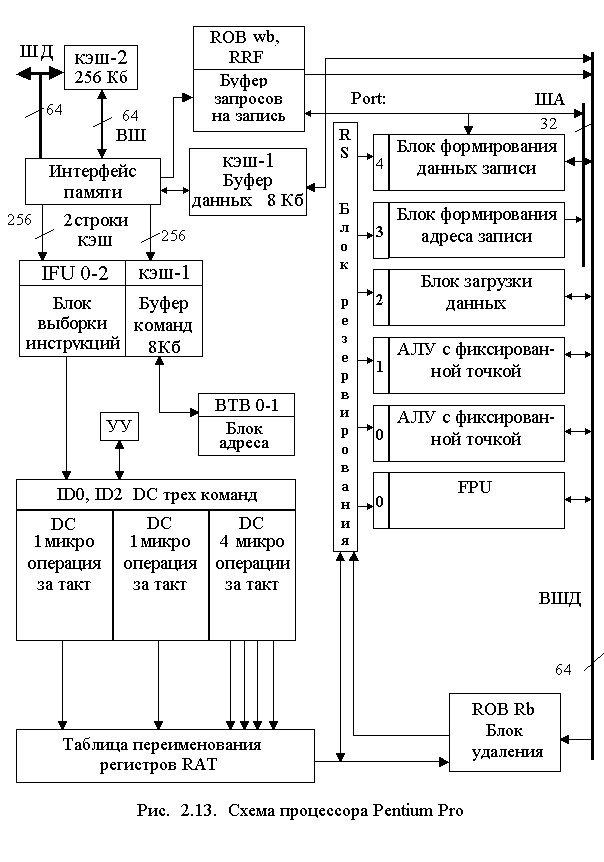  После RAT набор микроопераций направляется в блок резервирования RS и буфер переупорядочивания чтения ROB Rd, который осуществляет вычисление адресов операндов и загрузку ими переименованных регистров РОН в двух целочисленных АЛУ. После выполнения микроопераций ROB Rd удаляет их из блока резервирования RS. Блок RS является начальной ступенью произвольной обработки в ядре МП. В нем микрооперации могут ожидать операнды или устройства для выполнения операции. Если операнды доступны и устройства свободны, микрооперация направляется на исполнение через один из портов Port 0 - 4 минуя такты ожидания. Результаты выполнения микроопераций передаются в переупорядочивающий буфер записи ROB wb и файл регистров RRF, способный принимать за один такт три операнда. В этом блоке результаты окончания операций ожидают освобождения ШД для записи в кэш и ОЗУ. Для чего им восстанавливается порядок, соответствующий порядку результатов при выполнении закодированной программы. Для Pentium Pro Intel разработала два чипсета PCI: 82450GX (для серверов) и 82450FХ (для рабочих станций) и специальное программное обеспечение, обеспечивающее параллельную обработку команд в конвейере с 32 - разрядными числами. Хотя Pentium Pro программно совместим с предыдущими моделями микропроцессоров x86, эффективное его использование в персональных компьютерах сдерживалось дороговизной ЭВМ и недостаточным количеством необходимого программного обеспечения. Процессор PentiumII Процессор Pentium II, ранее носивший название Klamath, характеризуется дальнейшим увеличением быстродействия процессоров Pentium, совместимых с архитектурой x86. Объединив технологию MMX и архитектуру ядра МП Pentium Pro, фирма Intel с мая 1997 года начинает производить процессор Pentium II по 0.35-мкм КМОП-технологии с четырьмя слоями металлизации. Центральное ядро содержит 7,5 млн транзисторов и располагается на площади 203 мм2. Кристалл Pentium II размещается в пластмассовом корпусе PLGA, имеющем матрицу из 528 миниатюрных контактных площадок. Этот корпус устанавливается на одной процессорной мини-плате, уменьшающей отбраковку МП при производстве, вместе с кэш второго уровня и микросхемой памяти для хранения тэгов Tag RAM. Он закрыт в картридже общей крышкой, которая и охлаждается специальным вентилятором. Картридж с односторонним расположением контактов (S.E.C.С.) устанавливается в специально разработанный фирмой Intel разъём Slot1 на системной плате. Картридж может быть легко модифицирован с появлением новых промышленных кристаллов МП, кэш-2, памяти тэгов и контроллера кэша. Используя размер стока транзистора 0.28 мкм, Intel удалось повысить предельное быстродействие и достигнуть тактовой частоты от 233 до 450 МГц. На частоте 266 МГц Pentium II потребляет до 38 Вт электроэнергии. Внешняя тактовая частота процессора остается 66,6 МГц, что не позволяет более эффективное использование SDRAM, предназначенной для работы на частотах 83 и 100 МГц. С использованием двухпроцессорного режима SMP и интерфейса APIC возможна работа МП как в режиме параллельной обработки информации, так и в режиме контроля одного процессора другим в системе FRC. В процессорах Pentium Pro и Pentium II для расширения адресного пространства используется шина запроса памяти REQ (3,0). В режиме обмена с памятью, дополняя ША до 36 бит, она позволяет работать МП с памятью до 64 Гб. Архитектура ядра Pentium II мало отличается от архитектуры Pentium Pro. Традиционная система команд х86 реализуется с использованием методов, заимствованных у RISC-процессоров. При этом каждая операция преобразуется в последовательность простых микрокоманд. Эти простейшие микрокоманды выполняются с использованием принципов множественного предсказания переходов, исполнения команд по предположению и с изменением последовательности способа переименования регистров, что позволяет организовать параллельную конвейерную обработку нескольких команд. Однако архитектуры Pentium II и Pentium Pro имеют два существенных отличия. Pentium II специально создан для скоростной обработки мультимедиа-приложений, сочетает использование до 40 Мб видеопамяти с выполнением высококачественных ускоренных графических процессов, включающих до 512 Мб ОЗУ SDRAM, и обменом через новую шину AGP с профессиональным графическим ускорителем и поддержкой разрешения 1600х1280 при 16.7 млн цветов. МП поддерживает мультимедийное расширение набора команд (MMX). Для исполнения команд ММХ ядром Pentium Pro в Pentium II введены порты: - Port 0, содержащий АЛУ ММХ и умножитель ММХ; - Port 1, содержащий АЛУ ММХ и устройство сдвигов ММХ. Кроме того, Pentium II имеет средства переименования сегментных регистров. Использование этих средств ускоряет работу процессора под управлением 16-разрядных программ. При выполнении в Pentium Pro ранее разработанных 16-разрядных программ изменение содержимого сегментных регистров происходит часто. При этом обновление содержимого сегментного регистра требует очистки конвейера от команд, то есть необходимо выполнить все команды, использующие текущее значение сегментного регистра, до его обновления. С учетом времени, необходимого на передачу результатов для записи, полученная задержка составит почти 30 тактов. Pentium II в этом режиме выполняет запись в регистры по предположению, что позволяет командам, использующим старое значение сегмента, сосуществовать с командами, использующими новое значение сегмента. Ускорение работы 16-разрядных приложений может составить до 50% на той же частоте по сравнению с процессором Pentium Pro. Pentium II может обрабатывать 57 MMX-команд, при этом используется 8 адресуемых 64-разрядных регистров ММХ. Наличие команд поддержки режима MMX позволяет ускорить обработку мультимедиа-приложений при соответствующем программном обеспечении. Для компенсации относительно медленной работы кэш второго уровня размер внутреннего кэш был увеличен вдвое: с 16 Кб до 32 Кб (16 Кб для хранения команд и 16 Кб – для данных), где кэш-1 данных разбит на 8 чередующихся банков. Увеличение объема внутреннего кэша позволяет снизить частоту обращений к внешней памяти. Для установки Pentium II разработаны системные платы с набором ИС 440 LX, конструктивно несовместимые с ранее выпускавшимися процессорами. В январе 1998 г. Intel представила, кроме МП Pentium II 233, 266 и 300 МГц, четвертый по счету процессор семейства Pentium II, имеющий тактовую частоту 333 МГц на кристалле, содержащем 7.5 млн транзисторов (каждый транзистор в 400 раз меньше диаметра человеческого волоса). Он выпущен с применением передовой тогда 0,25 мкм производственной технологии Intel. Процессор Pentium II 333 МГц имеет наивысшую производительность по сравнению с предыдущими моделями при выполнении целочисленных операций и при работе с мультимедиа (для обработки звука, видео, оцифрованных изображений и поддержки видеоконференций). Процессор Pentium II 333 МГц имеет все те же характеристики, что и ранее выпущенные версии процессора Pentium II, в том числе: архитектуру двойной независимой шины (DIB), режим динамического исполнения, набор мультимедийных команд технологии Intel MMX и шину кэш-памяти второго уровня (L2) 512 Kб, работающую на частоте, в два раза меньшей тактовой частоты процессора. Для процессора Pentium II 333 МГц частота шины кэш-памяти L2 составляет 166.5 МГц. При работе со стандартными офисными приложениями процессор Pentium II 333 МГц превосходит процессор Pentium II 300 МГц по производительности на 10 %. Более ощутимо преимущество процессора Pentium II 333 МГц при его сравнении с процессором Pentium MMX, имеющим тактовую частоту 233 МГц. Притом что разница тактовых частот этих процессоров составляет 42 %, Pentium II 333 МГц превосходит его по производительности на 50 – 80 %. Характеристики процессора Pentium II представлены в табл. 2.4, из которой видно, что в дальнейшем было выпущено еще несколько его модификаций вплоть до Pentium II 450 МГц. Вторичный кэш в Pentium II медленнее, чем в Pentium Pro. Он построен по четырёхканальной множественно-ассоциативной синхронной структуре без блокирования на элементах статической памяти SRAM и работает в пакетном режиме. Частота тыльного кэш второго уровня в два раза ниже, чем внутренняя частота процессора. Емкость кэш второго уровня составляет 512 Кб, однако в других вариантах процессора Pentium II может устанавливаться кэш меньшей емкости (256 Кб). Процессор Pentium III Процессор Pentium II , как описано в п. 2.5.(«Процессор Pentium II»), изготовлен на основе ядра Klamath по технологии 0,35 мкм с частотой внешней шины 66 МГц. Затем на основе Klamath фирмой Intel было разработано ядро Deschutes для 0,25 мкм технологии и изготовлен Pentium II с частотой шины 100 МГц и Pentium II Xeon (Зеон), отличающиеся более высоким быстродействием и емкостью кэш-2, и дешевый Celeron (в начале без кэш-2 с частотой внешней шины 66 МГц). Позже на базе Deschutes было разработано ядро с интегрированным в тот же корпус быстрым кэш-2 Mendocino, на базе которого выпускались все Celeron «А» (с внутренним кэш-2 емкостью 128 Кб). Затем Intel разработала МП Dixon с емкостью 256 Кб встроенного кэш-2. Это Celeron с увеличенным кэш-2 вдвое. Но так как он работает как Pentium II, то имеет другое название. В начале 1999 г. на основе ядра Katmai изготовлены Pentium III и Pentium III Xeon (Tanner). В конце 1999 г. на базе ядра Coppermine по 0,18 мкм технологии изготовлен Pentium III и Pentium III Xeon (Cascades), имеющие как Mendocino быстрый интегрированный кэш-2. С 2001 г. Pentium III выпускается по 0,13 мкм (металлизация Cu) технологии на базе ядра Tualatin с частотой шины 1400 МГц и дешевый Celeron (1.2 и 1.3 ГГц). Так, ядро Coppermine имеет кэш-2 емкостью 256 Кб, который работает синхронно с МП. Организация внутреннего кэш-2 изменена. Он представляет собой 8-канальный ассоциативный буфер с 256-разрядной шиной ядра. Обмен МП с кэш-2 требует новых протоколов, то есть обновленной BIOS. В процессоре Pentium III оптимизирована схема внутренней буферизации (4 буфера с обратной записью; 6 буферов заполнения; 8 входов очереди шины). Оптимизация привела к сокращению времени ожидания данных из кэш-2 и увеличению производительности МП на той же частоте на 10 – 20 %. Повышение тактовой частоты до 1000 МГц достигнуто за счет уменьшения технологических норм, добавления 6 слоя алюминиевой металлизации и улучшения внутренней разводки цепей МП. Согласующие резисторы и конденсаторы, которые ранее устанавливались на плате процессорного модуля для Slot 1, перенесены в кристалл СБИС. Напряжение питания ядра понижено до 1.1 – 1.65 В. Таким образом, начиная с 1999 г. фирма Intel осуществляет серийный выпуск процессора Pentium III разных модификаций по 0.25 и 0.13 мкм технологии с внутренней частотой синхронизации от 450 до 1400 МГц. Pentium III в зависимости от модификации ядра изготавливается на кристалле, содержащем от 9.5 до 42 млн транзисторов. Он ориентирован на применение в настольных (Pentium III 450/500/533ЕВ/…/1400), портативных (Mobill Pentium III 400/500/600) ПК, а также для работы в серверах (Pentium III Xeon 600B/667B//1000B). С индексом ”В” процессоры используются в системных платах с частотой системной процессорной шины FSB 133 МГц. Процессоры Pentium III с индексом ”Е” имеют напряжение питания 1.6 В и изготовлены по 0.18 мкм технологии с внутренним кэш-2 емкостью 256 Кб, размещённым в кристалле процессора. В связи с этим Pentium III Е выпускается как в виде картриджа S.E.C.C.2 с разъёмом Slot 1, так и в виде одной СБИС в новом корпусе FCPGA с разъёмом Socket 370. С появлением Celeron, а затем Pentium III и Xeon осуществлялся переход спецификации процессорной шины и стандарта разъёма МП Slot 1 на Socket 370, а затем на Socket FCPGA. Для Xeon был разработан свой стандарт разъёма Slot 2. Mobill Pentium III питается от источника с пониженным напряжением 1.35 В и тактового генератора с частотой 100 МГц. Он оснащен встроенным в МП кэш-2 емкостью 256 Кб и блоком SSE. У Pentium III 0.25 мкм технологии кэш-2 емкостью 512 Кб размещается на процессорной плате. Обычный Pentium III поддерживает двухпроцессорную конфигурацию, а Хеоn до 4 МП. Хеоn может взаимодействовать с внешним тыльным кэш-2 емкостью до 2 Мб, работающим на частоте процессора, что позволяет намного увеличить его быстродействие вычислений по сравнению с обычным Pentium III . Новый картридж процессора Pentium III, заключенный в корпус с односторонним расположением контактов SECC2, упрощает конструкцию системных плат, предназначенных для работы с этим процессором, облегчает массовое их производство, безопасность при использовании и обеспечивает единый форм-фактор процессоров будущего. SECC2 – некое промежуточное звено между стандартным SECC и его полным отсутствием. В нём радиатор, обдуваемый вентилятором, соприкасается не с железной пластиной, прижатой к ядру, а непосредственно с микросхемой, обеспечивая лучший отвод тепла от кристалла, помещенного в новый органический сплав на основе меди OLGA. Pentium III имеет следующие особенности: 1.Обеспечивает одновременно технологии потоковых SIMD-расширений SSE для Internet, динамического исполнения команд и технологию MMX. 2.Имеет архитектуру независимой двойной шины DIB, что увеличивает пропускную способность и производительность его по сравнению с процессорами с единственной шиной данных. 3.Содержит функцию серийного номера процессора для расширения степени управляемости ЭВМ. 4.Имеет неблокируемую кэш-1 первого уровня емкостью 32 Kб (16 Кб/16 Кб) и унифицированную неблокируемую кэш-2 второго уровня емкостью 512 Кб, что обеспечивает ускоренный доступ к часто используемым данным. 5.Поддерживает кэширование памяти с объемом адресного пространства 4 Гб. 6.Позволяет создавать масштабируемые системы с двумя процессорами и физической памятью объемом до 64 Гб. 7.Поддерживает тестирование и мониторинг производительности. 8.Совместим по кодам с существующим программным обеспечением и процессорами предшествующих поколений на базе архитектуры Intel. Потоковые SIMD-расширения SSE для Internet (MMX2) представляют собой 70 новых команд, сгруппированных в следующие категории: 1.Команды копирования данных movaps,…, movss. Команды этой группы выполняют операции параллельного копирования упакованных элементов данных (PS), а также скалярного (SS) копирования только младшего элемента операнда. Действия производятся над операндами, расположенными в XMM‑регистрах или в памяти. 2.Арифметические команды SIMD выполняют сложение (addps, addss), вычитание, умножение (mulps, mulss), деление (divps, divss) и другие операции данных одинарной точности с плавающей точкой. Входной (второй) операнд этих команд может располагаться либо в SIMD‑регистре, либо в памяти. Выходной (первый) операнд должен находиться в SIMD-регистре. Арифметические команды поддерживают как параллельные, так и скалярные операции. 3.Команды сравнения cmpps,cmpss и другие попарно сравнивают все четыре соответствующих FP‑элемента двух операндов (для скалярного (SS) варианта команд – только младшие элементы), устанавливают соответствующие флаги в регистре EFLAGS и проверяют выполнение арифметического условия, специфичного для каждой команды. Если для сравниваемой пары условие выполняется, то в соответствующие 32 разряда выходного операнда записывается маска из всех единиц. В противном случае – маска из нулей. Получаемая в результате двоичная маска обычно используется при логических операциях с объектами. 4.Команды преобразования типов данных выполняют преобразования данных из 32-разрядного целочисленного представления со знаком в FP-представление и обратно. Эти команды производят преобразование упакованных и скалярных данных между 128‑битными SIMD регистрами с плавающей точкой и также с 64-битными целыми MMX регистрами или 32-битными целыми регистрами IA-32. 5.Логические команды andps, andnps, orps и xorps часто используются для вычисления абсолютной величины (модуля) чисел; изменения знакового разряда (инверсии знака); действий с маской из нулей и единиц. 6.Дополнительные целочисленные SIMD-команды, команды перестановки, управления состоянием, управления кэшированием. В Pentium III введён еще один блок, подобный MMX, только оперирующий с вещественными числами. Основной тип данных SSE это 128-разрядное значение, содержащее 4 последовательно расположенных (“упакованных”) 32-разрядных числа одинарной точности с плавающей точкой SPFP, как показано на рис. 2.14.
Рис. 2.14. Упакованное простое число с плавающей точкой Каждое 32-разрядное число с плавающей точкой (см. рис. 1.2.) имеет 1 знаковый бит, 8 битов порядка и 23 бита мантиссы, что соответствует стандарту IEEE-754 на формат представления чисел одинарной точности с плавающей запятой. SIMD-инструкции оперируют в новом модуле SSE со специальными 128-битными регистрами XMM0-XMM7 и улучшают работу с приложениями трехмерной графики, потокового аудио, видео и распознавания речи. Каждый из этих регистров хранит 4 вещественных числа одинарной точности (ОТ). Потоковое расширение SIMD архитектуры Intel поддерживает 2 типа операций над упакованными данными с плавающей точкой – параллельные и скалярные. Параллельные операции (ОР), как правило, действуют одновременно на все четыре 32-разрядных элемента данных в каждом из 128-разрядных операндов, как показано на рис. 2.15. В именах команд, выполняющих параллельные операции, присутствует суффикс ps. Например, команда addps складывает 4 пары элементов данных и записывает полученные 4 суммы в соответствующие элементы первого операнда. Скалярные операции действуют на младшие (занимающие разряды (31,0)) элементы данных двух операндов, как это показано на рис. 2.16. Остальные 3 элемента данных в выходном операнде не изменяются (исключение составляет команда скалярного копирования movss). В имени команд, выполняющих скалярные операции, присутствует суффикс ss (например, команда addss). 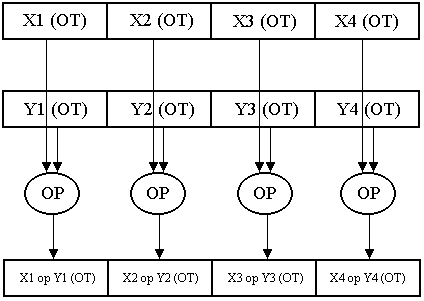 Рис. 2.15. Упакованные (параллельные) операции Большинство команд двухадресные и оперируют с двумя операндами. Данные, содержащиеся в первом операнде, могут использоваться командой, а после ее выполнения, как правило, замещаются результатами. Данные второго операнда в команде после ее выполнения не изменяются. Для всех команд адрес операнда в памяти должен быть выровнен по 16-байтной границе, кроме невыровненных команд сохранения и загрузки. 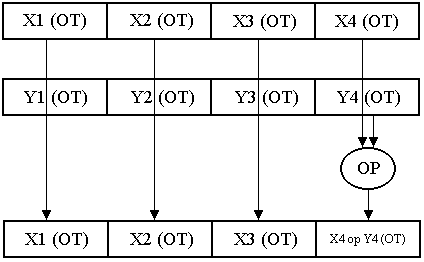 Рис. 2.16. Скалярные операции Таким образом, выполняя операцию над двумя регистрами, блок SSE фактически оперирует с четырьмя парами чисел. Благодаря этому процессор может выполнять до 4 одинаковых операций одновременно. Однако для выполнения четырех параллельных операций программист должен использовать специальные команды, а также позаботиться о помещении и извлечении данных из 128-битных регистров. Поэтому для использования всех вычислительных мощностей Pentium III необходима целенаправленная оптимизация. Внедрение потоковых SIMD-расширений позволяет существенно увеличить скорость и качество работы в реальном времени приложений, использующих: - трехмерную графику и 3D-моделирование, расчет освещенности с использованием вычислений с плавающей запятой; - обработку сигналов и моделирование процессов с широким диапазоном изменения параметров (вычисления с плавающей запятой); - генерацию трехмерных изображений в программах реального времени, не использующих целочисленный код; - алгоритмы кодирования и декодирования видеосигнала, обрабатывающие данные блоками; - численные алгоритмы фильтрации, работающие с потоками данных. Использование потоковых SIMD-расширений позволяет получить более высокое разрешение и качество изображений на дисплее, более высокое качество звука, видео и возможности параллельного кодирования и декодирования в формате сжатия цифровых кодов на оптический диск MPEG2, а также снизить загрузки процессора при распознавании речи и увеличить точность и быстродействие вычислений. Как указывалось выше, технология динамического исполнения команд в архитектуре Р6 обеспечивает предсказание ветвлений и прогнозирует исполнение программы по нескольким ветвям, позволяет осуществить анализ потока данных, оптимизацию и реорганизацию последовательности исполнения команд на основе используемых в них данных. Допускает спекулятивное исполнение команд на основе оптимизированной последовательности, которая увеличивает загрузку РОН и блоков процессора, что ведет к повышению общей производительности Pentium III. Кроме того, технология MMX обеспечивается в Pentium III набором 57 команд общего назначения для целочисленных операций, легко применимых к широкому спектру мультимедийных и коммуникационных приложений. Здесь также используются SIMD-инструкции, которые исполняются в восьми 64-разрядных регистрах MMX0-ММХ7. Серийный номер процессора – это электронный номер, позволяющий идентифицировать конкретную систему в больших компьютерных сетях. Тестирование и мониторинг производительности в Pentium III содержит следующие функции: - встроенный механизм самотестирования BIST обеспечивает постоянный контроль зависаний и сбоев в микрокоде и больших логических матрицах, а также тестирование кэш команд и кэш данных, буферов TLB и сегментов памяти ROM; - механизм стандартного порта доступа к тестированию и периферийному сканированию IEEE 1149.1 дает возможность осуществлять проверку каналов связи между процессором Pentium III и системой через стандартный интерфейс; - встроенные счетные устройства следят за показателями производительности и ведут подсчет событий. Таблица 2.4 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||