Лекции_Вычислительные машины_new. Лекция История развития вычислительной техники
 Скачать 5.16 Mb. Скачать 5.16 Mb.
|

|
5. Кэш-память Под кэш-памятью (кэш) понимается буферное оперативное, более высокого быстродействия, чем основное ОЗУ, запоминающее устройство, имеющее в своем составе схему быстрого поиска информации. Различают кэш первого уровня (L1), или внутренний, и второго уровня (L2), или внешний, подключаемый к шине процессора. Внутренний кэш работает с быстродействием МП, внешний – синхронно с устройствами шины процессора. Внутренний кэш является буфером между регистрами МП и ОЗУ. Если имеется внешний кэш, то он является буфером между внутренним кэш и ОЗУ. Кэш-2 может быть линейным, подключаемым к одной системной шине МП, или тыльным, выполняющим обмен по двум шинам, одна из которых осуществляет связь с МП на более высокой частоте, чем другая процессорная с ОЗУ. Иногда ЭВМ имеет в составе и кэш-3, которая является буфером между кэш-2 и ОЗУ. Емкость памяти внутреннего кэш определяется типом МП (8, 16 Кб и более), а память внешнего кэш может наращиваться при использовании Windows 95 до 512 Кб или до 2 Мб с 32 разрядными ОС, как OS/2, Windows NT и UNIX. Кэш строится на элементах SRAM с временем доступа 4.5 – 12 нс и схемах сравнения, и поэтому ощутимо дороже динамических ОЗУ. Для обмена информацией между кэш и ОЗУ используют 3 способа: - со сквозной записью; - со сквозной буферной записью; - с обратной записью. При сквозной записи результат операции передается МП одновременно в кэш и ОЗУ. При низком быстродействии ОЗУ МП простаивает, ожидая весь цикл записи. Увеличить быстродействие обмена удается при использовании сквозной буферной записи, когда МП ждет записи только в кэш, а для записи в ОЗУ информация передается в буферные регистры шинного интерфейса, а при свободной шине процессора затем передается в ОЗУ. Приоритет отдается операциям записи из МП в ОЗУ, и этот способ часто используются в алгоритмах, требующих синхронной смены информации в ОЗУ. Для многих задач адреса данных и следующих команд расположены рядом, при этом частично данные являются промежуточными и располагаются в одних и тех же ячейках памяти при выполнении различных операций. В таком случае большее быстродействие обмена обеспечивает способ с обратной записью. При таком способе данные из строк кэш передаются в ОЗУ только при изменении информации на новую запись из ОЗУ, когда стираемая строка в кэш обновляется МП при выполнении программы. Недостатком способа является старение информации в ОЗУ в процессе вычислений. Полное соответствие информации с кэш достигается только после решения задачи, когда кэш копируется в ОЗУ. При считывании в кэш все способы обмена работают одинаково. Для повышения быстродействия поиска информации в кэш используется ассоциативная [10] или адресно-ассоциативная [7] адресация. При ассоциативной адресации в качестве признака поиска (ключа, тэга) используется весь физический адрес. При адресно-ассоциативной адресации старшие разряды физического разряда используются для тэга, а младшие являются адресом ячейки внутри множества адресуемых ячеек. На рис. 3.7 приведена структура ассоциативной памяти. Физический адрес (ФА) с ША в виде, например, кода 01110 подается как тэг на схемы сравнения D1 DN+1. Наличие идентичности тэга с содержимым ячейки блока тэга (БТ) (например, с номером 0) включает соответствующую схему сравнения, выходной сигнал которой становится равен 1. Выходной сигнал 1 схемы сравнения (1 с D1) коммутирует соответствующую строку массива (0) на шину данных (ШД). Недостатками схемы являются значительные затраты памяти, требуемые для построения блока тэгов, и многочисленные поразрядные схемы сравнения. Число схем сравнения обычно равно числу строк. Преимущество – высокое быстродействие поиска из-за отсутствия дешифратора адреса. Снизить аппаратные затраты можно при помощи способа адресно-ассоциативной адресации (кэш прямого отображения), показанной на рис. 3.8. Кэш содержит массив данных из 0, 1 ..., N множеств. Каждое множество состоит из 0, 1, ..., ( В такой структуре кэш младшие разряды (смещение в команде или странице) используются для определения номера множества БТ с помощью DCA и номера строки с помощью дешифратора строк (DCC). Сигнал с одного из выходов DCA, равный 1, подключает тэг, обслуживающий множество, к схеме сравнения D1, на другие входы которой подаются старшие k разрядов ключа физического адреса с ША. 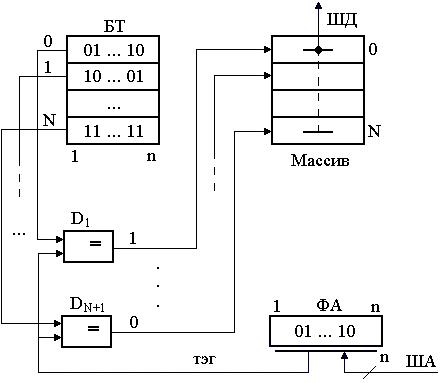 Рис. 3.7. Ассоциативный кэш При срабатывании D1 происходит коммутация содержимого возбужденной строки соответствующего множества массива на ШД. На схеме 3.8 строка На рис. 3.9 приведена структура кэш i486 [21], выполненная по схеме четырех направлений 0, 1, 2, 3. Каждое направление содержит множество из 128 строк размерностью по 16 байт. Запись в кэш осуществляется через буферные регистры интерфейса процессора. Для этого из МП в ОЗУ по ША передается адрес младшей ячейки в строке и осуществляется ее чтение в буфер интерфейса через шину (ШД) процессора, затем трижды выполняется инкремент адреса A(31,2) + 1 и трижды – чтение выше адресуемых ячеек. По окончании такой пакетной передачи содержимое буферного регистра записывается в строку множества, объявляемую недостоверной. Номер строки множества определяет адрес А(10,4), направление вычисляется в блоке LRU. По адресу А(10,4) и направлению, указанному блоком LRU, в блок тэгов записывается А(31,11) – старшие 21 бит физического адреса данных. Так как информация читается 32-битными ячейками по адресам, где А(1,0) = 00, то МП поддерживает при чтении только выровненные данные. Для повышения быстродействия чтения пакетный обмен производится по 16 байт. 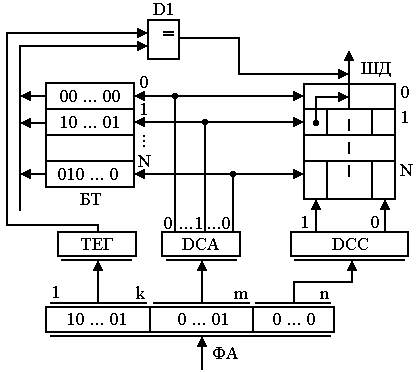 Рис. 3.8. Кэш прямого отображения Чтение из кэш осуществляется по физическому адресу ФА(31,0), поступающему из устройства сегментации или страничного преобразования по ША. Он позволяет извлекать информацию с точностью до байта, используя дешифратор строки DCC, на вход которого подаются младшие четыре бита адреса ФА(3,0). При попадании, когда выход DCA подключает строки БТ к схемам сравнения D1 D4, под действием одного из сигналов а, б, в, г строка одного из направлений массива передается в буферный регистр, из которого, с использованием DCC, требуемый байт (слово, двойное слово) передается на внутреннюю ШД процессора. Часто строка из буферного регистра передаётся как 16-байтный код в устройство предвыборки команд, минуя ВШД. При промахе, если не срабатываети одна из схем сравнения D1 D4, МП включает режим чтения внешнего кэш или ОЗУ по данному ФА. 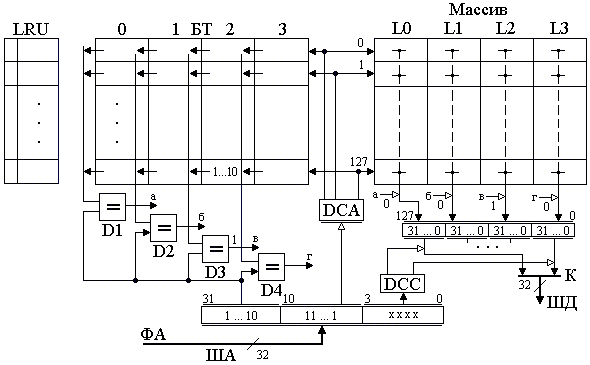 Рис. 3.9. Внутренний кэш i486 Блок LRU содержит память также из 128 строк, по 7 бит в строке. Три бита каждой строки LRU B0, B1, B2 служат для определения правила замены Lij j-й строки i-го направления при записи в кэш. Эти биты изменяются в одной из соответствующих строк при каждой записи или попадании в кэш следующим образом: - если при чтении было обращение к строке L0j или L1j, то B0j = 0; - если данные извлекались из L0j, L1j и оказались в L0j, то B1j = 1, а если из L1j, то B1j = 0; - если данные извлекались (записывались) из L2j, L3j и оказались в L2j, то B2j = 1, а если из L3j, B2j = 0. Состояния Четыре оставшиеся бита памяти строки LRU используются для определения достоверности данных, хранимых в кэш. При очистке кэш или сбросе МП все биты достоверности устанавливаются в 0. При промахе и новой записи бит, соответствующий направлению и строке, устанавливается в 1. При вычислениях МП может объявить часть строк недостоверными и соответствующие биты B3-B6 LRU установить в 0. Эти недостоверные строки впоследствии используются в первую очередь для записи новых данных в кэш. Если все биты B3-B6 = 1, то замена данных в кэш определяется в соответствии с состоянием Лекция 13: Логическая организация памяти Компьютеры PC и XT могут работать с памятью до 1 Мб (с адресами от 0 до 1 М - 1), а AT с МП 286 – до 16 Мб; более поздние модели – до 4 Гб, а ЭВМ с Pentium Pro и Pentium II/III/4 – до 64 Гб. Диапазон адресов определяется размерностью адресной шины МП. Более интенсивно во всех моделях используется память с младшими адресами, которая отводится для размещения ядра DOS, связи с внешними устройствами, стандартных программ тестирования и организации I/O. Чтобы исключить ошибочное использование начальной памяти, она распределяется по назначению на основании стандартов IBM и Intel. Карта логической организации памяти, представляющая собой ее распределение без учета физической сущности, представлена на рис. 3.10. Она распределена на области: стандартную CM, верхнюю UMA, расширенную EM и дополнительную EpM. Область стандартной памяти [15] СМ во всех компьютерах отводится под DOS и рабочие программы TSR с данными, которые обрабатываются МП. В последних моделях эта область наиболее динамичная. При многозадачном V-режиме она постоянно обновляется, и поэтому для повышения быстродействия такая память построена на элементах с малым временем чтения (DRAM и SRAM). Область в верхних адресах UMA емкостью 384 Кб зарезервирована для системного использования самой ЭВМ. Первая часть UMA (128 Кб) отводится под видеопамять (VM), которая предназначена для вывода оперативной информации на дисплей. В зависимости от типа монитора и видеоадаптера она используется не полностью для EGA, MDA, CGA с фиксированными адресами соответственно 640K, 704K, 736K или же используется в полном объеме для VGA и SVGA. Область видеопамяти обычно реализуется на ОЗУ типа VRAM с высоким быстродействием, которая работает с памятью видеоплаты емкостью до 2 Мб и более. Средняя область UMA зарезервирована в ЭВМ под стандартные программы-драйверы I/O и обмена между контроллерами или адаптерами с использованием системной шины. Так как драйверы MDA и CGA вшиты в схему системной платы, то они не требуют адресного пространства. Другие адаптеры, такие как EGA, VGA и SVGA, используют адресуемую память емкостью 16, 32, 64 Кб соответственно, начиная с адреса C0000 или C4000. Эта память отводится под ПЗУ (ROM), в которой размещается BIOS дисплеев. 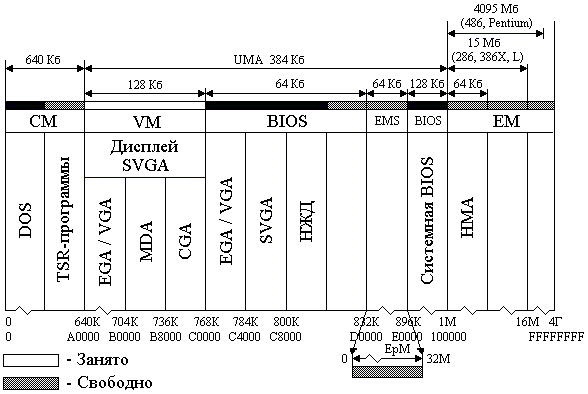 Рис. 3.10. Карта распределения памяти Под ROM BIOS контроллеров жестких дисков отведена область НЖМД с начальным адресом C8000. Контроллеры НЖМД 10 и 20 Мб XT использовали адресное пространство C8000-C9FFF, но контроллеры IDE ATA эту область не используют, т.к. их драйверы являются частью системной BIOS. Контроллеры EIDI и SCSI используют память емкостью 16 Кб в диапазоне адресов C8000-CBFFF. Память в диапазоне адресов CA000-CFFFF в средней области UMA может быть свободной. Во всех компьютерах свободным является адресное пространство D0000-DFFFF (окно EMS). Окно емкостью в 4 страницы по 16 Кб, расширяемое в сторону младших адресов, может быть использовано для работы в стандарте LIM/EMS с дополнительной памятью EpM емкостью до 32 Мб при инсталлированном драйвере, таком как EMM386.EXE. В эту свободную область могут последовательно перегружаться до 2 048 логических страниц при наличии соответствующей дополнительной памяти. Адресами средней области могут пользоваться также сетевые адаптеры в области сегментов C000 и D000, для чего используют ОЗУ на системной плате емкостью до 16 Кб. Последняя (третья) часть UMA выделена под системную BIOS. Программы системной BIOS обслуживают команды МП и играют роль драйверов различных устройств компьютера. Так как эти программы используются с момента включения питания, то они закодированы в ИС ПЗУ на системной плате. В их составе: - POST – программа тестирования исправности НЖМД, ОЗУ, клавиатуры и системной платы; - системный загрузчик – программа передачи файлов DOS с НЖМД или НГМД в начальные адреса ОЗУ и передачи управления; - стандартные программы-драйверы обмена с любыми блоками, подключаемыми к системной шине. Под системную BIOS отводится память 128 Кб в диапазоне E0000-FFFFF, которая почти полностью используется в последних моделях ЭВМ. Для повышения быстродействия при выполнении команд часть программ BIOS в процессе работы может перегружаться из медленного ПЗУ в ОЗУ с более высоким быстродействием. Существует еще одна область верхней памяти (HMA), которая может быть использована в реальном режиме процессорами 286 и выше при инсталлированном драйвере HIMEM.SYS. Эта область имеет размер 64 Кб (без 16 байт) и размещается в диапазоне адресов FFFF:0010-FFFF:FFFF. Известно, что МП 88/86 при вычислении адреса ячейки памяти выше 1 М осуществляют заворачивание адреса (сложение по mod220). Для процессора 286 этого не произойдет, т.к. он может включить адресную шину A0 A20 вместо A0 A19, как у МП 88/86. Управление включением A20 выполняется через бит порта 64h контроллера клавиатуры 8042. Область HMA является частью расширенной памяти (ЕМ), доступной в R-режиме. Расширенная область памяти ЕМ может быть использована только в P- или V-режимах в соответствии с правилами спецификации XMS. Размер этой памяти определяется автоматически программами системной BIOS. Эта память наращивается от 1 Мб в сторону больших адресов. В настоящее время в Pentium II/III/4 линейное адресное пространство ограничено 64 Г = 236, где для обращения к любому байту из этой области требуется 36-битный двоичный код. 7. Сегментация памяти Для эффективного распределения памяти в микропроцессорах 8086/88 была введена сегментация. Под сегментом в них принята область 64К смежных ячеек в любом месте адресного пространства от 0 до FFFFF. Для вычисления адреса используются четыре 16-разрядных регистра: кода CS, стека SS, данных DS, дополнительных данных ES. В этих регистрах для программы задаются базовые физические адреса начала сегмента. Так как шина адреса в 8086/88 20-разрядная, а ШД и сегментные регистры 16-разрядные, то принято, что 4 младших бита любого базового адреса равны 0. Поэтому базовые адреса указывают на границу параграфа (область памяти по 16 смежных байта, начиная с нулевого адреса) и используются для вычисления адреса по схеме, изображенной на рис. 3.11. В зависимости от типа команды, который определяется полем кода операции (КОП), устройство управления (УУ) для вычисления адреса команды или операнда в памяти привлекает один из соответствующих сегментных регистров CS, SS, DS или ES. Содержимое этих регистров подается в 16 старших разрядов сумматора (передача со сдвигом на 4 разряда влево – L4), а к 16 младшим разрядам сумматора подключается "смещение". При этом вычисление адреса в сумматоре происходит по модулю 220 (перенос из старшего разряда отбрасывается, т.е. осуществляется заворачивание адреса) по одной из формул: <ФА (19,0)> = [L4[CS)] + [IP], <ФА (19,0)> = [L4(SS)] + [SP], <ФА (19,0)> = [L4(DS или ES)] + [EA], где: <ФА (19,0)> – двоичный 20-разрядный код, передаваемый на шину адреса; IP, SP – содержимое счетчика команд и указателя стека соответственно; ЕА – смещение, располагаемое в поле команды, которое вычисляется по схеме рис. 1.5 для 16-битной адресации 8086, 286 без- масштабирования и защиты нарушения, где в качестве базы массива используется только РОН ВХ или ВР, индексов SI или DI. На рис. 3.11 в качестве примера рассмотрено вычисление адреса 49F62h операнда через адрес: сегмент : смещение = 49А6:0502, при обработке его командой (обращение по умолчанию к DS) со смещением в поле команды 0502h. В регистре DS хранится базовый адрес сегмента данных 49A6h, в котором 4 младших нулевых бита адреса не представлены. К недостаткам сегментной адресации в 8086 можно отнести: отсутствие контроля и защиты данных от неправильного использования сегментов; возможность обращения к несуществующей физической памяти. В дальнейшем, с целью изолирования программ и данных, организации динамического распределения памяти, фиксации ошибок программирования устройство сегментации было усовершенствовано. 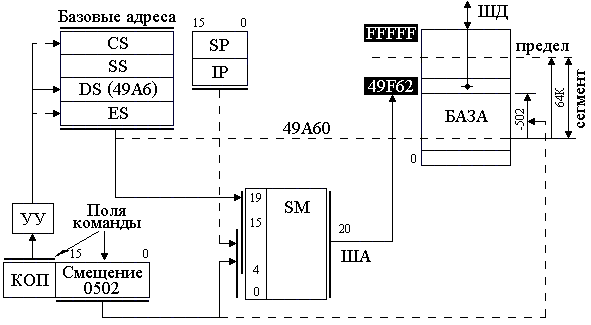 FFFFF 49F62 Рис. 3.11. Схема вычисления адреса в МП 8086 В i486, Pentium под сегментом понимается защищенная область линейного адресного пространства. Все пространство разбито на 16 383 сегмента, а их адреса и характеристики (атрибуты) занесены в дескрипторные таблицы GDT, IDT, LDT. Глобальная дескрипторная таблица GDT и дескрипторная таблица прерываний IDT создаются операционной системой для всех задач, фигурирующих в системе, а локальная таблица LDT может быть создана системным программистом для своих прикладных задач. Элементами этих таблиц являются дескрипторы размером в 8 байт с содержанием полей, приведенным на рис. 3.12. 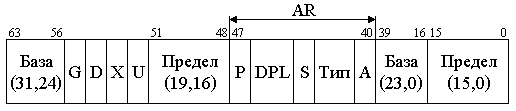 Рис. 3.12. Дескриптор сегмента Дескриптор содержит: - линейный базовый адрес сегмента Вс (31,0) в полях, соответствующих разрядам (63,56) и (39,16); - размер сегмента (предел) Рс (19,0), который находится в разрядах (51,48) и (15,0); - байт прав доступа AR в разрядах (47,40). Атрибуты дескриптора имеют следующее назначение: - А – бит доступа, устанавливается в "1" операционной системой при обращении к сегменту, используется в свопинге; - Тип – 3 бита определяют назначение сегмента и допустимые в нем операции: <000> – сегмент "0" - предназначен для данных и только считывания, 1 (<001>) - сегмент данных для записи и считывания, 2 – стек для считывания, 3 – стек для записи и считывания, 4-6 – сегмент кода, 7 – <111> подчиненный сегмент кода с разрешением выполнения и считывания. Операция выполнения предполагает использование считанного сегмента как команды, а считывания – как данных, причем запись в любой сегмент кода запрещена; - S – системный. При S = 0 дескриптор описывает системный объект; - DPL – двухбитное поле, определяет привилегии от 0 до 3 (код <11> – наименьший уровень); - Р – присутствие (Р = 1 – сегмент находится в физически доступной памяти). Бит дескриптора U используется при необходимости пользователем, бит Х зарезервирован (Х = 0). Бит D = 1 команда работает с 32-битными данными. Бит G является битом гранулярности. При G = 0 предел измеряется в байтах, при G = l предел измеряется в страницах Рс 4К. Число дескрипторов в таблицах IDT и GDT может достигать величины 8192, а наибольший размер любой таблицы = 8 8192 = 64 Кб. Эта величина максимальной размерности таблицы требует включения смещения 16 бит, которое хранится как предел в соответствующих программно-доступных регистрах GDTR и IDTR, и теневом – (LDTR). Элементы в дескрипторных таблицах размещаются последовательно по 8 байт и для их поиска достаточно задать 13-разрядный индекс. Индекс сегмента передается в старшие разряды 16-битного селектора сегмента. В 2 младших бита (0,1) RPL селектора заносится код привилегий, а третьему биту Т1 присваивается 1, если селектор обращается к LDT и 0 – при обращении к GDT. Перед выполнением команды используемый ею дескриптор должен быть определен, а его селектор занесен в один из регистров CS, SS, DS, ES, FS, GS. В процессе распределения памяти операционная система заносит ЛА в регистры GDTR и IDTR: в младшие 32 бита базовые адреса таблиц, а в старшие 16 разрядов – размер этих таблиц, которые не изменяются при постоянном числе задач, фигурирующих в компьютере. Изменить организацию сегментов системный программист может для своих прикладных задач с помощью таблицы LDT. В этой таблице он создает дескрипторы сегментов, доступ к которым осуществляется теми же селекторами в регистрах CS, ..., GS, но у которых бит Т1 установлен в 1. При этом дескрипторы LDT автоматически с загрузкой селекторов считываются в теневые регистры (CS), ..., (GS) с использованием базы теневого регистра (LDTR). База и предел в 48-разрядный теневой регистр (LDTR) передается из GDT, в которой размещается по индексу селектора регистра LDTR специальный дескриптор. На рис. 3.13 показан процесс вычисления линейного адреса в устройстве сегментации i486. Он осуществляется следующим образом. Перед началом решения задачи операционной системой формируются таблицы GDT и IDT и их адреса загружаются в регистры GDTR и IDTR. При необходимости специальными командами программист заносит селекторы в сегментные регистры CS, ..., GS, а системной программой устанавливает селектор в LDTR для чтения созданной им локальной дескрипторной таблицы. В пользовательской программе очередная команда обрабатывается устройством предвыборки команд. В соответствии с кодом операции (КОП) для выполнения команды, операнд которой находится в памяти, к ней подключается один из сегментных регистров CS, ..., GS и соответствующий ему теневой регистр (CS), ..., (GS). Базовый адрес теневого регистра и эффективный адрес (ЕА) в соответствии с типом команды суммируются в SM по модулю 232 по схеме рис. 3.13. В результате определяется линейный адрес операнда. Процессор, используя атрибуты дескриптора, пределы регистров таблиц, контролирует права доступа к сегменту и правильность выполнения команды. 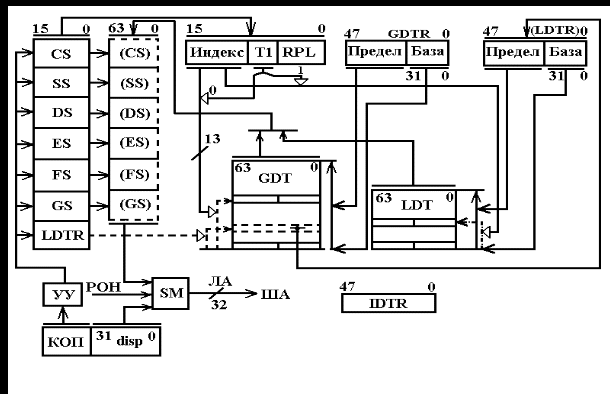 Рис. 3.13. Схема вычисления адреса в устройстве сегментации При отсутствии нарушений (см. рис. 1.5) линейный адрес передается на адресную шину (через устройство страничного преобразования в Р-режиме) ША для извлечения операнда из кэш-памяти или ОЗУ. При определении нарушений в i486 задействуется регистр IDTR с таблицей прерывания IDT и программа формирования соответствующих инструкций. Рассмотренная схема вычисления адреса позволяет обращаться к сегментам, распределенным в любой области линейного пространства от 0 до 4Г-1, с точностью до байта, т.к. базовый адрес сегмента Вс может иметь любой 32-разрядный код. Величина сегмента при G = 0 составляет не более одного Мб, а при G = 1 охватывает всю область линейного пространства. Смещение в команде определяет расстояние от базового адреса до ячейки в сторону увеличения адресов в сегментах данных и кода. В сегментах стека используется принцип записи "последним пришел, первым обслужился". Базовый адрес вместе с максимальной величиной ESP/SP (низ стека) ограничивают сегмент сверху. При каждой записи указатель стека декрементируется, а при считывании инкрементируется. Если бит D и G дескриптора = 1, то используется ESP и обмен идет 32-разрядными словами, тогда низ стека устанавливается адресом Вс+4Г-1. При D=0 в стековых операциях участвует SP и SS, где хранится Вс. Тогда низ стека устанавливается адресом SS : FFFFh. При обращении к ячейкам стека допустимы все смещения, которые больше предела, но меньше максимального размера, а при обращении к ячейкам сегментов кода и данных все смещения меньше предела. На рис. 3.14. показаны незаштрихованные рабочие области для сегментов кода и данных (а) и сегмента стека (б), имеющие D = 0, одинаковую базу Вс и предел 2FFFh. 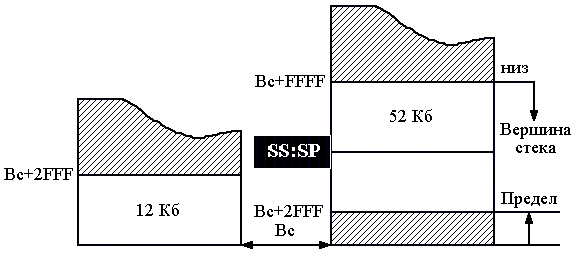 а б Рис. 3.14. Рабочие области сегментов: а – рабочие области для сегментов кода и данных, б – рабочие области для сегмента стека |