Лекции_Вычислительные машины_new. Лекция История развития вычислительной техники
 Скачать 5.16 Mb. Скачать 5.16 Mb.
|

|
8. Страничная организация памяти В P- и V-режимах МП 386 и выше могут поддерживать (с помощью внутреннего менеджера памяти MMU и операционной системы) страничную адресацию. При ней память 4 Гб разбивается на 1 М страниц емкостью по 4 Кб каждая. Тогда физический адрес байта вычисляется как <ФА (31,0)> = <<АС(19,0)>, < Асм(11,0)>>, где Ас(19,0) – 20-разрядный адрес страницы, от 0 до FFFFFh (01М-1), который передается в старшие разряды ША(31,12); Асм(11,0) – 12-разрядный адрес смещения внутри страницы, который передается в младшие разряды шины адреса ША(11,0). По этой формуле вычисляется виртуальный (virtual – фактический) адрес любого байта данных, размещенных по страницам. Причем номер страницы занимает старшие разряды шины адреса; адреса страниц выровнены по границе, т.е. младшие 12 разрядов номера страницы равны нулю, и поэтому номера новых страниц следуют с шагом 212 (4К) в линейном адресном пространстве 4Г. Если программа занимает память под свой код и данные с числом страниц и их номерами, не выходящими за емкость ОЗУ, собранного на ИС, вычисление адреса <АС(19,0)>, <Асм(11,0)> совпадает с обычным способом прямой адресации к физической памяти основного ОЗУ и приводит лишь к снижению быстродействия обмена. В данном случае эффективным будет режим запрета страничного преобразования. Однако в том случае, если программа работает с виртуальными адресами из верхней области линейного адресного пространства, превышающей емкость ОЗУ, следует: - размещать информацию по страницам; - необходимые страницы в процессе работы последовательно переписывать с диска в ОЗУ; - виртуальные адреса страниц Ас(19,0) преобразовывать в адреса страниц (кадров) реальной физической памяти ОЗУ Ас*(19,0). Преобразование Ас(19,0)Ас*(19,0) может быть осуществлено при помощи косвенной адресации, когда каждому адресу Ас(19,0) ставится в соответствие адрес ячейки памяти, где хранится Ас*(19,0). Если в 20 разрядах таких ячеек размещать реальный адрес страницы, а в других – дополнительную информацию о странице, то каждый элемент этой таблицы (дескриптор) может занимать 4 байта. Тогда при числе страниц 1М емкость памяти, требуемая под таблицу преобразования, может достигать 4 Мб. В мультизадачной среде таких таблиц может потребоваться несколько. Тогда таблицы сами могут занять всю область ОЗУ, что недопустимо. В процессорах МП 386 и выше используется более гибкое двухэтапное преобразование Ас(19,0)Ас*(19,0) с помощью таблиц PDE и PTEI (I = 0 1023), которое позволяет намного уменьшить емкость памяти косвенной адресации. Вычисление адреса операнда ФА (31,0) в ОЗУ по линейному адресу ЛА(31,0) осуществляется поэтапно по следующему правилу: ФА (31,0) = < PTEI L (31,0) = M1 ( PDE I (31,0) = M2 ( На первом этапе, как показано на рис. 3.15, в МП извлекается содержимое ячейки памяти М2 (дескриптор таблицы PDE), где в 20 старших разрядах хранится базовый адрес таблицы PTEI с физическими адресами страниц. Содержимое М2 извлекается из ОЗУ по ШД (31,0) по адресу ША (31,0) = < 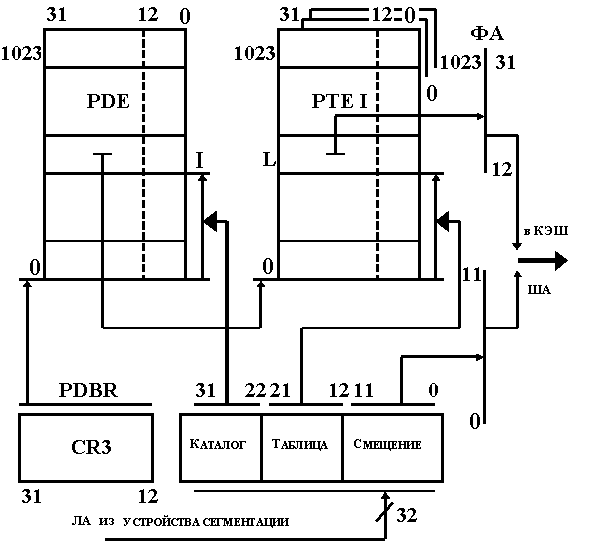 Рис. 3.15. Схема вычисления ФА при страничной адресации На втором этапе содержимое 20 старших разрядов М2 используется при определении базового адреса таблицы Смещение внутри страницы не подвержено преобразованию, и 12 его разрядов используются для определения ФА данных или кода внутри страничного кадра подключаясь к 12 разрядам внутренней шины адреса ША(11,0). Дескрипторы таблиц PDE и PTE имеют одинаковую структуру вида:
Разряды этих дескрипторов имеют следующее назначение: - P – бит присутствия, при P = 1 страница загружена в ОЗУ; - R/W – бит чтения/записи, при R/W = 1 страница допускает операции чтение/запись, а при R/W = 0 – только чтение; - U/S – пользователь/супервизор. При U/S = 0 страница с привилегиями супервизора, а при U/S = 1 – уровень пользователя; - PWT – запрет сквозной записи страницы. При PWT = 1 осуществляется сквозная запись, а при PWT = 0 – способ с обратной записью; - PCD – запрет кэширования страницы. При PCD = 1 кэширование страницы запрещено, в остальных случаях – кэширование по циклам; - A – бит обращения. A устанавливается в 1, когда МП обращается к странице для записи/считывания; - D – Dirty (грязный) бит. При записи новых данных в страницу DOS устанавливает его в 1; - Дос при страничной организации не используется, программно доступен; - ФА – 20-битное поле физического адреса таблицы PTE или страничного кадра задачи. При преобразовании линейного адреса в ФА МП проверяет в первую очередь бит P, если P = 0, то осуществляется свопинг (загрузка с НЖМД нужной страницы в ОЗУ) в следующей последовательности: - освобождение одного из страничных кадров ОЗУ и, при D = 1, пересылка его на диск; - DOS копирует нужную страницу в ОЗУ с диска в страничный кадр, начиная с ФА освободившейся памяти в 4 Кб; - загрузка 20-битного адреса ФА в соответствующий дескриптор PTE и установка в нем P = 1, а также, при необходимости, установка/сброс остальных флагов; - перезагрузка буфера TLB; - рестарт команды, инициировавшей свопинг. К преимуществам страничной адресации относится возможность использования всей области линейного пространства. К недостаткам можно отнести: - обмен страницами, которые могут быть не полностью заполнены информацией; - снижение производительности из-за свопинга и операций преобразования адреса; - сложность контроля со стороны пользователя за динамическим распределением памяти; - потеря части ОЗУ на размещение таблиц PDE и PTE. Двухэтапное преобразование уменьшает быстродействие вычисления адреса из-за дополнительного обмена с ОЗУ, и поэтому для повышения производительности используется ассоциативный буфер преобразования (TLB). Для того чтобы уменьшить время вычисления адреса страничного кадра Ас*(19,0) при страничной адресации, необходимые элементы таблиц PDE и PTE размещают в ассоциативном КЭШ-буфере преобразования (TLB), который хранит часть нужных дескрипторов и уменьшает число обращений к ОЗУ. На рис. 3.16 представлена структура буфера TLB, используемого устройством страничного преобразования i486. Он по содержанию и принципу работы имеет много общего с внутренним кэш. Блок данных TLB, состоящий из 4 множеств по 8 строк, емкостью по 20 бит каждое множество, используется для хранения физических адресов страничных кадров, которые заносятся непосредственно из ОЗУ при каждой загрузке PDBR. Блок LRU определяет, какие физические адреса (строки) можно заменить на новые при отсутствии их в TLB. 21-битные строки блоков тэгов (БТ) используются для хранения 17 старших разрядов виртуального адреса Ас (19,3), 3 бит атрибутов Ат и 1 бита V достоверности строки. Строки БТ имеют вид:
Разряды строк с (20, 17) используются блоком LRU. Разряды (16,0) множеств 0,1,2,3 БТ коммутируются на соответствующую множеству схему сравнения D1, ..., D4. Схемы D1 D4 сравнивают старшие разряды ЛА (31,15) с разрядами (16,0) каждой из строк направлений 0, 1, 2, 3 БТ, возбужденных в результате дешифрации кода <ЛА(14,12)>. Так, если этот код равен <1, 0, 1>, то пятая строка множеств с направлениями 0, 1, 2, 3 блока тэгов передается на входы своих схем D1 D4. На другие входы этих схем подается тэг с разрядов (31,15) линейного адреса. При срабатывании одной из схем сравнения от множеств коммутируется соответствующая строка из блока данных на шину адреса. На рис. 3.16 показано: D1 имеет выход 1 и коммутирует строку 5 направления 0 из блока данных на ША (31,12). . 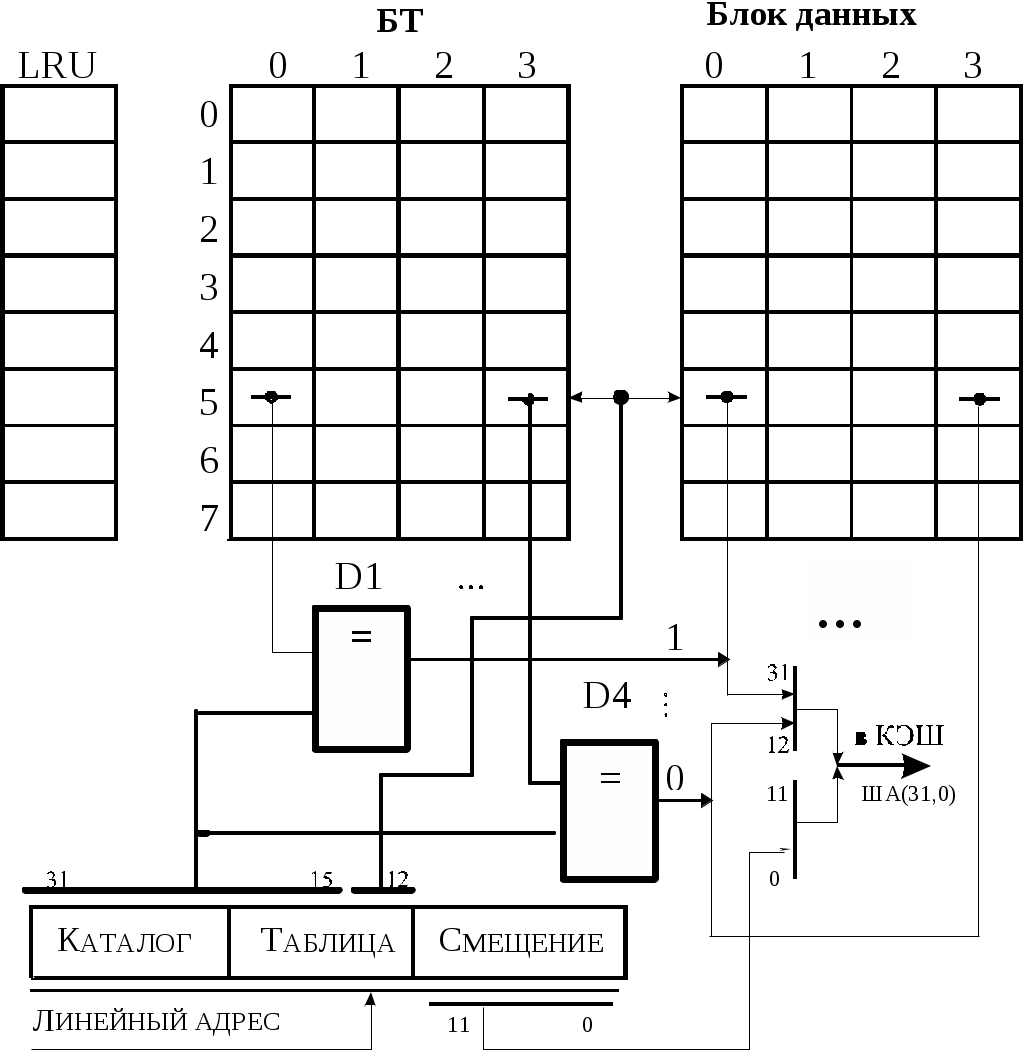 Рис. 3.16. Структура буфера TLB Если при сравнении D1 D4 не срабатывают, то в TLB отсутствует Ас*(19,0) и, используя алгоритм псевдо - LRU, аналогично механизму внутреннего кэш, осуществляется чтение таблиц PDE и PTE из ОЗУ и замена данных в блоке данных и БТ. Для проверки TLB могут использоваться два регистра TR6 и TR7 - при наиболее привилегированном уровне. Структура регистров представлена на рис. 3.17. Регистр данных TR7 «отображается» на блок адресов TLB и имеет следующие поля:
Рис. 3.17. Формат регистров проверки TLB - TR7(31,12) – физический адрес, который передается (считывается) со строки в соответствии с TR6 (31,12); - PCD, PWT – значения этих битов соответствуют битам дескриптора PDE; - LRU – при считывании – биты B0, B1,B2 LRU; - REP – при записи определяет направление. При считывании, если PL = 1, определяет срабатывание D1 D4 по коду направления; при PL = 0, содержимое REP не определено; - PL – бит промаха (PL = 0) или попадания (PL = 1) при поиске. При записи и PL = 1 подключается направление, указанное в REP, а при PL = 0 направление определяет LRU. Регистр TR6 является регистром команды со следующим назначением разрядов: - TR6 (31,12) – линейный адрес Ас (19,0) и тэг, передаваемый в БТ; - С – бит команды. При С = 0 запись, иначе – поиск или считывание; - D* – бит D и его дополнение; - U* – бит U/S и его дополнение; - W* – бит R/W и его дополнение; - V – достоверность, при отсутствии загрузки строки БТ V = 0, при записи в строку V = 1. Состояния двух разрядов любого поля D*, U*, W* устанавливаются в соответствии с табл. 3.3 и имеют значение в зависимости от режима поиска или записи. Таблица 3.3 Назначение наборов полей D*, U*, W*
Лекция 13: ОЗУ современных ЭВМ Увеличение частоты работы процессоров, разрядности шины данных требует повышения быстродействия обмена МП с ОЗУ и уменьшения величин задержек при циклах записи и чтения. Это способствует разработке новых элементов памяти, увеличению емкости ОЗУ, пропускной способности, разрядности системных шин и совершенствованию принципов хранения и передачи данных. Так, ЭВМ с процессорами Pentium II/III с 64-битной ШД, FSB 133 Мгц, AGP 4x, как показано в табл. 3.4 и 3.5, уже не может обеспечивать наивысшей производительности с основной памятью типа FRM, EDO и даже CDRAM 66 МГц. Таблица 3.4 Оценка пропускной способности устройств ЭВМ
Поэтому новые системные платы с FSB 133 Мгц и выше используют или усовершенствованное ОЗУ, или новую память фирмы Rambus [14]. Одним из способов повышения производительности динамической памяти является размещение статической кэш-памяти прямо в кристалле памяти. Такая двухступенчатая память применяется в некоторых моделях ПК, серийно выпускается на ИС CDRAM (Cached DRAM) – продуктах фирм Mitsubishi и Samsung. Микросхемы CDRAM емкостью 4 и 16 Мбит имеют 16 Кб кэш статической памяти со 128-битной внутренней шиной данных. Таблица 3.5 Характеристики различных типов памяти
Другая разновидность ИС CDRAM – микросхемы EDRAM (Enhanced DRAM) фирмы Ramtron. Микросхемы EDRAM емкостью 4 Мбит имеют 8 Кб кэш статической памяти с разрядностью внутренней шины данных 2048 бит. Память с внутренним кэшем существенно эффективнее обычной комбинации DRAM и вторичного кэша L2, особенно в многозадачных системах, где переключение задач приводит к высокой частоте кэш-промахов. 8.1. ОЗУ фирмы Rambus В 1995 г. фирма Rumbus inc. предложила новую технологию ОЗУ Rambus на основе игровых ИС памяти Base RDRAM, включающих 8-битный высокоскоростной канал обмена. Созданы 2 вида памяти Rambus – RDRAM (Direct RDRAM) и Concurent RDRAM. Вторая отличается высокой эффективностью, что делает приоритетным ее использование в графических станциях и серверах (передача данных с частотой 800 МГц). В Direct Rambus реализована шина, у которой сигналы управления передаются отдельно от данных. Естественно, потребовались модули нового типа, названные RIMM. Они имеют 184 контакта и рассчитаны на напряжение питания 2.5 В (SDRAM-3.3B), а их емкость составляет 64/128/256 Мб. Первоначально планировалась поддержка 3 RIMM, но из-за технологических проблем было принято решение о поддержке 2 модулей RIMM, что уменьшило физическую длину шины и увеличило ее надежность, однако ограничило память емкостью 512 Мб. Технология Direct RDRAM включает структуру, состоящую из основного контроллера, интерфейса и каналов Rambus, к которым подключаются ИС, а так же генератора дифференциальных импульсов. Интерфейс Rambus реализован как в чипах RDRAM, так и в связующем их канале Rambus. Структура ОЗУ Rambus показана на рис. 3.18. Каждый канал Rambus способен поддерживать до 32 чипов Direct RDRAM и передавать данные к контроллеру памяти на частоте синхронизации шины 400 МГц автономно. К оконечной ИС канала для исключения искажения сигналов подключается согласующее устройство (терминатор). ШД Rambus-канала 16-битная (18-ти с режимом ECC), ШУ 8-разрядная, ША 8-битная. Передача адреса ячейки осуществляется последовательно по отдельным шинам для передачи адреса строки и столбца, причем адрес может передаваться параллельно с данными. Для выборки данных в ОЗУ используется конвейерный режим. Контроллер работает на частоте до 200 Мгц, что вполне достаточно как для 200 МГц системной шины К7 AMD, так и для 133 МГц шины Pentium III 600. 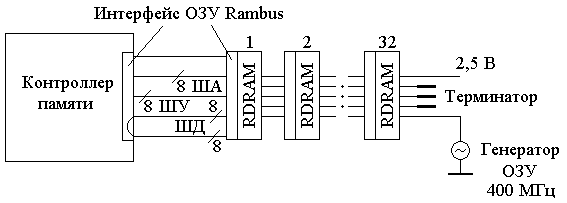 Рис. 3.18. Схема организации RDRAM Согласно спецификации, емкость одного чипа Rambus DRAM составляет 64, 128, 256 Мбит или 1 Гбит. Использование 9-го бита к байту емкости Rambus оставляет производителю системных плат право выбора: либо для введения контроля ЕСС, либо для увеличения общей емкости ОЗУ. Таким образом, появились, соответственно, 72 и 144 Мбит варианты ИС. Тактовая частота RDRAM – 400 МГц, но обмен данными осуществляется на переднем и заднем фронтах синхросигнала, в результате передача данных эквивалентна частоте обмена 800 МГц. Это в сочетании с двумя шинами передачи данных шириной по байту и дает нам пиковую пропускную способность чипа RDRAM в 1.6 Гб/с, в 8 раз превосходящую соответствующее значение чипа PC 100 SDRAM. Для упрощения чипа ИС RDRAM наделены лишь микрооперациями ответа на запросы, генерируемые контроллером памяти. Каждый контроллер содержит Rambus – интерфейс, лицензированный практически всеми крупными производителями ИС. Контроллер ИС может располагаться при необходимости на плате модуля RIMM или в чипе чипсета. У технологии Rambus есть недостатки, влияющие на длину задержек при выполнении циклов чтения/записи. Так, при операции записи, следующей за чтением, требуется выдержать паузу в зависимости от длины канала Rambus: для короткого канала она может составить всего один такт, 2.5 нс, тогда как в худшем случае пауза может составлять 5 тактов, что соответствует задержке равной 12.5 нс. Существуют задержки, возникающие при организации циклов микрооперациями обмена, перехода с одного режима на другой. Для уменьшения энергопотребления питание всех чипов RDRAM уменьшено с 3.3 В, потребляемых чипами SDRAM, до 2.5 В. Для этих же целей RDRAM имеет 4 режима работы: активный (active), надежный (standby), спящий (nap) и режим с пониженным потреблением энергии (powerdown). Каждый из них характеризуется определенным энергопотреблением и временем задержки для выполнения операции передачи данных. Обычно механизмы управления питанием переводят устройства в спящий режим тогда, когда в них нет особой нужды. Однако, чтобы не допустить перегрева, чип RDRAM же впадает в спячку во время интенсивной работы - игр, тестов, проигрывания потокового видео или аудио и т.д. Для уменьшения перегрева системы в отсутствии запросов основным режимом для всех чипов RDRAM, является режим Standby. Для включения в работу неактивного чипа RDRAM требуется порядка 100 нc. и при переходе к активной работе пропускная способность ОЗУ может составлять только 100 Мб/с. С каждой стороны платы модуля RIMM может располагаться до 8 чипов RDRAM емкостью по 64 Мбита, что соответствует модулю на 128 Мб. Таких модулей на системной плате через разъемы может подсоединяться до трех. Архитектура двух каналов Rambus обеспечивает необходимую для МП Pentium 4 максимальную скорость передачи данных – 3.2 Гб/с. Однако быстродействие обмена существенно зависит от задержек при выполнении операций чтения/записи и их интенсивности. 8.2. Пакетное ОЗУ SLDRAM В начале 1997 г. 12 производителей различных фирм объединились, чтобы создать более дешевую, чем Direct RDRAM, быстродействующую память емкостью 16, 64, 256 Мб для использования в ПК. Память нового типа с протоколом передачи данных на тактовой частоте более 400 Мгц получила название SLDRAM (Sync Link DRAM). Технология SLDRAM представляет собой следующий эволюционный шаг в развитии классического ядра DRAM. В SLDRAM используется 16-разрядная шина данных, работающая на тактовой частоте 400 МГц [4]. Аналогично DDR SDRAM и RDRAM, передача данных осуществляется на обоих фронтах тактового сигнала и пропускная способность SLDRAM составляет 16 бит 400 МГц 2 = 1.6 Гб/с. Она может быть увеличена за счет повышения тактовой частоты и разрядности (до 64 бит) системной шины памяти. В SLDRAM использована основательно переделанная архитектура синхронной памяти: адреса, команды, сигналы управления передаются в пакетном режиме по однонаправленной шине. Одновременно с ними по другой двунаправленной шине DataLink в пакетном режиме передаются данные. Величина всего пакета может равняться странице. Так как пропускная способность обеих шин одинакова, то переключение на любую страницу ОЗУ осуществляется без потери производительности. Набор команд у SLDRAM увеличен, что облегчает работу контроллера. Команда представляет собой четыре 10-битных пакета и содержит всю информацию о массиве данных для проведения следующей операции в ОЗУ, что повышает производительность SLDRAM. 8.3. Синхронное динамическое ОЗУ на 100 и 133 МГц При переходе с тактовой частоты шины 66 МГц на 100 МГц к ОЗУ SDRAM стали предъявлять более жесткие требования. В соответствии со стандартом Intel разработала спецификацию микросхем памяти, получившую название PC100. Микросхемы памяти PC100 SDRAM выпускаются в тонком малогабаритном корпусе TSOP, где количество выводов ИС определяется глубиной адресного пространства микросхемы. На основе этих микросхем изготовлены модули DIMM емкостью до 1Гб и модули RDIMM (Registerd) емкостью 1 Гб и более с буферным ОЗУ. Варианты модуля DIMM представлены в табл. 3.6. Организация ШД в 72 бита используется для DIMM с контролем ОЗУ в режиме EСС. Таблица 3.6 Конфигурация модулей PC100 SDRAM
С увеличением тактовой частоты системной шины до 133 МГц появились микросхемы PC133 SDRAM. Задержки у PC 133 на четверть меньше, чем у PC 100. На подготовку к процедуре чтения или записи PC 100 или PC 133 потребуется 3 такта, что для PC 100 займет 30 (310) нс, а для РС133 – 22.5 (37.5) нс. Для сравнения: величина задержки при переходе из пассивного режима в активный PC100 и PC133 меньше RDRAM, где она равна 57.5 (232.5) нс. Как видно из табл. 3.5, PC 133 по пиковой пропускной способности проигрывает даже Direct RDRAM 600 МГц - 1064 Мб/с против 2.4 Гб/с. Она также проигрывает по реальной и средней пропускной способности примерно 650 Мб/с против 840 Мб/с. Если исходить из требуемой пиковой пропускной способности, то до нее не хватает и Direct RDRAM 800 МГц. Если смотреть на среднюю, то она обеспечивается PC 100 SDRAM. Из табл. 3.4. видно, что PC 133 SDRAM удовлетворяет максимальные требования как системной шины с частотой 133 Мгц, так и AGP 4х. 8.4. ОЗУ с удвоенной скоростью передачи данных DDRSDRAM Дальнейшее совершенствование SDRAM (PC 66, 100, 133) способствовало разработке архитектуры ОЗУ с удвоенной скоростью передачи данных DDR SDRAM (SDRAM II), где можно передавать по одному проводу 2 бита данных за такт [4]. В ней добавлена ассоциация каналов памяти с процессами системы. Это увеличивает пиковую пропускную способность до 1.6 Гб/с при частоте шины 100 МГц. Этот тип памяти основан на тех же принципах, что и SDRAM, но включает в себя ряд весьма существенных возможностей. В DDR SDRAM используется синхронизация по переднему и заднему фронту, отсутствующая в SDRAM, и цикл с фиксированной задержкой DLL для выдачи сигнала DataStrobe, означающий доступность данных на выходных контактах. Используя один сигнал DataStrobe на каждые 16 выводов, контроллер может осуществлять доступ к данным более точно и синхронизировать входящие данные, поступающие из разных массивов, находящихся в одном банке. Хотя частота кристалла остается прежней, обмен данных в DDR SDRAM осуществляется на обеих фронтах сигнала, что увеличивает вдвое пиковую пропускную способность по сравнению с SDRAM, работающей на базовой частоте. Так, если за базовую принять частоту 100 МГц, то у DDR 200, пиковая пропускная способность которой 1.6 Гб/c, будет вдвое больше чем у PC 100 SDRAM и составит Direct Rambus DRAM 800 МГц. Стандартом предусмотрена частота 133 МГц и чипы DDR 266, у которых пиковая пропускная способность составляет 2.1 Гб/с. Direct RDRAM уступает ей как по пропускной способности, так и по задержкам при переходе с режима на режим (табл. 3.7.) Модуль DIMM DDR 200 потребляет примерно столько же мощности, сколько и модуль PC 100 той же емкости. Однако имеет 184 контакта против 164 контактов DIMM SDRAM. Это приводит к необходимости установки на системной плате специальных разъемов. Таблица 3.7 Характеристики DDR 266 и Direct RDRAM 800
В конце 2000 г. была разработана память DDR SDRAM с результирующей частотой 500 МГц, с учетом 128-битной шины пропускная способность составила 8 Гб/с. В 2003 г. планируется производство нового поколения DDR II с более низким напряжением питания 1.8 B вместо 2.5 В, в котором за один такт будут передаваться 4 пакета данных. Пропускная способность этой памяти на тактовой частоте 100 МГц при 64-разрядной шине составит 3.2 Гб/с. 8.5. ОЗУ с виртуальными каналами обмена Кроме увеличения частоты обмена, существуют другие способы повысить интенсивность работы SDRAM. Один из них – использование технологии обмена с виртуальным каналом VCM, разработанной фирмой NEC. В основе VCM лежит принцип снижения длительности задержки в обмене данными за счет увеличения числа каналов обмена с разными областями ОЗУ, а также снижение энергопотребления модулей памяти. Добиться выполнения этой задачи удалось следующим образом. В обычном ОЗУ для обмена данными по ШД любым системным устройствам (контроллеры PCI, IDE или AGP, кэш МП) менеджер памяти делает запрос, включающий адрес, размер блока данных и т.д., как показано на рис. 3.19. Причем если все эти действия ведутся одновременно несколькими устройствами, то выполнить обмен данными по этим запросам невозможно из-за наличия только одного буфера обмена ОЗУ с системной шиной. В VCM каждому устройству назначается свой высокоскоростной виртуальный канал, учитывающий специфические характеристики его запросов, в том числе и обеспечивающей функции кэширования. Менеджер памяти закрепляет устройства обмена ЭВМ за конкретными каналами, которым выделяется область ОЗУ и индивидуальные или смежные банки памяти. Затем он посылает каналу команду на запись или чтение, а каждый канал, включающий все необходимые микрооперации, такие как задержки между циклами, вычисление адресов блоков и т.д., занимается индивидуальным обменом. В результате внешние и внутренние операции оказываются независимыми друг от друга и могут исполняться параллельно. Эффективность доступа к памяти значительно повышается. Причем при необходимости можно увеличить число виртуальных каналов, обслуживающих одно устройство ЭВМ. Так, AGP может использовать каналы для загрузки текстур, расчета фигур, цвета и др. 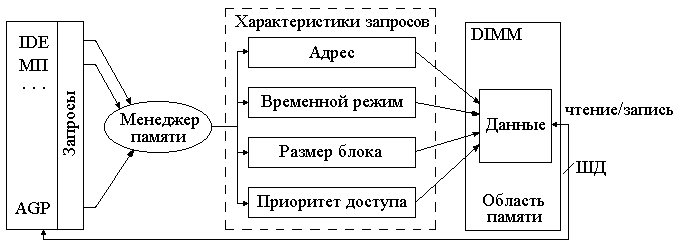 Рис. 3.19. Структура обмена устройств ЭВМ с ОЗУ Конструктивно, как показано на рис. 3.20, каждый виртуальный канал (ВК) включает ИС в виде буферной памяти SRAM емкостью 1 024 бит и располагается между линией ввода/вывода памяти и матрицей ячеек памяти. В буферной памяти осуществляется временное хранение данных, что позволяет с учетом разных банков осуществлять регенерацию памяти и циклы чтения/записи данных одновременно. Обмен данными между буфером виртуального канала и ячейками банка ОЗУ происходит блоками емкостью по 1 024 бита. Содержимое буфера канала затем участвует в интенсивных передачах системной шины. По данным NEC, увеличение эффективности может достичь 90 %, а по тестам VCM133 SDRAM превосходит РС133 на 10 – 30 %. Кроме того, уменьшается энергопотребление примерно на 30 % за счет того, что в тот момент, когда происходит передача результатов приказа системному устройству, участвующему в обмене, вся фоновая активность по другую сторону виртуального канала может быть заморожена. По выводам чипы VCM аналогичны обычным чипам SDRAM, совместимы с ними и по используемому интерфейсу. BIOS может легко распознать модули VCM. Модули, взаимозаменяемые с обычными SDRAM DIMM, причем все последние чипсеты от SiS и VIA поддерживают VCM. Увеличение площади чипа по сравнению SDRAM составляет всего 1 – 3 %, незначительно отличается и себестоимость РС133 SDRAM. VCM не критичен к типу памяти и легко может быть в дальнейшем встроен, например, в DDR SDRAM.  Рис. 3.20. Архитектура виртуального канала В табл. 3.8 приведены модели компьютеров, использующих новые типы ОЗУ емкостью 256 Мб. Таблица 3.8 Компьютеры с ОЗУ 256 Мб
ТЕМА 6. Организация ввода-вывода Лекция 15: Устройства ввада-вывода Вопросы организации ввода/вывода в вычислительной системе иногда оказываются вне внимания потребителей. Это привело к тому, что при оценке производительности системы часто используются только оценки производительности процессора, а оценкой системы ввода/вывода пренебрегают. Такое отношение к системам ввода/вывода, как к некоторым не очень важным понятиям, проистекает также из термина "периферия", который применяется к устройствам ввода/вывода. Однако это противоречит здравому смыслу. Компьютер без устройств ввода/вывода - как автомобиль без колес - на таком автомобиле далеко не уедешь. Очевидно одной из наиболее правильных оценок производительности системы является время ответа (время между моментом ввода пользователем задания и получения им результата), которое учитывает все накладные расходы, связанные с выполнением задания в системе, включая ввод/вывод. Кроме того, важность системы ввода/вывода определяется еще и тем, что быстрое увеличение производительности процессоров настолько изменило принципы классификации компьютеров, что именно по организации ввода/вывода мы можем как-то грубо их отличать: разница между мейнфреймом и миникомпьютером заключается в том, что мейнфрейм может поддерживать намного больше терминалов и дисков; разница между миникомпьютером и рабочей станцией заключается в том, что рабочая станция имеет экран, клавиатуру и мышь; разница между файл-сервером и рабочей станцией заключается в том, что файл-сервер имеет диски и ленточные устройства, а экран, клавиатура и мышь отсутствуют; разница между рабочей станцией и персональным компьютером заключается лишь в том, что рабочие станции всегда соединены друг с другом с помощью локальной сети. Уже сейчас мы можем наблюдать, что в компьютерах различного ценового класса от рабочих станций до суперкомпьютеров (суперсерверов) используется один и тот же тип микропроцессора. Различия в стоимости и производительности определяются практически только организацией систем памяти и ввода/вывода (а также количеством процессоров). Как уже отмечалось, производительность процессоров растет со скоростью 50-100% в год. Если одновременно не улучшались бы характеристики систем ввод/вывода, то, очевидно, разработка новых систем зашла бы в тупик. Важность оценки работы систем ввода/вывода была осознана многими пользователями компьютеров. Были разработаны специальные тестовые программы, позволяющие оценить эффективность систем ввода/вывода. В частности, такие тесты применяются для оценки суперкомпьютеров, систем обработки транзакций и файл-серверов. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||