Лекция 2. Лекция математические основы спортивной метрологии
 Скачать 50.88 Kb. Скачать 50.88 Kb.
|

|
ЛЕКЦИЯ 2. Математические основы спортивной метрологии Вопросы для рассмотрения: 1. Случайное событие, случайная величина, вероятность. 2. Генеральная и выборочная совокупность. 3. Предмет математической статистики. 4. Характеристики центра ряда. 5. Характеристики вариации. 6. Графическое представление вариационного ряда. 1. Теория вероятностей – раздел математики, который по известным вероятностям одних случайных величин определяет вероятности других случайных величин, взаимосвязанных с первыми. Случайное событие – событие, которое может случиться во время проведения испытания, т.е. оно не закономерно, его нельзя достоверно предсказать заранее. Случайная величина – такая величина, которая претерпевает случайные изменения от испытания к испытанию (от измерения к измерению). В зависимости от возможных значений случайная величина может быть дискретной или непрерывной. Например, при бросании игральной кости могут выпадать только целые значения (от 1 до 6) – это дискретная случайная величина; а время пробега спортсменом дистанции может изменяться плавно – это непрерывная случайная величина. Вероятность – степень возможности появления случайного события в результате проведения испытания, которое может повториться бесконечное количество раз. Существует статистическое и классическое определение вероятности. Рассмотрим статистическое определение. Будем фиксировать число испытаний, в результате которых появилось событие А. Всего было проведено N испытаний. В результате этих испытаний событие А наступило nN раз. Число nN называется частотой события, а отношение nN/N – частостью (относительной частотой) события А. (События в теории вероятностей принято обозначать заглавными латинскими буквами А, В, С, … .) Если мы будем увеличивать число испытаний N до бесконечности, то заметим, что относительная частота события А стремится к какому-то определенному числу, которое и называется вероятностью события А и обозначается Р(А). Математически это обозначается: 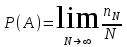 Так как nN≥0, то Р(А) ≥0 и т.к. nN≤N, то Р(А) ≤1, т.е. значение вероятности может находиться в пределах 0≤Р(А) ≤1. Экспериментально это проверить нельзя, т.к. на практике невозможно провести бесконечное количество испытаний. Далее следует классическое определение вероятности по Лапласу, которое пришло к нам из области азартных игр, где теория вероятностей применялась для определения перспективы выигрыша. Пусть испытание имеет n возможных исходов, т.е. отдельных событий, могущих появиться в результате данного испытания; причем при каждом повторении испытания возможен один и только один из этих исходов. Таким образом, все n исходов несовместимы. Кроме того, по условиям испытаний нет никаких оснований предполагать, что один из исходов появляется чаще других, т.е. все исходы являются равновозможными. Допустим теперь, что при n равновозможных исходах интерес представляет только некоторое событие А, появляющееся при каждом из m исходов и не повторяющееся при остальных n-m исходах. Тогда принято говорить, что в данном испытании имеется n случаев, из которых m благоприятствуют появлению события А. Вероятность события А в такой схеме равна отношению числа случаев, благоприятствующих события А, к общему числу всех равновозможных несовместимых случаев: 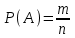 2. В процессе проведения исследований методами математической статистики описывается или измеряется общий признак объектов исследования (спортсменов, например). В результате такого описания или измерения получается статистическая совокупность. Если статистическая совокупность получена в результате выборочного исследования, то она называется выборочной совокупностью или выборкой. Под генеральной совокупностью подразумевается совокупность всех возможных значений признака в данном исследовании. Важнейшая характеристика выборки – объем выборки, т.е. число элементов в ней. Объем выборки принято обозначать символом n. Генеральную совокупность мысленно можно представить так: это все объекты наблюдения (например, спортсмены), которые обладают теми же свойствами, что и объекты выборки. Один из центральных вопросов статистики: как обобщить результаты, полученные на выборке, на всю генеральную совокупность? 3. Предметом математической статистики является анализ результатов массовых, повторяющихся измерений. Результаты таких измерений всегда более или менее отличаются друг от друга. Даже если измеряется тот же самый объект в неизменных условиях, нельзя получить одинаковые данные. Из-за многочисленности причин, не поддающихся контролю и варьирующих от одного измерения к другому, результаты измерений всегда претерпевают случайное рассеивание. Аналогичное рассеивание бывает при однотипных измерениях в группе однородных объектов (например, измерения высоты прыжка у группы школьников одного класса). Хотя результат каждого отдельного измерения при случайном рассеивании заранее предсказать нельзя, это не означает, что мы имеем дело с полным хаосом. Массовые изменения однородных объектов, обладающих качественной общностью, обнаруживают определенные закономерности. Математическая статистика создает методы выявления этих закономерностей. Выделяют три основных этапа статистических исследований. 1) Статистическое наблюдение. Представляет собой планомерный, научно обоснованный сбор данных, характеризующих изучаемый объект. Оно должно удовлетворять следующим требованиям: а) объекты наблюдения (испытуемые) должны быть одинаковыми (однородными) с точки зрения их свойств (квалификация, специализация, возраст, стаж работы и др.); б) число объектов наблюдения должно быть достаточным, чтобы можно было выявить закономерности и обобщить их свойства. 2) Статистические сводка и группировка. Они являются важной подготовительной частью к статистическому анализу данных. Этот этап предусматривает: а) систематизацию (группировку) данных; б) оформление определенных статистических таблиц. 3) Анализ статистического материала. Это завершающий этап статистического исследования. Его проводят с использованием соответствующих математико-статистических методов. 4. Центральную тенденцию выборки позволяют оценить такие статистические характеристики, как среднее арифметическое значение, мода, медиана. Наиболее просто получаемой мерой центральной тенденции является мода. Мода – это такое значение в множестве наблюдений, которое встречается наиболее часто. В случае, когда все значения в группе встречаются одинаково часто, считают, что эта группа не имеет моды. Когда два соседних значения в ранжированном ряду имеют одинаковую частоту и они больше частоты любого другого значения, мода есть среднее этих двух значений. Если два несмежных значения в группе имеют равные частоты, и они больше частот любого значения, то существуют две моды; в таком случае группа измерений или оценок является бимодальной. Наибольшей модой в группе называется единственное значение, которое удовлетворяет определению моды. Однако во всей группе может быть несколько меньших мод. Эти меньшие моды представляют собой локальные вершины распределения частот. Медиана (Me) – середина ранжированного ряда результатов измерений. Если данные содержат четное число различных значений, то медиана есть точка, лежащая посередине между двумя центральными значениями, когда они упорядочены. Среднее арифметическое значение 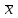 для неупорядоченного ряда измерений вычисляют по формуле: для неупорядоченного ряда измерений вычисляют по формуле: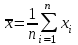 , (2.2) , (2.2)где 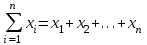 . .Каждая из выше вычисленных мер центра является наиболее пригодной для использования в определенных условиях. Мода вычисляется наиболее просто – ее можно определить на глаз. Более того, для очень больших групп данных это достаточно стабильная мера центра распределения. Медиана занимает промежуточное положение между модой и средним с точки зрения ее вычисления. Эта мера получается особенно легко в случае ранжированных данных. Ранжированием называют расстановку результатов измерений в порядке возрастания или убывания. Среднее арифметическое значение рассчитывается в основном в целях проведения арифметических операций. На величину среднего влияют значения всех результатов. Медиана и мода не требуют для определения всех значений. На величину среднего особенно влияют результаты, которые называют “выбросами”, т.е. данные, находящиеся далеко от центра группы оценок. Вычисление моды, медианы или среднего – чисто техническая процедура. Однако выбор из этих трех мер и их интерпретация зачастую требуют определенного размышления. В процессе выбора следует установить следующее: – в малых группах мода может быть совершенно нестабильной; – на медиану не влияют величины “больших” и “малых” значений; – на величину среднего влияет каждое значение; – некоторые множества данных не имеют центральной тенденции, что часто вводит в заблуждение при вычислении только одной меры центральной тенденции; – когда считают, что группа данных является выборкой из большой симметричной группы, среднее выборки, вероятно, ближе к центру большой группы, чем медиана и мода. Все средние характеристики дают общую характеристику ряда результатов измерений. На практике нас часто интересует, как сильно каждый результат отклоняется от среднего значения. Однако легко можно представить, что две группы результатов измерений имеют одинаковые средние, но различные значения измерений. Поэтому средние характеристики всегда необходимо дополнять показателями вариации, или колеблемости. 5. К характеристикам вариации, или колеблемости, результатов измерений относят размах варьирования, дисперсию, среднее квадратическое отклонение, коэффициент вариации, стандартную ошибку средней арифметической. Самой простой характеристикой вариации является размах варьирования. Его определяют как разность между наибольшим и наименьшим результатами измерений. Однако он улавливает только крайние отклонения, но не отражает отклонений всех результатов. Чтобы дать обобщающую характеристику, можно вычислить отклонения от среднего результата. Сумма этих отклонений всегда равна 0. Чтобы избежать этого, значения каждого отклонения возводят в квадрат. Значение 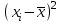 делает отклонения от средней более явственными. Получившуюся сумму делает отклонения от средней более явственными. Получившуюся сумму 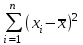 называют суммой квадратов отклонений. Разделив эту сумму на число измерений, получают средний квадрат отклонений, или дисперсию. Она обозначается 2 и вычисляется по формуле: называют суммой квадратов отклонений. Разделив эту сумму на число измерений, получают средний квадрат отклонений, или дисперсию. Она обозначается 2 и вычисляется по формуле: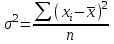 . .Если число измерений не более 30, т.е. n ≤ 30, используется формула: 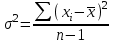 . .Величина n – 1 = k называется числом степеней свободы, под которым подразумевается число свободно варьирующих членов совокупности. Установлено, что при вычислении показателей вариации один член эмпирической совокупности всегда не имеет степени свободы. Эти формулы применяются, когда результаты представлены неупорядоченной (обычной) выборкой. Из характеристик колеблемости наиболее часто используется среднее квадратическое отклонение, которое определяется как положительное значение корня квадратного из значения дисперсии, т.е.: 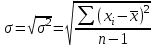 . (2.5) . (2.5)Среднее квадратическое отклонение или стандартное отклонение характеризует степень отклонения результатов от среднего значения в абсолютных единицах и имеет те же единицы измерения, что и результаты измерения. Однако для сравнения колеблемости двух и более совокупностей, имеющих различные единицы измерения, эта характеристика не пригодна. Коэффициент вариации определяется как отношение среднего квадратического отклонения к среднему арифметическому, выраженное в процентах. Вычисляется он по формуле: 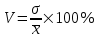 . .В спортивной практике колеблемость результатов измерений в зависимости от величины коэффициента вариации считают небольшой (0 – 10 %), средней (11 – 20 %) и большой (V > 20 %). Коэффициент вариации имеет важное значение в спортивной метрологии, т. к., будучи величиной относительной (измеряется в процентах), позволяет сравнивать между собой колеблемость результатов измерений, имеющих различные единицы измерения. Коэффициент вариации можно использовать лишь в том случае, если измерения выполнены в шкале отношений. 6. Выборки большого объема разбивают на интервалы. В простейшем случае их может быть два. Например, когда необходимо отобрать худших или лучших спортсменов. Однако, для получения достаточно точных результатов число интервалов (его обозначают буквой k) должно быть больше. В зависимости от объема выборки k устанавливают, придерживаясь формулы американского статистика Стерджесса 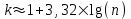 , ,где n – объём выборки.Тогда величина, или шаг интервала, определяется: 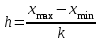 , ,где 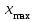 – максимальный результат измерений в выборке, – максимальный результат измерений в выборке, 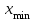 – минимальный результат. – минимальный результат.Используя полученный данные, определяют границы интервалов, а затем частоты интервалов. Частота интервала – количество значений числового ряда, которые попали в данный интервал. Распределение, составленное из частот, в статистике называют вариационным рядом. Анализ вариационных рядов упрощается при графическом представлении. Основные графики вариационного ряда: полигон распределения – график строится в прямоугольной системе координат. Середины интервалов откладываются на оси абсцисс, частоты – на оси ординат. Гистограмма распределения – график строится аналогично полигону распределения, однако на оси абсцисс откладываются не точки (середины интервалов), а отрезки, отображающие интервал, и вместо ординат, соответствующих частотам или частостям отдельных вариантов, строят прямоугольники с высотой, пропорциональной частотам интервалов. Контрольные вопросы для самопроверки: 1. Что изучает теория вероятностей? 2. Дайте определения случайного события, случайной величины. 3. Дискретные и непрерывные случайные величины. 4. Что такое вероятность? 5. Статистическое определение вероятности. 6. Классическое определение вероятности. 7. Генеральная и выборочная совокупность. Объём выборки. 8. Что изучает математическая статистика? 9. Этапы статистического обследования. 10. Как вычисляется среднее арифметическое значение выборки? 11. Дайте определения моды и медианы. 12. Исходя из чего выбирается мера центральной тенденции? 13. Как вычисляется и что показывают дисперсия и среднее квадратическое отклонение? 14. Как вычисляется и что показывает стандартная ошибка среднего арифметического? 15. Как вычисляется и для чего используется коэффициент вариации? 16. Что такое вариационный ряд результатов измерения? 17. Как строятся полигон и гистограмма распределения? |