Девятко И. Методы социологического исследования. Логика социологического исследования методология и логика социологического исследования. Возможно ли объективное и научное социальное знание
 Скачать 1.69 Mb. Скачать 1.69 Mb.
|

|
Анализ связи между двумя переменными Хотя результаты одномерного анализа данных часто имеют самостоятельное значение, большинство исследователей уделяют основное внимание анализу связей между переменными. Самым простым и типичным является случай ана- 5 Для больших выборок биномиальное распределение практически не отличается от нормального. Если Р и Q не слишком различны по величине, достаточно и не очень большой выборки. лиза взаимосвязи (сопряженности) двух переменных. Используемые здесь методы задают некоторый логический каркас, остающийся почти неизменным и при рассмотрении более сложных моделей, включающих множество переменных. Устойчивый интерес социологов к двумерному и многомерному анализу данных объясняется вполне понятным желанием проверить гипотезы о причинной зависимости двух и более переменных. Ведь утверждения о причинных взаимосвязях составляют фундамент не только социальной теории, но и социальной политики (по крайней мере, так принято считать). Так как возможности социологов проверять причинные гипотезы с помощью эксперимента, как уже говорилось, ограниченны, основной альтернативой является статистический анализ неэкспериментальных данных. В общем случае для демонстрации причинно-следственного отношения между двумя переменными, скажем, X и Y, необходимо выполнить следующие требования: 1) показать, что существует эмпирическая взаимосвязь между переменными; 2) исключить возможность обратного влияния Y на X; 3) убедиться, что взаимосвязь между переменными не может быть объяснена зависимостью этих переменных от какой-то дополнительной переменной (или переменных). Первым шагом к анализу взаимоотношений двух переменных является их перекрестная классификация, или построение таблицы сопряженности. Речь идет о таблице, содержащей информацию о совместном распределении переменных. Допустим, в результате одномерного анализа данных мы установили, что люди сильно различаются по уровню заботы о своем здоровье: некоторые люди регулярно делают физические упражнения, другие - полностью пренебрегают зарядкой. Мы можем предположить, что причина этих различий - какая-то другая переменная, например, пол, образование, род занятий, доход и т. п. Пусть мы располагаем совокупностью данных о занятиях физзарядкой и образовании для выборки горожан. Для простоты мы предположим, что обе переменные имеют лишь два уровня: высокий и низкий. Так как данные об образовании исходно разбиты на большее количество категорий, нам придется их перегруппировать, разбив весь диапазон значений на два класса. Предположим, мы выберем в качестве граничного значения 10 лет обучения, так что люди, получившие неполное среднее и среднее образование, попадут в «низкую» градацию, а остальные - в «высокую». (Это, конечно, большое огрубление, но мы используем его из соображений простоты.) Для занятий физическим^ упражнениями мы соответственно воспользуемся двумя категориями - «делают физзарядку» и «не делают физзарядку». Таблица 8.3 показывает, как могло бы выглядеть совместное распределение этих двух переменных. Таблица 8.3 Взаимосвязь между уровнем образования и занятиями физкультуройЗанятия физкультуройУровень образованияВсегонизкийвысокийделают зарядку50200250не делают зарядку20545250всего255245500 В таблице 8.3 два столбца (для образования) и две строки (для занятий физкультурой), следовательно, размерность этой таблицы 2х2. Кроме того, имеются дополнительные крайний столбец и крайняя строка (маргиналы таблицы), указывающие общее количество наблюдений в данной строке или в столбце. В правом нижнем углу указана общая сумма, т. е. общее число наблюдений в выборке. Не давшие ответа уже исключены (для реальных данных их число также стоит указать, но не в таблице, а в подтабличной сноске). Заметим здесь, что многие исследователи при построении таких таблиц пользуются неписаным правилом: для той переменной, которую полагают независимой, отводится верхняя строка (горизонталь), а зависимую располагают «сбоку», по вертикали (разумеется, соблюдение этого правила не является обязательным и ничего с точки зрения анализа не меняет). Обычно характер взаимоотношений между переменными в небольшой таблице можно определить даже «на глазок», сравнивая числа в столбцах или строках. Еще легче это сделать, если вместо абсолютных значений стоят проценты. Чтобы перевести абсолютные частоты, указанные в клетках таблицы, в проценты, нужно разделить их на маргинальные частоты и умножить на 100. Если делить на маргинал столбца, мы получим процент по столбцу. Например, 50/255х100 = 19,6%, т. е. 19,6% имеющих низкий уровень образования делают зарядку (но не наоборот!). Если делить на маргинал строки, то мы получим другую величину -процент по строке. В частности, можно заметить, что 80% делающих зарядку, составляют люди с высоким уровнем образования (200/250х100). Деление на общую численность выборки дает общий процент. Так, всего в выборке 50% людей, делающих зарядку. Так как вывод о наличии взаимосвязи между переменными требует демонстрации различий между подгруппами по уровню зависимой переменной, при анализе таблицы сопряженности можно руководствоваться простыми правилами. Во-первых, нужно определить независимую переменную и, в соответствии с принятым определением, пересчитать абсолютные частоты в проценты. Если независимая переменная расположена по горизонтали таблицы, мы считаем проценты по столбцу; если независимая переменная расположена по вертикали, проценты берутся от сумм по строке. Далее сравниваются процентные показатели, полученные для подгрупп с разным уровнем независимой переменной, каждый раз внутри одной категории зависимой переменной (например, внутри категории делающих зарядку). Обнаруженные различия свидетельствуют о существовании взаимосвязи между двумя переменными. (В качестве упражнения примените описанную процедуру к таблице 8.3, чтобы убедиться в наличии связи между уровнем образования и занятиями физкультурой.) Отметим специально, что элементарная таблица сопряженности размерности 2х2 - это минимально необходимое условие для вывода о наличии взаимосвязи двух переменных. Знания о распределении зависимой переменной недостаточно. Нельзя, например, утверждать, будто из того, что 75% детей-первенцев имеют интеллект выше среднего, а 25% - средний и более низкий, следует зависимость между порядком рождения и интеллектом. Необходимо проанализировать и распределение показателей интеллекта для детей-непервенцев. Варьировать должна не только зависимая, но и независимая переменная. Таблица 8.4 Oбщая форма таблицы сопряженности размерности 2х2 Переменная УПеременная Х01всего1аba+b0сdc+dВсегоа + сb+dп 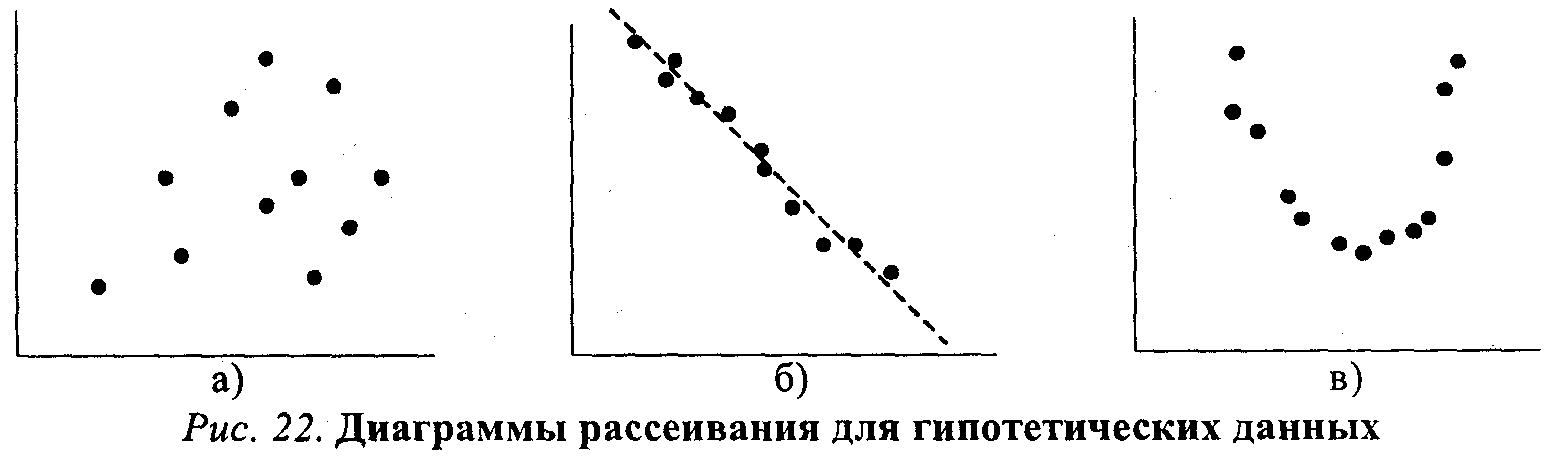 довольно ясно показывает, что всякое приращение в размерах партийной кассы (сдвиг вправо по оси Х) влечет за собой увеличение парламентского представительства (сдвиг вверх по оси ординат). Между переменными Х и Y существует линейное отношение: если одна переменная возрастает по величине, то это же происходит и с другой. Помимо указания на природу отношения двух переменных, диаграмма на рисунке 21 позволяет также сделать некоторые предположения об интенсивности, силе этого отношения. Очевидно, что чем более компактно, «скученно» располагаются точки-наблюдения вокруг пунктирной прямой линии (описывающей идеальное линейное отношение Х и Y), тем сильнее зависимость. На рисунке 22 приведены еще три диаграммы рассеивания. Очевидно, что на рисунке 22а какая-либо связь между xиy попросту отсутствует. На рисунке 22б воображаемая прямая линия (отмечена пунктиром) пересекла бы диаграмму сверху вниз, из левого верхнего в правый нижний угол. Иными словами, линейная связь в этом случае имеет обратное направление: чем больше X, тем меньше зависимая переменная У. Заметим также, что «кучность» расположения точек вдоль воображаемой прямой на рисунке 226 не очень велика, а значит и связь (корреляция) между переменными не только обратная, отрицательная, но еще и не очень сильная, умеренная. Наконец, на рисунке 22в зависимую и независимую переменную связывает явно нелинейное отношение: воображаемый график нисколько не похож на прямую линию и напоминает скорее параболу12. Отметим, что методы анализа, о которых сейчас пойдет речь, не годятся для этого нелинейного случая, так как обычная формула для подсчета коэффициента корреляции даст нулевое значение, хотя связь между переменными существует. Существует обобщенный показатель, позволяющий оценить, насколько связь между переменными приближается к линейному функциональному отношению, которое на диаграмме рассеивания выглядит как прямая линия. Это коэффициент корреляции, измеряющий тесноту связи между переменными, т. е. их тен-денцию изменяться совместно. Как и в рассмотренных выше мерах связи каче-ственных признаков, коэффициент корреляции позволяет оценить возможность предсказания значений зависимой переменной по значениям независимой. Общая формула для вычисления коэффициента корреляции Пирсона включает в себя величину ковариации значений X и Y. Эта величина (sxy) характеризует совместное изменение значений двух переменных. Она задается как сумма произ- 12 Именно так обычно выглядит зависимость между благожелательностью установки по отношению к некоторому объекту (X) и интенсивностью установки (Y): люди, занимающие крайне благожелательную или крайне неблагожелательную позицию в каком-то вопросе, обычно оценивают свои убеждения как более выраженные и интенсивные, чем те люди, чьи установки лежат в области середины, «нейтральных» значений шкалы. ведений отклонений наблюдаемых значений Х и У от средних X и Y соответственно, т. е. Ei=1n (Xi - Х )(Yi -Y ), деленная на количество наблюдений. Чтобы понять «физический смысл» ковариации, достаточно обратить внимание на следующее ее свойство: если для какого-то объекта i в выборке оба значения —X, и Y,— окажутся высокими, то и произведение (Хi - Х) на (Yi - Y) будет большим и положительным. Если оба значения (по Х и по Y) низки, то произведение двух отклонений, т. е. двух отрицательных чисел, также будет положительным. Таким образом, если линейная связь Х и Y положительна и велика, сумма таких произведений для всех наблюдений также будет положительна. Если связь между Х и У обратная, то многим положительным отклонениям по Х будут соответствовать отрицательные отклонения по Y, т. е. сумма отрицательных произведений отклонений будет отрицательной. Наконец, при отсутствии систематической связи произведения будут иногда положительными, иногда отрицательными, а их сумма (и, следовательно, кова-риация Х и Y) будет, в пределе, равна нулю. Таким образом, ко вариация показывает величину и направление связи, совместного изменения Х и У. Если разделить ковариацию sxy на стандартные отклонения sx и sy (чтобы избавиться от влияния масштаба шкал, в которых измеряются X и Y), то мы получим искомую формулу коэффициента корреляции Пирсона (rxy): Более удобная для практических вычислений расчетная формула выглядит так: 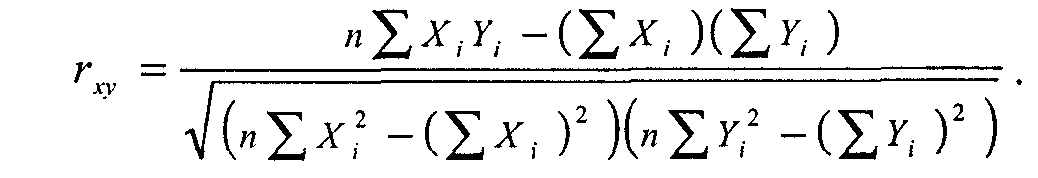 Несмотря на несколько устрашающий вид, расчетная формула очень проста. Для «ручного» вычисления rxy, вам понадобятся лишь пять величин: суммы зна- чений по X и Y (Ei=1nХi и Ei=1nYi), суммы квадратов значений по Х и Y (Ei=1nХ2 и Ei=1nY2), суммы произведений Х и Y по всем объектам-«случаям» (Ei=1n XiYi). В таблице 8.11 приведены данные о максимальных дневных и ночных температурах, зарегистрированных в 10 городах13. Просуммировав значения в столбцах, мы получим E10 i=1Хi =258 и E10 i=1 Yi=156. Возведя каждое из значений Х и Y в квадрат и просуммировав, мы найдем, что E10 i=1Хi2 = 7180 и E10 i=1 Yi2 = 2962. Сумма попарных произведений Хi и Yi (E10 i=1 XiYi) составит 4359. Вы можете самостоятельно убедиться в том, что подстановка всех значений в расчетную формулу даст (надеюсь) величину rxy=0,91. Иными словами, корреляция между дневными и ночными температурами воздуха очень высока, но все же отлична от 1,0 (коэффициент корреляции может меняться в пределах от-1,0 до +1,0). Это отличие, вероятно, объясняется влиянием других факторов (продолжительность дня и ночи, облачность, географическое поло- 13 Погода (Гидрометцентр РФ) // Сегодня. 1994. 23 авг.
жение и т. п.). Судя по полученной величине корреляции, знание дневных температур позволяет предсказывать ночные температуры с очень высокой точностью, но не безошибочно. Величина, которая равна квадрату коэффициента корреляции Пирсона, т. е. г, имеет ряд интересных статистических свойств. Отметим сейчас, что r2 является ПУО-мерой связи, подобной обсуждавшимся выше (см. с. 176—179). Можно показать, что она характеризует ту долю дисперсии значений Y, которая объясняется наличием корреляции между Х и Y. (Естественно, величина r2 будет всегда положительной и не может превзойти по абсолютной величине коэффициент корреляции.) 14 Та часть разброса в значениях Y, которая не может быть предсказана по значениям X,— это дисперсия ошибки нашего прогноза, т. е. 1 - r2. Необъясненный разброс в значениях У присутствует в том случае, когда при равных уровнях Х (ср., например, дневные температуры в Варшаве и Бонне из таблицы 8.11) сохраняются различия в значениях Y. Коэффициент корреляции позволяет оценить степень связи между переменными. Однако этого недостаточно для того, чтобы непосредственно преобразовывать информацию, относящуюся к одной переменной, в оценки другой переменной. Допустим, мы выяснили, что коэффициент корреляции между переменными «величина партийного бюджета» и «число мест в парламенте» равен 0,8. Можем ли мы теперь предсказать, сколько мест в парламенте получит партия, годовой бюджет которой равен 100 млн рублей? Похоже, что знание величины коэффициента корреляции нам здесь не поможет. Однако мы можем вспомнить, что коэффициент корреляции — это еще и оценка соответствия разброса наших наблюдений той идеальной модели линейного функционального отношения, которое на рассмотренных выше диаграммах рассеивания (см. рис. 21—22) представлено пунктирными прямыми. Эти линии называют линиями регрессии. Если бы все наблюдения аккуратно «укладывались» на линию регрессии, то для предсказания значения зависимой переменной достаточно было бы восстано- 14 Подробный анализ можно найти в большинстве руководств по прикладной статистике. Здесь мы ограничимся обсуждением общей логики оценки объясненной дисперсии. вить перпендикуляр к оси Y из той точки прямой, которая соответствует известному значению X. На рисунке 23 показано, как можно было бы графически определить ожидаемые значения Y для гипотетического примера с партийной кассой и местами в парламенте. (Разумеется, найти искомое значение У можно и без линейки, с помощью вычислений, если известен угол наклона регрессионной прямой и точка пересечения с осью ординат.) Как говорилось выше, линия регрессии не обязательно должна быть прямой, но мы ограничимся рассмотрением самого простого случая линейной зависимости (нелинейные связи во многих случаях также могут быть приближенно описаны линейными отношениями). Существуют специальные статистические процедуры, которые позволяют найти регрессионную прямую, максимально соответствующую реальным данным. Регрессионный анализ, таким образом, дает возможность предсказывать значения Y по значениям Х с минимальным количеством ошибок. В общем виде уравнение, описывающее прямую линию регрессии Yno X, выглядит так: где 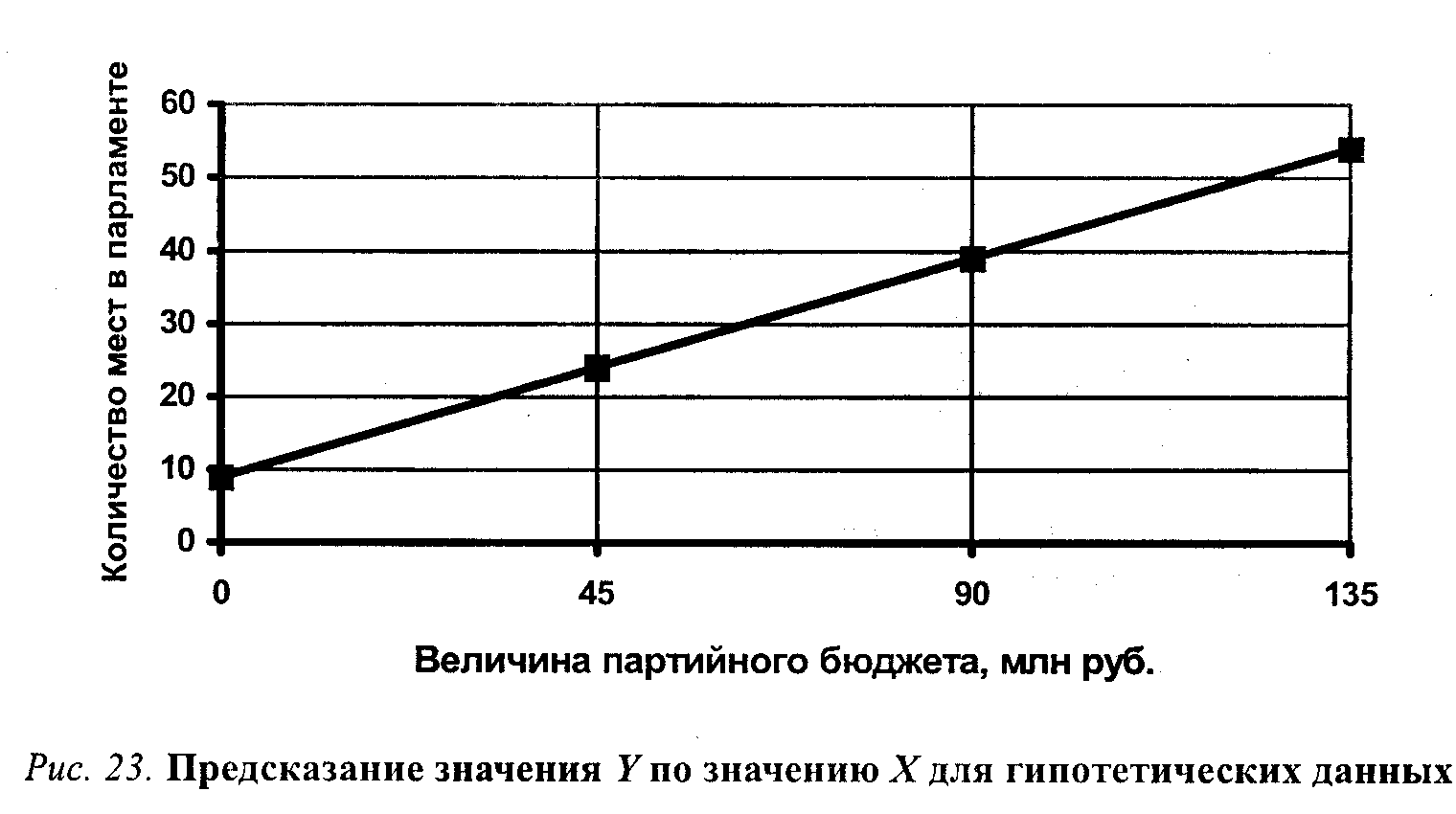 b позволяет сопоставить влияние на независимую переменную контрольных переменных, измеренных в разных шкалах. Социологи обычно осуществляют регрессионный анализ, используя возможности распространенных прикладных пакетов компьютерных программ (например, SPSS). В этом случае для нахождения линии регрессии, лучше всего соответствующей данной выборке наблюдений, которая представлена точками на диаграмме рассеивания, используют метод минимизации взвешенной суммы квадратов расстояний между этими точками и искомой прямой15. Хотя здесь не место для обсуждения статистических деталей, мы все же сделаем несколько замечаний, относящихся к осмысленному (или бессмысленному) использованию техники линейной регрессии. Во-первых, как и в ранее обсуждавшихся примерах анализа связи, наличие координации, согласованности в изменениях двух переменных еще не доказывает, что обнаруженное отношение носит собственно каузальный характер. Проверка альтернативных причинных моделей, иначе объясняющих эмпирическую сопряженность переменных-признаков, может основываться только на содержательных теоретических представлениях. Далее, нужно помнить о том, что регрессионные коэффициенты в общем случае асимметричны. Если мы решим, что это У, а не Х является независимой переменной, то вполне можем рассчитать другую по величине пару коэффициентов — аxу и bxу. (Заметьте, что порядок букв в подстрочном индексе значим: первой всегда идет предсказываемая переменная, а второй — предсказывающая.) Разумеется, при выборе кандидатов в зависимые и независимые переменные также важны не статистические, а содержательные соображения. Если вернуться к затронутой выше взаимосвязи между линейной регрессией и корреляцией, то здесь мы можем сделать следующие дополнения. Пусть все точки-наблюдения аккуратно размещены на регрессионной прямой. Перед нами почти невероятный случай абсолютной линейной зависимости. Зная, например, что коэффициент b (нестандартизованный) равен 313, мы можем утверждать, что именно такова величина воздействия переменной X на зависимую переменную Y. Кроме того, мы можем точно сказать, что единичная прибавка в величине X вызовет увеличение Y на ту же величину, 313 (если, допустим, Х— стаж работы, а У — зарплата, то с увеличением стажа на год зарплата растет на 313 рублей). В этом случае коэффициент корреляции будет равен в точности 1,0, что свидетельствует о сильном, «абсолютном», характере связи переменных. Различие между предсказанными и наблюдаемыми значениями в этом случае отсутствует. Корреляция как мера точности прогноза показывает, что ошибок предсказания просто нет. 15 Более детальные сведения можно найти в статистической литературе. Очень доступно проблема излагается, в частности, в кн.: Гласе Дж., Стенли Дж. Указ. соч. С. 123—141. Для тех же, кто захочет осуществить «ручную» регрессию для какого-либо из использованных примеров, просто приведем формулы для вычисления нестандартизированных коэффициентов (обозначения те же, что и выше): 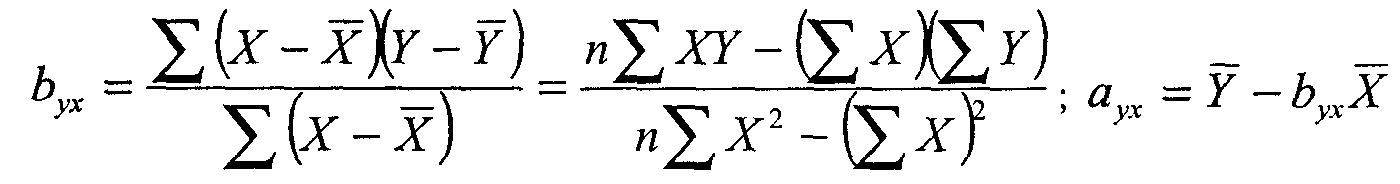 В действительности, однако, из-за влияния других переменных и случайной выборочной ошибки точки-наблюдения обычно лежат выше или ниже прямой, которая, как говорилось, является лишь наилучшим приближением реальных данных. Коэффициент корреляции Пирсона r и величина r2 по-прежнему служат оценкой точности прогноза, основанного на линии регрессии. Вполне возможны ситуации, когда коэффициент регрессии очень велик, воздействие X на Y просто громадно, но корреляция низка и, следовательно, точность прогноза невелика. Нет ничего необычного и в обратной ситуации: воздействие Х на Y относительно мало, а коэффициент корреляции и объясненная дисперсия очень велики. Посмотрев на приведенные выше диаграммы рассеивания, можно легко уяснить себе смысл отношения между корреляцией и регрессией: первая имеет прямое отношение к «разбросанности» точек наблюдения (чем выше «разбросанность», тем ниже r2 и ненадежнее прогноз), тогда как коэффициент регрессии описывает наклон, «крутизну» линии. Однако существующее здесь различие не стоит и преувеличивать: регрессионный коэффициент (наклон прямой) для стандартизованных данных в точности равен коэффициенту корреляции Пирсона r16. Предположим, что исследователь изучает зависимость между образованием матери (X) и образованием детей (Y). Обе переменные измерены как количество лет, затраченных на получение образования. Найдя достаточно высокую корреляцию между Х и У— скажем, равную 0,71, — он также находит коэффициенты регрессии а и b и устанавливает, что r2 (называемый также коэффициентом детерминации) в данном случае приближенно равен 0,5. Это значит, что доля вариации в значениях переменной Y (образование детей), объясненная воздействием переменной-предиктора Х (материнское образование), составляет около 50% общей дисперсии предсказываемой переменной. Коэффициент корреляции между переменными достаточно велик и статистически значим даже для не очень большой выборки. Следовательно, обнаруженная взаимосвязь переменных не может быть объяснена случайными погрешностями выборки. В пользу предложенной исследователем причинной гипотезы говорит и то обстоятельство, что альтернативная гипотеза — образование детей влияет на образовательный статус родителей — крайне неправдоподобна и может быть отвергнута на основании содержательных представлений о временной упорядоченности событий. Однако все еще не исключены те возможности, которые мы обсуждали в параграфе, посвященном методу уточнения. Иными словами, нам следует считаться с вероятностью того, что какая-то другая переменная (или несколько переменных) определяют и образование родителей и образование детей (например, финансовые возможности либо интеллект). Чтобы проверить такую конкурирующую гипотезу, следует рассчитать так называемую частную корреляцию. Логика расчета частной корреляции совпадает с логикой построения частных таблиц сопряженности при использовании метода уточнения. Построить частные таблицы сопряженности для различных уровней контрольной переменной в случае, когда переменные измерены на интервальном уровне,— это практически неразрешимая задача. Чтобы убедиться в этом, достаточно 16 Легко понять, что при измерении в единицах стандартного отклонения максимальная связь (Р= 1,0) соответствует ситуации, когда сдвигу от начала координат в 1 ед. стандартного отклонения по Х соответствует увеличение У также на 1 ед. стандартного отклонения. Важно заметить, что в случае стандартизированных переменных (и только в этом случае) коэффициенты регрессии YnoXиXnoY будут совпадать. подсчитать, каким должно быть количество таблиц уже при десяти-двенадцати категориях каждой переменной. Расчет коэффициента частной корреляции— это простейшее средство уточнения исходной причинной модели при введении дополнительной переменной. Интерпретация коэффициента частной корреляции не отличается от интерпретации частных таблиц сопряженности: частной корреляцией называют корреляцию между двумя переменными, когда статистически контролируется, или «поддерживается на постоянном уровне», третья переменная (набор переменных). Если, предположим, при изучении корреляции между образованием и доходом нам понадобится «вычесть» из полученной величины эффект интеллекта, предположительно влияющего и на образование, и на доход, достаточно воспользоваться процедурой вычисления частной корреляции. Полученная величина будет свидетельствовать о чистом влиянии образования на доход, из которого «вычтена» линейная зависимость образования от интеллекта. Мюллер и соавторы 17 приводят интересный пример использования коэффициента частной корреляции. В исследовании П. Риттербэнда и Р. Силберстайна изучались студенческие беспорядки 1968—1969 гг. Одна из гипотез заключалась в том, что число нарушений дисциплины и демонстраций протеста в старших классах учебных заведений связано с различиями показателей академической успеваемости учащихся. Корреляция между частотой «политических» беспорядков и средней успеваемостью оказалась отрицательной (хуже успеваемость — больше беспорядков) и статистически значимой (r = -0,36). Однако еще более высокой была корреляция между частотой беспорядков и долей чернокожих учащихся (r=0,54). Исследователи решили проверить, сохранится ли связь между беспорядками и успеваемостью, если статистически проконтролировать влияние расового состава учащихся. Коэффициент частной корреляции частоты беспорядков и успеваемости при контроле расового состава учащихся оказался равным нулю. Исходная корреляция между беспорядками и успеваемостью в данном случае может быть описана причинной моделью «ложной взаимосвязи» (см. рис. 19): наблюдаемые значения этих двух переменных скор-релированы лишь потому, что обе они зависят от третьей переменной — доли чернокожих в общем количестве учащихся. Чернокожие студенты, как заметили исследователи, оказались восприимчивее к предложенным самыми активными «политиканами» образцам участия в политических беспорядках. Кроме того, их успеваемость, помимо всяких политических событий, была устойчиво ниже, чем средняя успеваемость белых. Коэффициент частной корреляции между переменными Х и. Y при контроле дополнительной переменной Z (т. е. при поддержании Z «на постоянном уровне») обозначают как rxy.z. Для его вычисления достаточно знать, величины наблюдаемых попарных корреляций между переменными X, Y и Z (т. е. простых корреляций — rxy, ryz, rxz): 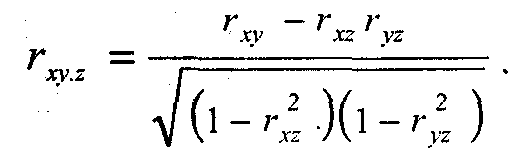 Как всякая выборочная статистика, коэффициент корреляции подвержен выборочному разбросу. Существует некоторая вероятность того, что для данной вы- 17 Mueller J., Schuessler К., Costner H. Statistical Reasoning in Sociology. 3rd ed. Boston: Haighton Mifflin Co, 1977. P. 279—281. борки будет получено ненулевое значение коэффициента корреляции, тогда как истинное его значение для генеральной совокупности равно нулю. Иными словами, существует задача оценки значимости полученных значений корреляций и коэффициентов регрессии, относящаяся к области теории статистического вывода. Описание соответствующих статистических методов выходит за рамки этой книги, поэтому мы рассмотрим лишь самые общие принципы, позволяющие решать описанную задачу в простых случаях и интерпретировать соответствующие показатели при использовании стандартных компьютерных программ. Прежде всего вероятностная оценка коэффициента корреляции подразумевает оценку отношения к его случайной ошибке. Удобная, хотя и не вполне надежная формула для вычисления ошибки коэффициента корреляции (тr), выглядит так18: Всегда полезно вычислить отношение полученной величины r к его ошибке (т. е. r/тi). В использовавшемся нами примере данных о погоде коэффициент корреляции оказался равен 0,91, а его выборочная ошибка составляет: Отношение r к mr обозначаемое как t, составит (0,91/0,573)= 15,88. Разумеется, коэффициент, превосходящий свою случайную ошибку почти в 16 раз, может быть признан значимым даже без построения доверительных интервалов. Когда значение г не столь близко к единице и выборка невелика, нужно все же проверить статистическую гипотезу о равенстве r нулю в генеральной совокупности. Для этого нужно определить t по формуле: 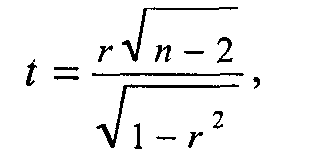 где t — это величина так называемого t-критерия Стьюдента (см. также главу 4), г — выборочный коэффициент корреляции, п — объем выборки. Для установления значимости вычисленной величины t-критерия пользуются таблицами t-распределения для (n - 2) степеней свободы (см. табл. 4.1). Во многих пособиях по статистике можно найти и готовые таблицы критических значений коэффициента корреляции r для данного уровня значимости а. В этом случае отпадает необходимость в каких-либо вычислениях t: достаточно сравнить полученную величину коэффициента корреляции с табличным значением 19. (Например, величина коэффициента корреляции r = 0,55 будет существенной на уровне значимости р = 0,01 даже для выборки объемом 105, так как критическое значение составляет 0,254.) 18 См.: Дружинин Н. К. Логика оценки статистических гипотез. М.: Статистика, 1973. С. 112—114. " См., в частности: Ликеш И., Ляга И. Основные таблицы математической статистики. М.: Финансы и статистика, 1985. (Табл. 14.) | |||||||||||||||||||||||||||||||||||||||