0_МПиИСТС_Все главы. Микропроцессоры и интерфейсные средства транспортных средств
 Скачать 10.01 Mb. Скачать 10.01 Mb.
|

1.10 CISC и RISC процессоры, конвейерное выполнение команд программыCISC (Complex Instruction Set Computer) – (компьютер с полным набором команд) - архитектура реализована во многих типах микропроцессоров, выполняющих большой набор разноформатных команд с использованием многочисленных способов адресации. Эта классическая архитектура процессоров, которая начала свое развитие в 40-х годах прошлого века с появлением первых компьютеров. Типичным примером CISC-процессоров являются микропроцессоры семейства Pentium. Большое многообразие выполняемых команд и способов адресации позволяет программисту реализовать наиболее эффективные алгоритмы решения различных задач. Однако при этом существенно усложняется структура микропроцессора, особенно его устройства управления, что приводит к увеличению размеров и стоимости кристалла, снижению производительности. В то же время многие команды и способы адресации используются достаточно редко. Поэтому, начиная с 80-х годов прошлого века, интенсивное развитие получила архитектура процессоров с сокращенным набором команд (RISC-процессоры). RISC (Reduced Instruction Set Computer) – (компьютер с сокращенным набором команд) - архитектура отличается использованием ограниченного набора команд фиксированного формата. Современные RISC-процессоры обычно реализуют около 100 команд, имеющих фиксированный формат длиной 2 или 4 байта. Также значительно сокращается число используемых способов адресации. Обычно в RISC-процессорах все команды обработки данных выполняются только с регистровой или непосредственной адресацией. При этом для сокращения количества обращений к памяти RISC-процессоры имеют увеличенный объем внутреннего РЗУ – от 32 до нескольких сотен регистров, тогда как в CISC-процессорах число регистров общего назначения обычно составляет 8-16. Обращение к памяти в RISC-процессорах используется только в операциях загрузки данных в РЗУ или пересылки результатов из РЗУ в память. При этом используется небольшое число наиболее простых способов адресации: косвенно-регистровая, индексная и некоторые другие. В результате существенно упрощается структура микропроцессора, сокращаются его размеры и стоимость, значительно повышается производительность. Указанные достоинства RISC-архитектуры привели к тому, что во многих современных CISC-процессорах используется RISC-ядро, выполняющее обработку данных. При этом поступающие сложные и разноформатные команды предварительно преобразуются в последовательность простых RISC-операций, быстро выполняемых этим процессорным ядром. VLIW (Very Large Instruction Word) - архитектура появилась относительно недавно – в 90-х годах 20-го века. Ее особенностью является использование очень длинных команд (до 128 бит), отдельные поля которых содержат коды, обеспечивающие выполнение различных операций. Таким образом, одна команда вызывает выполнение сразу нескольких операций, которые могут производиться параллельно в различных операционных устройствах, входящих в структуру микропроцессора. При трансляции программ, написанных на языке высокого уровня, соответствующий компилятор производит формирование «длинных» VLIW-команд, каждая из которых обеспечивает реализацию процессором целой процедуры или группы операций. Данная архитектура реализована в некоторых типах современных микропроцессоров (PA8500 компании Hewlett-Packard, Itanium – совместная разработка Intel и Hewlett-Packard, некоторые типы DSP - цифровых процессоров сигналов) и является весьма перспективной для создания нового поколения сверхвысокопроизводительных процессоров. 1.11 Конвейерная обработка данныхПри реализации конвейерной обработки выполнение каждой команды разбивается на несколько этапов (ступеней), аналогично сборке автомобиля на конвейере. Работа каждой ступени завершается за 1 такт работы МП. Результат на выходе конвейера появляется с каждым тактом МП (в идеальном случае). Если команды однотипны, то появление результата на выходе не тормозится в ожидании завершения предыдущей команды.
Если же используются разные типы команд, то возникает простой, когда на какой-то ступени конвейера ничего не выполняется.
На рисунке приведен 6-ти ступенчатый конвейер. Весь процесс выполнения команды разбивается на 6 частей: ВК – выборка очередной команды ДК – декодирование очередной команды ФА – формирование адреса операнда ПО – прием операнда из памяти ВО – выполнение операции РР – размещение результата в памяти ПР – простой ОЖ – ожидание Если возникает ситуация, когда нет данных с предыдущей команды для выполнения следующей команды, то происходит замедление работы конвейера, для приведенного на нижнем рисунке примера скорость падает в 5/3 раза. Эффективность работы конвейера будет тем ниже, чем более разнородные команды будут использованы (более эффективно работает конвейер при использовании RISC архитектуры, а при использовании CISC архитектуры наблюдается самая неэффективная работа). С повышением тактовой частоты микрооперации приходится делать более элементарными, чтобы успеть выполнить их за 1 такт (1ГГц такт 1 нс), следовательно, повышается количество ступеней конвейера для того, чтобы микрооперация успевала выполняться за 1 такт. Команды условного ветвления могут сильно замедлить работу конвейера. Для того, чтобы повысить эффективность работы конвейера при работе с командами ветвления используются механизмы предсказания ветвления. Простой механизм предсказания ветвления предполагает, что в очередной раз все будет так же, как в предыдущий. Вероятность правильного предсказания - до 80%. Более сложный механизм предполагает использование статистики. Вероятность правильного предсказания – до 95%. Суперскалярная структура. Возможность повышения производительности процессора достигается также путем включения в его структуру нескольких параллельных функционирующих операционных устройств, обеспечивающих одновременное выполнение нескольких операций, т.е. в процессоре имеется несколько исполнительных конвейеров, работающих параллельно. Такая структура МП называется суперскалярной. В идеале, в МП может одновременно обрабатываться столько команд, сколько в нем имеется операционных устройств. Реально при использовании от 4 до 10 операционных устройств удается обеспечить выполнение за такт от 2 до 6 команд, т.к. сложно обеспечить равномерную загрузку операционных устройств. Эффективная одновременная работа нескольких исполнительных конвейеров обеспечивается путем предварительной выборки и декодирования ряда команд и выделения среди них группы команд, которые могут использоваться одновременно. Обычно в МП используется несколько устройств для выполнения целочисленных операций, одно или несколько устройств для выполнения операций с плавающей точкой и отдельное устройство для обработки специальных форматов аудио и видео данных. Параллельно с ними работают устройства для формирования адресов и выборки операндов для исполняемых команд. Здесь реализуется спекулятивная (предварительная) выборка операндов. В итоге результаты последующих команд могут быть доступны раньше результатов предыдущих. Результаты выполнения команд могут быть получены не в том порядке, в каком они записаны в программе. Для упорядочивания вводится специальный буфер, который устанавливает требуемый порядок выдачи результатов. Одновременное выполнение команд может оказаться невозможным, если они обращаются к одному и тому же регистру. При ограниченной емкости РЗУ эта ситуация может возникать часто. Чтобы ее нейтрализовать, вводят специальные регистровые блоки, дублирующие основное РЗУ. Тогда, если происходит одновременное обращение к одному и тому же регистру, то один из запросов перенаправляется к дублирующему регистру – «переименование регистра». На рис. 1.8 представлена суперскалярная структура Гарвардской архитектуры. В ней используются 2 конвейера по 6 степеней в каждом. Устройство управления обеспечивает выборку, декодирование и распределение команд. В структуре присутствуют 2 устройства, которые работают с целочисленными данными (SIU1, SIU2), 1 устройство работает с данными в форме с плавающей запятой (FPU) и 1 устройство (MIU) выполняет сложные операции с целыми числами (умножение, деление). Блок работы с числами с плавающей запятой обслуживается собственным набором регистров по 64 бита (блок FPR); дополнительно имеется буфер - 1 набор из 8 регистров по 32 бита, т.е. каждый из регистров блока имеет дублирующий регистр. Блок DSU обеспечивает выборку операндов из памяти. После выполнения операнды накапливаются в специальном буфере (блоке завершения), который и записывает их в память в требуемой последовательности.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
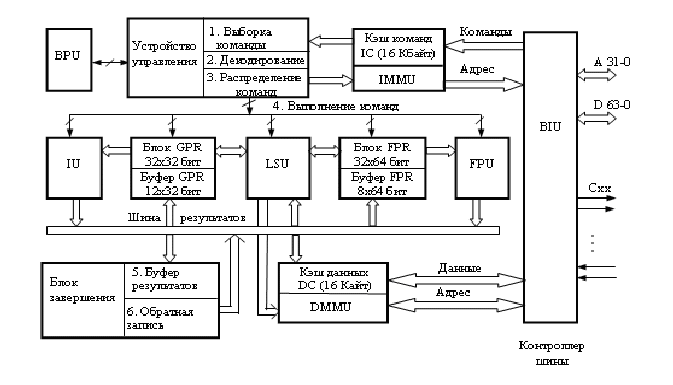 Рис. 1.8 Суперскалярная структура Гарвардской архитектуры
Рис. 1.8 Суперскалярная структура Гарвардской архитектуры