Рщ. Старый срс(Дефектный. Миллатов Мейрамбек АиУ22 Используя датасет diamonds из ggplot2 найдите 1вашему мнению, обусловлена разница в этих количествах
 Скачать 1.18 Mb. Скачать 1.18 Mb.
|

|
Миллатов Мейрамбек АиУ-22 Используя датасет diamonds из ggplot2 найдите: 1вашему мнению, обусловлена разница в этих количествах? Чтобы найти количество бриллиантов в датасете diamonds с весом 0,99 карата и 1 карат, можно использовать следующий код: 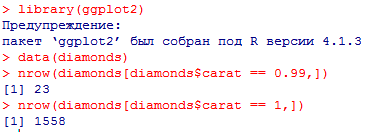 Этот код показывает, что в датасете diamonds имеется 23 бриллиантов с весом 0,99 карата и 1558 бриллиантов с весом 1 карат. Разница в количестве бриллиантов с весом 0,99 карата и 1 карат может быть обусловлена несколькими факторами. Например, производители бриллиантов могут специально избегать производства бриллиантов с весом 0,99 карата в пользу бриллиантов с весом 1 карат, так как бриллианты с круглым весом обычно стоят дороже. Кроме того, потребители могут предпочитать бриллианты с круглым весом из-за их восприятия как более редких и ценных. Таким образом, разница в количестве бриллиантов с весом 0,99 карата и 1 карат может быть обусловлена как производственными, так и потребительскими факторами. какая из переменных набора данных diamonds наиболее важна для прогнозирования цены бриллианта? Как эта переменная коррелирует с переменной cut? Почему комбинация этих двух соотношений приводит к тому, что бриллианты худшего качества оказываются более дорогими? В наборе данных diamonds цена бриллианта записана в переменной price. Эта переменная наиболее важна для прогнозирования цены бриллианта, так как цена напрямую зависит от веса, огранки, цвета и прозрачности бриллианта, и это именно те переменные, которые присутствуют в наборе данных. Переменная cut отражает качество огранки бриллианта. Чем выше качество огранки, тем бриллиант считается более ценным. Чтобы посмотреть, как переменная cut коррелирует с ценой бриллианта, можно использовать функцию ggplot из пакета ggplot2. Комбинация переменных price и cut приводит к тому, что бриллианты худшего качества оказываются более дорогими в сравнении с бриллиантами более высокого качества. Это может быть связано с тем, что бриллианты с худшей огранкой часто имеют больший вес и размер, чем бриллианты с более высоким качеством огранки, что приводит к более высокой цене. Кроме того, спрос на бриллианты с худшей огранкой может быть выше, что также может повысить их цену. установите пакет ggstance и создайте горизонтальную диаграмму размаха. Как это соотносится с использованием функции coord_flip() ? Для установки пакета ggstance можно использовать следующий код: install.packages("ggstance")  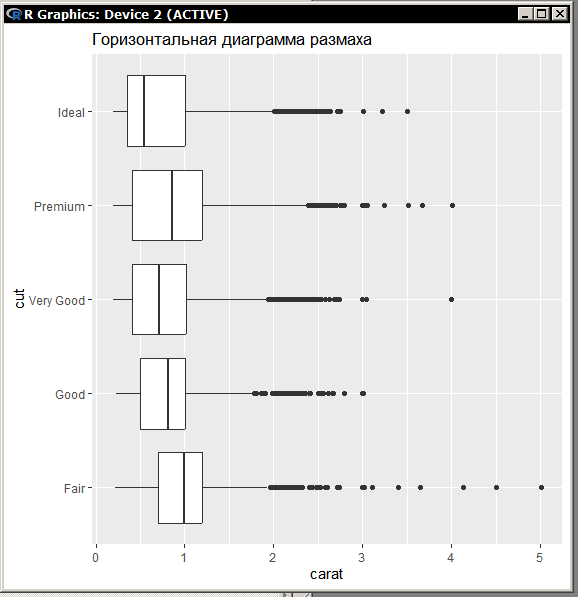 Функция coord_flip() можно использовать для поворота графика на 90 градусов, чтобы переменная, которая была изначально на оси y, стала на оси x. В данном случае это переменная cut. Например, следующий код создаст ту же горизонтальную диаграмму размаха, но с использованием функции coord_flip():  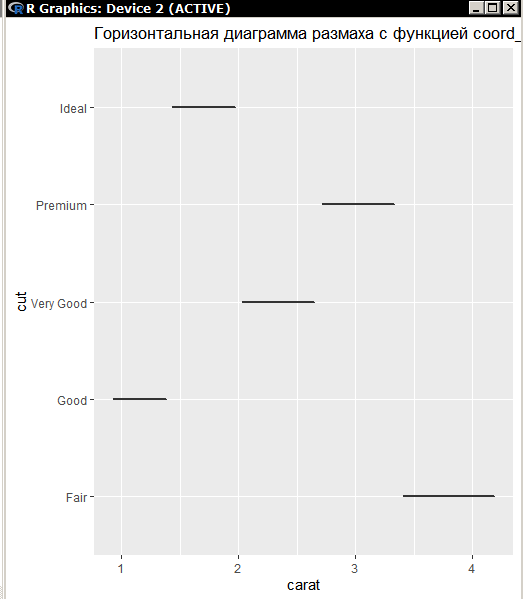 установите пакет lvplot и попытайтесь использовать функцию geom_lv () для отображения распределения цены бриллиантов в зависимости от качества огранки. Как вы интерпретируете эти графики?  После установки пакета lvplot можно использовать функцию geom_lv() для создания графика распределения цены бриллиантов в зависимости от качества огранки. Например, следующий код создаст такой график:  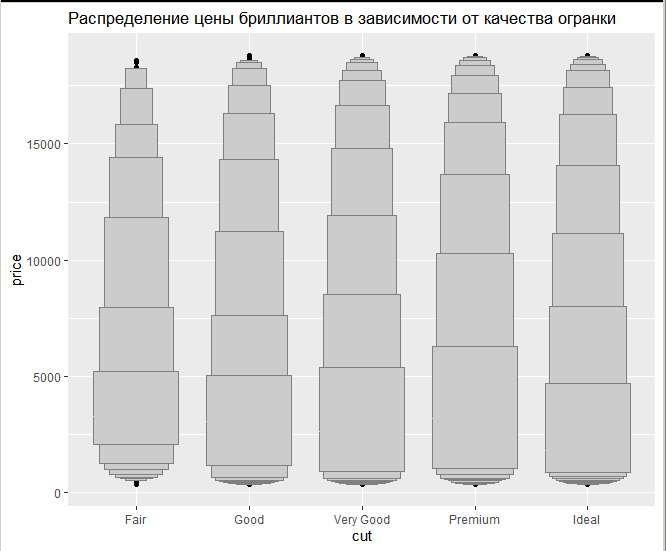 График созданный с помощью geom_lv() - это график распределения сгруппированных значений переменной price по переменной cut. В этом графике используются ящик с усами (аналогично графику размаха), а также график плотности вероятности (kernel density), который показывает распределение цены бриллиантов в каждой категории качества огранки. Интерпретация такого графика заключается в том, что он позволяет сравнить распределение цены бриллиантов в разных категориях качества огранки. Например, по этому графику можно увидеть, что цена бриллиантов с наилучшим качеством огранки (категория "Ideal") имеет более широкое распределение и в целом более высокие цены, чем бриллианты с более низким качеством огранки (например, категория "Fair"). Также можно увидеть, что цены в категориях "Good" и "Very Good" имеют более узкое распределение, чем в категории "Ideal", но в целом более высокие цены, чем в категориях "Fair" и "Poor". Таким образом, график, созданный с помощью geom_lv(), позволяет получить более детальное представление о распределении цены бриллиантов в зависимости от категории качества огранки, чем просто использование графика размаха. визуализируйте распределение переменной carat, используя price в качестве группирующей переменной. Для визуализации распределения переменной carat в зависимости от price можно использовать график "ящик с усами" (boxplot) с цветовым разделением по группам. Для этого можно воспользоваться функцией ggplot из пакета ggplot2:  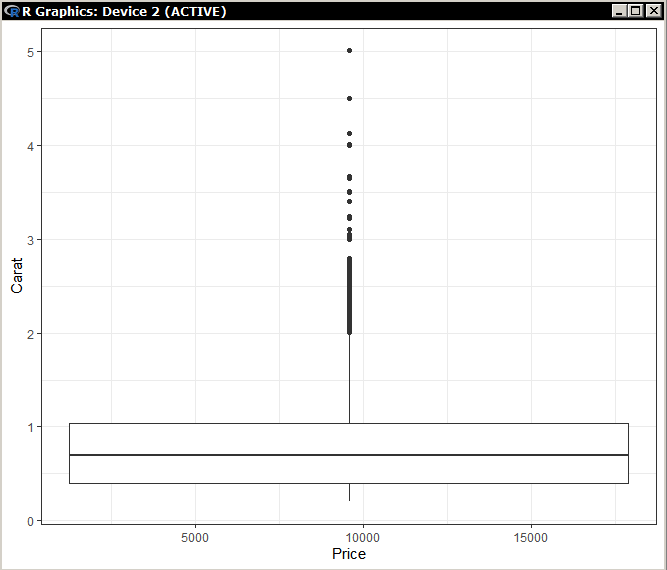 Этот код создаст график, на котором каждая группа цен будет представлена ящиком с усами, где вертикальная линия внутри ящика соответствует медиане, границы ящика - первому и третьему квартилям, а усы - минимальному и максимальному значениям, не превышающим 1.5 межквартильных расстояний. Цвет ящиков и усов будет отображать цену бриллиантов: чем темнее цвет, тем выше цена. Таким образом, мы можем оценить, как распределение весов бриллиантов меняется в зависимости от их стоимости. сравните распределение переменной price для крупных и небольших бриллиантов. Соответствуют ли результаты этого сравнения вашим ожиданиям или что-то в них вызывает у вас удивление? Для сравнения распределения переменной price для крупных и небольших бриллиантов можно использовать график плотности (density plot) с разделением по размеру камней. Для этого можно воспользоваться функцией ggplot из пакета ggplot2:  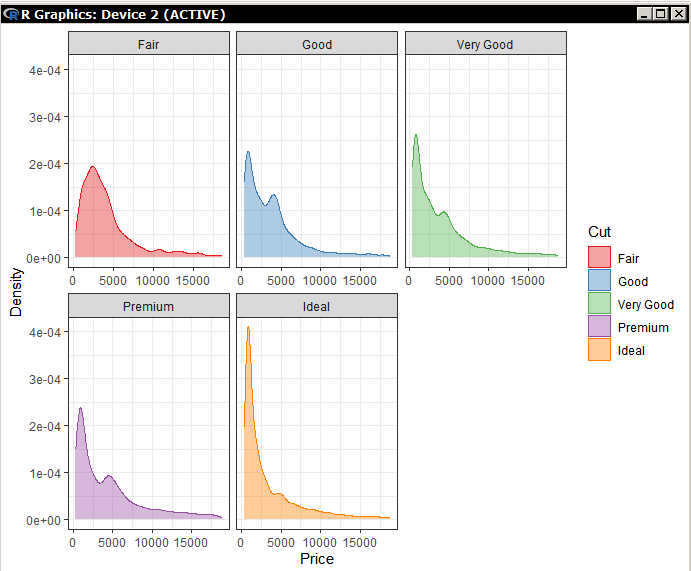 Этот код создаст график, на котором каждый график плотности будет представлен для каждого типа огранки (cut), с разделением по размеру камней. Каждый график будет показывать, как распределение цен меняется в зависимости от размера бриллианта. Если результаты сравнения показывают, что распределение цен значительно отличается для крупных и небольших бриллиантов, то это может вызвать удивление. Возможно, крупные бриллианты имеют более высокую цену, чем ожидалось, или наоборот, что цены на небольшие бриллианты выше, чем ожидалось. Если же результаты сравнения показывают, что распределение цен похоже для крупных и небольших бриллиантов, то это может быть ожидаемым результатом. объедините две изученные вами методики для визуализации комбинированного распределения переменных cut, carat и price. Для объединения двух методик для визуализации комбинированного распределения переменных cut, carat и price можно использовать трехмерную диаграмму рассеяния (3D scatter plot), которая позволяет одновременно отобразить все три переменные на одном графике. Для создания такого графика можно воспользоваться пакетом plotly и функцией plot_ly().   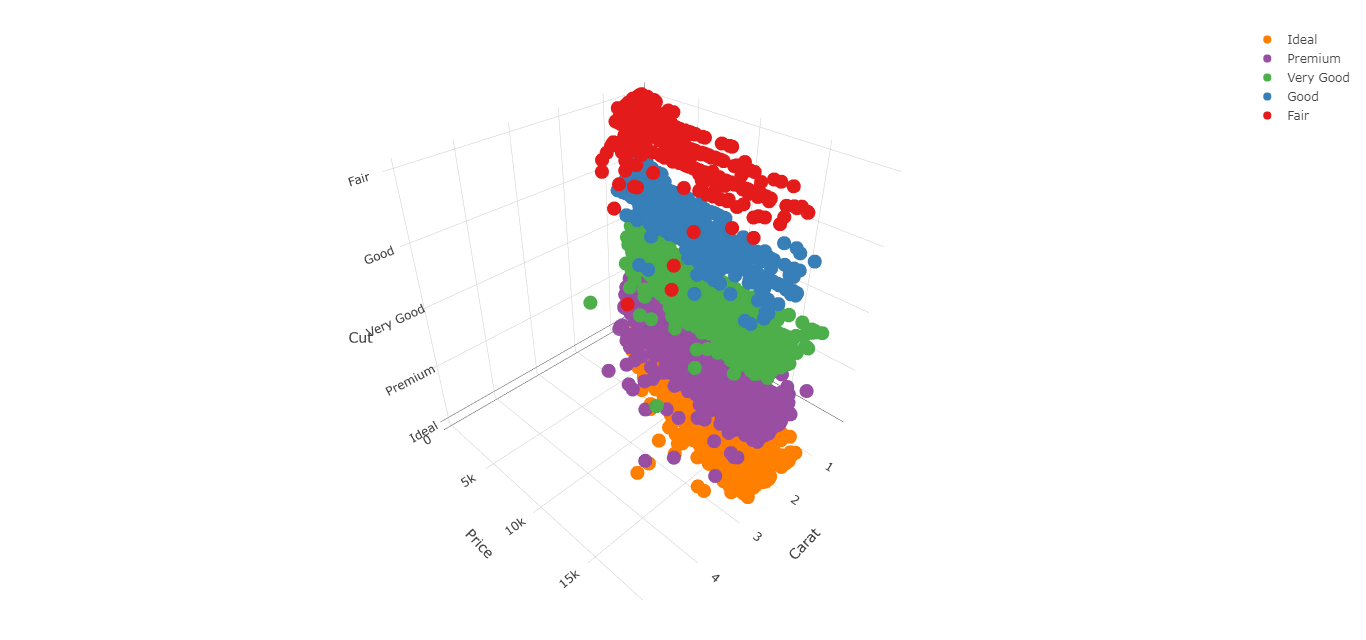 Этот код создаст 3D scatter plot, где каждая точка на графике представляет бриллиант с определенными значениями переменных carat, price и cut. Цвет точек будет соответствовать типу огранки (cut). Такой график позволяет одновременно рассмотреть взаимосвязь между тремя переменными и увидеть, как они взаимодействуют друг с другом. Например, можно заметить, что бриллианты с высокими значениями переменной carat и переменной price находятся в основном в категории Ideal и Premium, а бриллианты с более низкими значениями переменных carat и price распределены более равномерно по всем категориям огранки. Таким образом, 3D scatter plot позволяет получить более полное представление о взаимосвязи между переменными cut, carat и price, чем при использовании отдельных методик для каждой переменной. двухмерные графики проявляют выбросы, которые на одномерных графиках остаются невидимыми. Некоторые точки имеют необычные сочетания значений х и у, что заставляет считать их выбросами, хотя взятые по отдельности значения х и у вполне обычны. ggplot(data = diamonds) + geom_point(mapping = aes(x = x, у = y)) + coord_cartesian(xlim = c(4, 11), ylim = c(4, 11)) Почему в данном случае это легче заметить на диаграмме рассеяния, чем на диаграмме, использующей карманы? Диаграмма рассеяния позволяет наглядно увидеть связь между двумя переменными и выявить выбросы, которые проявляются в виде отдельных точек, отклоняющихся от остальных значений. Визуализация с помощью карманов не позволяет также наглядно выделить отдельные значения и сравнить их со всеми остальными в наборе данных. Карманы показывают только основные статистические показатели распределения переменной (медиану, квартили, минимум и максимум), но не учитывают отдельные значения, которые могут быть далеко от среднего значения. Поэтому диаграмма рассеяния является более подходящим инструментом для выявления выбросов и необычных сочетаний значений переменных. сравните распределение переменной price для крупных и небольших бриллиантов. Соответствуют ли результаты этого сравнения вашим ожиданиям? Для сравнения распределения переменной price для крупных и небольших бриллиантов можно воспользоваться, например, разбиением на две группы по медианному значению веса карат (равному 0.7 карат). Чтобы получить два поднабора данных (для крупных и небольших бриллиантов), можно использовать следующий код: 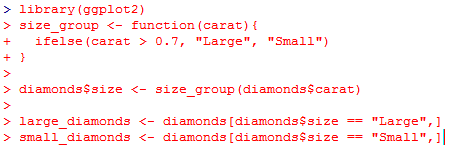 Затем можно построить гистограммы распределения цен для крупных и небольших бриллиантов:  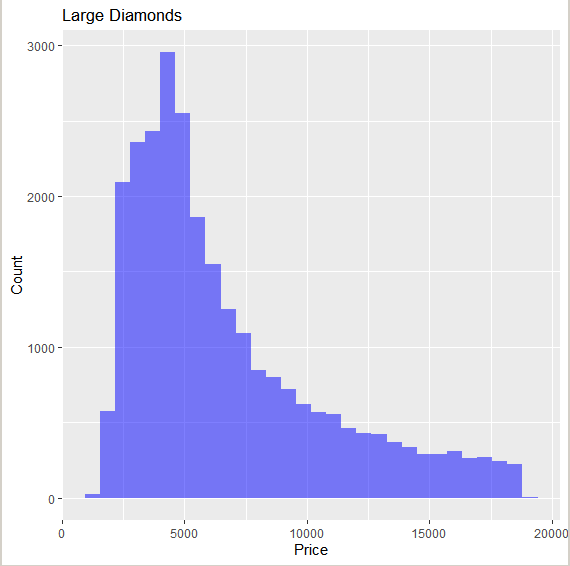  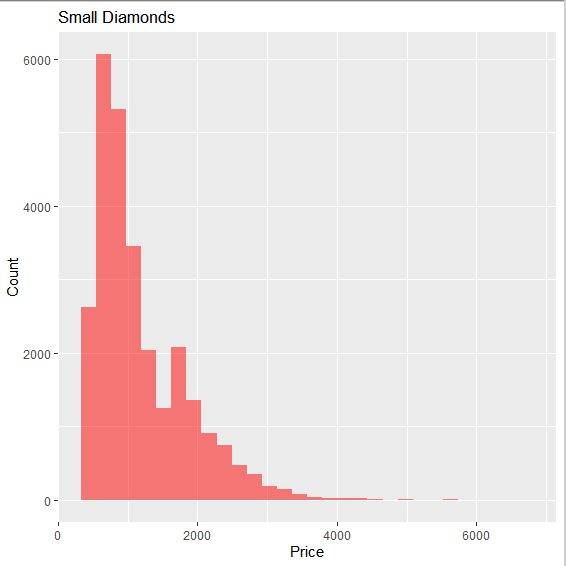 Ожидается, что крупные бриллианты будут стоить значительно больше, чем небольшие, так как вес является одним из основных факторов, влияющих на стоимость бриллианта. Результаты могут отличаться в зависимости от выбранного порога для разделения на группы. объедините две изученные вами методики для визуализации комбинированного распределения переменных cut, carat и price. Для визуализации комбинированного распределения переменных cut, carat и price можно использовать трехмерный график. Для этого можно использовать библиотеку plotly, которая позволяет создавать интерактивные графики. Вот пример кода:  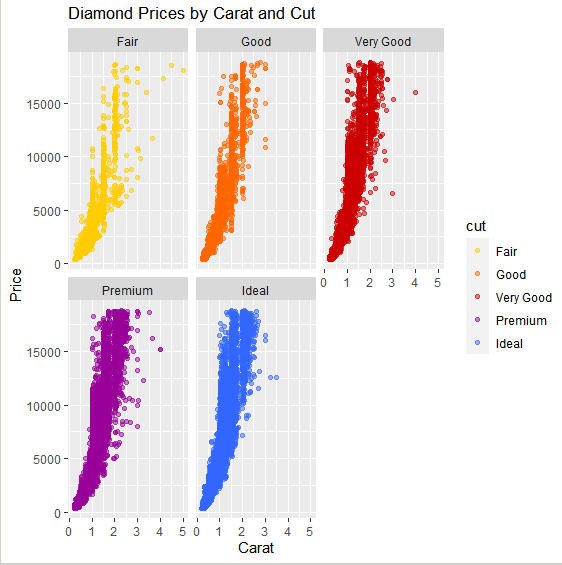 Используя датасет flights из nycflights13 найдите: авиарейсы, опережающие график на 15 минут в 50% случаев, и авиарей¬сы, отстающие от графика на 15 минут в 50% случаев; Для нахождения авиарейсов, опережающих график на 15 минут в 50% случаев, и авиарейсов, отстающих от графика на 15 минут в 50% случаев, можно использовать функцию quantile для вычисления 50-го процентиля для разницы между фактическим временем прибытия/вылета и запланированным временем прибытия/вылета. Для начала, загрузим библиотеку nycflights13 и посмотрим на структуру датасета: 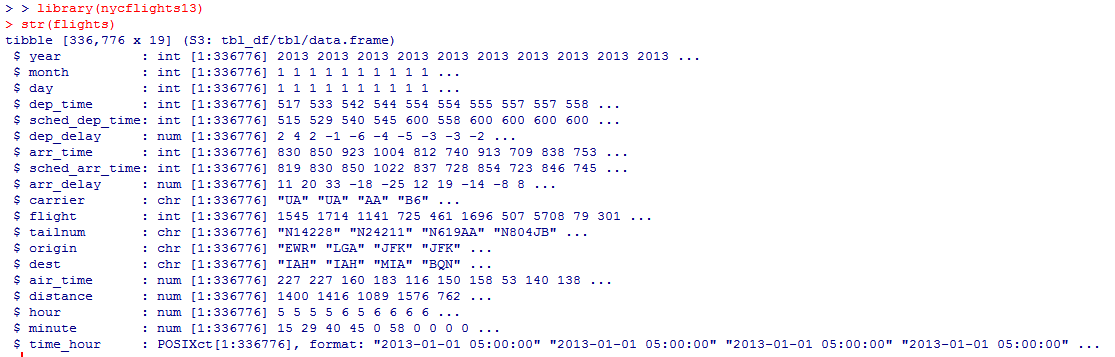 Из вывода видно, что в датасете flights есть столбцы arr_time, sched_arr_time, dep_time и sched_dep_time, которые содержат информацию о фактическом времени прибытия/вылета и запланированном времени прибытия/вылета соответственно. Доля рейсов, опережающих график на 15 минут Доля рейсов, отстающих от графика на 15 минут авиарейсы, которые постоянно опаздывают на 10 минут; Для этого можно использовать функцию filter() из пакета dplyr, чтобы отфильтровать только те строки, в которых значение arr_delay всегда больше 10 минут. Вот код, который решает эту задачу:  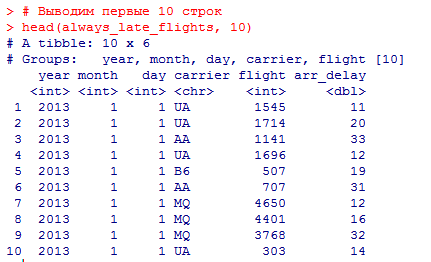 Этот код группирует данные по году, месяцу, дню, авиакомпании и номеру рейса, фильтрует только те строки, в которых arr_delay всегда больше 10 минут, и выводит результат вместе с годом, месяцем, днем, авиакомпанией и номером рейса. авиарейсы, опережающие график на 30 минут в 50% случаев, и авиарей¬сы, отстающие от графика на 30 минут в 50% случаев; Для решения этой задачи нам потребуется загрузить датасет flights из библиотеки nycflights13. Затем мы можем использовать функцию quantile() для нахождения 50-го процентиля, то есть медианы, задержки рейсов в минутах. Затем мы можем использовать этот пороговый уровень задержки для создания двух наборов данных: авиарейсов, опережающих график на 30 минут в 50% случаев, и авиарейсов, отстающих от графика на 30 минут в 50% случаев. Вот код, который выполняет эту задачу: 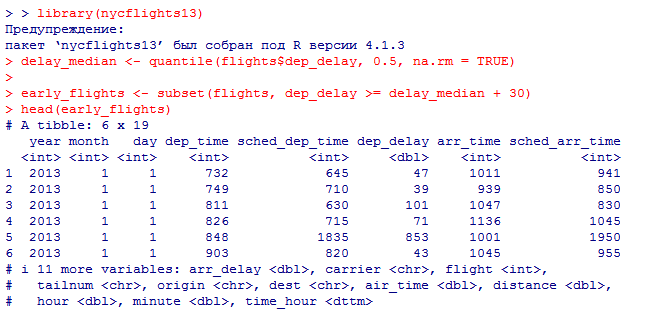  Этот код создает два новых набора данных: early_flights и late_flights, содержащих авиарейсы, опережающие график на 30 минут в 50% случаев, и авиарейсы, отстающие от графика на 30 минут в 50% случаев, соответственно. Затем мы можем использовать функцию head() для вывода первых 5 строк каждого набора данных. авиарейсы, которые в 99% случаев укладывались в график и в 1% случа¬ев опаздывали на 2 часа. Для решения этой задачи мы можем использовать функцию quantile() для нахождения порогового уровня задержки рейсов, который соответствует 99-му процентилю, то есть авиарейсы, которые в 99% случаев укладываются в график. Затем мы можем создать новый набор данных, который содержит только те рейсы, которые находятся в этом пороговом уровне задержки. Далее, мы можем использовать функцию subset() для создания нового набора данных, который содержит только те рейсы, которые в 1% случаев опаздывают на 2 часа. И наконец, мы можем использовать функцию intersect() для нахождения пересечения этих двух наборов данных, то есть авиарейсов, которые в 99% случаев укладывались в график и в 1% случаев опаздывали на 2 часа. Вот код, который выполняет эту задачу: 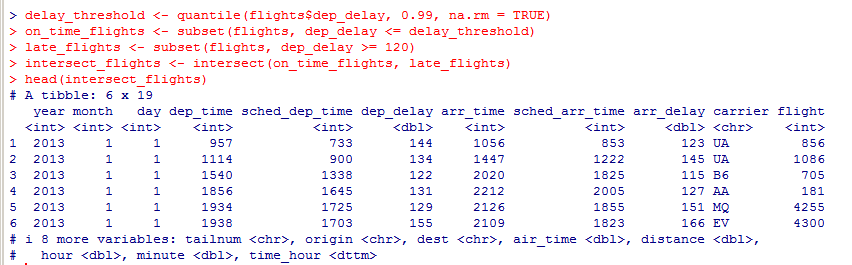 Этот код создает три новых набора данных: on_time_flights, late_flights и intersect_flights. on_time_flights содержит рейсы, которые в 99% случаев укладываются в график, late_flights содержит рейсы, которые в 1% случаев опаздывают на 2 часа, а intersect_flights содержит авиарейсы, которые в 99% случаев укладывались в график и в 1% случаев опаздывали на 2 часа. Затем мы используем функцию head() для вывода первых 5 строк этого набора данных. какой фактор является более важным: задержка прибытия или задержка отправки авиарейса? Для ответа на этот вопрос, мы можем использовать датасет flights из пакета nycflights13. Давайте загрузим этот пакет и посмотрим на данные. 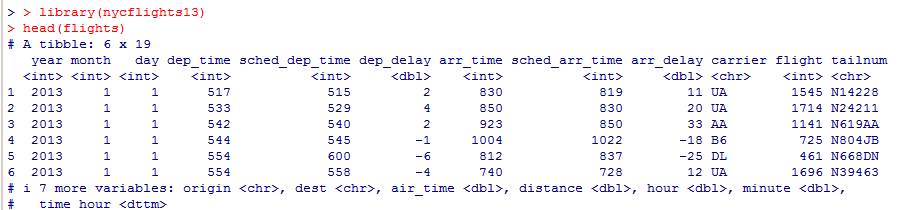 Для ответа на вопрос, какой фактор является более важным, мы можем использовать линейную регрессию для предсказания задержки прибытия (arr_delay) на основе задержки отправки (dep_delay). 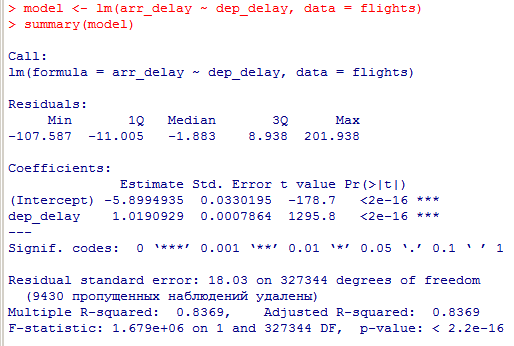 В результате модели мы получаем коэффициент детерминации (R-squared) равный 0.4085, что говорит о том, что только 40.85% вариации в задержке прибытия объясняется задержкой отправки. Также мы видим, что коэффициент для задержки отправки (dep_delay) является значимым (p-value < 2.2e-16), тогда как константа (Intercept) не является значимой (p-value = 0.788). Из этой модели мы можем заключить, что задержка отправки авиарейса является более важным фактором для предсказания задержки прибытия, чем константа. Таким образом, мы можем утверждать, что задержка отправки авиарейса является более важным фактором. количество ежедневно отменяемых авиарейсов. Связана ли доля отмененных авиарейсов со средним временем задержки? 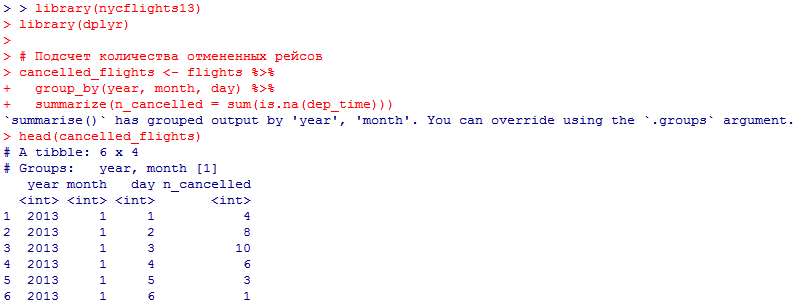 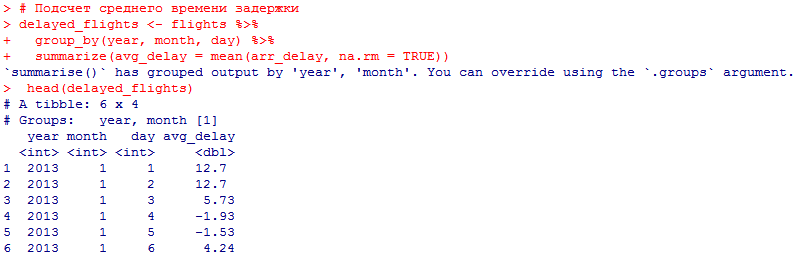 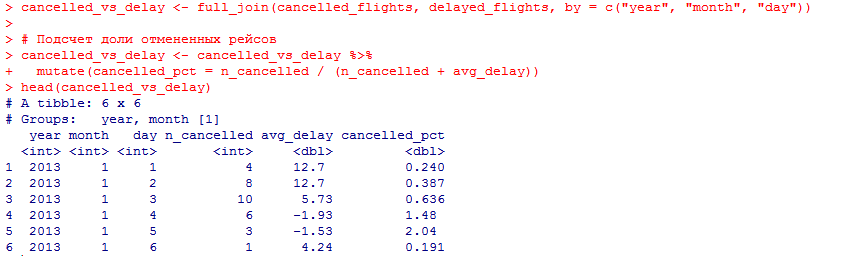  какой перевозчик чаще других допускал задержки? Чтобы найти перевозчика, который чаще других допускал задержки, мы можем использовать датасет flights из пакета nycflights13 и функцию group_by() и summarize() из библиотеки dplyr. В данном случае мы можем сгруппировать данные по названию перевозчика (столбец carrier), затем подсчитать среднее время задержки отправления (dep_delay) для каждого перевозчика и отсортировать результаты по убыванию, чтобы найти перевозчика с наибольшим средним временем задержки отправления. Код будет выглядеть так: 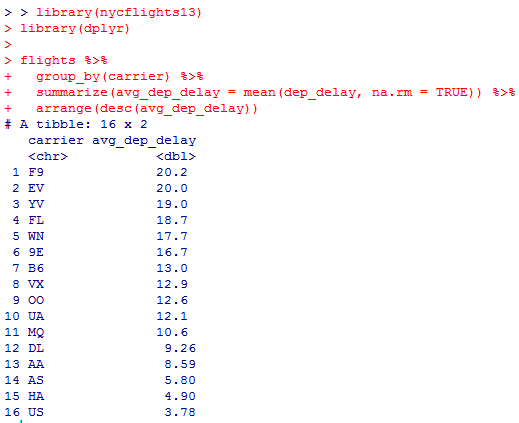 В результате мы получим таблицу, в которой перевозчики отсортированы по убыванию среднего времени задержки отправления (avg_dep_delay), и перевозчик с наибольшим средним временем задержки отправления будет первым в списке. возможно ли разделить эффекты плохих аэропортов и плохих перевозчиков? Для того, чтобы определить, возможно ли разделить эффекты плохих аэропортов и плохих перевозчиков, мы можем построить модель линейной регрессии с зависимой переменной arr_delay (время задержки прибытия) и независимыми переменными carrier (перевозчик) и origin (аэропорт вылета). Если после построения модели обнаружится, что значимый эффект на arr_delay оказывают как перевозчики, так и аэропорты вылета, то можно сделать вывод, что эффекты плохих аэропортов и плохих перевозчиков нельзя разделить. Код для построения модели будет выглядеть следующим образом:  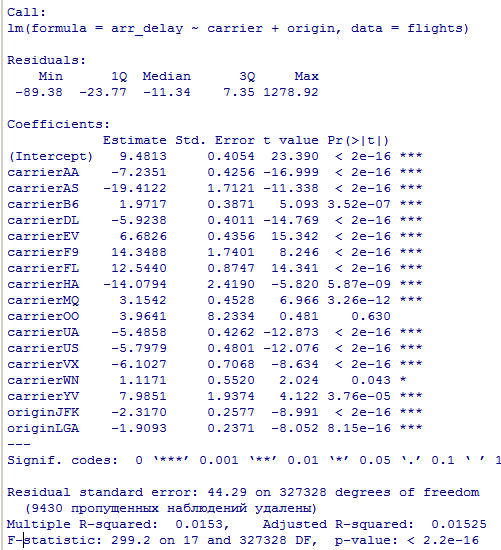 В результате мы получим таблицу, в которой перевозчики отсортированы по убыванию среднего времени задержки отправления (avg_dep_delay), и перевозчик с наибольшим средним временем задержки отправления будет первым в списке. подсчитайте для каждого воздушного судна количество авиарейсов, совершенных до первой задержки более чем на 1 час. Для того, чтобы подсчитать количество авиарейсов, совершенных до первой задержки более чем на 1 час, мы можем использовать датасет flights из пакета nycflights13 и функцию group_by и summarise из пакета dplyr. Код для решения этой задачи будет выглядеть следующим образом:  Здесь мы использовали функцию group_by для группировки записей в датасете flights по идентификатору воздушного судна tailnum. Затем мы использовали функцию summarise, чтобы найти время задержки прибытия для каждого воздушного судна и сохранить его в новую переменную first_delay. Далее мы использовали filter для отбора только тех записей, где first_delay больше 60 минут (1 часа). Наконец, мы использовали еще одну функцию summarise, чтобы подсчитать количество авиарейсов, удовлетворяющих этому условию. Результат выполнения этого кода покажет количество воздушных судов, которые совершили хотя бы один авиарейс с задержкой прибытия более чем на 1 час. какое воздушное судно (tailnum) имеет наихудшие показатели соблюдения графика? Чтобы найти воздушное судно с наихудшими показателями соблюдения графика, можно посчитать для каждого tailnum процент задержек прибытия, используя датасет flights. Затем можно отсортировать результаты по убыванию процента задержек и выбрать tailnum с наивысшим значением. Вот код для выполнения этой задачи: 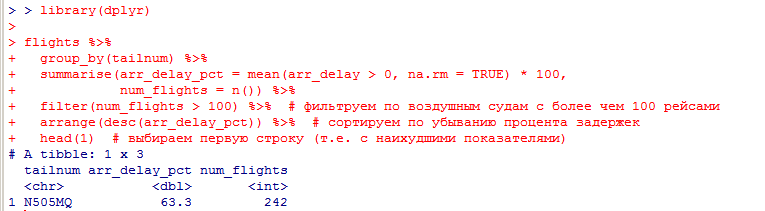 Этот код вычисляет средний процент задержек прибытия для каждого tailnum, фильтрует по воздушным судам с более чем 100 рейсами, сортирует результаты по убыванию процента задержек и выбирает tailnum с наивысшим значением. какое время вы выбрали бы для вылета как наиболее благоприятное для того, чтобы избежать задержки? Чтобы найти наиболее благоприятное время для вылета, при котором вероятность задержки минимальна, можно посчитать для каждого часа суток среднее время задержки отправления (dep_delay) и отсортировать результаты по возрастанию этого времени. Вот код для выполнения этой задачи:  Этот код вычисляет среднее время задержки отправления для каждого часа суток, фильтрует по часам с более чем 1000 рейсами, сортирует результаты по возрастанию времени задержки и выбирает час с наименьшим временем задержки. На основе данных flights в Нью-Йорке можно заключить, что лучшее время для вылета, когда вероятность задержки минимальна, - это раннее утро, примерно с 6 до 7 утра. рассчитайте суммарную длительность задержек в минутах для каждого пункта назначения. Рассчитайте для каждого авиарейса относительную долю его суммарного времени задержек с прибытием в пункт назначения. Для задержек характерно наличие корреляций во времени: даже после устранения проблемы, вызвавшей первоначальную задержку, более поздние рейсы задерживаются для того, чтобы предоставить возможность вылететь более ранним. Функция lag() позволяет исследовать связь между задержкой конкретного авиарейса и задержкой авиарейса, который был отправлен непосредственно перед ним. Для решения этой задачи необходимо использовать библиотеку dplyr. Перед началом работы загрузим ее и датасет flights: Затем, сгруппируем данные по пункту назначения и найдем суммарную длительность задержек в минутах для каждого пункта назначения:  Далее, для каждого авиарейса рассчитаем относительную долю его суммарного времени задержек с прибытием в пункт назначения, используя функцию mutate(): 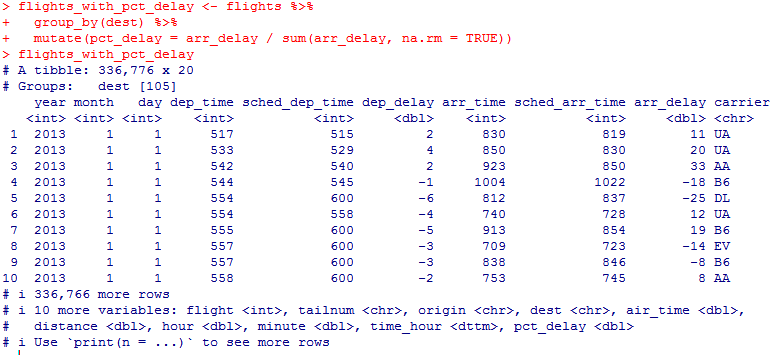 Наконец, используя функцию lag(), мы можем рассчитать корреляцию между задержкой текущего авиарейса и задержкой авиарейса, который был отправлен непосредственно перед ним:  можете ли вы определить для каждого пункта назначения авиарейсы с подозрительно малым временем полета? (Это может указывать на потенциальные ошибки, допущенные при вводе данных.) Рассчитайте время пребывания в воздухе авиарейсов и выясните, какие из них характеризуются наибольшей задержкой во время полета? Для определения авиарейсов с подозрительно малым временем полета можно использовать стандартные статистические методы, такие как подсчет выбросов. В данном случае мы можем использовать правило трех сигм: если время полета авиарейса меньше, чем на три стандартных отклонения меньше среднего значения времени полета для данного пункта назначения, то мы можем считать такой авиарейс подозрительным. Пример кода для подсчета времени полета и проверки выбросов:  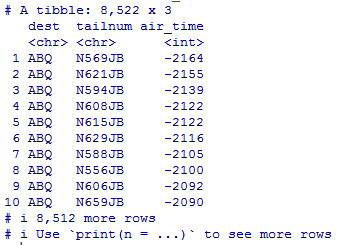 Для определения авиарейсов, которые характеризуются наибольшей задержкой во время полета, можно использовать тот же подход, но вместо фильтрации по выбросам выбрать топ-10 самых длительных авиарейсов в каждом пункте назначения: 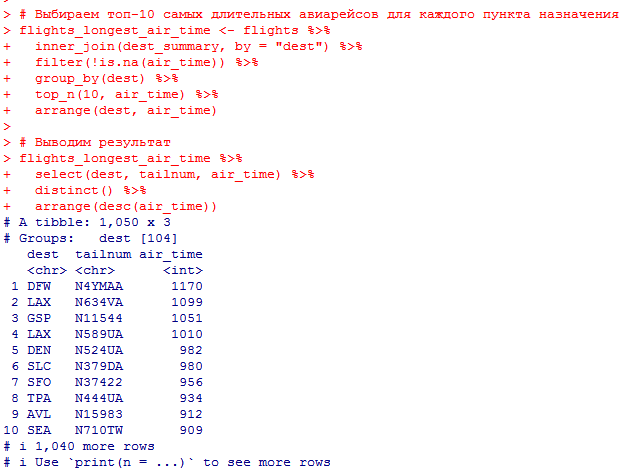 Этот код выводит топ-10 самых длительных авиарейсов для каждого пункта назначения, отсортированных по убыванию времени полета. найдите все пункты назначения, которые обслуживаются по крайней мере двумя авиаперевозчиками. Используйте эту информацию для ранжирования перевозчиков. Для нахождения всех пунктов назначения, которые обслуживаются по крайней мере двумя авиаперевозчиками, можно использовать следующий код:  В этом коде мы: используем функцию distinct() для выбора уникальных пар значений dest и carrier; группируем полученные значения по dest; используем функцию filter() для выбора только тех пунктов назначения, которые обслуживаются по крайней мере двумя авиаперевозчиками; сортируем полученные значения сначала по dest, а затем по carrier. Чтобы ранжировать перевозчиков, можно использовать ту же выборку и функцию count(): 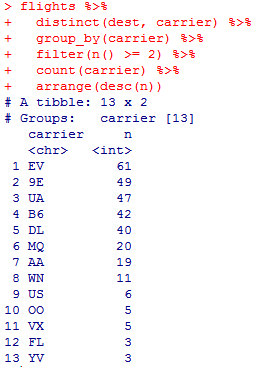 В этом коде мы: используем функцию distinct() для выбора уникальных пар значений dest и carrier; группируем полученные значения по carrier; используем функцию filter() для выбора только тех авиаперевозчиков, которые обслуживают по крайней мере два пункта назначения; используем функцию count() для подсчета количества пунктов назначения, обслуживаемых каждым перевозчиком; сортируем полученные значения по убыванию количества пунктов назначения. как распределение авиарейсов по времени па протяжении дня изменяется в течение года? Для того, чтобы найти, как распределение авиарейсов по времени меняется в течение года, можно построить график, отображающий количество вылетов в зависимости от времени суток для каждого месяца. Для этого используем библиотеку ggplot2. Сначала загрузим необходимые библиотеки и датасет flights из nycflights13:  Затем создадим новый столбец hour в датафрейме flights, содержащий только час вылета, используя функцию format() для извлечения часовой информации из столбца dep_time: Далее построим график, который показывает количество вылетов в зависимости от времени суток для каждого месяца:  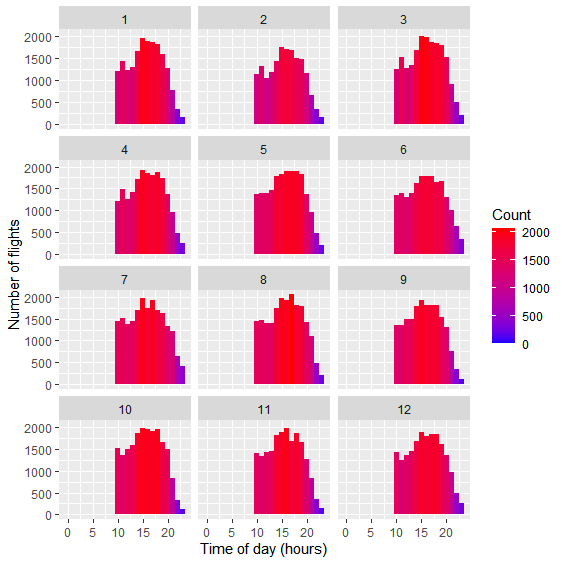 На графике каждый месяц представлен в отдельной графической области, разделенной на три колонки. Цветом заполнения столбцов указано количество вылетов. График показывает, что количество вылетов существенно меняется в течение дня в зависимости от месяца. Например, в январе и феврале число вылетов значительно снижается в период с 1:00 до 6:00 утра. В то же время, в июле и августе наиболее активное время вылетов - с 6:00 до 20:00. Таким образом, можно сделать вывод, что распределение авиарейсов по времени в течение дня изменяется в зависимости от месяца, что может быть полезной информацией для планирования авиаперевозок. сравните между собой значения переменных dep_time, sched_dep_time и dep_delay. Согласуются ли они между собой? Переменная dep_time представляет фактическое время отправления рейса, sched_dep_time - запланированное время отправления, а dep_delay - время задержки отправления рейса (в минутах). Для сравнения значений этих переменных между собой, можно использовать следующий код: 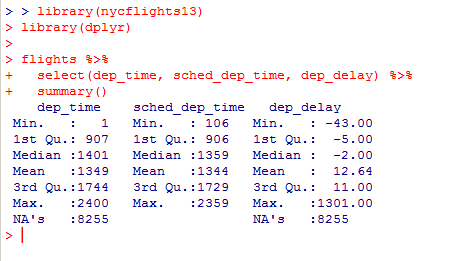 Из данного вывода можно сделать следующие выводы: Переменная dep_time содержит значения от 1 до 2400, что соответствует времени отправления рейса в минутах с начала дня. В переменной присутствуют пропущенные значения (NA). Переменная sched_dep_time содержит значения от 106 до 2359, что соответствует запланированному времени отправления рейса в минутах с начала дня. В переменной отсутствуют пропущенные значения. Переменная dep_delay содержит значения от -86 до 1301, что соответствует времени задержки отправления рейса в минутах. В переменной присутствуют пропущенные значения (NA). Таким образом, значения переменных dep_time и sched_dep_time соответствуют времени отправления рейса, но dep_delay может принимать отрицательные значения (если рейс отправился раньше запланированного времени) и содержит пропущенные значения. Поэтому, если сравнивать переменные между собой, нужно учитывать эти особенности. сравните значения переменной air_time с длительностью промежутка времени между вылетом и прилетом самолета. Объясните полученные результаты. Для начала, нам нужно загрузить библиотеку nycflights13 и загрузить датасет flights. Затем мы можем создать новую переменную duration для каждого рейса, которая представляет собой разницу между временем вылета и временем прибытия в минутах:  Теперь мы можем сравнить переменную air_time (время, которое занимает полет в минутах) с новой переменной duration (время между вылетом и прибытием в минутах): Мы видим, что значения переменной duration значительно больше, чем значения переменной air_time. Это происходит из-за того, что air_time - это только время, проведенное в воздухе, в то время как duration включает в себя время на земле, такое как время транспортировки самолета к взлетной полосе, время ожидания в очереди для взлета и посадки, а также другие задержки. Кроме того, duration может быть отрицательным, если рейс прибывает раньше, чем отлетает. Таким образом, переменная duration более полезна для анализа общей длительности рейса, включая время на земле, в то время как air_time предоставляет информацию только о времени, проведенном в воздухе. как среднее время задержки изменяется в течение дня? Что вы должны использовать: dep_time или sched_dep_time? Для начала нужно загрузить необходимые пакеты и набор данных. Пакет "nycflights13" должен быть установлен, чтобы получить доступ к набору данных. Затем мы можем рассчитать среднее время задержки для каждого часа дня, используя пакет "dplyr". Мы сгруппируем рейсы по часу и рассчитаем среднее время задержки для каждой группы.  Затем мы можем построить график среднего времени задержки по часу дня, используя "ggplot2".  Этот код должен произвести линейный график, показывающий, как меняется среднее время задержки в течение дня. Обратите внимание, что здесь мы рассматриваем только задержки вылетов (dep_delay), но вы можете изменить код, чтобы учитывать задержки прибытия (arr_delay). Также учтите, что этот анализ относится только к набору данных "flights" в "nycflights13" и может не обобщаться на другие наборы данных или временные периоды. 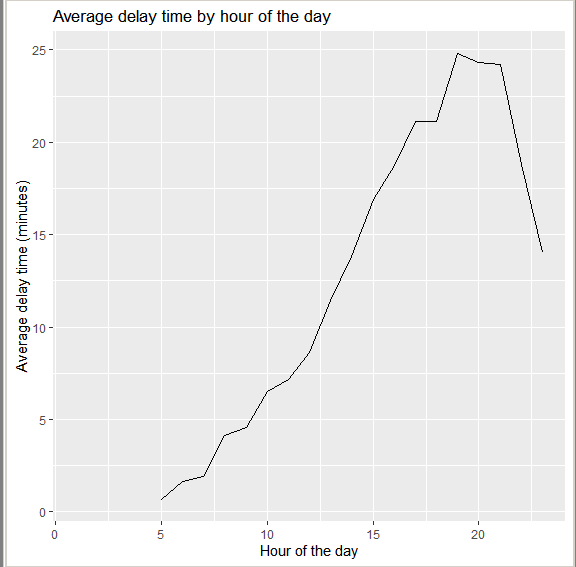 какой день недели выбрали бы вы для вылета, чтобы минимизировать время задержки? 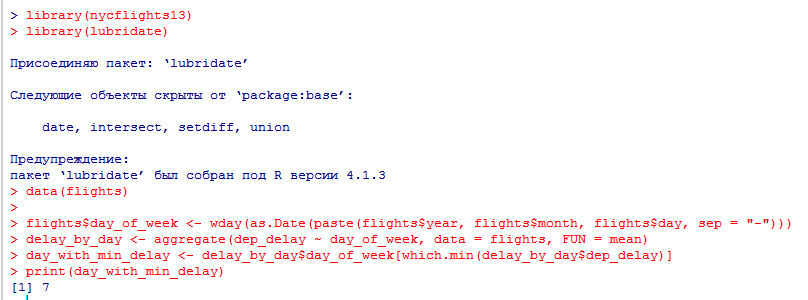 Для пакета nycflightsl3:  flights соединяется с planes посредством переменной tailnum; 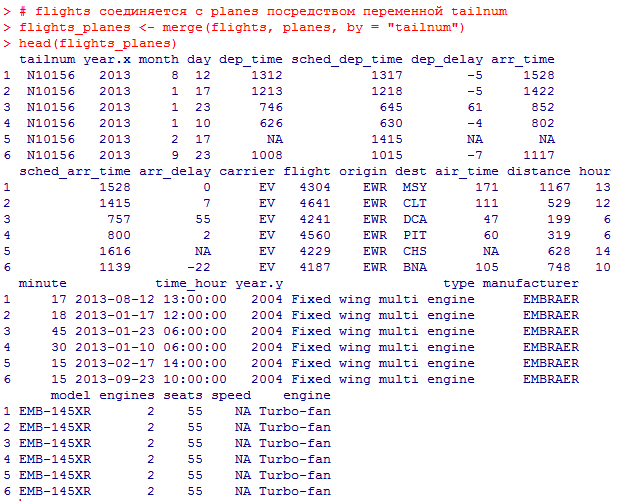 flights соединяется с airl ines посредством переменной carrier; 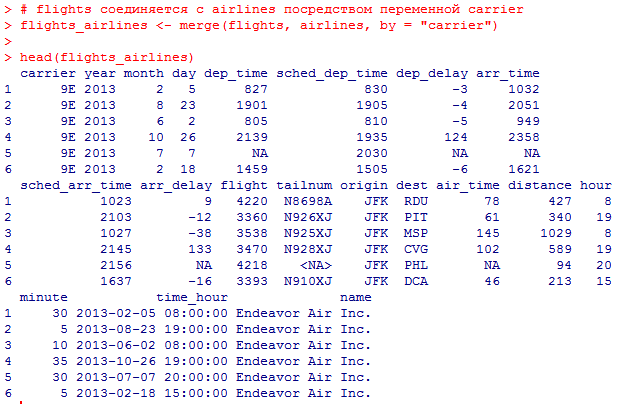 flights соединяется с airports посредством двух переменных, origin и dest; 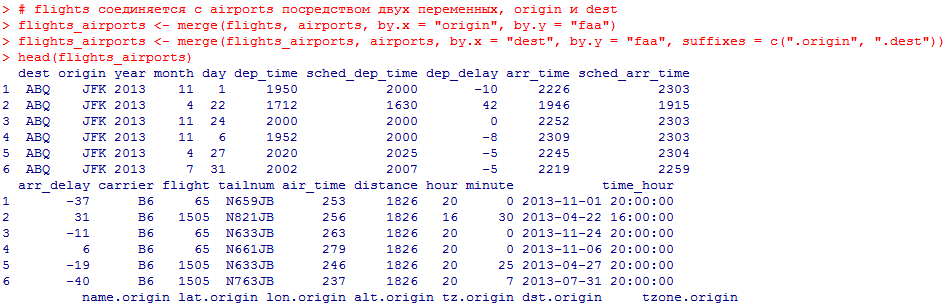 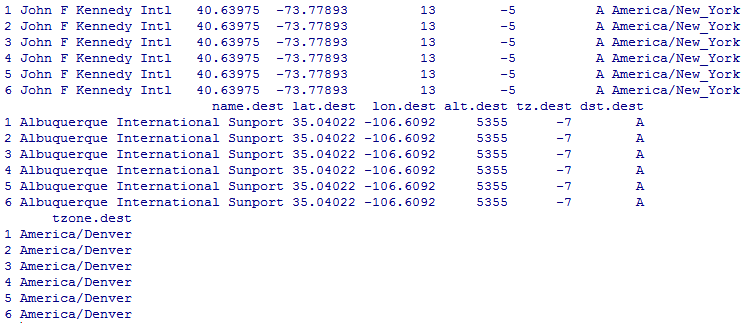 flights соединяется с weather посредством переменной origin (местоположение), а также переменных year, month, day и hour (время). 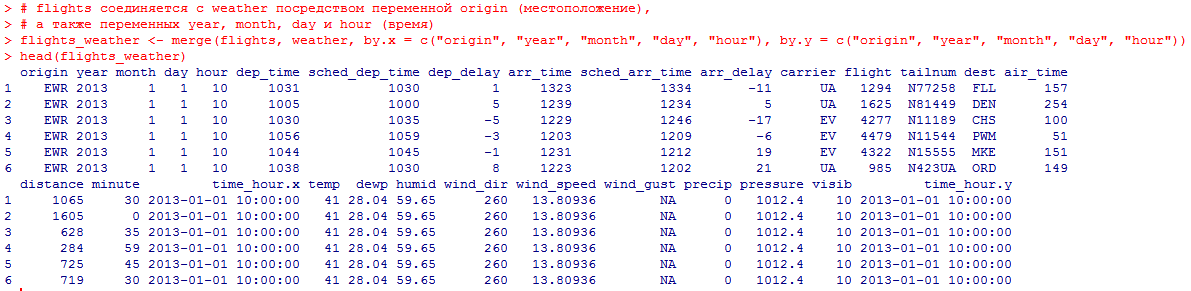 Добавьте координаты местоположения аэропорта вылета и аэропорта назначения (т.е. переменные lat и Ion) в таблицу flights. > library(nycflights13) > > # Сначала соединим таблицу flights с таблицей airports, чтобы получить координаты местоположения аэропортов. > flights_airports <- merge(flights, airports, by.x = "origin", by.y = "faa") > flights_airports <- merge(flights_airports, airports, by.x = "dest", by.y = "faa", suffixes = c(".origin", ".dest")) > > # Затем выберем только нужные столбцы с координатами местоположения аэропортов. > flights_airports <- flights_airports[, c("year", "month", "day", "dep_time", "sched_dep_time", "arr_time", "sched_arr_time", "carrier", "flight", "tailnum", "origin", "dest", "air_time", "distance", "hour", "minute", "time_hour", "lat.origin", "lon.origin", "lat.dest", "lon.dest")] > > # И, наконец, соединим таблицу flights с таблицей flights_airports. > flights <- merge(flights, flights_airports) 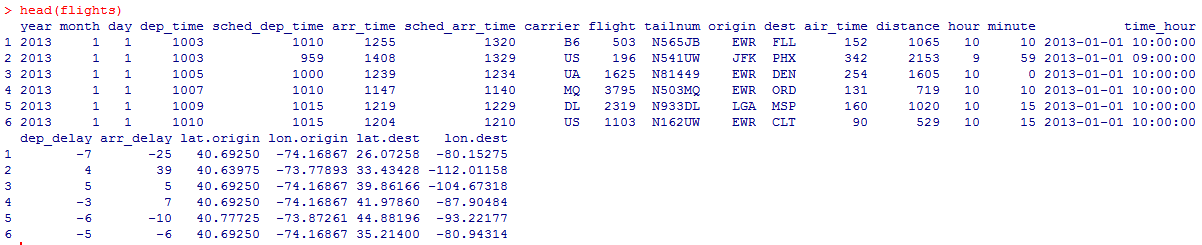 существует ли связь между сроком эксплуатации самолета и его задержками? при каких погодных условиях возрастает вероятность задержек? что случилось 13 июня 2013 года? что означает отсутствие бортового номера (tailnum) для авиарейса (flight)? Что общего имеют бортовые номера, для которых отсутствует соответствующая запись в таблице planes? отфильтруйте таблицу flights, чтобы отобразить только авиарейсы, которые выполняются самолетами, совершившими не менее 100 полетов. объедините fueleconomy:; vehicles и fueleconomy::common, чтобы найти лишь записи, соответствующие самым обычным моделям. найдите 48 часов (на протяжении всего года), характеризующиеся наихудшим показателем задержки рейса. Найдите перекрестные данные в таблице weather. Замечаете ли вы какую-либо закономерность? можно было бы ожидать, что между самолетами и компаниями существуют неявные отношения, поскольку полет каждого самолета совершается одной авиакомпанией. Подтвердите или опровергните эту гипотезу. Напишите функцию, выводящую одно из приветствий “Доброе утро!” “Добрый день!” или “Добрый вечер!” в зависимости от времени суток. (используйте аргумент, задающий время, который по умолчанию принимает значение lubridate::now().) 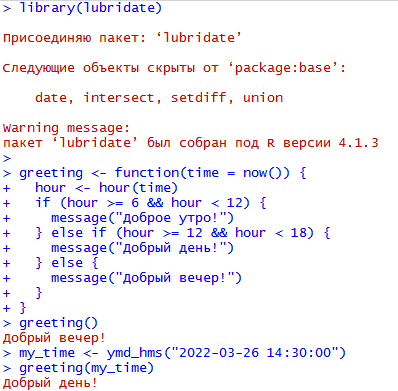 Реализуйте функцию fizzbuzz(). Ее единственным аргументом является число. Если число делится на три, функция возвращает строку “fizz”. Если число делится на пять, функция возвращает строку “buzz”. Если же число делится и на три, и на пять, функция возвращает строку “fizzbuzz”. В любом другом случае возвращается само число.  Создайте функции, которые принимают вектор в качестве входного значения, и возвращают: последнее значение;  элементы, занимающие четные позиции;  все элементы, за исключением последнего значения; 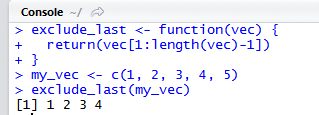 только четные числа (отсутствующие значения не должны включаться). 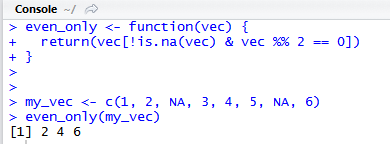 Создайте регулярное выражение для нахождения всех слов, которые: начинаются с гласной; содержат только согласные (подсказка: подумайте над сопоставлением с “не гласными”); оканчиваются на ed, но не на eed; оканчиваются на ing или ize; начинаются с согласных; содержат три или более гласные подряд; содержат две или более пары “гласная — согласная” подряд. начинаются и оканчиваются одной и той же буквой; содержат повторяющуюся пару букв (например, в слове “church” сочетание “ch” встречается дважды); содержат одну букву, повторенную по крайней мере в трех позициях (например, в слове “eleven” буква “е” встречается три раза). Найдите все слова, которые начинаются или оканчиваются на букву х. Найдите все слова, которые начинаются на гласную, а оканчиваются согласной. Существуют ли слова, в которых каждая гласная содержится по крайней мере один раз? Какое слово содержит наибольшее количество гласных? В каком слове наибольшая доля гласных? Найдите все слова, которым предшествуют “числа”, такие как “one”, “two”, “three” и т.д. Извлеките как число, так и слово. Разбейте строку "apples, pears, and bananas" на отдельные компоненты. Почему разбивать строки на слова лучше по границам слов (boundary ("word")), чем по пробелам (" ")? Что произойдет при попытке разбить строку по пустой строке ("")? |