отчет. Н. Ф. Гусарова, Н. В
 Скачать 2.27 Mb. Скачать 2.27 Mb.
|

Механизмы применяющиеся, для обеспечения гарантированного качества обработки и интерпретации:Задача FEATURES SELECTION может быть обобщена путем определения преобразования Z = F(X), позволяющего из X формировать но- вое пространство признаков Z, |Z| < |X|. В такой постановке задача называ- ется задачей FEATURES EXTRACTION (извлечение или конструирование признаков). При решении FEATURES EXTRACTION формируются новые признаки на основе уже имеющихся в X. Самое простое преобразование Z=F(X) – это линейное преобразование. Основными способами решения задачи FEATURES EXTRACTION являются методы факторного анализа и метод экстремальной группировки признаков. Факторный анализ позволяет выделить обобщенные признаки (факторы), каждый из которых представляет сразу несколько исходных при- знаков. Метод накопленных частот Суть МНЧ заключается в следующем. Пусть имеются два набора значений признака х X, принадлежащие двум матрицам «объект – признак» обучающих выборок A1 и A2. Далее не будем делать различия между выборками и соответствующими им матрицами «объект – признак». По двум наборам значений признака x строятся эмпирические распределения и подсчитываются накопленные частоты как суммы частот от начального до текущего интервала распределения. Мерой информативности признака х служит модуль максимальной разности накоп- ленных частот. Метод Шеннона В методе Шеннона в качестве меры информатив- ности признака x рассматривается средневзвешенное количество информа- ции, которое свойственно анализируемому признаку. Метод Кульбака В данном методе в качестве меры информативно- сти признака х рассматривается величина, называемая дивергенцией Куль- бака и отражающая расхождение между выборками A1 и A2. Вторая (практическая) частьВ качестве научной статьи в данной практической работе использо- ван источник: https://academic.oup.com/bioinformatics/article/30/1/104/236067. Краткое описание данной статьи: при использовании современных поисковиков выдача по определенному поисковому запросу составляет ты- сячи, а то и миллионы страниц. Авторы же реализовали систему, способную при определенном медицинском запросе выдавать меньший по количеству, но более качественный набор веб-страниц. Система включает в себя модель, оценивающую релевантность страницы к заданному пользователем запросу и краулер, собирающий страницы для оценки. Таким образом, согласованная с преподавателем конечная работа: реализовать модель оценки веб-страницы. Модель Φ(𝑤𝑤𝑤𝑤, Ω), получающая на вход wp – веб-страницу, Ω – тему, и выдающая в ответ значение принадлежности страницы к теме в диапазоне от 0 до 1. Выбранная тема – рак печени. Ход выполнения: 1 этап: сбор веб-страниц форумов Сперва были собраны исходные данные в виде 20 веб-страниц, явля- ющиеся форумами. Они были найдены по простым поисковым запросам в Яндекс и Google, по типу «рак печени форум», «обсуждение рака печени» и т.д. Список страниц с личными оценками: [ ('https://www.oncoforum.ru/forum/showthread.php?t=107634', 2), ('http://www.rakpobedim.ru/forum/index.php?/topic/1592-рак-печени/', 8), ('http://www.woman.ru/kids/healthy/thread/4714336/', 7), ('https://khabmama.ru/forum/viewtopic.php?t=135141', 1), ('https://www.e1.ru/talk/forum/read.php?f=36&t=483540', 3), ('https://forum.guns.ru/forummessage/80/2111885.html', 6), ('https://samaraonko.ru/forums/viewtopic.php?id=16880', 5), ('https://forum.ngs.ru/board/health/flat/1873376851/?fpart=1&per-page=50', 7), ('https://forums.rusmedserv.com/showthread.php?t=200647', 6), ('http://golodanie.su/forum/showthread.php?t=11761', 6), ('https://forums.playground.ru/talk/rak_pecheni_x-128505/', 3), 'https://www.nn.ru/community/biz/medicine/proshu_pomoshchi_i_sovetov_u_p apy_rak_metastazy.html', 5), ('http://www.onconet.ru/showthread.php?p=9318', 3), ('http://crimea-med.net/index.php?/topic/3759-rak-pecheni/', 4), ('https://eva.ru/kids/messages-3240292.htm', 5), ('http://forumjizni.ru/archive/index.php/t-9567.html', 5), ('https://www.u-mama.ru/forum/family/health/788648/', 5), ('http://rak.flyboard.ru/topic2210.html', 2), ('https://forum.ykt.ru/viewmsg.jsp?id=24732435', 7), ] Каждая страница была субъективна оценена в работе по шкале от 0 до 10. В дальнейшем это значение делилось на 10. Оценивалась степень ин- формативности ответов людей на тему, полнота ответа. На втором этапе был произведен сбор информации с веб-страницы. Разработка велась на языке программирования Python. Как предлагалось в статье, с веб-страницы необходимо собрать три набора данных: T1 – основной текст страницы. T2 – название заголовков в html-тэгах h1, h2, h3, h4, h5, h6. T3 – название тэгов, содержащих в себе ссылку на другие страницы. Каждый набор был собран при помощи библиотеки BeautifulSoup4.  Третий этап включал в себя выделение ключевых слов. Авторами предлагается метод RAKE для выделения из текста ключевых слов и фраз. Для этого использовалась библиотека multi-rake позволяющая работать с множеством языков, в том числе и русским. При дальнейшем отборе клю- чевых слов авторы предлагают убрать все слова, получившие оценку RAKE ниже определенной. Посмотрев вручную, ниже оценки 1.1 собирается много различных слов, большая часть из которых бесполезны для темы медицины.  Здесь показано, что при значении ниже 1.1 (список дальше идет еще на 100 слов) меньше подходящих слов, чем выше это значение.  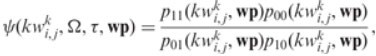 Следующим этапом отбора слов авторы предлагают каждому ключе- вому слову выдать значение по следующей формуле. Следующим этапом отбора слов авторы предлагают каждому ключе- вому слову выдать значение по следующей формуле.Числа p имеют два индекса принимающие значения 1 или 0. Число p является количеством страниц включающих (или не включающих) в себя конкретное ключевое слово среди страниц имеющих оценку больше (или меньше) знания т (тау). Опишем алгоритм: Берется отдельно каждое ключевое слово в каждой веб-странице и проверяется его нахождение в каждой другой имеющейся странице. Если же первый индекс равен 1, то проверяется наличие ключевого слова в наборе страницы, при 0 проверяется его отсутствие. Второй индекс при 1 включает только те страницы, чья оценка выше тау. При 0 ниже тау.  На четвертом этапе проводится обучение модели. Модель в статье основана на полиноминальной регрессии. Для определения подходящей степени полинома отыщем значения квадрата ошибки при построении по- линомов различной степени. На рис. 5.1. видно, что при переходе от поли- нома 14 степени к полиному 15 степени происходит огромный скачок по- рядков. Поэтому выберем 14 степень полинома. Модель обучена. 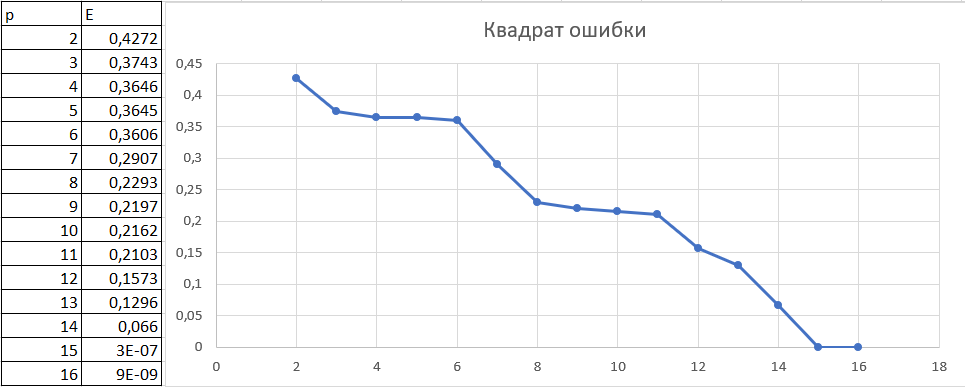 Рис. 5.1. График полиноминальной регрессии На пятом этапе проводилась проверка контрольной выборки. Полная выборка из 20 веб-страниц была разделена на обучающую и контрольную. Обучающая выборка составляла 80% процентов всей выборки. Экспери- мент проводился несколько раз, каждый раз изменяя набор каждой выборки, не повторяющий предыдущий. Новые выборки определяются так: сдвига- ются на 1 пункт списка. Каждый раз записывался результат оценки качества проверки. Срав- нивались известное значение оценки страницы с тем, что выдала модель. Процент точности высчитывался следующим образом: (модуль расстояния между оценками)/(максимальное расстояние до истинного значения оценки). Для каждого эксперимента выводился средний процент ошибки. Таблица 5.1. Процент ошибки Как видно из таблицы, ошибка может достигать 12%, но может и пре- вышать 50%. Чаще всего она варьируется около 25-30%. Таким образом, получили обучающуюся модель, которая по опреде- ленному запросу и начальной ранжированной выборке, дает оценку другим страницам по данной теме. Недостатки данного эксперимента: Малая выборка данных. Для хороших экспериментов необходима выборка в 50 веб-страниц, а то и 100 и более. Субъективная оценка страниц «эксперта», не имеющего достаточ- ных знаний в отрасли. Для повышения качества, необходимы квалифициро- ванные «эксперты», и не один, а несколько. Учитывать оценку каждого. А также увеличить диапазон оценки «от 0 до 100». |