Глава 8 Неоднородные вычисления. Неоднородные вычисления Содержание Глава Неоднородные вычисления Основы неоднородных вычислений
 Скачать 0.62 Mb. Скачать 0.62 Mb.
|

|
Глава 8. Неоднородные вычисления Содержание Глава 8. Неоднородные вычисления Основы неоднородных вычислений Основы архитектуры GPU Основы программирования GPU CUDA OpenCL Работа с PyCUDA Приготовление Как это сделать... Как это работает... Также ознакомьтесь... Дополнительно Гетерогенное программирование с применением PyCUDA Как это сделать... Как это работает... Также ознакомьтесь... Дополнительно Реализация управления памятью с применением PyCUDA Приготовление Как это сделать... Как это работает... Также ознакомьтесь... Дополнительно Введение в PyOpenCL Приготовление Как это сделать... Как это работает... Также ознакомьтесь... Дополнительно Построение приложений при помощи PyOpenCL Как это сделать... Как это работает... Также ознакомьтесь... Дополнительно Поэлементные выражения с применением PyOpenCL Приготовление Как это сделать... Как это работает... Также ознакомьтесь... Дополнительно Оценка приложений PyOpenCL Приготовление Как это сделать... Как это работает... Также ознакомьтесь... За OpenCL и PyOpenCL Против OpenCL и PyOpenCL За CUDA и PyCUDA Против CUDA и PyCUDA Дополнительно Программирование GPU с применением Numba Приготовление Как это сделать... Как это работает... Также ознакомьтесь... Дополнительно Данная глава поможет нам изучить технологии программирование GPU (Graphics Processing Unit) с применением языка Python. Продолжающееся развитие GPU выявляет насколько великие возможности эти архитектуры способны привносить в осуществление сложных вычислений. Несомненно, GPU никогда не заменят ЦПУ. Однако они являют собой хорошо структурированный и неоднородный код, который способен эксплуатировать сильные стороны обоих видов процессоров, что может давать существенные преимущества. Мы изучим основные среды разработки для неоднородного (гетерогенного) программирования, а именно, среды PyCUDA и Numba для CUDA (Compute Unified Device Architecture), а также PyOpenCL, который предназначен для инфраструктуры OpenCL (Open Computing Language) в своей версии Python. {Прим. пер.: во второй половине ноября 2019 года мы намерены выложить в Дополнении к этому переводу описание интерфейса Python для нового процессора Fujitsu (DLU), выпускаемого ими в сотрудничестве с Intel 5 ноября 2019.} В этой главе мы охватим такие рецепты: Основы неоднородных вычислений Понимание архитектуры GPU Основы программирования GPU Работа с PyCUDA Неоднородное программирование в PyCUDA Реализация управления памятью при помощи PyCUDA Введение в PyOpenCL Построение приложения с применением PyOpenCL Поэлементные выражения PyOpenCL Вычисление приложений PyOpenCL GPU программирование с применением Numba Давайте начнём с более подробного понгимания неоднородных вычислений. Основы неоднородных вычислений На протяжении многих лет поиск наилучшей производительности для всё более сложных вычислений привёл к принятию новых методов применения компьютеров. Один из таких способов имеет название неоднородных вычислений (гетерогенных вычислений), который имеет целью взаимодействие с различными (или гетерогенными) процессорами таким образом, чтобы получать преимущества (в частности) в отношении промежуточной вычислительной мощности. В этом контексте, тот процессор, в котором запущена основная программа (как правило, ЦПУ) именуется хостом, в то время как имеющиеся сопроцессоры (например, GPU) имеют название устройств. Эти последние обычно физически обособлены в своём хосте и управляют своим собственным пространством памяти, которое также обособлено от памяти хоста. В частности, следуя за значительным спросом на рынке, такие GPU превратились в процессор с высокой параллельностью, преобразовав графический процессор из устройства построения графики в устройства для параллельных и интенсивных вычислений общего назначения. В действительности применение GPU для задач, отличных от построения графического изображения на экране и имеет название неоднородных вычислений. Наконец, задача достойного программирования GPU состоит в том, чтобы максимально применять высокий уровень параллелизма и математических возможностей, предлагаемых такими графическими картами, сводя к минимуму все предоставляемые ею недостатки, например, задержку физического соединения между самим хостом и устройством. Основы архитектуры GPU Некий GPU является специализированным процессором/ ядром для векторной обработки графических данных при построении изображения из примитивов многоугольников. Основная задача хорошнй программы GPU состоит в максимальном применении предлагаемого графическими картами высочайшего уровня параллелизма и математических возможностей при минимизации всех имеющихся у неё недостатков, таких как задержка в физическом соединении между основным хостом и его устройством. GPU отличается высокой степенью параллельности строения, что делает возможным эффективную работу с большими наборами данных. Эти свойства сочетаются с быстрыми улучшениями в аппаратной производительности программ, привнося особое внимание всего научного мира к возможности применения GPU для целей, отличающихся от построения изображений. Некий GPU (см. следующую схему) состоит из определённого числа вычислительных устройств, носящих название Потоковых мультипроцессоров (SM, Streaming Multiprocessors), которые являют собой самый первый уровень параллелизма. На практике каждый SM работает одновременно и независимо от прочих. Рисунок 8-1 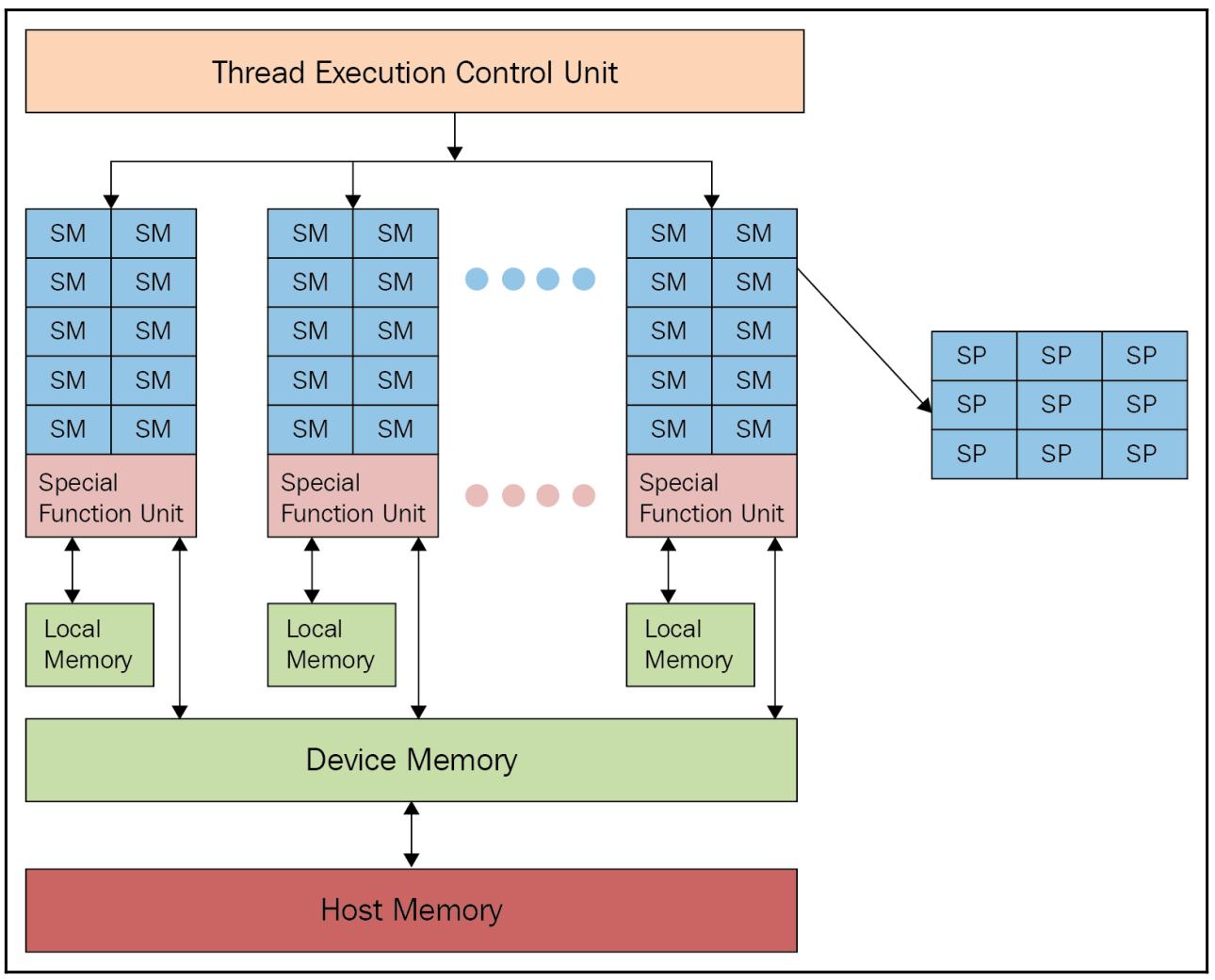 Архитектура GPU Каждый SM делится на некую группу Потоковых процессоров (SP, Streaming Processors), обладающих неким ядром, способным последовательно выполнять некий поток. Такой SP представляет наименьший элемент логики выполнения и самый тонкий уровень параллельности. Для наилучшего программирования такого типа архитектуры нам требуется представить программирование GPU, которое мы и описываем в следующем разделе. Основы программирования GPU Графические процессоры непрерывно улучшают свои программные возможности. На практике их набор инструкций был расширен для предоставления возможности выполнения большего числа задач. В наши дни GPU способен выполнять классические инструкции ЦПУ, такие как циклы и условия , доступ к памяти и вычисления с плавающей точкой. Два основных производителя дискретных видео карт - NVIDIA и AMD - разработали собственные архитектуры GPU, снабжая разработчиков соответствующими средами разработки, которые позволяют программировать на различных языках программирования, включая Python. {Прим. пер.: во второй половине ноября 2019 года мы намерены выложить в Дополнении к этому переводу описание интерфейса Python для нового процессора Fujitsu (DLU), выпускаемого ими в сотрудничестве с Intel 5 ноября 2019.} В настоящее время разработчики обладают ценными инструментами для написания программного обеспечения, которое применяет GPU в не связанном с графикой контексте. Среди основных сред разработки для неоднородных вычислений у нас имеются CUDA и OpenCL. Давайте рассмотрим их подробнее. CUDA CUDA является частной аппаратной архитектурой nVIDIA, которая также снабдила своим названием и связанную с ней среду разработки. В наши дни CUDA обладает пулом из сотен тысяч активных разработчиков, которые демонстрируют растущий интерес со стороны разработчиков к данной технологии в среде параллельного программирования. CUDA предлагает расширения для наиболее применяемых языков применяемых в программировании, в том числе и Python. Наиболее хорошо известными расширениями CUDA Python являются: PyCUDA Numba В последующих разделах мы рассмотрим их подробнее. OpenCL Вторым главным действующим лицом в параллельных вычислениях выступает OpenCL, который (в отличие от своего аналога nVIDIA) является открытым стандартом и может применяться не только с графическими процессорами разных производителей, но и с микропроцессорами разных типов. Тем не менее, OpenCL является более полным и универсальным решением, пока не обладающим такой зрелости и простоты применения как CUDA. Расширением OpenCL в Python выступает PyOpenCL. В наших последующих разделах будут проанализированы модели программирования CUDA и OpenCL в их расширениях Python и они будут сопровождены некоторыми занятными примерами использования. Работа с PyCUDA PyCUDA это библиотека привязок, обеспечивающая доступ к API Python CUDA от Андреаса Клёкнера. Основные функции содержат автоматическую очистку, которая привязана к времени жизни объектов, что предотвращает утечки памяти, удобную абстракцию поверх модулей и буферов, полный доступ к драйверу и встроенную обработку ошибок. Данный продукт является открытым исходным кодом с лицензией MIT, его документация очень ясная, к тому же множество находящихся в открытом доступе исходных кодов могут оказать содействие и поддержку. Основная цель PyCUDA состоит в том, чтобы позволить разработчику вызывать CUDA с минимумом абстракций Python и также поддерживать метапрограммирование и шаблоны CUDA. Приготовление Для установки PyCUDA, будьте любезны следовать инструкциям домашней страницы Андреаса Клёкнера. Наш следующий пример программирования имеет двойную функцию: Прежде всего убедиться что PyCUDA установлен как подобает. Во- вторых, считать и вывести на печать характеристики имеющихся карт GPU. Как это сделать... Давайте рассмотрим следующие шаги: Самой первой инструкцией мы импортируем имеющийся драйвер Python (то есть, pycuda.driver) в установленной на вашем ПК библиотеке CUDA: import pycuda.driver as drv Инициализируем CUDA. Обратите внимание, что следующую инструкцию следует вызывать прежде всех прочих инструкций из модуля pycuda.driver: drv.init() Пересчитываем общее число карт GPU в вашем ПК: print ("%d device(s) found." % drv.Device.count()) Для каждой из установленных GPU карт выводим на печать название их модели, вычислительные возможности, а также общий объём памяти данного устройства в килоБайтах: for ordinal i n range(drv.Device.count()): dev = drv.Device(ordinal) print ("Device #%d: %s" % (ordinal, dev.name()) print ("Compute Capability: %d.%d"% dev.compute_capability()) print ("Total Memory: %s KB" % (dev.total_memory()//(1024))) Как это работает... Всё исполнение достаточно незатейливое. В самой первой строке кода импортируется pycuda.driver, а затем и инициализируется: import pycuda.driver as drv drv.init() Этот модуль pycuda.driver выставляет уровень драйвера для интерфейса программирования CUDA, что более удобно нежели интерфейс программирования времени исполнения C CUDA, к тому же он обладает рядом функциональных возможностей, которые не представлены в интерфейсе времени выполнения. Затем он обходит в цикле значение функции drv.Device.count(), причём для каждой карты GPU выводятся на печать название этой карты и её основные характеристики (вычислительные возможности и общий объём памяти): print ("Device #%d: %s" % (ordinal, dev.name())) print ("Compute Capability: %d.%d" % dev.compute_capability()) print ("Total Memory: %s KB" % (dev.total_memory()//(1024))) Выполняем следующий код: C:\> python dealingWithPycuda.py После его выполнения на экране будут отображены все установленные GPU, примерно как в следующем образце: 1 device(s) found. Device #0: GeForce GT 240 Compute Capability: 1.2 Total Memory: 1048576 KB Также ознакомьтесь... Модель программирования CUDA (а следовательно и PyCUDA, которая является обёрткой Python) реализуется через особые расширения стандартной библиотеки, написанной на языке программирования С. Эти расширения были созданы просто как вызовы функции из стандартной библиотеки C, делая возможным простой подход к модели неоднородного программирования, которая содержит код и для своего хоста, и для устройства. Собственно управление такими двумя логическими частями выполняется компилятором nvcc. Вот краткое описание того как это работает: Выделяем код устройства из кода хоста. Вызываем некий компилятор по умолчанию (к примеру, GCC), для компиляции кода хоста. Строим необходимый код устройства в двоичном виде (объекты .cubin) или в ассемблерном виде (объекты PTX): Рисунок 8-2 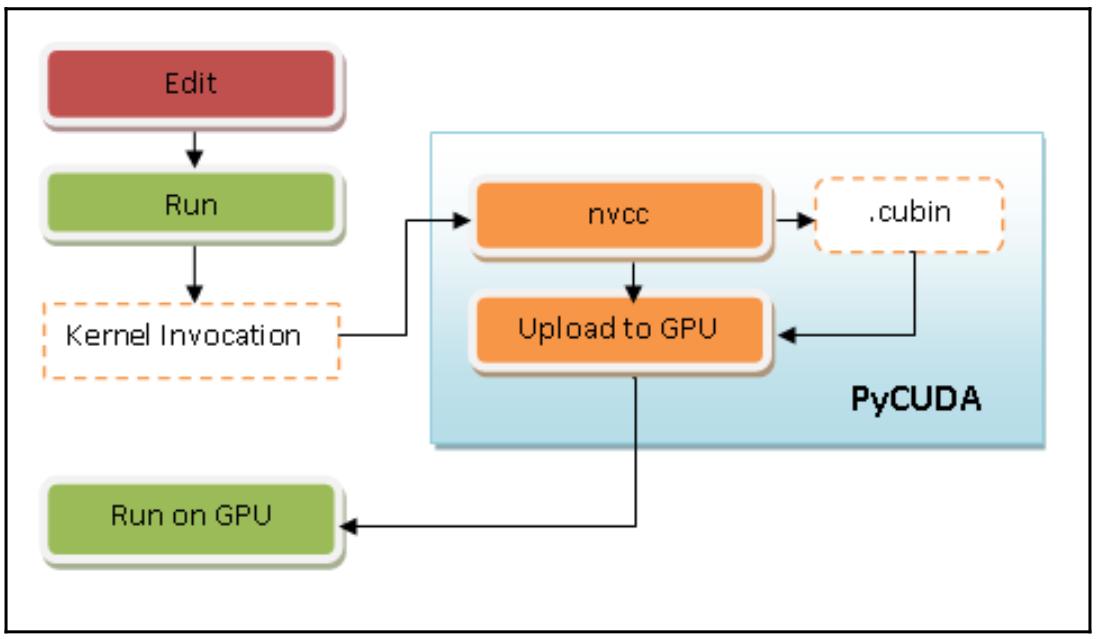 Модель работы PyCUDA Все предыдущие шаги выполняются со стороны PyCUDA в процессе выполнения с неким ростом в нагрузке времени исполнения по сравнению с приложением CUDA. Дополнительно Руководство по программированию CUDA доступно тут Документация PyCUDA доступна здесь Гетерогенное программирование с применением PyCUDA Модель программирования CUDA (а следовательно и PyCUDA) разработана для того чтобы соединить программное приложение ЦПУ и GPU для выполнения имеющейся последовательной части в установленном ЦПУ, а той части, которая может выполняться параллельно, в присутствующем GPU. К сожалению, наш компьютер не достаточно сообразителен чтобы разбираться в том как автономно распределять полученный код, а потому именно разработчик сверху должен указывать какие части следует выполнять в ЦПУ, а какие в GPU. На практике приложение CUDA составляется из неких последовательных компонентов, которые выполняются ЦПУ системы или хоста, либо параллельных компонентов, носящих названия ядер (kernels), которые исполняются вместо этого GPU или устройством. Некое ядро определяется как решётка (сетка, grid) и в свою очередь может подвергаться декомпозиции на блоки, которые последовательно назначаются различным мультипроцессорам, тем самым реализуя параллелизм крупной грануляции (coarse-grained parallelism). Внутри этих блоков присутствуют основополагающие вычислительные элементы, потоки, с очень тонкой степенью параллельной грануляции (fine parallel granularity). некий поток может относиться только к одному блоку и идентифицироваться неким уникальным индексом для блоков и трёхмерными индексами для потоков. В них имеющиеся ядра выполняются последовательно. Блоки же и потоки, в свою очередь, выполняются параллельно. Общее число запущенных (параллельно) потоков зависит от их организации в блоки, а также от их запросов в плане ресурсов в соответствии с теми ресурсами, которые доступны в данном устройстве.
|
