Глава 8 Неоднородные вычисления. Неоднородные вычисления Содержание Глава Неоднородные вычисления Основы неоднородных вычислений
 Скачать 0.62 Mb. Скачать 0.62 Mb.
|

|
Как это работает... Давайте рассмотрим рабочий поток программирования PyCUDA. Подготовим необходимые входные матрицы, матрицы вывода и где мы будем хранить полученные результаты: MATRIX_SIZE = 5 a_cpu = np.random.randn(MATRIX_SIZE, MATRIX_SIZE).astype(np.float32) b_cpu = np.random.randn(MATRIX_SIZE, MATRIX_SIZE).astype(np.float32) c_cpu = np.dot(a_cpu, b_cpu) Затем мы перешлём эти матрицы в вычислительное устройство GPU воспользовавшись функцией PyCUDA gpuarray.to_gpu(): a_gpu = gpuarray.to_gpu(a_cpu) b_gpu = gpuarray.to_gpu(b_cpu) c_gpu = gpuarray.empty((MATRIX_SIZE, MATRIX_SIZE), np.float32) Основной сердцевиной данного алгоритма является приводимая далее функция ядра. Давайте обратим внимание на имеющееся ключевое слово __global__, определяющее что данная функция является функцией ядра, что означает что она будет исполняться вычислительным устройством (GPU), вслед за вызовом из соответствующего кода хоста (ЦПУ): __global__ void MatrixMulKernel(float *a, float *b, float *c){ int tx = threadIdx.x; int ty = threadIdx.y; float Pvalue = 0; for (int k = 0; k < %(MATRIX_SIZE)s; ++k) { float Aelement = a[ty * %(MATRIX_SIZE)s + k]; float Belement = b[k * %(MATRIX_SIZE)s + tx]; Pvalue += Aelement * Belement;} c[ty * %(MATRIX_SIZE)s + tx] = Pvalue; } threadIdx.x и threadIdy.y это координаты, которые позволяют указывать конкретные потоки в имеющейся решётке двухмерных блоков. Обратите внимание, что такие потоки внутри установленной решётки блоков выполняют один и тот же код ядра, но с разными частями данных. Если мы сравним свою параллельную версию с последовательной, тогда мы немедленно заметим, что наши индексы циклов i и j были заменены на соответствующие индексыthreadIdx.x и threadIdy.y. Это означает, что в нашей параллельной версии у нас будет иметься лишь одна итерация данного цикла. На практике наше ядро MatrixMulKernel будет выполнено некой решёткой с размерностью потоков 5 х 5. Это условие отображается на следующей схеме: Рисунок 8-5 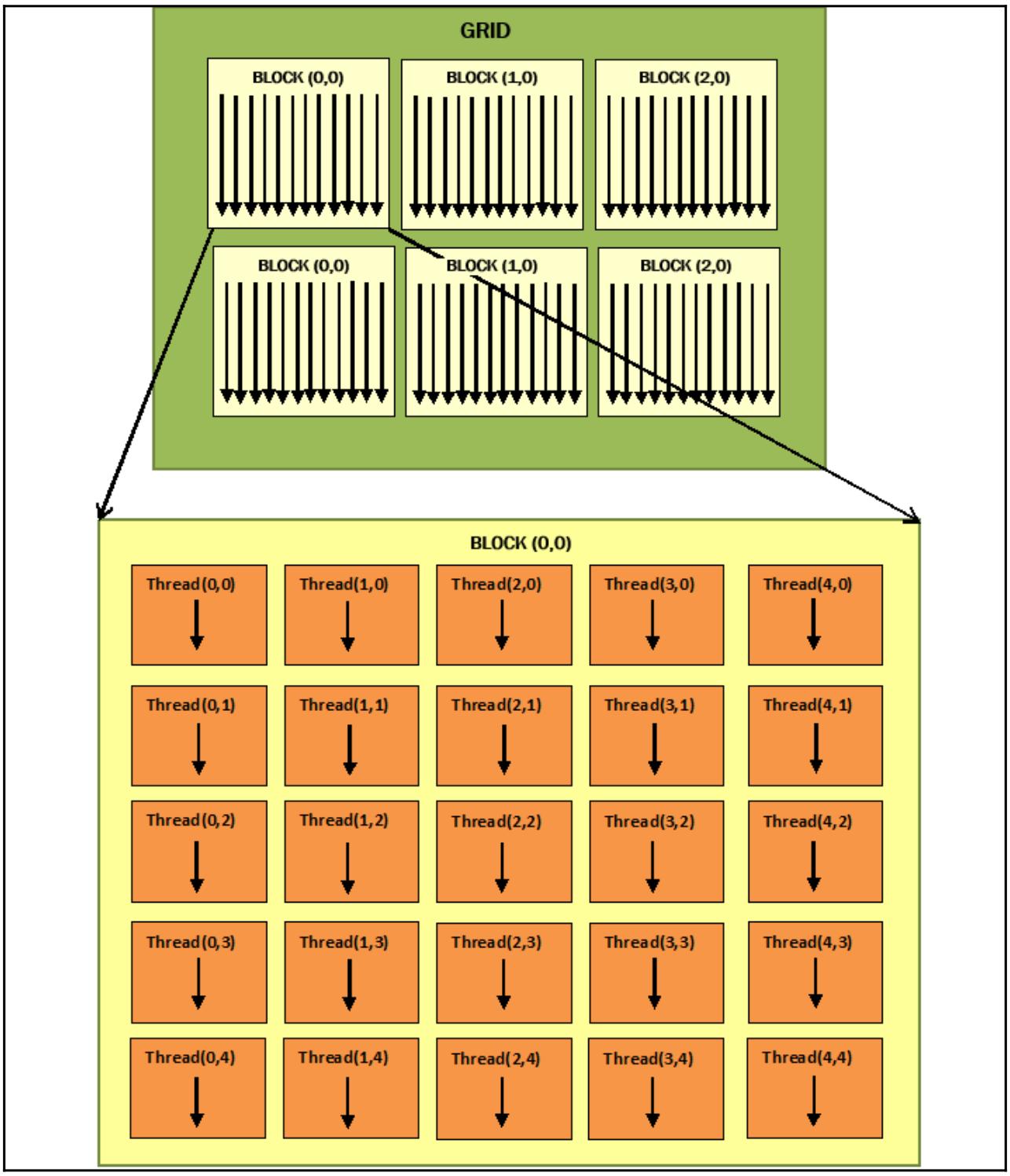 Оптимизация решётки и блока потоков для данного примера Затем мы проверяем полученное произведение просто сравнивая две полученные в результате матрицы: np.allclose(c_cpu, c_gpu.get()) Получаемый вывод следующий: C:\> python memManagementPycuda.py --------------------------------------------------------------------- Matrix A (GPU): [[ 0.90780383 -0.4782407 0.23222363 -0.63184392 1.05509627] [-1.27266967 -1.02834761 -0.15528528 -0.09468858 1.037099 ] [-0.18135822 -0.69884419 0.29881889 -1.15969539 1.21021318] [ 0.20939326 -0.27155793 -0.57454145 0.1466181 1.84723163] [ 1.33780348 -0.42343542 -0.50257754 -0.73388749 -1.883829 ]] --------------------------------------------------------------------- Matrix B (GPU): [[ 0.04523897 0.99969769 -1.04473436 1.28909719 1.10332143] [-0.08900332 -1.3893919 0.06948703 -0.25977209 -0.49602833] [-0.6463753 -1.4424541 -0.81715286 0.67685211 -0.94934392] [ 0.4485206 -0.77086055 -0.16582981 0.08478995 1.26223004] [-0.79841441 -0.16199949 -0.35969591 -0.46809086 0.20455229]] --------------------------------------------------------------------- Matrix C (GPU): [[-1.19226956 1.55315971 -1.44614291 0.90420711 0.43665022] [-0.73617989 0.28546685 1.02769876 -1.97204924 -0.65403283] [-1.62555301 1.05654192 -0.34626681 -0.51481217 -1.35338223] [-1.0040834 1.00310731 -0.4568972 -0.90064859 1.47408712] [ 1.59797418 3.52156591 -0.21708387 2.31396151 0.85150564]] --------------------------------------------------------------------- TRUE Также ознакомьтесь... Размещённые в совместной памяти данные обладают ограниченной видимостью в однопоточном блоке. Легко обнаружить что представленная модель программирования PyCUDA адаптируется к конкретным классам приложений. В частности, те свойства, которые должны представлять эти приложения связаны с наличием множества математических операций, причём с высокой степенью параллелизма (то есть одна и та же последовательность операций повторяется на больших объёмах данных). Те области приложений, которые овладевают этими характеристиками относятся к следующим наукам: криптография, вычислительная химия, а также анализ изображений и сигналов. Дополнительно Дополнительные примеры использования PyCUDA можно обнаружить по следующей ссылке. Введение в PyOpenCL PyOpenCL является братским проектом по отношению к PyCUDA. Это библиотека привязок, которая предоставляет полный доступ к API OpenCL из Python, причём также от Андреаса Клёкнера. Он оснащён множеством тех же самых понятий что и PyCUDA, включая очистку от вышедших из сферы объектов, частичног абстрагирование от структур данных, а также обработку ошибок, причём всё это с минимумом накладных расходов. Этот проект доступен по лицензии MIT; его документация очень хороша и в открытом доступе можно найти обилие руководств и учебных пособий. Основное средоточие PyOpenCL состоит в предоставлении некого обладающего лёгким весом соединения между Python и OpenCL, но он также содержит поддержку шаблонов и метапрограмм. Основной поток программы PyOpenCL почти в точности та же самая, что и у программ C и C++ для OpenCL. Сама программа хоста подготавливаем необходимые вызовы программ вычислительного устройства, запускает их, а затем дожидается полученных результатов. Приготовление Основной ссылкой для установки PyOpenCL является домашняя страница Андреаса Клёкнера. Если вы применяете Anaconda, то она предлагает такие шаги: Установите самый последний дистрибутив Anaconds c Python 3.7 со следующей ссылки. Для данного раздела была установлена через установщик Windows Anaconda 2019.07. Со ссылки получите предварительно построенный двоичный файл PyOpenCL от Кристофера Гёльке. Выбеоите правильное сочетание версий ОС и CPython. В нашем случае применяется pyopencl-2019.1+cl12-cp37-cp37m-win_amd64.whl. Для установки указанного выше пакета воспользуйтесь pip Просто в приглашении своей Anaconda наберите: (base) C:\> pip install здесь Более того, приводимая ниже нотация указывает на тот факт, что мы работаем из приглашения Anaconda: (base) C:\> здесь Как это сделать... В своём следующем примере мы воспользуемся некой функцией PyOpenCL, которая позволит нам перенумеровать все свойства того GPU, с которым она будет работать. Необходимый для этого код очень прост и логичен: Самым первым шагом мы импортируем необходимую нам библиотеку pyopencl: import pyopencl as cl Мы строим функцию, вывод которой предоставит нам все характеристики применяемого нами GPU: def print_device_info() : print('\n' + '=' * 60 + '\nOpenCL Platforms and Devices') for platform in cl.get_platforms(): print('=' * 60) print('Platform - Name: ' + platform.name) print('Platform - Vendor: ' + platform.vendor) print('Platform - Version: ' + platform.version) print('Platform - Profile: ' + platform.profile) for device in platform.get_devices(): print(' ' + '-' * 56) print(' Device - Name: ' \ + device.name) print(' Device - Type: ' \ + cl.device_type.to_string(device.type)) print(' Device - Max Clock Speed: {0} Mhz'\ .format(device.max_clock_frequency)) print(' Device - Compute Units: {0}'\ .format(device.max_compute_units)) print(' Device - Local Memory: {0:.0f} KB'\ .format(device.local_mem_size/1024.0)) print(' Device - Constant Memory: {0:.0f} KB'\ .format(device.max_constant_buffer_size/1024.0)) print(' Device - Global Memory: {0:.0f} GB'\ .format(device.global_mem_size/1073741824.0)) print(' Device - Max Buffer/Image Size: {0:.0f} MB'\ .format(device.max_mem_alloc_size/1048576.0)) print(' Device - Max Work Group Size: {0:.0f}'\ .format(device.max_work_group_size)) print('\n') Итак, мы реализуем свою функцию main, которая вызывает реализованную выше функцию print_device_info: if __name__ == "__main__": print_device_info() Как это работает... Следующая команда применяется для импорта библиотеки pyopencl: import pyopencl as cl Это делает для нас доступным метод get_platforms, который возвращает список экземпляров платформы,то есть перечень устройств для данной системы: for platform in cl.get_platforms(): Затем для каждого обнаруженного устройства отображаются следующие основные свойства: Название и тип устройства Максимальная тактовая частота Вычислительные элементы Локальная/ постоянная/ глобальная память Для нашего примера вывод таков: (base) C:\> python deviceInfoPyopencl.py ============================================================= OpenCL Platforms and Devices ============================================================ Platform - Name: NVIDIA CUDA Platform - Vendor: NVIDIA Corporation Platform - Version: OpenCL 1.2 CUDA 10.1.152 Platform - Profile: FULL_PROFILE -------------------------------------------------------- Device - Name: GeForce 840M Device - Type: GPU Device - Max Clock Speed: 1124 Mhz Device - Compute Units: 3 Device - Local Memory: 48 KB Device - Constant Memory: 64 KB Device - Global Memory: 2 GB Device - Max Buffer/Image Size: 512 MB Device - Max Work Group Size: 1024 ============================================================ Platform - Name: Intel(R) OpenCL Platform - Vendor: Intel(R) Corporation Platform - Version: OpenCL 2.0 Platform - Profile: FULL_PROFILE -------------------------------------------------------- Device - Name: Intel(R) HD Graphics 5500 Device - Type: GPU Device - Max Clock Speed: 950 Mhz Device - Compute Units: 24 Device - Local Memory: 64 KB Device - Constant Memory: 64 KB Device - Global Memory: 3 GB Device - Max Buffer/Image Size: 808 MB Device - Max Work Group Size: 256 -------------------------------------------------------- Device - Name: Intel(R) Core(TM) i7-5500U CPU @ 2.40GHz Device - Type: CPU Device - Max Clock Speed: 2400 Mhz Device - Compute Units: 4 Device - Local Memory: 32 KB Device - Constant Memory: 128 KB Device - Global Memory: 8 GB Device - Max Buffer/Image Size: 2026 MB Device - Max Work Group Size: 8192 Также ознакомьтесь... OpenCL в настоящее время управляется Khronos Group, некоммерческим консорциумом компаний, которые сотрудничают в определении спецификаций этого (и многих иных) стандартов и параметров совместимости для создания особенных для OpenCL драйверов всех видов платформ. Такие драйверы также предоставляют функции для вычислительных программ, которые пишутся на языке ядра: они преобразуются в программы некого вида промежуточного языка, который обычно является особым для производителя, а затем исполняются на эталонной архитектуре. Дополнительные сведения по OpenCL можно найти по следующей ссылке. |