курсовая. Основы работы со строками
 Скачать 146.26 Kb. Скачать 146.26 Kb.
|

|
Основы работы со строками В Python есть несколько способов задания строк. С первыми двумя способами мы уже немного познакомились на предыдущих занятиях: str1 = 'Hello1' str2 = "Hello2" А другие два позволяют задавать многострочные данные: str3 = '''Многострочные строки 1'''; str4 = """Многострочные строки2"""; print(str1) print(str2) print(str3) print(str4) То есть, синтаксис из трех кавычек задает множественные строки. Причем, смотрите, если мы непосредственно в консоли напишем: '''hello world''' то при выводе после hello увидим символ \n, который и означает перевод строки. Функция print обрабатывая этот символ делает перевод строки: print('hello\nworld') Если в кавычках ничего не записано: str0 = "" то это будет пустая строка, не содержащая никаких символов. При работе с переменными в Python всегда следует помнить, что это лишь ссылки на соответствующие объекты. Из этого следует, что если у нас определена некая строка: str1 = "сообщение" и мы другой переменной присвоим первую: str2 = str1 то получим две ссылки на один и тот же объект (одну строку). То есть, копирование строки здесь не происходит!  Как создавать копии строк вы узнаете дальше из этого занятия. Операторы и функции для строк Первый оператор + – это соединение двух строк (или как еще говорят, конкатенация строк). Он используется так: str1 = 'Hello' str2 = "world!" msg = str1+str2 print(msg) Здесь сначала будут идти символы первой строки, а затем – второй. В результате у нас формируется новый объект, содержащий эти символы. Но у нас оба слова слились в одно. Как можно было бы добавить между ними пробел? Это можно сделать так: msg = str1+" "+str2 то есть, мы можем последовательно соединять множество строк между собой. И здесь важно знать, что соединять между собой можно только строки. Например, вот такая операция приведет к ошибке: dig = 5 msg = "число = "+dig print(msg) так как dig здесь число, а не строка. Поправить программу можно преобразовав число в строку с помощью функции str(<аргумент>) Основные методы строкКак мы уже неоднократно говорили, в Python строки являются объектами и у этих объектов есть методы, то есть, функции, выполняющие определенные действия: строка.имя_метода(аргументы) Для примера, предположим, у нас имеется такая, уже классическая строка: string = "Hello World!" и мы собираемся для нее вызвать метод String.upper() который возвращает строку со всеми заглавными буквами. Для этого, пишется сама строка, ставится точка и записывается имя метода. В конце обязательно ставим круглые скобки: string.upper() Вот по такому синтаксису вызываются различные методы строк. Причем, сама переменная string продолжает ссылается на ту же самую неизмененную строку «Hello World!». Как мы с вами говорили на предыдущем занятии, строки – это неизменяемые объекты, поэтому метод upper возвращает новую строку с заглавными буквами, не меняя прежней. Если бы нам потребовалось изменить строку, на которую ссылается переменная string, то это можно сделать так: string = string.upper() В этом случае переменная станет ссылаться на новый строковый объект с заглавными буквами, а прежний будет автоматически удален сборщиком мусора (так как на него не будет никаких внешних ссылок). Также этот метод мы можем вызвать непосредственно у строкового литерала: "hello".upper() Так тоже можно делать. Ну и раз уж мы затронули метод upper, который переводит буквы в верхний регистр, то отметим противоположный ему метод: String.lower() который, наоборот, преобразует все буквы в строчные. Например: string.lower() возвращает строку «hello world!». Соответственно, сама строка здесь остается прежней, измененным является новый строковый объект, который и возвращает метод lower. По такому принципу работают все методы при изменении строк. Следующий метод String.count(sub[, start[, end]]) возвращает число повторений подстроки sub в строке String. Два необязательных аргумента: start – индекс, с которого начинается поиск; end – индекс, которым заканчивается поиск. В самом простом случае, мы можем для строки msg = "abrakadabra" определить число повторений сочетаний «ra»: msg.count("ra") получим значение 2 – именно столько данная подстрока встречается в нашей строке. Теперь предположим, что мы хотим начинать поиск с буквы k, имеющей индекс 4.  Тогда метод следует записать со значением start=4: msg.count("ra", 4) и мы получим значение 1. Далее, укажем третий аргумент – индекс, до которого будет осуществляться поиск. Предположим, что мы хотим дойти до 10-го индекса и записываем: msg.count("ra", 4, 10) и получаем значение 0. Почему? Ведь на индексах 9 и 10 как раз идет подстрока «ra»? Но здесь, также как и в срезах, последний индекс исключается из рассмотрения. То есть, мы говорим, что нужно дойти до 10-го, не включая его. А вот если запишем 11: msg.count("ra", 4, 11) то последнее включение найдется. Следующий метод String.find(sub[, start[, end]]) возвращает индекс первого найденного вхождения подстроки sub в строке String. А аргументы start и end работают также как и в методе count. Например: msg.find("br") вернет 1, т.к. первое вхождение «br» как раз начинается с индекса 1. Поставим теперь значение start=2: msg.find("br", 2) и поиск начнется уже со второго индекса. Получим значение 8 – индекс следующего вхождения подстроки «br». Если мы укажем подстроку, которой нет в нашей строке: msg.find("brr") то метод find возвращает -1. Третий аргумент end определяет индекс до которого осуществляется поиск и работает также как и в методе count. Метод find ищет первое вхождение слева-направо. Если требуется делать поиск в обратном направлении: справа-налево, то для этого используется метод String.rfind(sub[, start[, end]]) который во всем остальном работает аналогично find. Например: msg.rfind("br") возвратит 8 – первое вхождение справа. Наконец, третий метод, аналогичный find – это: String.index(sub[, start[, end]]) Он работает абсолютно также как find, но с одним отличием: если указанная подстрока sub не находится в строке String, то метод приводит к ошибке: msg.index("brr") тогда как find возвращает -1. Спрашивается: зачем нужен такой ущербный метод index? В действительности такие ошибки можно обрабатывать как исключения и это бывает полезно для сохранения архитектуры программы: когда неожиданные ситуации обрабатываются единым образом в блоке исключений. Но, обо всем этом речь пойдет позже. Следующий метод String.replace(old, new, count=-1) Выполняет замену подстрок old на строку new и возвращает измененную строку. Например, в нашей строке, мы можем заменить все буквы a на o: msg.replace("a", 'o') на выходе получим строку «obrokodobro». Или, так: msg.replace("ab", "AB") Используя этот метод, можно выполнять удаление заданных фрагментов, например, так: msg.replace("ab", "") Третий необязательный аргумент задает максимальное количество замен. Например: msg.replace("a", 'o', 2) Заменит только первые две буквы a: «msg.replace("a", 'o', 2)». При значении -1 количество замен неограниченно. Следующие методы позволяют определить: из каких символов состоит наша строка. Например, метод String.isalpha() возвращает True, если строка целиком состоит из букв и False в противном случае. Посмотрим как он работает: msg.isalpha() вернет True, т.к. наша строка содержит только буквенные символы. А вот для такой строки: "hello world".isalpha() мы получим False, т.к. имеется символ пробела. Похожий метод String.isdigit() возвращает True, если строка целиком состоит из цифр и False в противном случае. Например: "5.6".isdigit() т.к. имеется символ точки, а вот так: "56".isdigit() получим значение True. Такая проверка полезна, например, перед преобразованием строки в целое число: dig = input("Введите число: ") if(dig.isdigit()): dig = int(dig) print(dig) else: print("Число введено неверно") Следующий метод String.rjust(width[, fillchar = ‘ ‘]) возвращает новую строку с заданным числом символов width и при необходимости слева добавляет символы fillchar: d="abc" d.rjust(5) Получаем строку « abc» с двумя добавленными слева пробелами. А сама исходная строка как бы прижимается к правому краю. Или, можно сделать так: d.rjust(5, "-") Получим строку «--abc». Причем вторым аргументом можно писать только один символ. Если записать несколько, то возникнет ошибка: d.rjust(5, "-*") Если ширина width будет меньше длины строки: d.rjust(2) то ничего не изменится. Аналогично работает метод String.ljust(width[, fillchar = ‘ ‘]) который возвращает новую строку с заданным числом символов width, но добавляет символы fillchar уже справа: d.ljust(10, "*") Следующий метод String.split(sep=None, maxsplit=-1) возвращает коллекцию строк, на которые разбивается исходная строка String. Разбивка осуществляется по указанному сепаратору sep. Например: "Иванов Иван Иванович".split(" ") Мы здесь разбиваем строку по пробелам. Получаем коллекцию из ФИО. Тот же результат будет и при вызове метода без аргументов, то есть, по умолчанию он разбивает строку по пробелам: "Иванов Иван Иванович".split() А теперь предположим, перед нами такая задача: получить список цифр, которые записаны через запятую. Причем, после запятой может быть пробел, а может и не быть. Программу можно реализовать так: digs = "1, 2,3, 4,5,6" digs.replace(" ", "").split(",") мы сначала убираем все пробелы и для полученной строки вызываем split, получаем список цифр. Обратный метод String.join(список) возвращает строку из объединенных элементов списка, между которыми будет разделитель String. Например: d = digs.replace(" ", "").split(",") ", ".join(d) получаем строку «1, 2, 3, 4, 5, 6». Или так, изначально была строка: fio = "Иванов Иван Иванович" и мы хотим здесь вместо пробелов поставить запятые: fio2 = ",".join(fio.split()) Теперь fio2 ссылается на строку с запятыми «Иванов,Иван,Иванович». Следующий метод String.strip() удаляет пробелы и переносы строк в начале и конце строки. Например: " hello world \n".strip() возвращает строку «hello world». Аналогичные методы: String.rtrip() и String.ltrip() удаляют пробелы и переносы строк только справа и только слева. 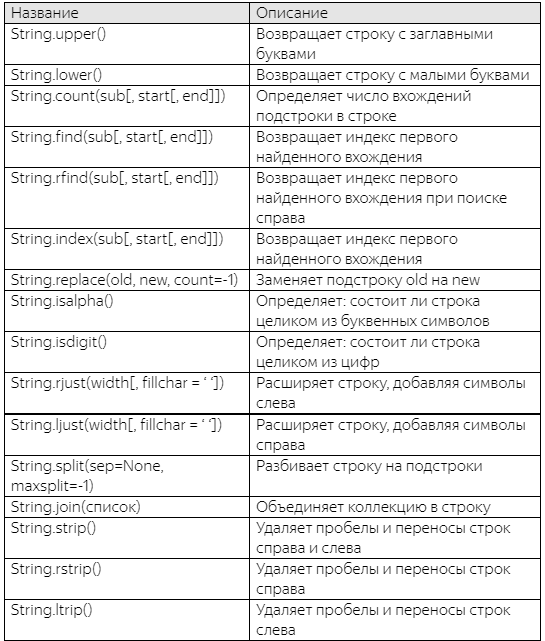 |

