Анализ данных. Разложение суммы квадратов в однофакторном да
 Скачать 2.64 Mb. Скачать 2.64 Mb.
|

Последовательный симплексный метод Этот метод требует проведения минимально возможного числа опытов при определении направления движения.Симплексом в n-мерном пространстве называют многогранник с (n+1)-й вершиной. Если расстояния между вершинами симплекса одинаковы, такой симплекс называют регулярным. Симплексный метод включает в себя следующие основные процедуры: 1. Линейное преобразование входных переменных с таким расчетом, чтобы изменение каждой из них на единицу одинаково сказывалось бы на изменении выходной переменной. 2. Построение регулярного симплекса и реализация опытов в вершинах симплекса. 3. Отбрасывание вершины с минимальным значением целевой величины и построение нового симплекса, который образуется оставшимися вершинами исходного симплекса и новой вершиной, получаемой зеркальным отображением отброшенной вершины относительно противоположной ей где 4. Проведение эксперимента в вершине 5. Если при перемещении симплекса за 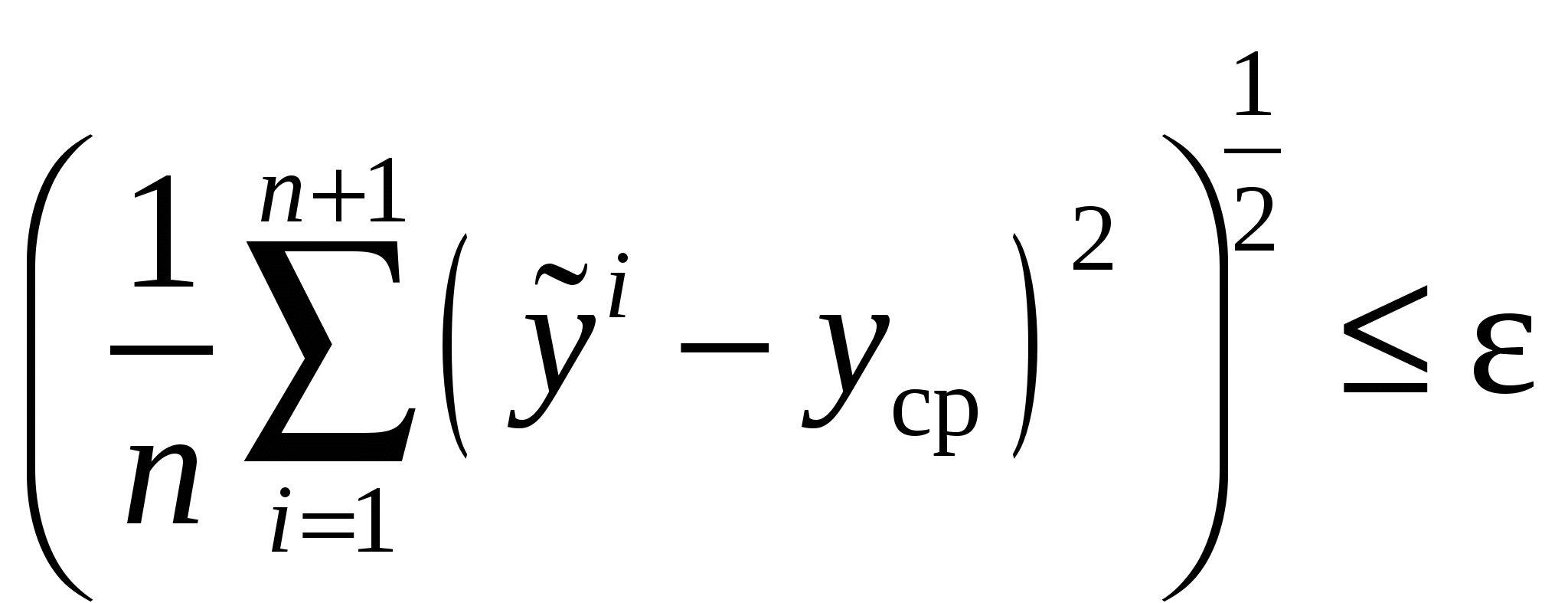 , где – малая величина (порог), , где – малая величина (порог), К числу достоинств симплексного метода наряду с экономичностью по числу опытов и простотой вычислений следует отнести также возрастание эффективности метода с ростом числа входных переменных, устойчивость выделения направления движения, поскольку оно определяется только соотношением целевых величин, а не их абсолютными значениями. Графическая иллюстрация симплексного метода при двух входных переменных приведена на рис.5. Здесь поверхность отклика задается линиями уровня. x2 x1 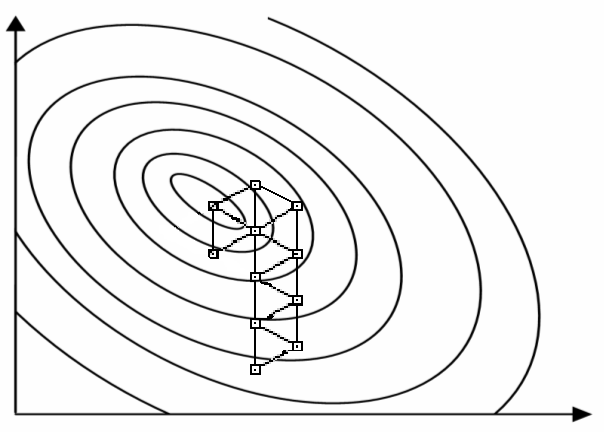 Рис. 5. Схема последовательного симплексного метода 13. Метод Бокса-Уилсона. На основе малой серии опытов строится линейное описание поверхности отклика в окрестности начальной точки. В центре этой локальной области определяется значение градиента, после чего начинаются опыты в направлении градиента. Бокс и Уилсон предложили использовать дробные факторные планы для поиска линейной модели. Метод состоит из последовательности циклов, каждый из которых содержит два шага. 1. Построение линейной модели в окрестности некоторой начальной точки 2. Пошаговое увеличение величины целевой функции (движение в направлении градиента). Координаты точки наблюдения на Геометрическая интерпретация метода приведена на рис.4. Здесь поверхность отклика задается линиями уровня. x2  x1 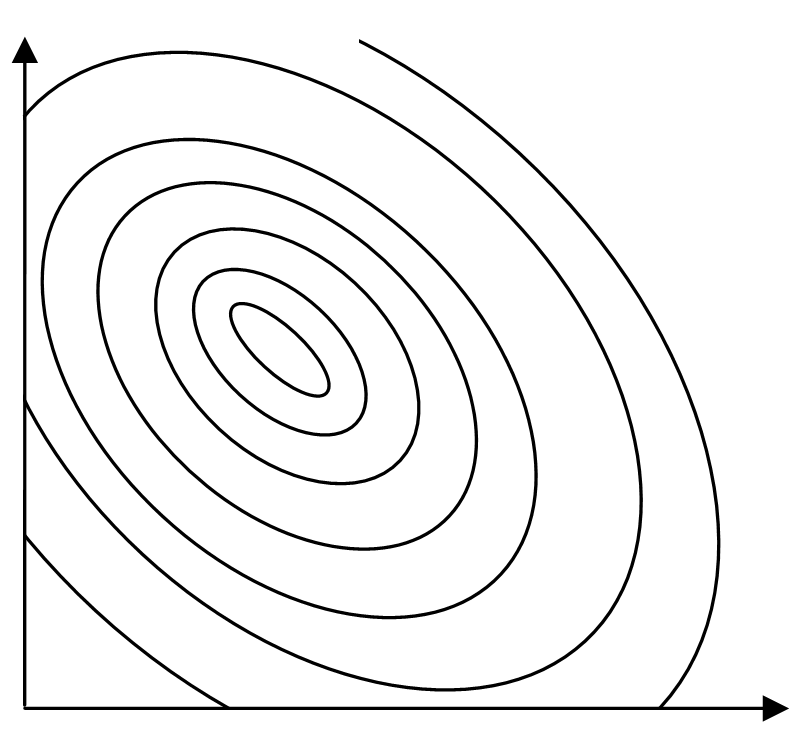 Рис. 4. Схема метода Бокса–Уилсона Рассмотрим в качестве примера использование метода Бокса−Уилсона для поиска максимума функции Допустимая область изменения переменных: 0х120, 0х210, 1х315. Начальная точка поиска х0= Линейная модель Таблица 16
В последнем столбце табл.16 содержатся значения функции (6.11) для исходных переменных, то есть 40,8=у(4,4,7) и так далее. МНК-оценки коэффициентов линейной модели составят: Отнормируем полученные компоненты градиента, поделив их на максимальное значение Таблица 17
Движение в направлении градиента после четвертого шага невозможно из-за ограничения на х3. Теперь следует определить градиент в точке x0+3bii. Поскольку темп роста функции замедлился на последних шагах, область линейного описания следует сузить, уменьшив значения i. 14. Анализ главных компонент. Вычислительная процедура. Пусть имеется множество, состоящее из N объектов. Каждый объект описывается с помощью n переменных (признаков, факторов). Совокупность значений переменных сведена в матрицу: 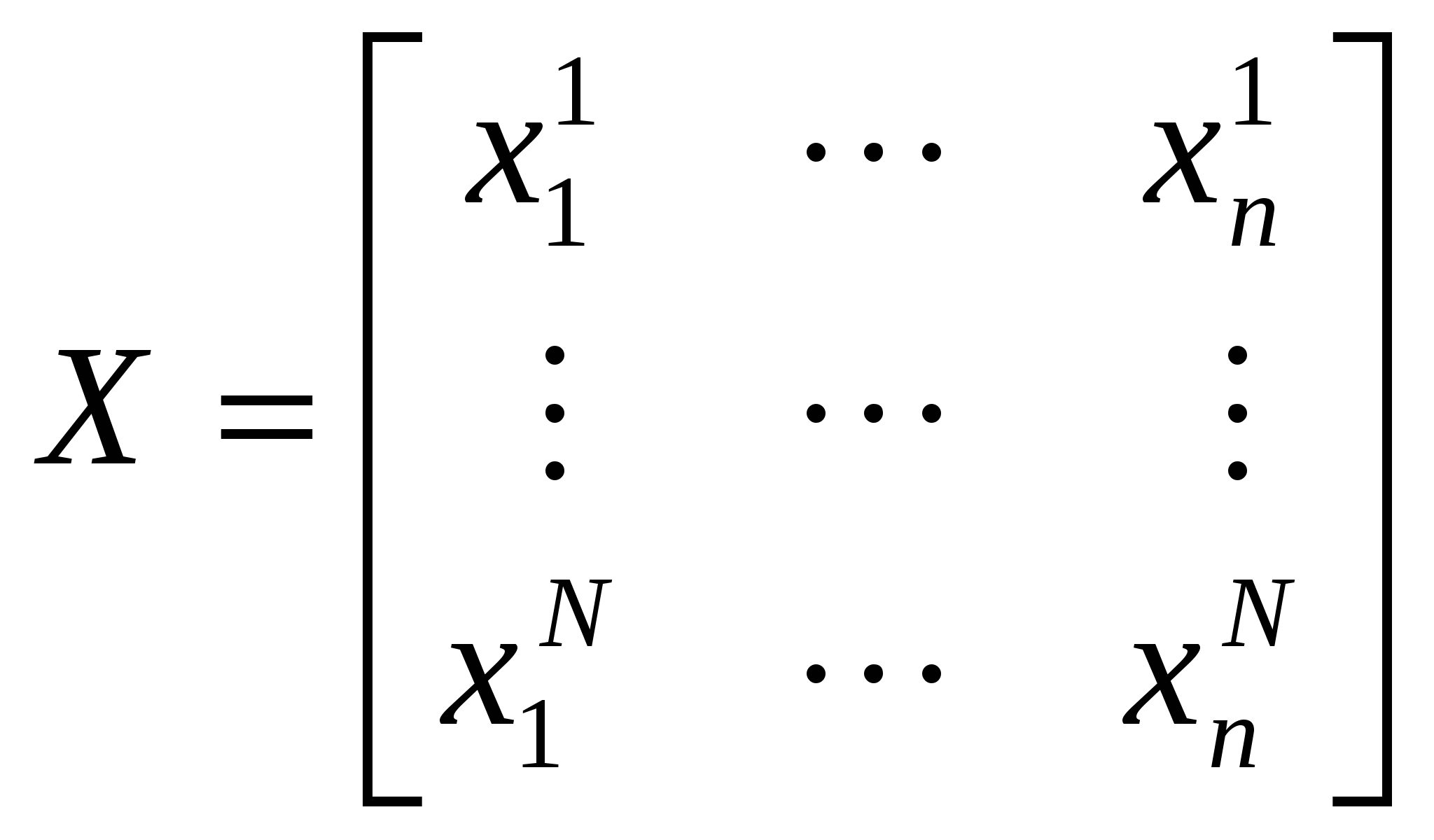 , (10.1) , (10.1)в которой наблюдения представлены в виде отклонений от выборочных средних, иначе говоря, центрированы, т.е. где От исходного вектора признаков перейдем к новому множеству переменных Каждую компоненту вектора z будем представлять в виде некоторой линейной комбинации исходных признаков, т.е. где На компоненты вектора z наложим следующее требование: первая переменная Вычисление главных компонент Вычисление весовых коэффициентов будем проводить последовательно, начиная с первой главной компоненты. Значение первой главной компоненты Вводя векторное обозначение Оценка дисперсии D(z1) центрированной переменной Вектор параметров Для максимизации (10.5а) при ограничении (10.6) воспользуемся методом неопределенных множителей Лагранжа. Определим где Дифференцирование Из (10.7) видно, что Из (10.6) и (10.7) следует, что Поскольку При поиске значений элементов вектора Поскольку ни (N-1), ни нулю не равны, имеем: Определим функцию Лагранжа следующим образом: где λ2 и Приравняем нулю частную производную φ по Умножая последнее равенство слева на Учитывая, что Следовательно, соотношение (10.8) примет вид где в качестве В итоге, значения главных компонент задаются матрицей: Ковариационная матрица главных компонент есть Введем диагональную матрицу собственных значений 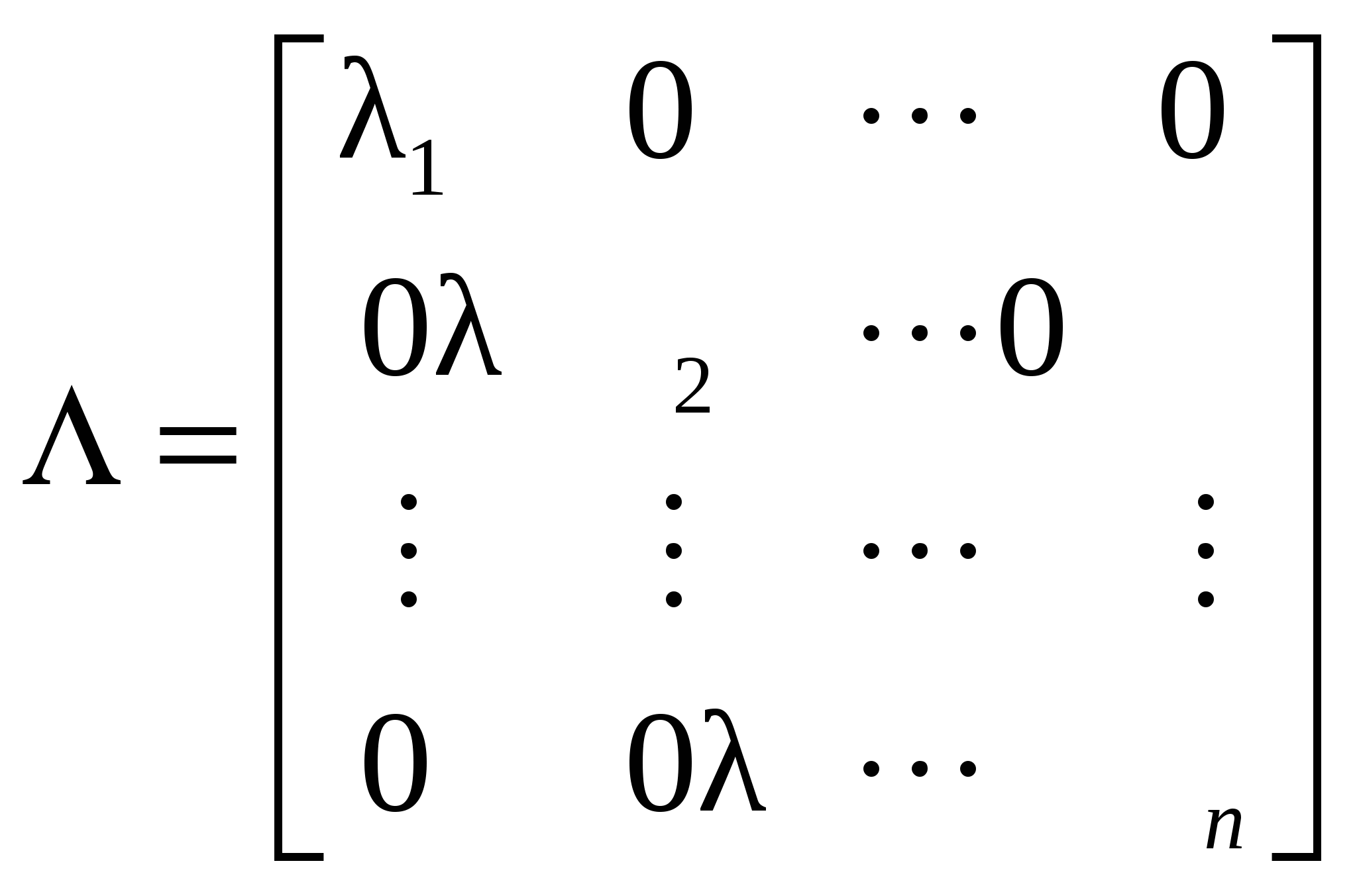 Тогда Следовательно, главные компоненты попарно некоррелированы, а их дисперсии совпадают с собственными значениями ковариационной матрицы исходных переменных. Если ранг матрицы Х меньше n , то у матрицы Суммарная дисперсия исходных переменных, равная следу матрицы Здесь мы воспользовались свойством неизменности следа произведения матриц при перестановке сомножителей, т.е. tr(AB)=tr(BA) (предполагается, что произведение ВА существует). Тогда отношения 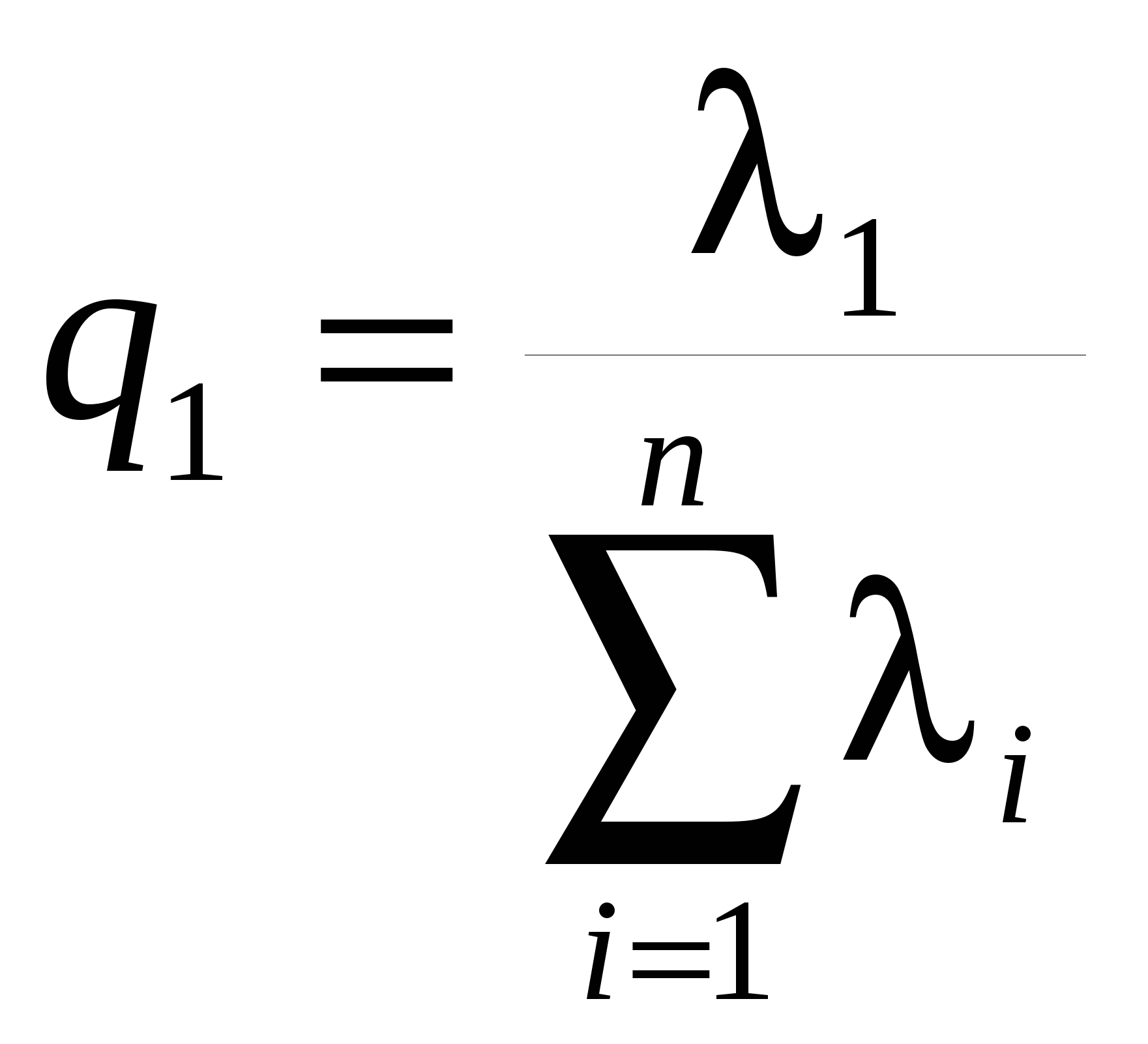 , ,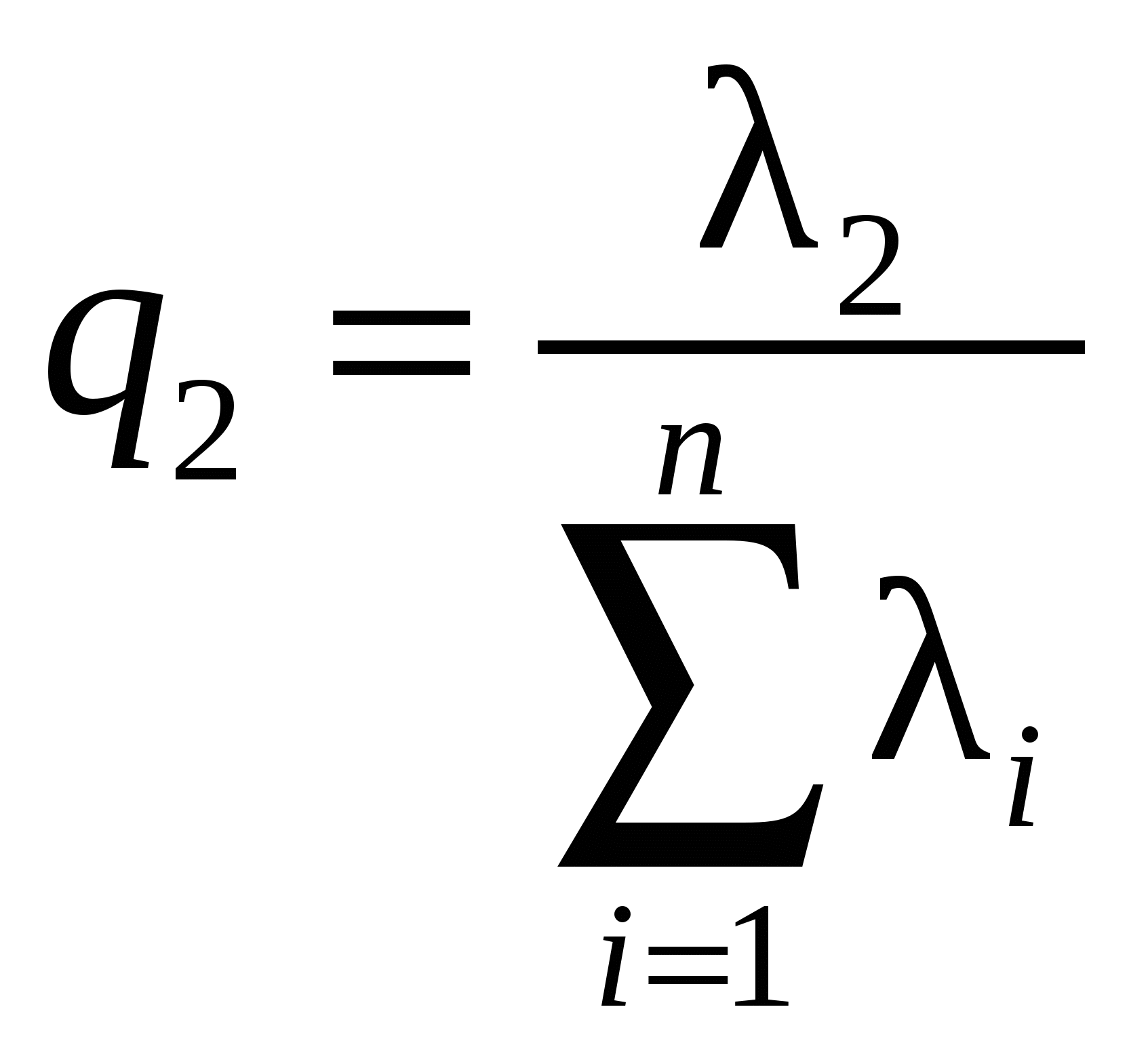 ,…, ,…,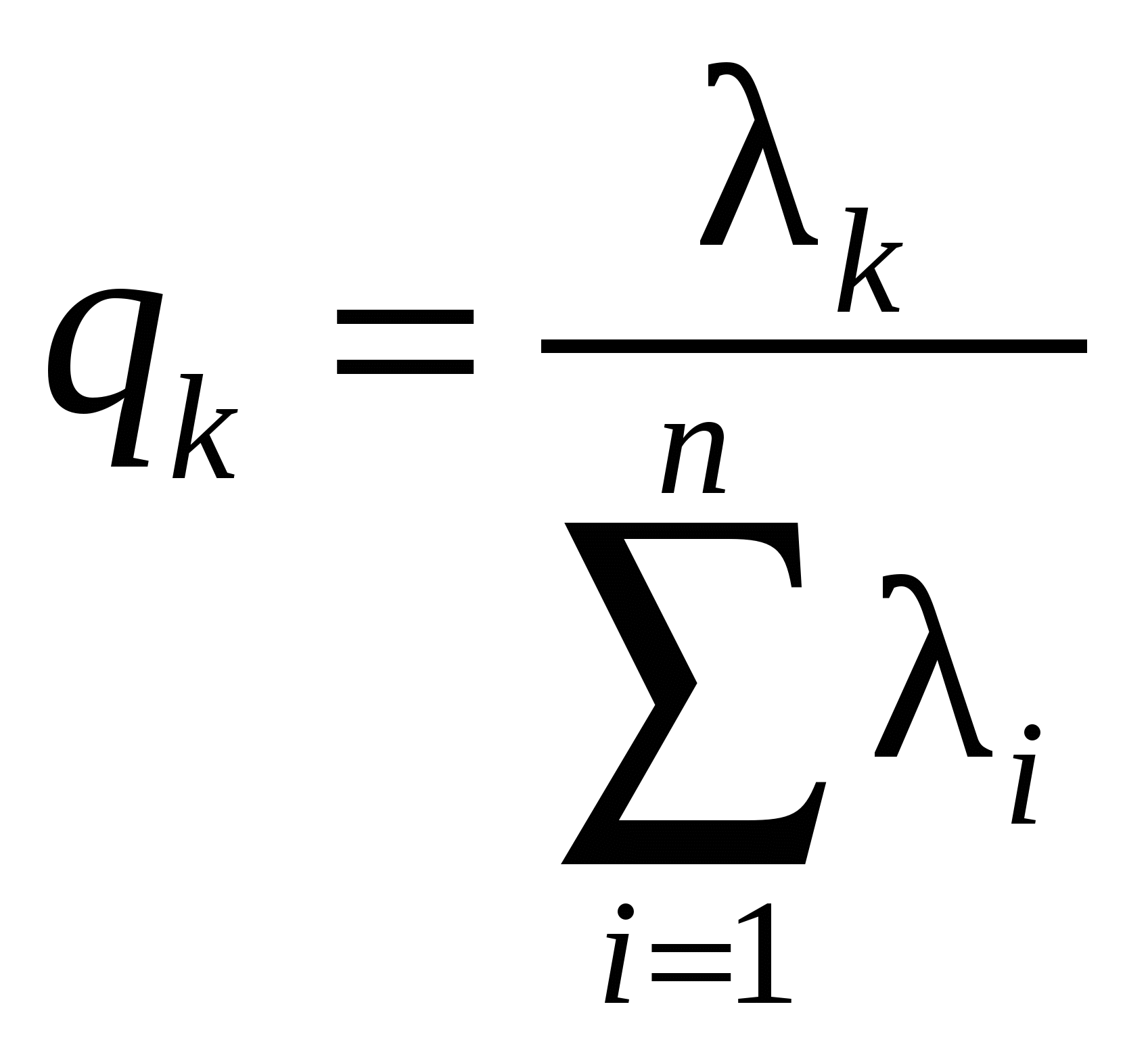 , ,характеризуют пропорциональный вклад каждого вектора, представляющего главные компоненты, в суммарную дисперсию исходных переменных. Накопленные отношения показывают относительную долю в суммарной дисперсии исходных переменных, которая приходится на первые k главных компонент. Задавшись некоторым порогом В заключение сделаем два замечания. 1. Переход к главным компонентам наиболее естественен и эффективен, когда исходные признаки имеют общую физическую природу и измерены в одних и тех же единицах. Если это условие не имеет место, то результаты иcследования с помощью главных компонент будут существенно завиcеть от выбора масштаба и природы единиц измерения. В качестве практического средства в таких ситуациях можно рекомендовать переход к вспомогательным безразмерным признакам 2. Аналитически доказано, что переход от исходного n-мерного пространства к m-мерному пространству главных компонент сопровождается наименьшими искажениями суммы квадратов расстояний между всевозможными парами точек наблюдений, расстояний от точек наблюдений до их общего центра тяжести, а также углов между прямыми, соединяющими всевозможные пары точек наблюдений с их общим центром тяжести | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||