курсовая работа тема акимат. Акимат. Разработка информационной системы контроля исполнения поручений для сотрудников акимата
 Скачать 1.29 Mb. Скачать 1.29 Mb.
|

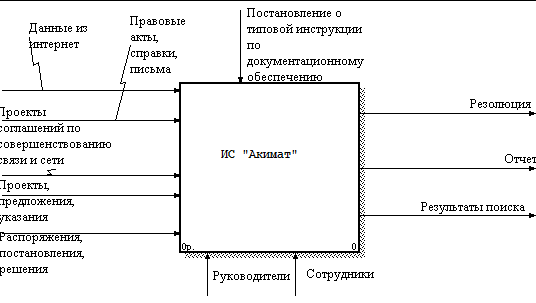 Рисунок 3. ERP – модель ИС «Акимат» BPwin – это мощный инструмент моделирования, который используется для анализа, документирования и реорганизации сложных бизнес-процессов. Модель, созданная средствами BPwin, позволяет четко документировать различные аспекты деятельности - действия, которые необходимо предпринять, способы их осуществления, требующиеся для этого ресурсы и др. Таким образом формируется целостная картина деятельности предприятия - от моделей организации работы в маленьких отделах до сложных иерархических структур. Модели BPwin дают основу для осмысления бизнес - процессов и оценки влияния тех или иных событий, а также описывают взаимодействие процессов и потоков информации в организации. Неэффективная, высоко затратная или избыточная деятельность может быть легко выявлена и, следовательно, усовершенствована, изменена или устранена в соответствии с общими целями организации. ERP – модель бизнес-процессов рассмотрена на рисунке 4. 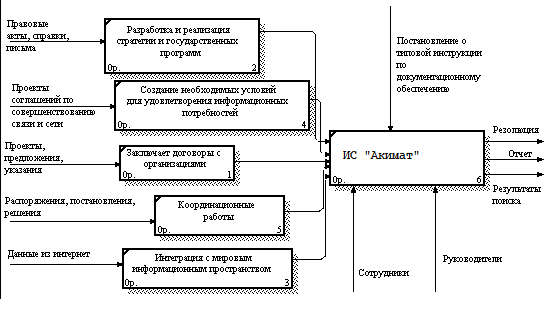 Рисунок 4. ERP – модель бизнес-процессов С точки зрения системного анализа концептуальное моделирование является структуризацией предметной области, для которой разрабатывается система. Ее цель - выявление перечня и иерархии предметов, объектов, факторов и явлений, полный набор которых позволяет реализовать поставленные перед системой цели и задачи. Согласно методологии ООАПиП системный анализ проекта предполагает на первом этапе рассмотрение и физическое моделирование предметной области. На данном этапе проводится расчленение (выделение, разбивка) предметной области, объектов системы на ряд подоблостей или подсистем (уровней), характеризуемых целостностью их восприятия и однородностью выполняемых работ (функций). При этом требуемый критерий целостности восприятия дает право продолжать расчленение до тех пор пока предмет или объект (фактор системы) не перестанет восприниматься как в свою очередь состоящий из объектов, т.е. до элементарного, неделимого уровня. Критерий однородности выполняемых работ (функций) дает возможность использовать концептуальную модель для корректировки разработанного во введении дерева работ. Результаты концептуального моделирования являются базисными для реализации этапов информационного моделирования и затем разработки моделей состояний (жизненных циклов системы) - моделей, определяющих функционирование разрабатываемой системы. Для углубленного изучения и закрепления проделанной работы, немаловажную роль играет детальное рассмотрение различных объектов. Именно в этом состоит задача концептуального моделирования. Иными словами говоря концептуальное моделирование включает системное представление доменов предметной области с кратким описанием назначения или функций объекта и структуризацию факторов (атрибутов). Так как, объекты составляют основу концептуального моделирования, я хотел бы остановиться на них более подробно. Объект это абстракция множества предметов реального мира. Различают следующие виды объектов. Реальные объекты – предметы реального мира, а точнее абстракции реальных объектов, как их мы представляем для наших целей. Например: завод, бухгалтерия, склад. Ролевые объекты – абстракции цели или назначения человека, функциональные части оборудования или организации. Например: бухгалтер, экономист, аудитор. Инциденты – абстракция чего-то произошедшего или случившегося. Например: перечисление в банк, проводка, платежи, поставка. Взаимодействие – объекты получаемые из отношений с другими объектами. Например: контракт, платежная ведомость, налоги, главная книга. Спецификация – используется для представления правил, нормативных документов или критериев качества, стандартов. Методы концептуального моделирования используют широкий диапазон математических средств и методов представления знаний. Широко используются как древовидные, так и сетевые конструкции, в которых различаются как вершины, так и ребра. Одним из видов являются графы связей, позволяющие разбивать структуру на узкие классы объектов системы. Очень часто графы связей отображаются таблицами в виде логических матриц отношений. Построение графов связей или таблиц один из распространённых методов формализации проектных задач. В данной курсовой работе была выбрана древовидная структура как более удобная и наглядная в конкретном случае. Древовидная или иерархическая структура – эта структура, в которой каждый компонент системы, исключая первый непосредственно подчиняется только одному (вышестоящему) компоненту структуры. Это хорошо видно в (Приложении Б) на приведенных примерах концептуальных моделей. Цель этапа информационного моделирования состоит в том, чтобы идентифицировать концептуальные сущности, или объекты, которые составляют подсистему для анализа. Объекты информационной модели представляются через их имена и имена их атрибутов. Здесь устанавливаются связи между информационными объектами и функциональные зависимости. На рисунке 5 показана концептуальная модель. 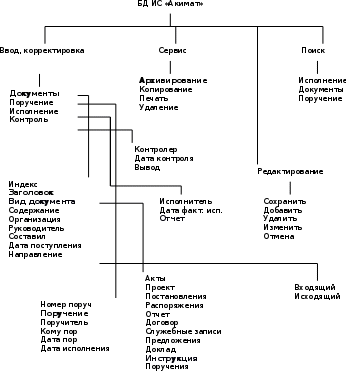 Рисунок 5. Концептуальная модель Кроме структурной направленности информационное моделирование связанно с особенностями реализации связей в различных компьютерных технологиях, в зависимости от количества связываемых предметов. Методология ООАПиП, в этой связи различает и рассматривает три вида связей: 1) один к одному; 2) один ко многим; 3) многие ко многим. Это объясняется различными подходами и методами их реализации в отдельных компьютерных технологиях. Так, связи один к одному реализуется преимущественно матрицами, связи один ко многим на базе реляционной алгебры и реляционных таблиц, а связи “многие ко многим” требуют использования вспомогательного объекта. Поэтому данная глава курсовой работы двунаправлена - решает как задачу структуризации системы, так и задачу анализа и формирования упомянутых трех видов связей. Кроме того, в методологии ООАПиП принят графический вид информационных моделей, как предварительных, базисных для последующего моделирования состояний - жизненных циклов. В информационной модели каждому объекту должно быть назначено уникальное имя. При этом имя должно явно указывать отношение объекта или к классу объектов или к экземпляру. Для успешной реализации проекта объект проектирования должен быть прежде всего адекватно описан, должны быть построены полные и непротиворечивые функциональные и информационные модели ИС. Накопленный к настоящему времени опыт проектирования ИС показывает, что это логически сложная, трудоемкая и длительная по времени работа, требующая высокой квалификации участвующих в ней специалистов. Однако до недавнего времени проектирование ИС выполнялось в основном на интуитивном уровне с применением неформализованных методов, основанных на искусстве, практическом опыте, экспертных оценках и дорогостоящих экспериментальных проверках качества функционирования ИС. Кроме того, в процессе создания и функционирования ИС информационные потребности пользователей могут изменяться или уточняться, что еще более усложняет разработку и сопровождение таких систем. Ручная разработка обычно порождала следующие проблемы: неадекватная спецификация требований; неспособность обнаруживать ошибки в проектных решениях; низкое качество документации, снижающее эксплуатационные качества; затяжной цикл и неудовлетворительные результаты тестирования. Перечисленные факторы способствовали появлению программно-технологических средств специального класса - CASE-средств, реализующих CASE-технологию создания и сопровождения ИС. Термин CASE (Computer Aided Software Engineering) используется в настоящее время в весьма широком смысле. Первоначальное значение термина CASE, ограниченное вопросами автоматизации разработки только лишь программного обеспечения (ПО), в настоящее время приобрело новый смысл, охватывающий процесс разработки сложных ИС в целом. Теперь под термином CASE-средства понимаются программные средства, поддерживающие процессы создания и сопровождения ИС, включая анализ и формулировку требований, проектирование прикладного ПО и баз данных, генерацию кода, тестирование, документирование, обеспечение качества, конфигурационное управление и управление проектом, а также другие процессы. CASE-средства вместе с системным ПО и техническими средствами образуют полную среду разработки ИС. CASE-технология представляет собой методологию проектирования ИС, а также набор инструментальных средств, позволяющих в наглядной форме моделировать предметную область, анализировать эту модель на всех этапах разработки и сопровождения ИС и разрабатывать приложения в соответствии с информационными потребностями пользователей. Большинство существующих CASE-средств основано на методологиях структурного (в основном) или объектно-ориентированного анализа и проектирования, использующих спецификации в виде диаграмм или текстов для описания внешних требований, связей между моделями системы, динамики поведения системы и архитектуры программных средств. Пример информационной модели данных по системе «Автоматизированная система документооборота» проработан в системе Erwin, в соответствии с рисунком 6. 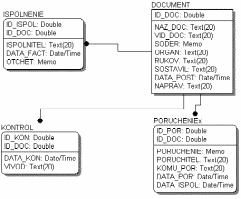 Рисунок 6. Информационная модель Необходимость анализа и разработки больших сложных, а в последнее время и сверхсложных систем, появление и использование при этом новых методологий, в частности ООАПиП, корпоративное проектирование, методология управления проектами, появление современных компьютерных технологий привело к следующему факту: - при планировании и реализации этих работ алгоритмический подход, которым ранее широко пользовались, имеет существенный недостаток препятствующий этим работам. Обнаружилось, что при алгоритмическом подходе трудно отслеживать все нюансы поведения (изменений состояний) анализируемых и разрабатываемых информационных объектов и систем, охватить все аспекты их поведения (функционирования), управления и пребывания в отдельных промежуточных состояниях. В связи с этим современные методы анализа разработки, моделирования, а также компьютерной технологии предлагают рассматривать поведение информационных объектов и систем в динамике (при функционировании) вводя понятие жизненного цикла объектов, подсистем, систем и надсистем. Жизненный цикл представляет как модель их поведения, т.е. переход из одного состояния в другое. При этом считается наиболее подходящей моделью для представления жизненного цикла дискретный автомат Мура. С этих позиций проанализируем и сопоставим трактовку модели представления жизненного цикла (состояний) методологии ООАПиП и классическую модель конечного автомата Мура представляющего частный их вид – автоматы без выходов. Методология считает , что модель имеет следующий состав : 1) Множество состояний. Каждое состояние представляет стадию или этап в жизненном цикле типичного экземпляра объекта, при этом в качестве объектов рассматриваются не только элементарные но и подсистемы и надсистемы. С точки зрения теории КА – это внутреннее состояние автомата которое, как правило, обозначается в алфавите Q. 2) Множество событий. Каждое событие представляет собой некоторое законченное действие влекущее за собой некоторое действие изменяющее поведение, состояние объекта или системы. 3) Множество правил перехода. Правило перехода определяет в какое следующее состояние переходит объект или система совпадая с теорией КА. 4) Действия. Действия – это деятельность или совокупность операций которые должны быть выполнены над объектами системы для достижения определенного состояния. По крайней мере одно определенное действие должно быть связанно каждым состоянием, с точки зрения теории КА действие соответствует функциям перехода. Придание функциям перехода более широкого смысла действия расширяет возможности моделирования жизненных циклов поскольку внутреннее состояние рассматривается в течении промежутка времени во время которого решается частная задачи ведущие к достижению данного состояния или совершается определенная работа результатом которой является данное состояние. В качестве примеров действий приводятся выполнение расчетов над некоторой промежуточной таблицей; реализации элементарного этапа; действие по достижению заданного критериального значения; определенная работа требующееся для достижения данного состояния; определенной обработки данных заданных состояний и т.п. Анализ описания действий в методологии ООПиП рпиводит к выводу, что это понятие подробно обсуждается в связи с удобством его использования при реализации модели состояний в различных компьютерных технологиях. С другой стороны широкой трактовкой действия подтверждается сущность систем как интерпретирующих блок-схемы системы. Ибо как указанно выше интерпретирующая система по своему определению связанна с определенными действиями. Каков бы ни был замысел проекта, сам по себе, без реализации он мало что значит. Важен результат выполнения проекта, нужна работа по его осуществлению. Каждый проект независимо от его сложности и объема работ, необходимых для его выполнения, проходит в своем развитии определенные состояния: от состояния, когда «проекта еще нет», и до состояния, когда «проекта ужу нет». Это упрощенное представление о «начале» и «конце» жизни проекта требует уточнения. Что считать началом проекта? Иногда это момент рождения идеи, особенно если ее рождению предшествовал скрупулезный поиск. Для деловых людей начало проекта связанно скорее с началом его реализации и началом вложения денежных средств в его выполнение. Концом проекта может быть: завершение работ над его реализацией, то есть ввод проекта в действие; перевод персонала, выполняющего проект, на другую работу; достижение проектом заданных результатов; прекращение финансирования проекта. Понятие жизненного цикла ее программного обеспечения (ЖЦ ПО) - это непрерывный процесс, который начинается с момента принятия решения о необходимости его создания и заканчивается в момент его полного изъятия из эксплуатации. Согласно сложившейся практике, состояния, через которые проходит проект, называют фазами (этапами, стадиями). Деление проекта на фазы может быть самым разнообразным, такое деление выявляет некоторые важные контрольные точки «вехи», во время прохождения которых просматривается дополнительная информация и оцениваются возможные направления развития проекта. В свою очередь каждая выделенная фаза (этап) может делиться на фазы следующего уровня (подфазы, подэтапы) и т.д. Применительно к очень крупным проектам, количество фаз и этапов их реализации может быть увеличено. Выделение дополнительных этапов связанно с необходимостью более тщательного согласования действий. Наряду с организацией хранения документов, их необходимо также быстро и эффективно искать. Со скоростью поиска все относительно понятно - чем быстрее вы найдете необходимые документы, тем лучше. А вот с эффективностью поиска документа ситуация не так проста. Что считать эффективным поиском? Для того чтобы понять это, рассмотрим модели поиска. Здесь существует два подхода. Первый состоит в том, что в процессе поиска вы ищете документ, который точно существует в системе, и ваша задача - свести процесс к его нахождению. Этот метод применяется в 90% всех случаев. Второй подход состоит в том, что вы ищете все документы, которые могут относиться к интересующему вас вопросу. Очевидно, применение данного подхода целесообразно в аналитических и исследовательских задачах. Для него характерны такие термины, как полнота поиска - соответствие между найденными документами по данному запросу и действительному списку документов; шум при поиске - соотношение (соответствие) соответствующих и несоответствующих запросу документов. Существует два основных типа поиска. Атрибутивный, когда каждому документу присваивается набор определенных атрибутов (полей). При сохранении документа в архив поля заполняются определенными значениями, в дальнейшем при поиске проверяется совпадение значений этих полей запросу. К атрибутам документа можно отнести имя документа, время создания, автора, машинистку, имя подразделения, тип документа (факс, письмо, контракт, спецификация). Ясно, что список таких атрибутов должен быть расширяем. Их совокупность называется карточкой документа. Поля могут заполняться произвольно или из предопределенных справочников. Причем последнее наиболее предпочтительно, так как сужает области поиска. Второй тип поиска носит название полнотекстовый. В этом случае автоматически обрабатывается все содержание, как правило предварительно проиндексированного, документа, и затем его можно найти по любому входящему в него слову. Соответственно, существует зависимость между типами поиска и подходами к поиску. Для поиска известного документа более пригоден атрибутивный поиск, тогда как для исследовательского - полнотекстовый. Существует комбинация полнотекстового и атрибутивного поиска, когда атрибуты документа обрабатываются так же, как все содержание документа. Полнотекстовый поиск зависит от формата документа и языка, на котором он создан. Электронный документ любого формата необходимо предварительно преобразовывать в плоский текст для обработки системой полнотекстового поиска, следовательно, любая такая система должна содержать в своем составе конвертеры форматов. Зависимость от языка выражается в следующих факторах. Поиск документа более полный, если в результате запроса будут найдены не только документы, которые точно соответствуют слову в запросе, но и те, в которых присутствуют различные его словоформы. Данная технология носит название нормализации. Причем эффективность метода зависит от применяемого алгоритма. Для русского языка наиболее эффективен словарный метод, когда слово нормализуется на основе словарей, в которых содержатся словоформы. Кроме словарного может применяться эвристический метод нормализации, когда слово может быть приведено к нормальному виду путем выполнения определенных правил, описывающих алгоритм нормализации. Если для английского языка свод правил нормализации составляет 300 страниц машинописного текста, то для русского он на несколько порядков больше. Аналогично нормализации было бы логично выполнять поиск не только по конкретному слову, но и его синонимам. Процессом, аналогичным индексации, в бумажном делопроизводстве является регистрация. Регистрация является "священной коровой" делопроизводства. Историческая неразвитость системы управления в сочетании с большими расстояниями и традиционно низкой ответственностью исполнителей породила своеобразный, скрупулезный подход к регистрации документов на всех уровнях управления. Хрестоматийным примером может послужить журнал учета входящих документов. Индексация электронных документов, осуществляемая системами автоматизации делопроизводства, преследует несколько иную цель – получить максимальное количество достоверной информации о формируемом документе и создать его регистрационную карточку. Процесс этот тем более важен, что в дальнейшем система управления документами имеет дело именно с этой карточкой, не затрагивая реальные объекты файловой системы. Далее мы в общих чертах рассмотрим известные методы индексации. Итак, на основе вышесказанного становится очевидным то, что успешный поиск документа во многом зависит от реализованного в системе метода индексирования документов. Рассмотрим основные положения индексирования. Индексирование документа обычно организуется через автоматическую обработку его текста и заполнение метаданных. Автоматическая обработка – полнотекстовое индексирование – заключается в преобразовании текста документа в набор слов. Причем обычно для слов сохраняется их позиция в документе, для обеспечения возможности поиска по словосочетаниям. Существуют два принципиально различных метода такого индексирования с учетом применяемых в дальнейшем методов поиска: бинарное индексирование – не зависит от языка документа по причине бинарной или словарной индексации; морфологическое индексирование – производится с учетом морфологии и семантики языка. При бинарном индексировании поиск ведется на основе алгоритмов “нечеткого поиска”, т.е. поиска с ошибками. В этом случае допускается неполное (с заданным количеством ошибок в начале, середине и конце слова) совпадение слов с шаблоном. При втором методе индексации слова преобразуются в словоформы с отсечением суффиксов и окончаний, что позволяет искать склонения и спряжения шаблонов. Стандарта на метаданные на текущий момент не существует, но обычно они включают по крайней мере дату создания документа, его размер, возможно, тип и автора, краткое содержание – аннотацию и ключевые слова. Стоит отметить, что последние поля (аннотация и ключевые слова) на сегодняшний день заполняются вручную. При этом, если формат документа их предусматривает и автор их заполнил, то все неплохо, но практически всегда в реальных документах они отсутствуют. Поэтому существующие сегодня системы документооборота их обычно игнорируют по причине крайне дорогого и медленного их заполнения оператором, вводящим документы в систему. Векторная и линейная модель индексирования и поиска документов. Ниже приведен разработанный алгоритм процесса индексирования документа. Присвоение документу уникального идентификатора, внесение в файл идентификаторов: Определение формата документа. Определение кодировки документа. Перевод текста в «плоский» формат. Определение единицы поиска. Выделение отдельных слов. Выделение отдельных предложений. Исключение из запроса шумовых слов. Составление (пополнение) индекса определенного формата. При индексировании нового документа в уже существующий индекс напротив слов добавляется идентификатор нового документа и номера данного слова в нем. При этом идентификаторы документов сортируются в соответствии с количеством вхождений слова в документ. Таким образом, приведенный выше алгоритм обеспечивает составление единогоиндекса для всех индексируемых документов, что существенно уменьшает объем занимаемого индексами дискового пространства, а также уменьшает время, затрачиваемое на поиск документа. В модели информационного потока вообще можно выделить несколько основных понятий: словарь, документ, поток и процедуры поиска и коррекции запросов. Под словарем понимают упорядоченное множество терминов, мощность которого обозначают как D. Документ - это двоичный вектор размерности D. Если термин входит в документ, то в соответствующем разряде этого двоичного вектора проставляется 1, в противном же случае - 0. Обычно все операции в линейной модели индексирования и поиска документов выполняются над поисковыми образами документов, но при этом их как правило называют просто документами. Информационный поток или массив L представляют в виде матрицы размерности NxD, где в качестве строк выступают поисковые образы N документов. При таком рассмотрении можно сформулировать процедуру обращения к информационной системе по формуле (1). |