Спортивная метрология как учебная дисциплина. Основы теории спортивных измерений
 Скачать 192.69 Kb. Скачать 192.69 Kb.
|

|
ЛЕКЦИЯ 4. Тема: Взаимосвязь результатов измерения. Методы вычисления коэффициентов взаимосвязи. Вопросы для рассмотрения: 1. Виды взаимосвязи. 2. Основные задачи корреляционного анализа. 3. Коэффициент корреляции и его свойства. 4. Методы вычисления коэффициентов взаимосвязи. 1. В спортивных исследованиях между изучаемыми показателями часто обнаруживается взаимосвязь. Вид ее бывает различным. Например, определение ускорения по известным данным скорости в биомеханике, закон Фехнера в психологии, закон Хилла в физиологии и другие характеризуют так называемую функциональную зависимость, или взаимосвязь, при которой каждому значению одного показателя соответствует строго определенное значение другого. К другому виду взаимосвязи относят, например, зависимость веса от длины тела. Одному значению длины тела может соответствовать несколько значений веса и наоборот. В таких случаях, когда одному значению одного показателя соответствует несколько значений другого, взаимосвязь называют статистической. Изучению статистической взаимосвязи между различными показателями в спортивных исследованиях уделяют большое внимание, поскольку это позволяет вскрыть некоторые закономерности и в дальнейшем описать их как словесно, так и математически с целью использования в практической работе тренера и педагога. Среди статистических взаимосвязей наиболее важны корреляционные. Корреляция заключается в том, что средняя величина одного показателя изменяется в зависимости от значения другого. 2. Статистический метод, который используется для исследования взаимосвязей, называется корреляционным анализом. Основной задачей его является определение формы, тесноты и направленности взаимосвязи изучаемых показателей. Корреляционный анализ позволяет исследовать только статистическую взаимосвязь. Он широко используется в теории тестов для оценки их надежности и информативности. Различные шкалы измерений требуют разных вариантов корреляционного анализа. Анализ взаимосвязи начинается с графического представления результатов измерений в прямоугольной системе координат. Строится график, на оси абсцисс которого откладываются результаты X, а на оси ординатрезультаты Y. Таким образом, каждая пара результатов в прямоугольной системе координат будет отображаться точкой. Полученная совокупность точек обводится замкнутой кривой. Такая графическая зависимость называется диаграммой рассеивания или корреляционным полем. Визуальный анализ графика позволяет выявить форму зависимости (по крайней мере, сделать предположение). Если форма корреляционного поля близка к эллипсу, такую форму взаимосвязи называют линейной зависимостью или линейной формой взаимосвязи. Однако, на практике можно встретить и иную форму взаимосвязи. Зависимость, экспериментально полученная при подачах в теннисе, является характерной для нелинейной формы взаимосвязи, или нелинейной зависимости. Таким образом, визуальный анализ корреляционного поля позволяет выявить форму статистической зависимостилинейную или нелинейную. Это имеет существенное значение для следующего шага в анализевыбора и вычисления соответствующего коэффициента корреляции. 3. Если измерения происходят в шкале отношений или интервалов и наблюдается линейная форма взаимосвязи, для количественной оценки тесноты взаимосвязи используется коэффициент корреляции Бравэ-Пирсона. Обозначается буквой r. Вычисляется по формуле: 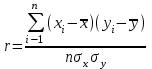 , ,где 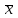 и и 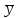 – средние арифметические значения показателей x и y; σx и σy – средние квадратические отклонения; n – число измерений (испытуемых). – средние арифметические значения показателей x и y; σx и σy – средние квадратические отклонения; n – число измерений (испытуемых).Его свойства: 1) Значения r могут изменяться от –1 до 1. 2) В случае r=-1 и r=1 взаимосвязь функциональная, соответственно, отрицательная и положительная. 3) При r=0 линейная взаимосвязь не установлена, но при этом может наблюдаться взаимосвязь другой формы. 4) При r<0 взаимосвязь отрицательная, при r>0 – положительная. Для оценки тесноты взаимосвязи в корреляционном анализе используется значение (абсолютная величина) коэффициента корреляции. Абсолютное значение любого коэффициента корреляции лежит в пределах от 0 до 1. Объясняют (интерпретируют) значение этого коэффициента следующим образом: коэффициент корреляции равен 1,00 (функциональная взаимосвязь, т.к. значению одного показателя соответствует только одно значение другого показателя); коэффициент корреляции равен 0,990,7 (сильная статистическая взаимосвязь); коэффициент корреляции равен 0,690,5 (средняя статистическая взаимосвязь); коэффициент корреляции равен 0,490,2 (слабая статистическая взаимосвязь); коэффициент корреляции равен 0,190,01 (очень слабая статистическая взаимосвязь); коэффициент корреляции равен 0,00 (корреляции нет). 4. Прежде, чем начать механическую процедуру вычисления коэффициента корреляции, необходимо ответить на некоторые вопросы: 1) В какой шкале измеряется изучаемый показатель? 2) Как много измерений этого показателя выполнено? 3) Можно ли считать ряд измерений показателя выборкой, имеющей нормальный закон распределения? И т.д. От ответов на эти вопросы зависит, какой именно коэффициент взаимосвязи будет вычисляться. В частности, в том случае, когда измерения проводятся в шкале интервалов или отношений, для оценки тесноты взаимосвязи вычисляют коэффициент корреляции Бравэ-Пирсона; в ранговой шкале вычисляют ранговый коэффициент корреляции Спирмэна; а в шкале наименований, когда интересующие признак варьирует альтернативно, используют тетрахорический коэффициент сопряженности. Ранговый коэффициент корреляции Спирмэна вычисляют по формуле: 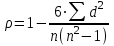 , ,где d=dx-dy – разность рангов данной пары показателей X и Y; n – объем выборки. Применяется, когда показатели измерены в шкале наименований (т.е. им присвоены числа, но нельзя сказать, что один из них больше другого), а показатели варьируют альтернативно (пол мужской/женский, выполнение или невыполнение задания и т.д., иначе говоря, есть два состояния: 0 и 1). Обозначается Т4 и вычисляется по формуле: 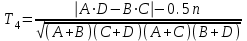 , ,где A – значение, которое соответствует числу испытуемых (попыток), совпадающих по обоим показателям X и Y, т.е. 1 и 1; B – значение, которое соответствует числу совпадений 0 – X и 1 – Y; C – значение, соответствующее числу совпадений 1 – X и 0 – Y; D – значение совпадений 0 и 0; n – объем выборки. Контрольные вопросы для самопроверки: 1. Функциональная взаимосвязь. Определение и примеры. 2. Статистическая взаимосвязь. Определение и примеры. Корреляционная взаимосвязь. 3. Основные задачи корреляционного анализа. 4. Корреляционное поле. Порядок построения, анализ изображения. 5. Направленность взаимосвязи. 6. Коэффициент корреляции Браве-Пирсона и его свойства. 7. Правила выбора коэффициента взаимосвязи. Литература: 1. Основы математической статистики. Уч. пособие для ин-тов физической культуры (под общ. ред. В.С. Иванова). – М.: Физкультура и спорт, 1990. – С. 124 – 126, 142 – 150, 155 – 162. 2. Рукавицына С.Л., Волков Ю.О., Солтанович Л.Л. Спортивная метрология. Проверка эффективности методики тренировки с применением методов математической статистики. Практикум для студентов БГУФК. – Минск: БГУФК, 2006. – С. 42 – 48. 3. Гинзбург Г.И., Киселев В.Г. Расчетно-графические работы по спортивной метрологии. – Минск: БГОИФК, 1984. – С. 51 – 60. ЛЕКЦИЯ 5. Тема: Статистические гипотезы и достоверность статистических характеристик. Сравнение средних арифметических по данным малых выборок. Расчёт и построение доверительных интервалов. Вопросы для рассмотрения: 1. Понятие статистической гипотезы. 2. Принцип проверки гипотез. 3. Алгоритм выбора критерия для сравнения средних арифметических по данным малых выборок. 4. Расчёт и построение доверительных интервалов. 5. Пример сравнения средних арифметических, расчёта и построения доверительного интервала. 1. В физическом воспитании и спорте часто приходится делать вывод об общих закономерностях проявления какого-либо показателя: нормально или нет распределены результаты измерений этого показателя в генеральной совокупности, отличается ли среднее арифметическое значение результатов измерения в генеральной совокупности после тренировок от аналогичного параметра до тренировок, а обнаруженное расхождение между результатами не выходит за пределы случайных ошибок (эффективна или нет методика тренировок), отличается ли дисперсия генеральной совокупности результатов измерения показателя после тренировок от такого же показателя до тренировок (изменилась или нет стабильность результатов спортсмена) и т.д. Так как указанные выводы делаются на основании относительно небольшого числа результатов измерения показателя (n = 30), необходима проверка достоверности (бесспорности) таких выводов. Для этого применяются статистические гипотезы. Статистической гипотезой называется предположение о свойстве генеральной совокупности, которое можно проверить, опираясь на данные выборки. Статистическую гипотезу обозначают символом H. Обычно выдвигают и проверяют две противоречащие друг другу гипотезы: нулевую (основную) H0; конкурирующую (альтернативную) H1. Примеры статистических гипотез: 1) Нулевая гипотеза H0: закон распределения результатов измерения является нормальным. Конкурирующая гипотеза H1: закон распределения результатов измерения отличен от нормального. 2) Нулевая гипотеза H0: среднее арифметическое значение генеральной совокупности результатов измерения показателя после цикла тренировок не изменилось. Конкурирующая гипотеза H1: среднее арифметическое значение увеличилось. 2. Для проверки выдвинутых нулевых гипотез применяют статистические критерии, разработанные математиками и носящие, как правило, их имена. Статистическим критерием называют определенное правило, задающее условия, при которых проверяемую нулевую гипотезу следует либо отклонить, либо принять. При отклонении нулевой гипотезы принимается конкурирующая. Критерий обозначается буквой К. Значение критерия, вычисленное по данным выборки, называют наблюдаемым значением критерия (Кнабл). Совокупность значений критерия, при которых отвергают нулевую гипотезу, называют критической областью. Совокупность значений критерия, при которых нулевую гипотезу принимают, называют областью принятия гипотезы (областью допустимых значений). Указанные области разграничены критическим (граничным) значением критерия, который находится по соответствующей таблице. Односторонняя критическая область используется, если, согласно конкурирующей гипотезе, одна рассматриваемая величина может быть только больше (или только меньше) другой величины. Двусторонняя критическая область используется, если, согласно конкурирующей гипотезе, одна рассматриваемая величина может быть как больше, так и меньше (не равна) другой. Отклонение нулевой гипотезы, когда она фактически верна, называется ошибкой первого рода. Принятие нулевой гипотезы, когда фактически она не верна, называется ошибкой второго рода. Уровень значимости – это вероятность попадания критерия К в критическую область, если верна нулевая гипотеза, другими словами, уровень значимости – это вероятность ошибки первого рода. Он служит для определения по таблицам критических значений критерия (Ккрит), которые указывают положение критических точек, отделяющих критическую область от области принятия гипотезы. Обычно величина выбирается малой. Поэтому попадание критерия К в критическую область при справедливости нулевой гипотезы мало вероятно. В этом случае, при попадании критерия К в критическую область считают, что должна быть принята конкурирующая гипотеза. Часто принимают равной 0,05. Это означает, что вероятность ошибочно принять гипотезу H1, если справедлива гипотеза H0, равна только 5 %. Сформулируем основные этапы проверки статистических гипотез: 1) Исходя из задач исследования, формулируются статистические гипотезы. 2) Выбирается уровень значимости, на котором будут проверяться гипотезы. 3) На основе выборки, полученной из результатов измерения, определяется статистическая характеристика гипотезы. 4) Определяется критическое значение статистического критерия по соответствующей таблице на основании выбранного уровня значимости и объема выборки. 5) Вычисляется наблюдаемое (фактическое) значение статистического критерия. 6) На основе сравнения наблюдаемого и критического значения критерия в зависимости от результатов проверки нулевая гипотеза либо принимается, либо отклоняется в пользу альтернативной. Для проверки статистических гипотез используются параметрические и непараметрические методы. Параметрические методы служат для проверки гипотез о неизвестных параметрах генеральной совокупности, когда закон распределения случайной величины известен. Непараметрические методы применяются в тех случаях, когда закон распределения случайной величины неизвестен, или когда условия применения параметрических методов не выполняются. Параметрические методы эффективнее непараметрических. Перейдем к ознакомлению с основными положениями теории надежности тестов. 3. В математической статистике разработан ряд критериев (параметрических и непараметрических) для сравнения средних арифметических. Выбор критерия зависит от следующих условий: 1) объёма выборки (большие или малые); 2) законов распределения исследуемых совокупностей (нормальные, другие); 3) степени независимости выборок (зависимые, независимые); 4) известны или неизвестны генеральные дисперсии; 5) одинаковы или различны генеральные дисперсии; 6) возможна ли количественная или только качественная оценка рассматриваемого явления. К параметрическим критериям для сравнения двух средних арифметических относятся критерии t для независимых и попарно зависимых выборок, имеющие распределение Стьюдента, а также критерий z, имеющий нормальное распределение. Последний разработан для сравнения двух средних арифметических независимых нормальных генеральных совокупностей, дисперсии которых известны. Так как в задачах из области физической культуры и спорта дисперсии генеральных совокупностей обычно неизвестны, критерий z для малых выборок не используется. Его рекомендуется использовать в качестве приближённого критерия для сравнения больших независимых выборок, имеющих любой закон распределения, так как для больших выборок (n≥30) выборочные средние арифметические распределены приближённо нормально, а выборочные дисперсии приближённо равны генеральным дисперсиям. Из существующих непараметрических критериев наиболее мощными являются X-критерий Ван дер Вардена для независимых выборок и U-критерий Уилкоксона для попарно зависимых выборок. При сравнении средних независимых выборок рекомендуется поступать следующим образом: 1) Каждая в отдельности выборка проверяется на нормальность распределения по критерию Шапиро и Уилка 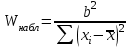 . .В случае, если обе выборки распределены нормально, следует переходить к следующему пункту, в противном случае – к п. 4. 2) Сравниваются дисперсии выборок 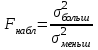 . .В случае равенства дисперсий следует переходить к следующему пункту, в противном случае – к п. 4. 3) Для сравнения средних арифметических используется критерий Стьюдента 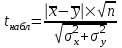 . .Сравнение окончено. 4) Для сравнения средних арифметических используется критерий Ван дер Вардена 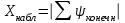 . .Сравнение окончено. При сравнении средних попарно зависимых выборок рекомендуется поступать следующим образом: 1) Составляется выборка разностей парных значений 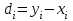 . .2) Составленная выборка проверяется на нормальность распределения по критерию Шапиро и Уилка. В случае, если выборка распределена нормально, переходим к следующему пункту, в противном случае – к п. 4. 3) Для сравнения средних арифметических используется критерий Стьюдента 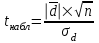 . .Сравнение окончено. 4) Для сравнения средних арифметических используется U-критерий Уилкоксона. Сравнение окончено. 4. По найденным характеристикам выборки судят о неизвестных характеристиках генеральной совокупности. Очевидно, что в общем случае они не будут точно совпадать друг с другом: истинное значение характеристики может быть больше или меньше выборочного значения характеристики *. Чтобы статистически оценить искомое истинное значение характеристики , поступают следующим образом: 1) Задаются некоторой достаточно большой вероятностью p (например, p = 0,9; 0,95; 0,99; 0,999), чтобы событие, заключающееся в нахождении искомого значения с этой вероятностью в соответствующем интервале можно было считать статистически достоверным. Эту вероятность называют доверительной вероятностью. В спортивных исследованиях обычно принимают p = 0,95 (иногда 0,99).  2) Затем для заданной величины p рассчитывают по формулам математической статистики нижнюю 1 и верхнюю 2 границы интервала Jp. Доверительным интервалом Jp называют случайный интервал (1, 2), который накрывает неизвестную характеристику с доверительной вероятность p. Границы доверительного интервала Jp называют: 1 = * - 1нижней доверительной границей; 2 = * - 2верхней доверительной границей. Значения 1 и 2 могут совпадать (при симметричном распределении *) и быть разными (при несимметричном распределении *). Они характеризуют точность, а вероятность pнадежность определения . Между надежностью и точностью существует обратная зависимость: чем выше надежность, тем ниже точность определения и наоборот. С увеличением числа измерений при заданном p повышается точность определения (уменьшаются 1 и 2). Для точного расчета границ доверительного интервала необходимо знать закон распределения выборочной характеристики *. Задача определения доверительных интервалов для оценки генерального среднего арифметического значения xг нормального распределения решена математической статистикой для следующих двух случаев: а) генеральная дисперсия известна; б) генеральная дисперсия неизвестна. Рассмотрим второй случай. В этом случае искомое генеральное среднее арифметическое находится в следующем доверительном интервале: 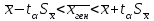 , ,где – среднее арифметическое значение выборки; t – величина, которая находится по таблицам распределения Стьюдента в зависимости от числа степеней свободы k = n - 1, уровня значимости ; 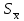 – стандартная ошибка среднего арифметического, рассчитывается по формуле: – стандартная ошибка среднего арифметического, рассчитывается по формуле: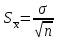 . .Примечание: В практике научных исследований, когда закон распределения малой выборочной совокупности (n < 30) неизвестен или отличен от нормального, пользуются вышеприведенной формулой для приближенной оценки доверительных интервалов. |