курсовая с. КУРСОВАЯ с++ ПЕРВАЯ ПРАВКА. Разработка программы, реализующей алгоритмы сортировки и поиска
 Скачать 0.55 Mb. Скачать 0.55 Mb.
|

|
НАО «Карагандинский технический университет имени Абылкаса Сагинова» Кафедра информационных технологий и безопасности КУРСОВОЙ ПРОЕКТ По дисциплине «Программирование на С++» (наименование дисциплины) Тема: «Разработка программы, реализующей алгоритмы сортировки и поиска» Принял: ______________ ст.преподаватель Солодовникова И.В. (оценка) (фамилия, инициалы) _________________________ (подпись) (дата) Члены комиссии: Выполнил: ст.гр.ВТ-21-2 Грызлов С. С. (подпись, фамилия, и.о.) (фамилия, инициалы) ___________21/6-68__________ (подпись, фамилия, и.о.) (шифр зач. книжки) Караганда 2022 НАО «Карагандинский технический университет имени Абылкаса Сагинова» Факультет ИТ «УТВЕРЖДАЮ»  Кафедра ИТБ Зав. кафедрой Кафедра ИТБ Зав. кафедрой(подпись) «» _________ 2022г ЗАДАНИЕ НА КУРСОВОЙ ПРОЕКТ по дисциплине «Программирование на С++» Студенту Грызлову С.С. группы ВТ-21-2 Тема: Разработка программы, реализующей алгоритмы сортировки и поиска Исходные данные: Задание к индивидуальному варианту №6 и методические указания к выполнению курсового проекта Задание выдано «____» ______________ 2022 года.  Руководитель Солодовникова И.В. подпись______________ Руководитель Солодовникова И.В. подпись______________Студент Грызлов С.С. подпись______________ Содержание: Введение 4 1 Теоретический материал 5 Структуры данных 5 Методы сортировки 8 Методы поиска 11 2 Список очередь 12 2.1 Генерация очереди 12 2.2 Вывод очереди 13 2.3 Добавление и удаление элементов 14 2.4 Сортировка очереди попарным слиянием 15 2.5 Поиск элемента в очереди 17 2.6 Сохранение очереди в файле. Считывание очереди из файла 18 3 Массив 20 3.1 Генерация массива 20 3.2 Сортировка массива 21 3.3 Интерполяционный поиск в массиве 23 3.4 Бинарный поиск в массиве 23 Заключение 25 Список литературы 26 Приложение А. Блок-схема нахождения максимального значения 27 Приложение Б. Блок-схема алгоритма “Сортировка подсчетом” 28 Приложение В. Блок схема “Поразрядная сортировка” 29 Приложение Г. Код программы обработки списка 30 Приложение Д. Код программы обработки массива 34 Введение На сегодняшний день, невозможно оспорить важность изучения работы с структурами данных, которая заключается в алгоритмах обработки этих же структур, а также их изменению и использованию, как самих структур, так и логических данных, находящихся в этих структурах. Практически в каждой сфере, связанной с профессиями, невозможно обойтись без структурирования и упорядочения различных данных, нужно максимально эффективно организовать этот процесс, используя минимальные затраты времени и сил. Одни структуры используются для баз данных, другие для словарей, третьи вовсе для данных, имеющих организацию структуру в форме дерева, от более важных данных, к менее важным. Не менее важны также алгоритмы обработки, от них зависят скорость и удобство работы с такими данными. Благодаря непрерывному развитию и исследованиям, были выявлены множество различных методов сортировки и поиска по структурам данным, одни способы появились намного раньше других, одни просты в использовании, но и с тем же неэффективны, в отличие от других, более поздних и более совершенных. И на этом поиск наилучших методов не останавливается, будут созданы новые способы, совершенно отличающихся по принципам от более старых, либо же, эффективные методы, основанных на использовании принципов нескольких методов сортировки. Только объединяя лучшие качества этих способов, люди придут к наилучшим методам работы с различными структурами данных. В этой курсовой работе будут рассмотрены способы сортировки и поиска в различных структурах данных, недостатки и достоинства определенных методов сортировки и поиска, описание алгоритмов и функций, а также выполнение поставленной задачи, которая заключается в создании программы, способной выполнять функции сортировки и поиска по заданному списку, реализовать дополнительные функции, приведенные в задании к курсовой работе, такие как добавление и удаление элементов из структуры данных. Целью курсовой работы является получение и закрепление навыков для работы с структурами данных, реализации алгоритмов обработки их, а также изучение и реализация алгоритмов сортировки данных, исследование эффективности разных методов сортировок. Также, очень пригодятся изучение и реализация алгоритмов поиска по структурным данным разных типов, ведь не организовав поиск данных по массивным структурам, будет невозможно выполнить проверку или изменение данных в них же. Данная, в курсовой работе, программа, должна выполнять все требуемые от нее задачи – сортировка, поиск, добавление и удаление элементов, загрузка данных из структуры данных, именующейся файлом. 1 Теоретический материал 1.1 Структуры данных Существует довольно много типов структур данных, но выделяют только основные: 1. Массив (Array) 2. Стек (Stack) 3. Очередь (Queue) 4. Связный список (Linked List) 5. Граф (Graph) 6. Дерево (Tree) 7. Хэш-таблица (Hash Table) Каждый из этих типов структур данных имеет свои свойства и характеристики, одни произошли от других, либо же уникальны. 1. Массив — это самая простая и самая распространенная структура данных. Ее использование не ограничено типами данных, хранить можно практически что угодно, массив представлен в виде некоей последовательности данных, каждая из частей представляет собой ячейку. Каждая ячейка имеет собственный индекс, который показывает позицию элементов в массиве. Значение индекса является уникальным, и не повторяется дважды в массиве. Выделяют два типа массивов – это одномерные и многомерные. Одномерные массивы представляют простую последовательность данных, в ней данные следуют строго друг за другом. В отличие от одномерных, многомерные массивы представляют собой более сложную организацию хранения данных, в качестве примера можно взять двумерные массивы, которые имеют форму матрицы, состоящей из строк и столбцов. Первый индекс в таких массивах, указывает индекс строки, а второй же индекс, индекс столбца. Двумерный массив по структуре представляет собой последовательность одномерных массивов. Трехмерный массив также представляет собой уже последовательность двумерных массивов. Такой способ организации данных довольно распространен, и широко используется. В качестве примеров двумерного массива, можно представить комод, с ящиками расположенными друг над другом [1]. 2. Стеки – это разновидность массива, которая работает по принципу LIFO (Last In First Out), то есть, последним пришел – первым ушел. Данный тип массивов можно рассмотреть, как пачку тетрадей, расположенных друг над другом. Чтобы получить доступ к тетрадям в середине стопки, нужно будет удалить все тетради, расположенные выше требуемой. Данные типы массивов позволяют реализовать принцип отмены действий, когда последние совершенные действия можно обратить первыми. 3. Очереди – разновидность массива, которая также последовательно хранит данные, но ее отличием от стека является совершенно другой метод, не LIFO, а FIFO (First In First Out), то есть, первым пришел - первым ушел. Идеальный пример такого расположения элементов – очереди людей, очередь выполнения задач. В таких массивах первые добавленные элементы, также будут удалены первыми, а последние – последними. Добавление идет с конца очереди. 4. Более сложными структурами данных являются связные списки. Такие списки, хоть и похожи на массивы, но имеют свои особенности, такие как дистрибутивность памяти, организация данных внутри структуры, а также принципиально отличными от вышеуказанных, способами удаления и вставки элементов. Связный список – это узлы, связанные между собой односторонне, или многосторонне, и каждый узел содержит данные, и ссылки, которые указывают либо на следующий, либо на предыдущий, либо на те и другие узлы в списке. Данная структура данных имеет преимущество перед массивами – добавление и удаление элементов значительно упрощается (элементы могут добавляться как в начало, так и в конец, или вовсе в середину списка), и порядок элементов не является строго упорядоченным, один узел может указывать на совершенно другой узел, не следующий за первым. Структуры данного типа могут иметь строго указанные начало и конец, либо вовсе не иметь их. Списки без строго указанных начала и конца, называются кольцевыми, и являются замкнутыми, последний элемент указывает на первый и наоборот. В односвязных списках указатели на элементы идут только в одном направлении, в отличие от двусвязных, в которых каждый элемент может указывать и на предыдущий, и на следующий элементы. Однако такие списки имеют и недостатки: сложность получения доступа к конкретным элементам, дополнительный расход памяти на указатели, некоторые операции существенно замедляются из-за сложности обращения к некоторым элементам списка [2]. 5. Граф – структура данных, которая выглядит как некий набор узлов, соединенных между собой в виде сети. Каждый узел также может называться вершиной. На рисунке 1 A, B, C соединены между собой, последовательно. Вершины соединены между собой с помощью ребер, каждое ребро может содержать определенный вес, который показывает, сколько усилий должно быть затрачено, чтобы пройти от A до B, от B до C. Существует два типа графа – ориентированный и неориентированный. Неориентированным граф называется, ребра которого не имеют направления. Графы используются в программировании для описания систем, у которых в наличии сложные связи. 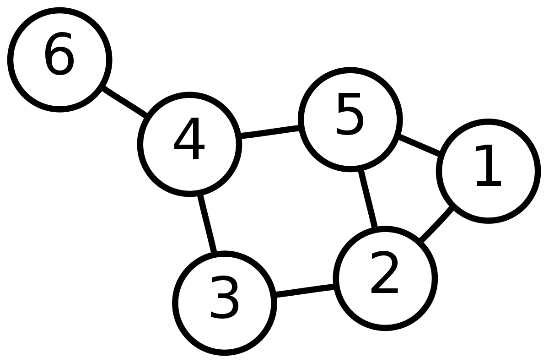 Рисунок 1 – Граф 6. Дерево – структура данных, имеющая иерархию, состоит из узлов и ребер, соединяющих их. Единственным, но важным отличием дерева от графа является невозможность циклического соединения в структуре данных. Такой принцип построения структуры данных используется в искусственном интеллекте и сложных алгоритмах, чтобы максимизировать эффективность хранения данных. Самым распространенным типом дерева является B-дерево, или иначе – бинарное дерево. Данные деревья имеют множество ветвей, ведущих к конкретным элементам структуры данных, имеют уровни данных. B-дерево является мультисписочной структурой страниц памяти, каждому узлу соответствует блок памяти(страница). Такой тип структуры на сегодняшний день применяется для организации индексов во многих современных системах управления баз данных. На рисунках 2-3 представлены примеры структуры данных, именующийся деревом. 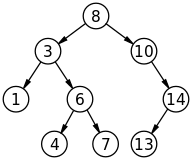 Рисунок 2 - Дерево  Рисунок 3 – Дерево Хеш-таблица – это структура данных, которая реализует хранение пар, содержащих ключ и значение. Благодаря хранению этих самых пар, операции добавления, удаления, и поиска элементов значительно упрощаются, и осуществляются по ключу. Преимуществом хеш-таблиц является скорость и удобство работы с данными, и операции выполняются в среднем за O(1), что довольно быстро. Недостатком хеш-таблиц является появление коллизий. Коллизия возникает, когда у двух разных элементов таблицы хеш-адрес будет одинаковым, что может привести к ошибкам и замедлению работы с хеш-таблицами. В таком случае, нужно сводить появление коллизий к минимуму, и для этого придумали множество способов: метод цепочек (попадание элементов с одинаковым хешем в одну ячейку в виде списка), открытая индексация (хранение пары ключ-значение в хеш-таблице непосредственно, алгоритм вставки проверяет ячейки до тех пор, пока не будет найдена пустая ячейка). 1.2 Методы сортировки Алгоритмом сортировки называют алгоритм, выполняющий функцию упорядочивания элементов в массиве. На сегодняшний день существует множество типов сортировки элементов, с разными подходами к выполнению задачи. Основными характеристиками таких алгоритмов сортировки являются: время, память. Время может также называться вычислительной сложностью, и оно характеризует быстродействие сортирующего алгоритма. А память же, требуется для некоторых алгоритмов сортировки, требующих дополнительного выделения памяти для операций. Такие методы сортировки обычно требует O(log n) памяти. Теперь о методах сортировки. Выделяют основные методы сортировки: 1. Сортировка выборкой. 2. Сортировка пузырьком. 3. Сортировка шейкером (перемешиванием). 4. Сортировка вставками. 5. Сортировка Шелла. 6. Быстрая сортировка. 7. Сортировка слиянием. 8. Сортировка подсчетом. 9. Поразрядная сортировка. Каждый из этих методов сортировки реализует решение задач разным подходом и способами. 1. Сортировка выборкой реализует алгоритм полного прохождения списка и нахождения минимального значения в этом же списке, а затем обмен минимального значения с значением первой позиции. Далее сортируются следующие после первого элемента, отсортированные значения уже не затрагиваются. Преимуществом такого алгоритма сортировки является надежность и стабильность, простота реализации. Недостатком же является сравнительно малая скорость сортировки, по сравнению с другими методами. Затрачиваемое время сортировки данных – O(n2). 2. Сортировка пузырьком реализует алгоритм сравнения пар значений при полном прохождении списка, если первое значение больше второго в паре, происходит обмен этих же значений. Максимальные отсортированные значения в итоге оказываются в конце списка, и не затрагиваются при дальнейшей сортировке. Преимуществом такого алгоритма сортировки является простота реализации, а минусом – крайне медленная скорость работы метода, если более мелкие значения находятся в конце списка, то алгоритм затрачивает довольно много времени, чтобы их переместить ближе к началу списка. Затрачиваемое время сортировки данных в лучшем случае – O(n), в худшем случае – O(n2). Хоть и сортировка не используется на данный момент, кроме как в учебных целях, тем не менее, ее принципы используются в сортировке шейкером(перемешиванием). 3. Сортировка шейкером(перемешиванием) реализует алгоритм двунаправленной сортировки, в отличие от пузырьковой, которая реализует только однонаправленную сортировку значений. Принцип сортировки тот же, отличие только в том, что алгоритм перемещается по значениям сначала слева направо, а потом справа налево. В данном случае, устраняется проблема пузырьковой сортировки – медленное время работы, при наличии минимальных значений в конце списка. Ведь при прохождении алгоритмом списка справа налево, эти же значения будут отодвигаться в начало списка. Затрачиваемое время сортировки данных в лучшем случае - O(n), в худшем случае – O(n2). Хоть и теоретически время сортировки совпадает с пузырьковой, однако в реальной работе, и с большими списками, сортировка шейкером показывает себя лучше. 4. Сортировка вставками реализует алгоритм перемещения нужного значения в начало списка, при полном прохождении списка. Данный метод сортировки обрабатывает элементы массива по порядку, все что находится слева от определенного индекса – уже отсортировано. Алгоритм в течение прохождения по списку, сравнивает второе значение с первым, если больше, ничего не делает, если меньше, производит так называемую вставку – вырезает элемент, весь, или часть списка сдвигаются вправо, и вырезанный элемент вставляется на нужное место. И крайнее значение отсортированного списка будет сравниваться с следующими значениями после него. Затрачиваемое время сортировки данных в лучшем случае – O(n) для сравнения, и O(1) для перестановок, а в худшем случае - O(n2) для сравнений и перестановок. Отличие данного метода сортировки от предыдущих заключается в том, что для произведения вставки элементов, нужна дополнительно выделенная память. 5. Сортировка Шелла реализует усовершенствованный алгоритм вставками. Главным его отличием от сортировки вставками – сравнение элементов, стоящих не только рядом, но и на определенном расстоянии. Можно сказать, что это сортировка вставками с “грубыми” проходами, не требующими строгого задания шагов между элементами списка. Затрачиваемое время сортировки данных в лучшем случае - O(nlog2n), в худшем случае O(n2). Данный метод сортировки данных быстрее предыдущих, но медленнее быстрой сортировки, однако у нее есть и преимущества – отсутствие дополнительного потребления памяти, и даже при самых худших условиях, среднее время сортировки слабо изменяется. 6. Быстрая сортировка реализует совершенно иной алгоритм, с своими особенностями. Сначала из списка выбирается один элемент, который является опорным, другие элементы в списке распределяют и сортируют так, чтобы элементы меньше опорного оказались до него, а большие или такие же, после него. Затем, такой же алгоритм применяется рекурсивно для частей списка, находящихся слева и справа от опорного элемента. Такой метод сортировки списка значительно быстрее предыдущих, однако, зависит от выбора опорного элемента, при неправильном выборе, сортировка крайне медленна, и выполняется за O(n2) времени. Наилучшее же время сортировки – O(nlogn). Алгоритм отвечает типу – “разделяй и властвуй” (разделение списка на две части, и сортировка рекурсивно). 7. Сортировка слиянием реализует схожий принцип алгоритма быстрой сортировки. Происходит также деление списка на более мелкие части и сортировка их. Единственное отличие от быстрой сортировки – нет какого-либо опорного элемента, список делится пополам, и этот же процесс совершается рекурсивно для каждой части списка до тех пор, пока не будут отсортированы элементы, а затем эти же элементы будут вставлены обратно в верном порядке. Однако, у такого метода есть значительный минус – алгоритм выполняет все те же действия даже для частично отсортированного списка, что может повлиять на работу над такими списками. При таком раскладе, прочие методы сортировки справятся с списком значительно быстрее, чем сортировка слиянием. Сортировка слиянием использует тот же принцип, что и быстрая сортировка – “разделяй и властвуй”. Затрачиваемое время сортировки данных в лучшем случае – O(nlogn), в худшем случае все также – O(nlogn). Данный алгоритм довольно стабилен, однако он требует дополнительного выделения памяти под подсписки, которые возникают в процессе разделения и сортировки отдельных элементов, причем, процесс выделения памяти происходит постоянно, может произойти перевыделение памяти для списков. 8. Сортировка подсчетом реализует алгоритм с помощью подсчета, используется диапазон чисел сортируемого списка для подсчитывания количества совпадающих элементов. Такой метод применяется только в том случае, если значения подпадающие под алгоритм сортировки подсчетом, имеют сравнительно малый диапазон возможных значений по сравнению с сортируемым множеством. Как пример, сотни тысяч числовых значений, имеющих диапазон от 0 до 100. Обычные алгоритмы сортировки будут затрачивать в разы больше времени, чем сортировка подсчетом, которая каждое значение записывает в список отдельный, и так с каждым последующим значением. Однако, эта же сортировка крайне неэффективна для обычных списков, где диапазон значений схож с количеством их же. 9. Поразрядная сортировка реализует алгоритм сортировки целых числовых значений. Однако, такой алгоритм можно применить и для любых объектов, запись которых возможна с помощью деления на разряды. К этим данным можно отнести цифры, строки с набором символов, произвольные значения в памяти, которые представлены набором байтов. Сравнение в таких алгоритмах происходит с помощью разрядов, то есть, поразрядно, сравниваются значения одного крайнего разряда, и по этому результату сравнения, элементы группируются. Затем, значения следующих разрядов, и соседнего сравниваются, и опять элементы сортируются по порядку. Таким образом, алгоритм проходит до конца, до последнего разряда и сортирует все элементы. Затрачиваемое время сортировки данных в худшем случае – O(w*n), где w – это количество бит, которые требуется для хранения ключа, формула расхода памяти также аналогична [3]. |