4 курс ИБ. 7 модели безопасности основных ос
 Скачать 1.72 Mb. Скачать 1.72 Mb.
|

|
СХЕМА ЭЛЕКТРОННОЙ ПОДПИСИ СООБЩЕНИЯ m: 1 Отправитель А вычисляет пару: kAsecretСЕКРЕТНЫЙ ключ подписывающего (абонента А) и kA public– соответствующий ОТКРЫТЫЙ ключ проверяющего (абонента В). Отправитель А посылает kApublicполучателю В, сохраняя kAsecretв секрете. 2 Для получения подписи документа m отправитель А ВЫЧИСЛЯЕТ ПОДПИСЬ s с помощью алгоритма формирования подписи S от сообщения m на секретном ключе kA secret и посылает сообщение mи подпись s получателю В. 3 Получатель В вычисляет у себя подпись с помощью алгоритма V проверки (верификации) подписи от сообщения m, подписи s на открытом ключе kApublic. В зависимости от результата вычисления, принимает или отвергает подпись s. Классическая СХЕМА СОЗДАНИЯ И ПРОВЕРКИ ЭЛЕКТРОННОЙ ПОДПИСИ показана на рисунке 9.1. 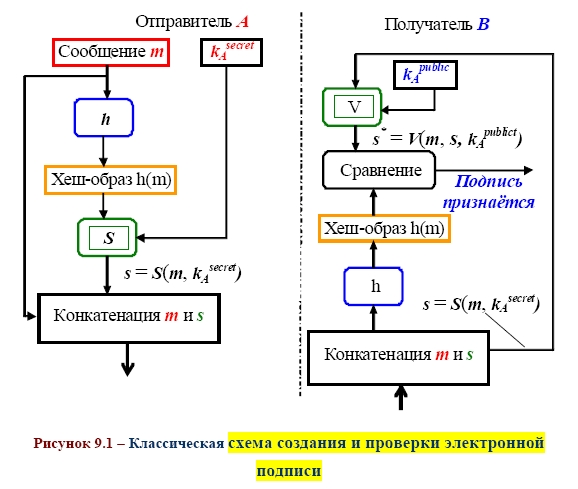 В российском стандарте цифровой подписи используется разработанная отечественными криптографами ХЭШ-ФУНКЦИЯ (256 бит) стандарта ГОСТ Р 34.11–94 (в основе алгоритм блочного шифрования по ГОСТ 28147–89). Стандарт определяет алгоритм и ПРОЦЕДУРУ ВЫЧИСЛЕНИЯ ХЭШ-ФУНКЦИИ ДЛЯ ЛЮБОЙ ПОСЛЕДОВАТЕЛЬНОСТИ двоичных символов, которые применяются в криптографических методах обработки и защиты информации, в том числе для реализации процедур электронной подписи (ЭЦП) при передаче, обработке и хранении информации в автоматизированных системах. Определённая в стандарте функция хэширования используется при реализации систем электронной цифровой подписи на базе ассиметричного криптографического алгоритмапо ГОСТ Р 34.10–94 «Информационная технология. Криптографическая защита информации. Процедуры выработки и проверки электронной цифровой подписи на базе ассиметричного криптографического алгоритма». В общем, хэш-функция h отображает двоичные строки произвольной конечной длины в выходы небольшой (например, 64, 128, 160,192, 224, 256, 384, 512) фиксированной длины [13], называемые хэш-величинами: где {01}* – множество двоичных строк произвольной конечной длины; {01}n – множество двоичных строк длиной n бит, то есть {01}* – это объединение всех множеств Сообщения с произвольной длиной можно сжать, используя хэш-функцию с фиксированным размером входа, при помощи двух методов: – последовательного (итерационного); – параллельного. В ГОСТ Р 34.11–94 использовали первый путь – метод последовательного хэширования, использующий хэш-функцию с фиксированным размером входа 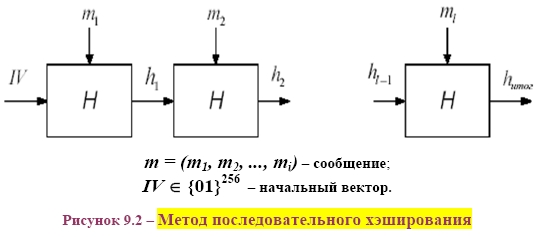 Если необходимо хэшировать сообщение m = (m1, m2, …, mi), то хэширование выполняется следующим образом: Здесь Hi – функция сжатия, а hi– переменная сцепления. Если последний блок меньше, чем n бит, то он набивается одним из существующих методов до достижения длины, кратной n. В отличие от стандартных предпосылок, что сообщение разбито на блоки и произведена набивка последнего блока, если необходимо (форматирование входа априори), до начала хэширования, то в ГОСТ Р 34.11–94 процедура хэширования ожидает конца сообщения (форматирование входного сообщения постериори). Набивка производится следующим образом: последний блок сдвигается вправо, а затем набивается нулями до достижения длины в 256 бит. Алгоритм хэширования по ГОСТ Р 34.11–94 можно классифицировать как устойчивый к коллизиям код (при n = 256, и один из видов атак потребует приблизительно 2256/2 операций хэширования), выявляющий модификации (Collision Resistant Hash Function, CRHF). Также конструкторы предусмотрели ДОПОЛНИТЕЛЬНЫЕ МЕРЫ ЗАЩИТЫ: а) параллельно рассчитываются контрольная сумма, представляющая собой сумму всех блоков сообщения(последний суммируется уже набитым) по правилу A + B [mod 2k], где k = |A| = |B|, а |A| и |B| битовые длины слов A и B соответственно (далее на рисунках и в тексте эта операция будет обозначаться б) параллельно рассчитываются битовая длина хэшируемого сообщения, приводимая по mod 2256 (MD-усиление), которые в финальной функции сжатия используются для вычисления итогового хэша (см. рисунок 9.3). 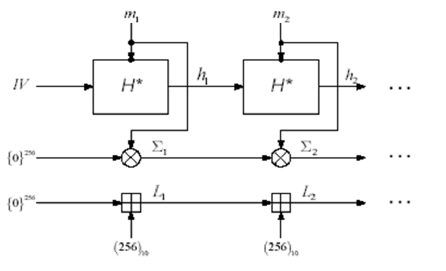 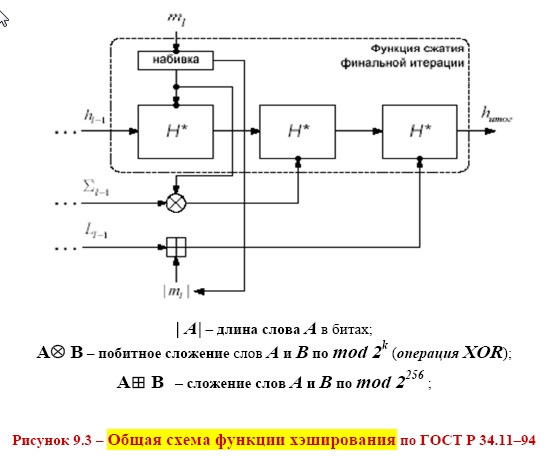 Указывать в передаваемом сообщении, сколько было добавлено нулей к последнему блоку, не требуется, так как длина сообщения участвует в хэшировании (см. рисунок 9.4). 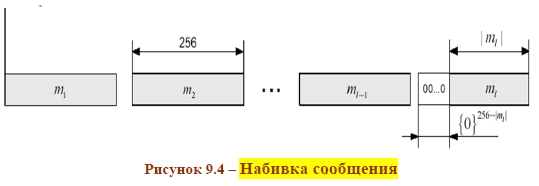 Начальный вектор IV: согласно ГОСТ Р 34.11–94, IV – произвольное фиксированное слово длиной 256 бит (IV ϵ{01}256). Если он априорно не известен верифицирующему целостность сообщения, то он должен передаваться вместе с сообщением с гарантией целостности. При небольших сообщениях можно выбирать IV из небольшого множества допустимых величин. Также он может задаваться в рамках организации, домена, как константа. Каждый входной блок рассматривается как результат конкатенации четырёх 64-разрядных двоичных наборов. Функция сжатия Hiвыполняется в ТРИ шага: 1) генерация четырёх 256-разрядных ключейдля зашифрования в режиме простой замены 64-разрядных частей i-го блока; 2) зашифрование частей блока hi c использованием алгоритма ГОСТ 28147–89; 3) перемешивание результатов зашифрования 9.1 Типовые схемы идентификации и аутентификации пользователя Первая из типовых схем – «С ОБЪЕКТОМ-ЭТАЛОНОМ» [1]: в системе создаётся объект–эталон Ei (используя идентификатор IDi и аутентификатор Ki) для идентификации и аутентификации пользователя. Структура объекта–эталона приведена в таблице 9.1.  Здесь Ei = F(IDi, Ki), где F – функция, обладающая свойством «невосстановимости» значения аутентификатора Kiпо Eiи IDi. Невосстановимость Ki оценивается по пороговой трудоемкости Т0 решения задачи восстановления аутентифицирующей информации Ki по Ei и IDi. Так как для пары Ki и Kjвозможно совпадения значений Е, то вероятность ложной аутентификации не должна быть больше некоторого порогового значения Р0. На практике задают Протокол идентификации и аутентификации следующий: а) пользователь предъявляет свой идентификатор ID; б) если ID = IDi, то пользователь i прошёл идентификацию; в) субъект аутентификации запрашивает у пользователя его аутентификатор Кi; д) субъект аутентификации вычисляет значение Yi = F(IDi, Ki); е) субъект аутентификации сравнивает значения Yiи Ei, и при совпадении пользователь аутентифицирован в системе: информация о нем передается в программные модули, использующие ключи пользователей (систему шифрования, разграничения доступа, и т. п.). Вторая типовая схема – «С МОДИФИЦИРОВАННЫМ ОБЪЕКТОМ–ЭТАЛОНОМ»: в системе также создаётся объект– эталон, таблица 9.2. 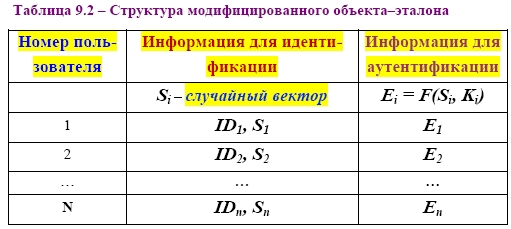 Здесь значение Ei = F(Si, Ki), где Si– случайный вектор, задаваемый при создании идентификатора пользователя. Функция F обладает свойством невосстанавливаемостизначения Kiпо Eiи Si. Протокол идентификации и аутентификации следующий: а) пользователь предъявляет свой идентификатор ID; б) если ID = IDi, то пользователь i прошёл идентификацию; в) по идентификатору IDi выделяется (определяется) вектор Si; д) субъект аутентификации запрашивает у пользователя аутентификатор Кi; е) субъект аутентификации вычисляет значение Yi = F(Si, Ki); ж) субъект аутентификации производит сравнение значений Yiи Eiи при их совпадении пользователь аутентифицирован в системе. Этот метод обычно используется в ОС UNIX, где в качестве идентификатора используется имя пользователя (запрошенное по Login), а в качестве аутентификатора Ki – пароль (запрошенный по Password). Функция F – алгоритм шифрования DES. Эталоны для идентификации и аутентификации содержатся в файле /etc/passwd. Парольная аутентификация имеет пониженную стойкость, так как выбор аутентифицирующей информации происходит из относительно небольшого множества осмысленных слов. Мощность этого множества определяется энтропией языка. 9.2 Взаимная проверка подлинности пользователей Процесс взаимной аутентификации восполняют в начале сеанса связи. Применяют способы «запроса–ответа»; «отметки времени» («временной штемпель»). Механизм «ЗАПРОСА-ОТВЕТА»включает в посылаемое от А к В сообщение непредсказуемый элемент – запрос Х (напр., случайное число). При ответе В должен выполнить над этим элементом некоторую операцию (напр., вычислить некоторую функцию f ( x ). Получив ответ с результатом действий В, можно установить подлинность В. Недостаток метода – возможность установить закономерность между запросом и ответом (иначе будет предсказуемый элемент). Механизм «ОТМЕТКИ ВРЕМЕНИ»выполняет регистрацию времени для каждого сообщения. Можно решить, насколько устарело сообщение и решить принимать или не принимать его, т. к. оно может быть ложным. При использовании отметок времени возникает проблема допустимого временного интервала задержки для подтверждения подлинности сеанса. Ведь сообщение не может быть передано мгновенно, а часы получателя и отправителя не могут быть абсолютно синхронизированы. Для обоих случаев применяют шифрование, чтобы быть уверенным, что ответ послан не злоумышленником. Для ВЗАИМНОЙ ПРОВЕРКИ подлинности используют ПРОЦЕДУРУ «РУКОПОЖАТИЯ». Указанные выше механизмы контроля используются при взаимной проверке ключей. НАПРИМЕР, симметрическая криптосистема с секретным ключом КАВ, рисунок 9.5. Порядок операций следующий. 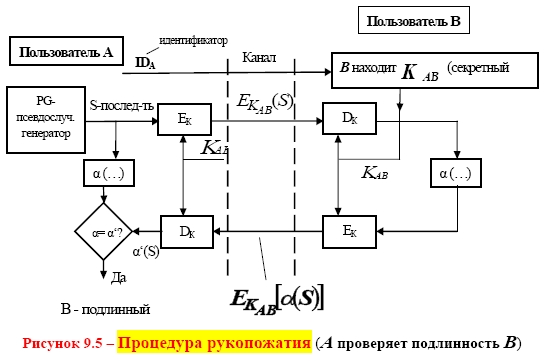 А) А инициирует процедуру рукопожатия и отправляет В свой идентификатор IDАв открытой форме. Б) В, получив свой IDА, находит в базе данных секретный ключ КАВи вводит его в криптосистему. В) Также А генерирует случайную последовательность S с помощью псевдослучайного генератора PG и отправляет её В в виде криптограммы E K AB ( S ). Д) В расшифровывает эту криптограмму и раскрывает последовательность S. Ж) А и В преобразуют последовательность S, используя одностороннюю открытую функцию α (…). И) В шифрует сообщение α(S) и отправляет эту криптограмму для А. К) А расшифровывает эту криптограмму и сравнивает полученное сообщение α‘(S) с исходным α(S). При равенстве сообщений А признаёт подлинность В. В проверяет подлинность А также. Достоинство модели рукопожатияв том, что ни один из участников не получает никакой секретной информации во время процедуры. Если необходима непрерывная проверка подлинности отправителей в течение всего сеанса связи, то можно использовать способ, показанный на рисунке 9.6. 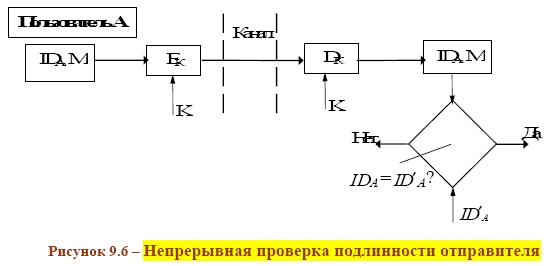 Передаваемая криптограмма имеет вид: EK (IDA, M,) где IDA– идентификатор отправителя А; М– сообщение. В, принявший это сообщение, расшифровывает его и раскрывает пару (IDA, M). Если принятый IDAсовпадает с хранимым ID’A, то В признаёт эту криптограмму. Вместо идентификатора отправителя можно использовать его секретный пароль(подготовленные пароли РА и РВ известны обеим сторонам). А создаёт криптограмму, сравнивает извлеченный из неё пароль с исходным значением. Такая процедура рукопожатия предполагает общий секретный сеансовый ключ для А и В. Другие процедуры могут включать в себя как этап распределения ключей между партнёрами, так и этап подтверждения подлинности. 9.3 Применение пароля для аутентификации Пароль пользователя – одно из самых важных и самых слабых мест безопасности системы. Человек или программа, отгадавшие пароль пользователя, получает доступ к ресурсам системы в том объёме, в котором он предоставляется пользователю. Особенно это важно в случае пароля администратора, так как его полномочия в системе гораздо шире, а действия от его имени могут повредить систему. Обычно, пароль РА, представляемый пользователем, сравнивается с исходным значением РА, хранящемся в компьютерном центре. Так как пароль должен храниться в тайне, он должен шифроваться перед пересылкой по незащищенному каналу. При совпадении РАи Р'Апароль считается подлинным, рисунок 9.7. 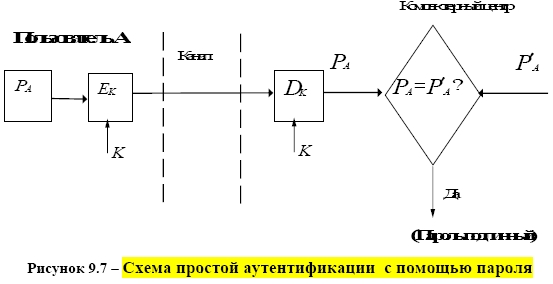 Если получатель НЕ ДОЛЖЕН раскрывать исходную форму пароля, то отправитель пересылает ВМЕСТО открытой формы пароля ОТОБРАЖЕНИЯ ПАРОЛЯ, получаемое с использованием односторонней функции α (…). Это преобразование должно гарантировать невозможность раскрытия пароля по его отображению противником в связи с неразрешимой числовой задачей. Функция α (…) определяется: α(Р) = Ер(ID) где Р – пароль отправителя; ID – идентификатор отправителя; Ер – процедура шифрования, выполняемая с использованием пароля в качестве ключа. |