Поручиков М.А. Анализ данных. А. поручиков
 Скачать 2.76 Mb. Скачать 2.76 Mb.
|

КЛАССИФИКАЦИЯ ДАННЫХОбщие сведенияКлассификация – это процесс определения принадлежности объектов к определенным классам. Существует много практических задач классификации. В промышленности при оценке качества продукции возникает задача подразделения изделий на годные и бракованные. В банковском секторе при выдаче кредитов возникает задача подразделения заемщиков на кредитоспособных и некредитоспособных. В медицине при оценке состояния здоровья возникает задача постановки диагноза. Как и регрессия, классификация относится к типу задач обучения с учителем (Supervised Learning в терминах Machine Learning). Предполагается, что имеется некоторая выборка данных, в которой представлены объекты нескольких классов. При этом выборка содержит как свойства объектов, так и признак принадлежности объекта к какому-либо классу. Применение классификации производится в два этапа. На первом этапе выполняется обучение классификатора на некотором наборе данных, а на втором этапе – непосредственная классификация новых объектов (рис. 19).  Новые объекты Новые объектыНабор классифицированных объектов Классы объектов  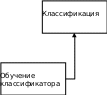 Параметры классификатора Параметры классификатора Рис. 19. Схема применения классификации Различают бинарную и множественную классификацию. Бинарная классификация предполагает наличие двух классов, множественная – трех и более классов. Классификация выполняется с помощью специальных методов (алгоритмов). Известно большое количество алгоритмов классификации. Так, в работе [20] проведены исследования 179 алгоритмов. Бинарная классификацияЗадачей бинарной классификации является определение принадлежности некоего объекта к одному из двух возможных классов. Например: является ли сообщение электронной почты «нормальным» или представляет собой спам; здоров или болен пациент; является ли заемщик банка надежным или ненадежным; качественная или бракованная деталь. Наиболее известными методами бинарной классификации являются: логистическая регрессия (Logistic Regression); «наивный» байесовский классификатор (Naive Bayes Classifier); метод опорных векторов (Support Vector Machine, SVM); нейронная сеть (Neural Network). Логистическаярегрессия Логистическая регрессия – один из методов бинарной классификации данных. Алгоритм применения логистической регрессии: Подготовка обучающей выборки – кодирование классов числами. Задание функций штрафа. 3 Задание целевой функции. 4 Задание начальных значений коэффициентам функции. 5 Численное решение: z x ; (8) h(xj) 1 1 ez ; (9) CF(hj, yj) (1 yj) ln(1 hj) yj ln(hj) . (10) В ряде случаев использование численных методов может приводить к ошибкам вычислений, поэтому иногда удобнее использовать формулу (10) в другом варианте: CF(h, y ) ln(1 hj), yj 0 . (11) jj ln(h), y 1 jj Оптимизационная задача по-прежнему формулируется как задача минимзации функции штрафа: CF CF(hj, yj) min . (12) j Рассмотрим численное решение задачи логистической регрессии с помощью программного обеспечения Microsoft Excel: 1 В соответствии с предложенным выше алгоритмом представим исходные данные и расчетные формулы (рис. 20; 21). 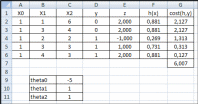 Рис. 20. Логистическая регрессия в Excel (режим значений) 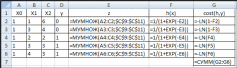 Рис. 21. Логистическая регрессия в Excel (режим формул) 2 Выполним численное решение с помощью инструмента «Поиск решения» (рис. 22). 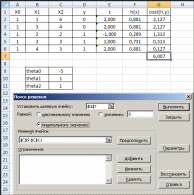 Рис. 22. Параметры поиска решения В результате численного решения будут определены параметры функции линейного разделения. Визуальная проверка показывает корректность разделения двух классов (рис. 23). 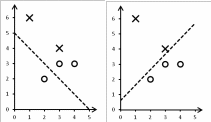 Рис. 23. Визуальное представление классов Зачастую в реальных задачах бинарной классификации данные не могут быть разделены на два класса линейной функцией гипотезы (рис. 24). 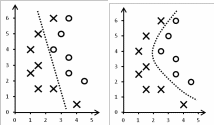 Рис. 24. Проблема линейной разделимости Возможны следующие способы решения этой проблемы: применение нелинейной функции гипотезы; принципиальная замена логистической регрессии другим методом, например, нейросетевым классификатором. |