Лекционный материал Часть 2. Контент-анализ (1). Богомолова Н. Н., Стефаненко Т. Г. Контентанализ как метод изучения документов1
 Скачать 141 Kb. Скачать 141 Kb.
|

Богомолова Н. Н., Стефаненко Т. Г. Контент-анализ как метод изучения документов1Контент-анализ (content-analysis) является одним из методов изучения документов, используемый в различных социальных исследованиях, в том числе и в социально-психологических. Специфика контент-анализа по сравнению с другими методами исследования содержания документов заключается в том, что его процедура предусматривает подсчет частоты (и/или объема) упоминаний тех или иных смысловых единиц исследуемого текста. Полученные таким образом количественные характеристики текста, т. е. его квантификация, дают возможность сделать выводы о качественном, в том числе латентном, неявном содержании документа. В связи с этим метод контент-анализа нередко обозначается как качественно-количественный анализ документов 1. Правомерность использования контент-анализа в социально-психологических и других социальных исследованиях определяется тем, что текст документа, являющийся для контент-анализа реальностью первого порядка, есть всегда продукт человеческой деятельности, социальной среды в широком смысле. Поэтому он несет в себе следы влияния разнообразных социальных и психологических факторов. Отсюда проистекает возможность обнаружения и замера этих факторов путем регистрации в тексте соответствующих индикаторов или референтов этих факторов. Таким образом, целью контент-анализа является постижение внетекстовой реальности, т. е. на основе текста документа, его анализа делаются выводы о реальных людях или явлениях. Главная сложность в процессе контент-анализа заключается в нахождении таких процедур, при помощи которых можно было бы обнаружить в тексте соответствующие индикаторы исследуемых явлений и характеристик, замерить их и затем адекватно интерпретировать. Для решения этой задачи применяют процедуры, суть которых заключается в том, чтобы исходя из конкретного текста документов и цели исследования сделать следующее: а) сформулировать ключевые, концептуальные понятия исследования, которые принято называть категориями контент-анализа; б) надежно и систематически зафиксировать частоту (и/или объем) упоминания этих категорий в отдельных элементах текстов анализируемых документов и во всей их совокупности. Полученные таким образом количественные данные подвергаются статистической обработке, и результаты интерпретируются в соответствии с целями исследования. Принято выделять следующие условия, которые делают целесообразным применение контент-анализа: 1) изучаемые качественные характеристики, в том числе и социально-психологические, носят однопорядковый характер и появляются в документах с достаточной частотой; 2) изучаемого материала столь много, что его невозможно охватить без суммарных оценок, особенно если он носит несистематизированный характер; 3) квантифицированные тексты необходимо сопоставить с иными количественными характеристиками1. Эти условия особенно четко проявляются в массовой коммуникации1, однако мы находим их и во многих других документах, в том числе в документах социально-психологических исследований, например таких, как тексты ответов на открытые вопросы анкет, в материалах интервью, в данных проективных методик и т.д. Поэтому метод контент-анализа широко используется в социально-психологических исследованиях. К основным областям его применения можно отнести исследования общения для выявления социально-психологических характеристик: а) коммуникатора сообщений, как отдельных личностей, так и социальных групп; б) реципиентов, например, на основе анализа писем или опросов аудитории; в) объектов сообщений, в том числе отдельных лиц и социальных групп, жизнедеятельность которых освещается в сообщении; г) различных средств общения, в том числе невербальных, а также особенностей форм и приемов организации содержания сообщений. Вместе с тем, коль скоро при помощи контент-анализа можно обрабатывать ответы на открытые вопросы анкет, материалы интервью и т.п., то практически контент-анализ оказывается пригодным для исследования самых различных социально-психологических феноменов: процессов групповой активности, ценностных ориентаций, межличностного и межгруппового взаимодействия и т.п. Непосредственным объектом контент-анализа чаще всего выступает текст документа, но им могут быть и фотографии в печатных изданиях1, а также звуко- и видеоряд в передачах радио и телевидения, на сайтах Интернета. Следует также отметить специальное науковедческое использование контент-анализа для исследования научной литературы по социальной психологии (выявление преобладания различной проблематики или тех или иных методов исследования в различные периоды развития социальной психологии, анализ цитирования, ссылок и т.п.). Контент-анализ может использоваться как самостоятельный метод, однако наиболее целесообразно применять его в сочетании с другими методами (прежде всего с опросом), используя в них аналогичные категории. Специфика применения контент-анализа в каждом конкретном случае в очень большой степени определяется целью и теоретической основой исследования. Ни один другой метод в социальной психологии не связан так непосредственно с теоретическими концепциями исследователя. Это объясняется тем, что основные понятия, вытекающие из целей и теоретической основы исследования, одновременно являются и категориями (смысловыми единицами) контент-анализа, с которыми исследователь соотносит отдельные элементы анализируемого текста и затем статистически обрабатывает выявленные соотношения. <…> В процессе контент-аналитического исследования можно выделить несколько этапов. 1-й этап - определение задач, теоретической основы, предмета и объекта исследования, разработка категориального аппарата, выбор соответствующих качественных и количественных единиц контент-анализа. Данный этап контент-анализа непосредственно связан с составлением программы исследования. Он носит характер качественного анализа, который подготавливает перевод смыслового содержания текста в цифровое выражение для его последующего количественного анализа. В этих целях на основе задач и теоретического контекста осуществляется выбор объекта исследования, и определяются конкретные единицы анализа. Выбор объекта исследования. При контент-анализе целевых документов, например текстов ответов на открытые вопросы анкеты, текстов интервью и т. п., обычно анализируются все собранные документы. Если же речь идет о документах, не зависимых от исследователя (текстах газет, журналов и т.п.), то возникает необходимость в выборке. В принципе построение выборки осуществляется в данном случае так же, как и в других социально-психологических исследованиях. Так, при контент-анализе текстов массовой коммуникации вначале, как правило, выбирается орган печати, затем номера за определенный период времени и типы сообщений (рубрики, типы публикаций и т.п.). Единицы контент-анализа можно разделить на две большие группы: качественные и количественные. Здесь можно ввести следующие разграничения. Качественные единицы контент-анализа отвечают на вопрос, что надо считать в тексте. Количественные единицы контент-анализа отвечают на вопрос, как надо считать. К качественным единицам можно отнести категории и их индикаторы в тексте. Следует иметь в виду, что для обозначения различных единиц контент-анализа в отечественной и зарубежной литературе используются самые разнообразные термины. Большинство авторов единодушны лишь в обозначении основной смысловой единицы контент-анализа - категории. Разнобой в терминологии при обозначении различных единиц контент-анализа в определенной степени затрудняет понимание процедуры данного метода, особенно на первых этапах его изучения. Категории контент-анализа. Ими служат ключевые понятия, составляющие концептуальную схему исследования. Категории могут быть столь же разнообразны, насколько разнообразны цели, характер и теоретическая основа исследования. В качестве категорий могут выступать, например, различные виды деятельности, типы групп, социально-психологические феномены, личностные характеристики и др.1 Категории контент-анализа могут относиться как к содержанию, так и к форме текста. В том случае, если исследователь хочет проверить гипотезу, категории выделяются заранее. При отсутствии исходной гипотезы подбор категорий усложняется и должен исходить из самого содержания документов. Таким образом, при выделении категорий необходимо исходить из особенностей как задач исследования, так и текста документов. Поскольку в процессе контент-анализа происходит соотнесение определенных элементов текста именно с этими категориями, то очень важно, чтобы они были: четко и однозначно сформулированными (у разных исследователей должна быть относительно них высокая степень согласия); исчерпывающими, т.е. охватывающими все части содержания документа, определяемые задачами данного исследования; взаимоисключающими (одни и те же части содержания документов не должны относиться к различным категориям). Категории могут подразделяться на более мелкие смысловые единицы - подкатегории. Так, например, категория «индивидуальные характеристики» может подразделяться на такие подкатегории, как «демографические характеристики», «личностные характеристики» и др. Индикаторы категорий. Это те элементы текста, те единицы содержания, которые служат качественными признаками соответствующих категорий и подкатегорий. В зависимости от специфики исследования индикаторы категорий могут выражаться в виде отдельных слов, словосочетаний, суждений, тем и т.п. Количественными единицами контент-анализа являются единицы контекста и единицы счета. Единицы контекста используются для обозначения того сегмента текста, в пределах которого определяется частота упоминания соответствующих категорий и подкатегорий. Единицей контекста может служить предложение, статья, ответ на вопрос анкеты, интервью и т.п. Единицы счета (измерения, регистрации) необходимы для осуществления статистических процедур. Они могут и совпадать и не совпадать с качественными единицами анализа или их показателями. В первом случае единица счета выражает количественную меру соотношения различных элементов текста. Квантификация текста сводится к подсчету частоты упоминания категорий и подкатегорий, который может быть: сплошным, терминологическим; сегментарным, тематическим. При сплошном подсчете регистрируются и затем подсчитываются все появления индикаторов данной категории или подкатегории. Так, например, если в качестве единицы контекста взята отдельная публикация и регистрируется частота упоминания категории «лидерство», то необходимо зарегистрировать и подсчитать все упоминания данного термина в публикации. При сегментарном, тематическом подсчете упоминаний категорий регистрируется лишь первое появление данной категории в единице контекста, а повторные упоминания этой категории в данной единице контекста не учитываются. Так, например, при тематическом подсчёте частоты упоминания категории «лидерство» вся публикация будет засчитываться как одно упоминание, независимо от того, сколько раз в ней будет использован термин «лидерство». Во втором случае единицей счета избирают объем - физическую протяженность или площадь текстов, заполненных смысловыми единицами. Объем упоминаний категорий контент-анализа может измеряться различными способами: подсчетом числа строк, печатных знаков, квадратных сантиметров площади, посвященных данной категории и т.д. Для кино, радио, телевидения обычно подсчитывается время, отведенное освещению определенного события, или метраж израсходованной кино - или магнитной пленки. Очень часто необходим учет оценочного отношения коммуникатора к предмету сообщения. Исследователи обычно фиксируют положительное, отрицательное и нейтральное отношение. Иногда особо выделяется и так называемое «сбалансированное» отношение, в котором содержатся элементы как благоприятного, так и неблагоприятного отношения. Характеристики содержания по знаку не имеют четко разработанных критериев. Знаки (плюс, минус) несут определенные слова, которые и выражают отношение коммуникатора. Однако его подлинное отношение может быть установлено при рассмотрении знаковой ситуации в целом. Свое отношение коммуникатор может выразить двумя путями: а) открыто, с использованием оценочных суждений («Это плохо», «Я это одобряю» и т.п.); б) в скрытой форме, изображая события как соответствующие или несоответствующие нормам и ценностям данного общества. Следует иметь в виду, что контент-анализ может быть многосторонним, когда одновременно используются различные количественные единицы. Одно из основных предъявляемых к ним требований заключается в том, чтобы они поддавались объективному, надежному и проверяемому измерению. 2-й этап - составление кодировочной инструкции. На этом этапе осуществляется соотнесение категорий и подкатегорий контент-анализа с конкретными содержательными элементами текста, т.е. происходит отыскание в тексте индикаторов выбранных категорий исследования. Здесь либо составляется соответствующий словарь индикаторов категорий, либо дается развернутое описание категорий в терминах исследуемых текстов. Все категории и подкатегории контент-аналитического исследования кодируются, т.е. им даются определенные цифровые или буквенные обозначения, что составляет код данного исследования. Все это входит в кодировочную инструкцию. В нее также включаются обозначения знаков информации (+, -, 0, +/-), что соответствует положительному, отрицательному, нейтральному и сбалансированному отношению к предмету сообщения. Составление кодировочной инструкции имеет очень большое значение, так как по существу в ней находят свое конкретное выражение основные положения методики исследования. Кроме соответствующего определения категорий и подкатегорий и других единиц анализа в кодировочную инструкцию включаются правила кодирования, оговариваются спорные случаи и т.д. При составлении конкретного кода в категориях предусматривается подкатегория «другое», в которую включаются те индикаторы данной категории, которые не вошли в выделенные подкатегории, но, тем не менее, являются ее показателями и поэтому должны быть зафиксированы в частоте и объеме ее упоминаний. Необходимость включения подкатегории «другое» вызывается тем, что заранее невозможно, а часто и не нужно, предусмотреть все подкатегории. 3-й этап - пилотажная кодировка текста. На данном этапе осуществляется кодировка части исследуемого массива текстов с целью апробации методики, изложенной в кодировочной инструкции. Кодировка текста представляет собой процедуру непосредственного перевода качественных, смысловых единиц (категорий, подкатегорий) через нахождение их индикаторов в тексте в количественные единицы, т. е. перевод текстов в условные обозначения - коды (цифры или буквы, которыми обозначены в кодировочной инструкции те или иные категории и подкатегории). Подобная пилотажная кодировка дает возможность проверить надежность методики, т. е. испытать ее на обоснованность (соответствие задачам и теоретическим понятиям исследования) и устойчивость (воспроизводимость результатов): 1. Обоснование полноты выделения смысловых единиц доказывается следующим образом. Выделяются все смысловые единицы из первого анализируемого текста, затем из второго текста - те же единицы плюс ранее не встречавшиеся, из третьего документа - те же, что уже встречались в двух предыдущих, плюс дополнительные и т.д. После изучения 3-5 очередных текстов, в которых не попадается ни одной новой, ранее не фиксированной в предыдущих документах единицы, можно полагать, что «поле» смысловых единиц из изучаемого материала исчерпано1. 2. Контроль на обоснованность содержания смысловых единиц проводится с помощью экспертов - специалистов по проблематике данного исследования. 3. Обоснованность по независимому критерию выявляется посредством получения аналогичных данных другими методами (опрос, наблюдение, тестирование). 4. Устойчивость данных определяется при помощи повторного кодирования тех же документов тем же кодировщиком (устойчивость во времени) или разными кодировщиками по единой инструкции (устойчивость среди аналитиков). Если данные разных кодирований находятся в достаточном соответствии (например, расхождение не выше 5%, т. е. коэффициент корреляции на уровне значимости 0,05), то можно считать, что методика позволяет получать надежные результаты2. Следует иметь в виду, что высокая надежность обычно свойственна простым формам контент-анализа. Усложнение, более тонкая дифференциация категорий связаны с понижением надежности, но дают больше информации об объекте исследования. Решение о соотношении надежности и значимости категорий обычно принимается исходя из поставленных перед исследованием задач3. Помехами для получения надежных результатов могут служить различные причины: недостатки кодировочной инструкции, низкая квалификация кодировщика и др. Следует отметить, что контент-аналитическое исследование требует от кодировщика большого внимания, терпения, упорства и добросовестности. После проведения пилотажного исследования в кодировочную инструкцию обычно вносятся соответствующие изменения для устранения выявленных помех. 4-й этап - кодировка всего массива исследуемых текстов. На данном этапе осуществляется процесс квантификации, т. е. перевод в цифровое выражение всей совокупности исследуемых текстов. Регистрация частоты и объема упоминания категорий и подкатегорий контент-анализа может производиться либо на отдельных карточках, либо в заранее подготовленных таблицах, в настоящее время, как правило, электронных. 5-й этап - статистическая обработка полученных количественных данных. Эта обработка осуществляется вручную или на компьютере. Нередко оба эти способа используются одновременно. Статистическая обработка цифрового материала, полученного в процессе кодировки, по своим методам фактически не отличается от статистической обработки данных, полученных в других видах социально-психологических исследований. Обычно используются процентные и частотные распределения, разнообразные коэффициенты корреляций и т.п. Вместе с тем следует указать и на особые способы количественной обработки данных, полученных в контент-аналитическом исследовании. Сюда следует отнести формулу оценки «удельного веса» смысловых категорий в общем объеме текста, предложенную А. Н. Алексеевым. Формула указывает на уровень интенсивности представления в тексте определенной темы, аргументации, способов обращения к читателю и т.д.: где Укс – «удельный вес» данной смысловой единицы; Кгл – число случаев, когда смысловая единица оказалась главной; Квт – число случаев, когда смысловая единица оказалась второстепенной; - сумма анализируемых документов1. Специальным способом, разработанным для нужд контент-анализа, является методика Ч. Осгуда, позволяющая при помощи расчета совместной встречаемости различных элементов в тексте анализировать взаимосвязанность элементов содержания. Процедура данной методики состоит в том, что после подсчета совместной встречаемости единиц анализа, рассчитывается квадратная матрица возможных и фактических совместных появлений этих единиц в тексте (рис. 4).
Рисунок 4. Матрица возможных и фактических совместных появлений единиц контент-анализа. Например, единица А встречается в 40% анализируемых сообщений (Ра = 0,4), а единица В - в 20% сообщений (Рв = 0, 2). Можно ожидать, что по теореме умножения вероятностей совместно эти единицы появятся с вероятностью 0,08 (Рав = Ра х Рв = 0,4 х 0,2= 0,08). Записываем это значение в соответствующую верхнюю от матричной диагонали клетку. Но на самом деле единицы А и В совместно встречаются только в 6 % сообщений (Fав = 0,06). Это число записываем в соответствующую нижнюю от диагонали клетку. Сравнивая фактические и вероятностные величины, определяем, какие фактические зависимости оказываются неслучайными. В нашем примере совместное появление единиц А и В - случайно, так как фактическая величина ниже вероятностной. Используя методику Осгуда, можно рассчитать уровень значимости неслучайных зависимостей, выделить плеяды взаимосвязанных единиц и т.д.1 6-й этап - интерпретация полученных данных. На последнем этапе исследования, так же как и на первом, связанном с составлением программы, особенно ярко выступает качественная сторона контент-анализа в отличие от количественного аспекта, преобладающего на промежуточных этапах. Для адекватной интерпретации результатов и их соотнесения с данными, полученными с помощью других методов, особенно большое значение имеет учет более широкого теоретического и социального контекста. Так, при контент-аналитическом исследовании определенной тематики или «героя» в газете или журнале весьма важно иметь данные о целях и задачах, преследуемых коммуникатором (редакцией) в данном вопросе, а также об ожиданиях аудитории и ее восприятии соответствующих сообщений (текстов), полученных, например, при помощи опроса, и соотнести результаты контент-анализа с результатами опроса. При выполнении любого контент-аналитического исследования, в том числе и заданий данного практикума, необходимо должным образом учитывать все этапы изложенной процедуры, которые суммированы в нижеприведенной схеме. Схема процедуры контент-аналитического исследования (рис. 5). 1-й этап - составление программы исследования; Программа исследования 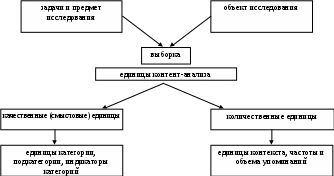 Рис. 5. Схема процедуры контент-аналитического исследования. 2-й этап - составление кодировочной инструкции; 3-й этап - пилотажная кодировка части текстов и соответствующая корректировка кодировочной инструкции; 4-й этап - кодировка всего текста, т. е. перевод смыслового содержания в цифровое выражение (квантификация текстового материала); 5-й этап - статистическая обработка полученных в кодировке цифровых данных; 6-й этап - интерпретация полученных результатов, формулировка выводов. 1 Методы социально-псилогического исследования:Учебное пособие для вузов/Под ред. Т. В. Фоломеевой. – Кемерово: Юнити, 2002. С. 35-48. 1 Семенов В. Е. Метод изучения документов в социально-психологических исследованиях. Л. , 1983. 1 Ядов В. Я. Стратегия социологического исследования. Описание, объяснение, понимание социальной реальности. М. , 1998. 1 Не случайно происхождение контент-анализа связано с исследованиями именно в этой области. 1 См., например: Фомичева И. Д. , Марковский Э. Я. Опыт качественно-количественного анализа газетной фотографии // Социологические исследования эффективности журналистики. М., 1986. 1 Примеры категорий для анализа взаимодействия в групповой дискуссии содержатся в методике Р.Бейлса (см. Общий практикум по психологии. ) Метод наблюдения. Ч. 2. М. , 1985. С. 35-51), для анализа взаимодействия учителя и ученика в классе - в методике Н. Фландерса (см. Общий практикум по психологии. Метод наблюдения. Ч. 1. М. , 1985. С. 22-23). 1 Ядов В. Я. Стратегия социологического исследования. Описание, объяснение, понимание социальной реальности. М. , 1998. 2 Методы социальной психологии/ Под ред. Е. С. Кузьмина, В. Е. Семенова. Л. , 1977. 3 Рабочая книга социолога. М. , 1983. 1 Алексеев А. Н. Опыт измерения удельного веса категорий содержания на страницах газеты // Проблемы контент-анализа в социологии. Новосибирск, 1970. 1 Методы социальной психологии/ Под ред. Е. С. Кузьмина, В. Е. Семенова. Л. , 1977. |