статистика. про тьюкиMU_4_5(DA). Дисперсионный анализ
 Скачать 1.5 Mb. Скачать 1.5 Mb.
|

Дисперсионный анализДисперсионный анализ — метод, направленный на поиск зависимостей в экспериментальных данных путём исследования значимости различий в средних значениях. Дисперсионный анализ позволяет сравнивать средние значения двух и более групп. Основную задачу дисперсионного анализа можно сформулировать следующим образом: оказывает ли значимое влияние на значение некоторой количественной переменной интересующий нас признак, измеренный на номинальном или порядковом уровне? В терминах метода дисперсионного анализа та переменная, которая, как мы считаем, должна оказывать влияние на конечный результат, называется фактором. Например, если мы хотим объяснить различия в средних доходов респондентов тем, что респонденты проживают в различных населенных пунктах, то переменная «место проживания респондента» - будет выступать фактором. Конкретное значение фактора (например, определенный населенный пункт) называют уровнем фактора. Значение измеряемого признака (в нашем примере — величину среднего дохода) называют откликом. Если исследуется зависимость отклика только от одного фактора, то такой дисперсионный анализ называется однофакторным, если исследуется зависимость от двух и более факторов, то такой дисперсионный анализ называется многофакторным. Само название - дисперсионный анализ (analysis of variance – сокращенно ANOVA) происходит из того, что метод проверки статистической гипотезы о равенстве средних значений в нескольких непересекающихся группах, основан на сопоставлении двух оценок дисперсии анализируемой количественной переменной. 1. Однофакторный дисперсионный анализВ однофакторной модели дисперсионного анализа исходят из следующей модели порождения данных: 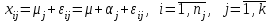 , ,где: 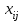 - i-ое наблюдаемое значение отклика в j-ой группе (для j-го уровня фактора); - i-ое наблюдаемое значение отклика в j-ой группе (для j-го уровня фактора);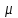 - среднее значение отклика по всем уровням фактора (среднее по всей совокупности); - среднее значение отклика по всем уровням фактора (среднее по всей совокупности);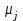 - среднее значение отклика для j-го уровня фактора; - среднее значение отклика для j-го уровня фактора;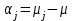 - дифференциальный эффект среднего, соответствующий j-му уровню фактора; - дифференциальный эффект среднего, соответствующий j-му уровню фактора;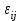 - независимые случайные величины с математическим ожиданием равным нулю и одинаковой дисперсией - независимые случайные величины с математическим ожиданием равным нулю и одинаковой дисперсией 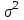 . .Выражение 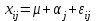 можно представить в виде можно представить в виде 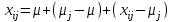 , ,или: 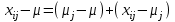 . .Данное соотношение говорит о том, что отклонение наблюдаемого значения отклика для j-ой группы складывается из суммы двух слагаемых: отклонения отклика от среднего значения j-ой группы: 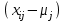 , и отклонения среднего значения j-ой группы от среднего значения всей совокупности: , и отклонения среднего значения j-ой группы от среднего значения всей совокупности: 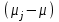 . Что, по сути, означает, что дисперсия отклика может быть представлена в виде суммы двух дисперсий, одна из которых характеризует внутригрупповую изменчивость, а вторая межгрупповую. . Что, по сути, означает, что дисперсия отклика может быть представлена в виде суммы двух дисперсий, одна из которых характеризует внутригрупповую изменчивость, а вторая межгрупповую.Разложение общей дисперсии на составляющие для выборочных данных обычно записывается в виде равенства сумм квадратов соответствующих отклонений: 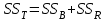 , ,где: 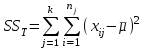 – общая, или полная, сумма квадратов отклонений; – общая, или полная, сумма квадратов отклонений;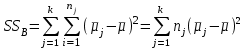 – сумма квадратов отклонений групповых средних от общего среднего, или межгрупповая (межуровневая факторная) сумма квадратов отклонений, также называемая суммой квадратов эффекта фактора или просто эффектом фактора; – сумма квадратов отклонений групповых средних от общего среднего, или межгрупповая (межуровневая факторная) сумма квадратов отклонений, также называемая суммой квадратов эффекта фактора или просто эффектом фактора;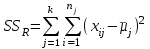 – сумма квадратов отклонений наблюдений от групповых средних, или внутригрупповая (остаточная) сумма квадратов отклонений, также называемая остаточным эффектом или эффектом ошибок; – сумма квадратов отклонений наблюдений от групповых средних, или внутригрупповая (остаточная) сумма квадратов отклонений, также называемая остаточным эффектом или эффектом ошибок;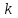 – число уровней фактора, – число уровней фактора,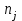 – число наблюдений для j-го уровня фактора, – число наблюдений для j-го уровня фактора,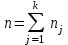 - общее число наблюдений. - общее число наблюдений.В разложении дисперсии на составляющие заключена основная идея дисперсионного анализа: общая вариация переменной, порожденная влиянием фактора и измеренная суммой 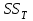 , складывается из двух компонент: , складывается из двух компонент: 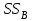 и и 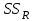 , характеризующих изменчивость этой переменной между уровнями фактора ( ) и внутри уровней фактора ( ). , характеризующих изменчивость этой переменной между уровнями фактора ( ) и внутри уровней фактора ( ).В дисперсионном анализе анализируются не сами суммы квадратов отклонений, а так называемые средние квадраты, которые получаются делением сумм квадратов отклонений на соответствующее число степеней свободы. Число степеней свободы для суммы квадратов случайных величин определяется как общее число линейно независимых слагаемых. Для полной суммы квадратов число степеней свободы 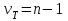 , так как при ее расчете используются , так как при ее расчете используются 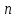 наблюдений, связанных между собой одним уравнением для общего выборочного среднего всей совокупности. наблюдений, связанных между собой одним уравнением для общего выборочного среднего всей совокупности.Для суммы квадратов эффекта фактора 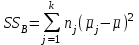 число степеней свободы число степеней свободы 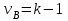 , так как при ее расчете используются групповых средних, связанных между собой также одним уравнением для общего выборочного среднего всей совокупности. , так как при ее расчете используются групповых средних, связанных между собой также одним уравнением для общего выборочного среднего всей совокупности.Для суммы квадратов ошибок число степеней свободы 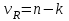 , ибо при его расчете используются наблюдений, связанных между собой уравнениями для выборочных средних групп. , ибо при его расчете используются наблюдений, связанных между собой уравнениями для выборочных средних групп.Соответственно выражения для средних квадратов отклонений, которые являются несмещенными оценками соответствующих дисперсий, имеют вид: 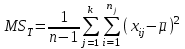 , ,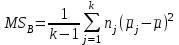 , ,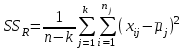 . .В случае нормального распределения остатков , при условии истинности 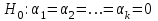 (что равносильно: (что равносильно: 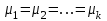 ), статистика ), статистика 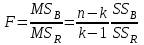 имеет распределение Фишера с 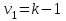 и и 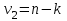 числом степеней свободы. числом степеней свободы. Если наблюдаемое значение статистики 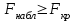 , где , где 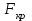 - критическая точка распределения Фишера уровня - критическая точка распределения Фишера уровня 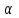 (или квантиль уровня (или квантиль уровня 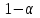 ) с числом степеней свободы и , то нулевая гипотеза отклоняется и считается, что средние для различных уровней фактора значимо различаются. ) с числом степеней свободы и , то нулевая гипотеза отклоняется и считается, что средние для различных уровней фактора значимо различаются.Условия применимости данной модели дисперсионного анализа: 1) нормальность распределения данных для каждого уровня фактора; 2) однородность (равенство) дисперсий для различных уровней фактора. Рассмотренная модель дисперсионного анализа предполагает, что данные измерены в количественной шкале. Для порядковых данных непараметрической альтернативой однофакторного дисперсионного анализа являются ранговый дисперсионный анализ Краскела–Уоллиса и медианный тест. В основе метода дисперсионного анализа Краскела — Уоллиса лежит однофакторный дисперсионный анализ, в котором вместо значений переменных используется ранг переменных. Если обозначить через 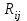 ранг элемента , в общем вариационном ряду значений отклика, то величины ранг элемента , в общем вариационном ряду значений отклика, то величины 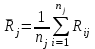 будут определять средние ранги для элементов j-ой группы, а величина будут определять средние ранги для элементов j-ой группы, а величина 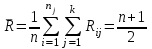 средний ранг всей совокупности. Соответственно, величина средний ранг всей совокупности. Соответственно, величина 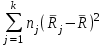 будет характеризовать межгрупповой разброс рангов. будет характеризовать межгрупповой разброс рангов.При условии истинности гипотезы 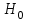 равенства средних рангов групп, статистика равенства средних рангов групп, статистика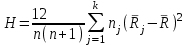 будет иметь приближенно распределение Хи-квадрат с 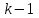 степенью свободы. степенью свободы.Если наблюдаемое значение статистики 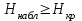 , где , где 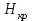 - критическая точка распределения Хи-квадрат с числом степеней свободы уровня (или квантиль уровня ), то нулевая гипотеза отклоняется и считается, что средние ранги для различных уровней фактора значимо различаются. - критическая точка распределения Хи-квадрат с числом степеней свободы уровня (или квантиль уровня ), то нулевая гипотеза отклоняется и считается, что средние ранги для различных уровней фактора значимо различаются. |